
- 1Redis数据库及其可视化管理工具RedisDesktopManager && Mysql数据库及其可视化管理工具navicat (一条龙解决从下载到使用!)_redisdesktopmanager和navicat for redis
- 2android com.intellij.openapi.externalSystem.model.ExternalSystemException
- 3harmonyOS:Service远程设备启动和停止的演示_鸿蒙os怎么开启远程服务
- 4【NLP学习笔记】NLP四大类任务+三大特征提取器_nlp文本特征提取
- 5【AI视野·今日NLP 自然语言处理论文速览 第八十期】Fri, 1 Mar 2024
- 6python3.8.3下载不了nltk_解决win10环境下python3无法下载nltk_data的问题
- 7rasa_nlu_chi 测试不成功 “error“: “y should be a 1d array, got an array of shape (1, 5) instead.
- 8Python数据集可视化:抽取数据集的两个特征进行二维可视化、主成分分析PCA对数据集降维进行三维可视化(更好地理解维度之间的相互作用)_以iris数据集为例,对该数据集的任意两个特征,使用python画图工具,将样本显示在二
- 9新词发现的代码实现_新词发现算法代码
- 10vue 透传 Attributes(二)
yolov8 瑞芯微RKNN和地平线Horizon芯片仿真测试部署_yolov8 rknn
赞
踩
特别说明:参考官方开源的yolov8代码、瑞芯微官方文档、地平线的官方文档,如有侵权告知删,谢谢。
模型和完整仿真测试代码,放在github上参考链接 模型和代码。
跟上技术的步伐,yolov8 首个板端芯片部署。
#2024年更新了更简单、更高效的部署博客(推荐使用)#
更简单、更高效的方式参考最新部署版本(推荐使用):【yolov8n 瑞芯微RKNN、地平线Horizon芯片部署、TensorRT部署,部署工程难度小、模型推理速度快】
1 模型和训练
训练代码参考官方开源的yolov8训练代码,由于SiLU在有些板端芯片上还不支持,因此将其改为ReLU。
2 导出 yolov8 onnx
后处理中有些算在板端芯片上效率低或者不支持,导出 onnx 需要将板端芯片不友好或不支持算子规避掉。导出onnx修改的部分。(注意以下步骤顺序不能乱,且有些步骤会运行保存,但只要能生成对应的文件就可以,报错不用管。)
第一步:
将pt只保存权重值,增加代码如下图。

# 保存权重值
import torch
self.model.fuse()
self.model.eval()
torch.save(self.model.state_dict(), './weights/Yolov8_dict.pt')
# self.model.load_state_dict(torch.load('./weights/Yolov8_dict.pt', map_location='cpu'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
修改后运行以下代码:
from ultralytics import YOLO
model = YOLO('./weights/yolov8n_coco128.pt')
results = model(task='detect', mode='predict', source='./images/test.jpg', line_thickness=3, show=True, save=True, device='cpu')
- 1
- 2
- 3
第二步:
导出onnx,去除不需要的算子。修改代码如下。
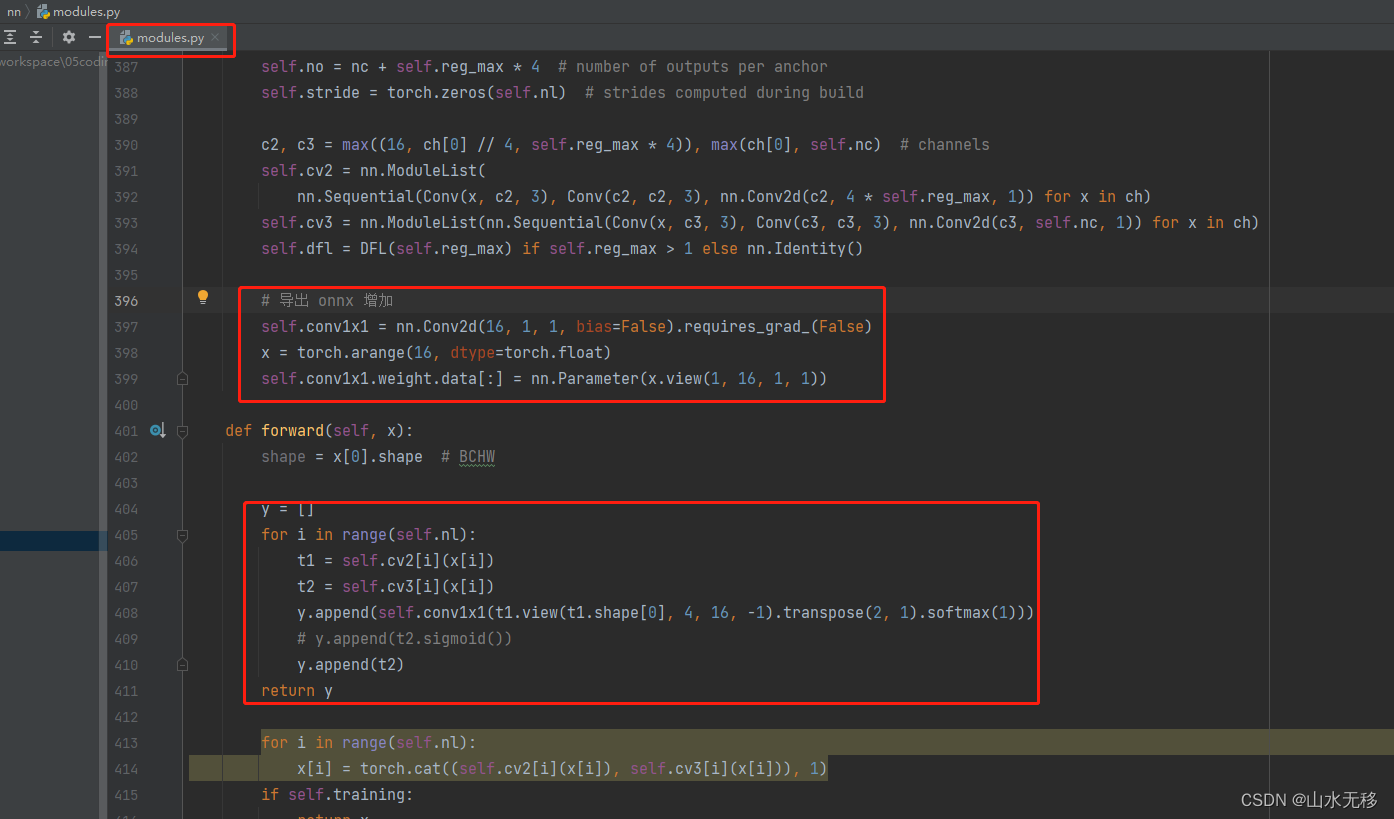
