
- 1HIFUSE:用于医学图像分类的分层多尺度特征融合网络
- 2ubuntu16.04安装python3.6.8_在 Ubuntu 16.04 LTS 上安装 Python 3.6.0
- 3HTTP状态码(响应码)_响应状态码
- 4宾至如归 | 开源社邀请您参加亚洲自由开源软件峰会2023(FOSSASIA SUMMIT 2023)
- 5