# heads class Detect(nn.Module): # YOLOv8 Detect head for detection models dynamic = False # force grid reconstruction export = False # export mode shape = None anchors = torch.empty(0) # init strides = torch.empty(0) # init def __init__(self, nc=80, ch=()): # detection layer super().__init__() self.nc = nc # number of classes self.nl = len(ch) # number of detection layers self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x) self.no = nc + self.reg_max * 4 # number of outputs per anchor self.stride = torch.zeros(self.nl) # strides computed during build c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], self.nc) # channels self.cv2 = nn.ModuleList( nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch) self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch) self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() # 导出 onnx 增加 self.conv1x1 = nn.Conv2d(16, 1, 1, bias=False).requires_grad_(False) x = torch.arange(16, dtype=torch.float) self.conv1x1.weight.data[:] = nn.Parameter(x.view(1, 16, 1, 1)) def forward(self, x): shape = x[0].shape # BCHW y = [] for i in range(self.nl): t1 = self.cv2[i](x[i]) t2 = self.cv3[i](x[i]) y.append(self.conv1x1(t1.view(t1.shape[0], 4, 16, -1).transpose(2, 1).softmax(1))) # y.append(t2.sigmoid()) y.append(t2) return y for i in range(self.nl): x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1) if self.training: return x elif self.dynamic or self.shape != shape: self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5)) self.shape = shape box, cls = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2).split((self.reg_max * 4, self.nc), 1) dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides y = torch.cat((dbox, cls.sigmoid()), 1) return y if self.export else (y, x) def bias_init(self): # Initialize Detect() biases, WARNING: requires stride availability m = self # self.model[-1] # Detect() module # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1 # ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency for a, b, s in zip(m.cv2, m.cv3, m.stride): # from a[-1].bias.data[:] = 1.0 # box b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
增加保存onnx模型代码,如下:
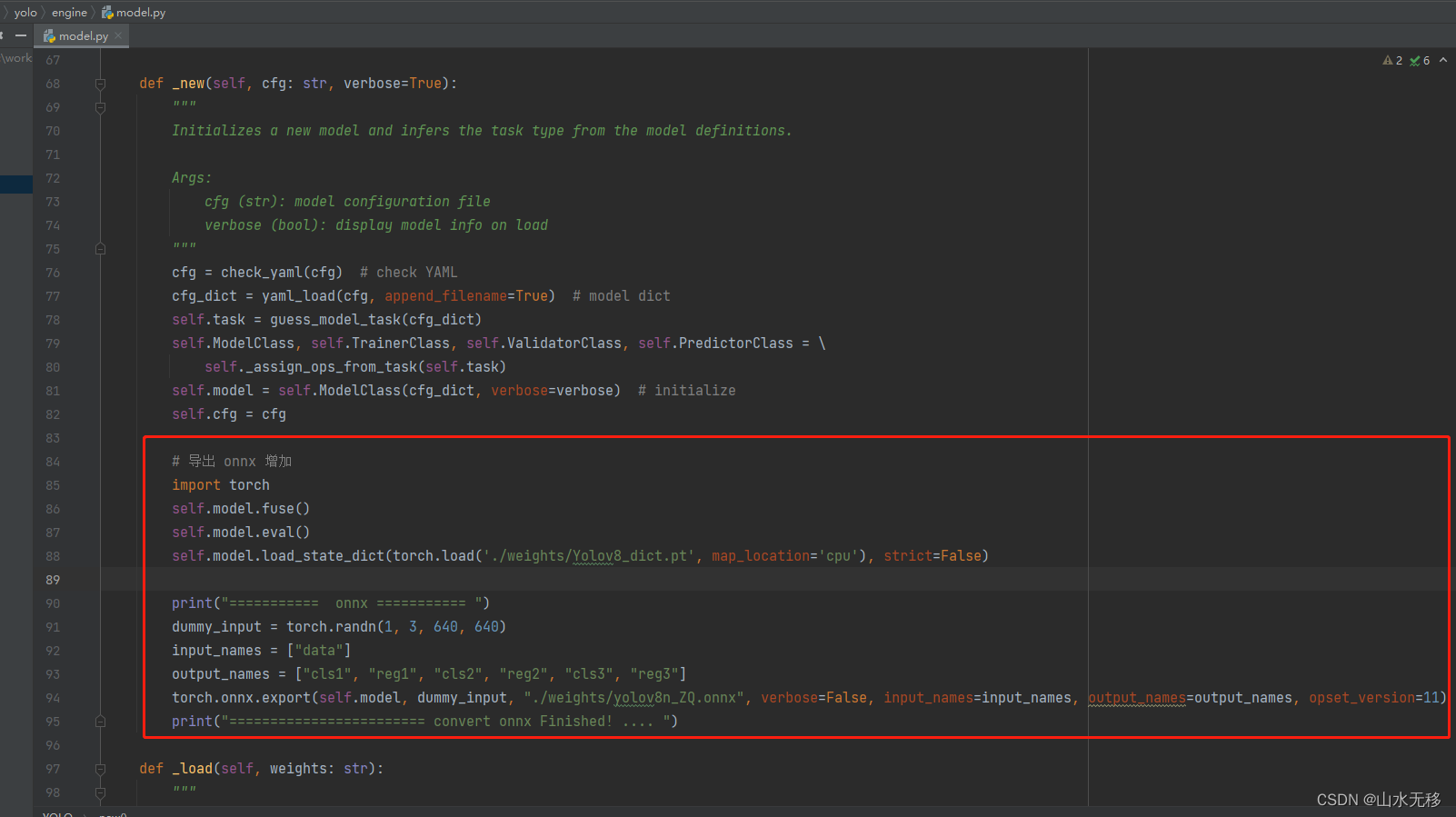
# 导出 onnx 增加
import torch
self.model.fuse()
self.model.eval()
self.model.load_state_dict(torch.load('./weights/Yolov8_dict.pt', map_location='cpu'), strict=False)
print("=========== onnx =========== ")
dummy_input = torch.randn(1, 3, 640, 640)
input_names = ["data"]
output_names = ["cls1", "reg1", "cls2", "reg2", "cls3", "reg3"]
torch.onnx.export(self.model, dummy_input, "./weights/yolov8n_ZQ.onnx", verbose=False, input_names=input_names, output_names=output_names, opset_version=11)
print("======================== convert onnx Finished! .... ")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
以上修改后完运行以下代码(注意和第一次运行的不一样,这次加载的是yaml):
from ultralytics import YOLO
model = YOLO('./ultralytics/models/v8/yolov8n.yaml')
results = model(task='detect', mode='predict', source='./images/test3.jpg', line_thickness=3, show=False, save=True, device='cpu')
- 1
- 2
- 3
- 4
3 yolov8 onnx 测试效果
onnx模型和测试完整代码,放在github上代码。

注:图片来源coco128
4 yolov8导出瑞芯微rknn和地平线horizon仿真测试
4.1 瑞芯微 rknn 仿真
瑞芯微环境搭建和详细步骤参考上一篇 【瑞芯微RKNN模型转换和PC端仿真】。
yolov8导出rknn模型代码和后处理参考 yolov8_rknn
4.2 地平线仿真
地平线环境搭建和详细步骤参考上一篇 【地平线Horizon模型转换和PC端仿真测试】。
yolov8导出地平线模型代码和后处理参考 yolov8_horizon
5 官方导出onnx方式进行瑞芯微rknn和地平线horizon仿真测试
yolov8 官方模型进行瑞芯微RKNN和地平线Horizon芯片仿真测试部署
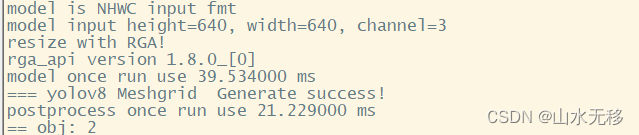
6 rknn 板端C++部署
把板端C++代码的模型和时耗也给贴出来供大家参考,使用芯片rk3588。
7 yolov8seg 部署
想尝试yolov8seg的小伙伴看过来,参考链接yolov8seg完整部署代码和模型示例


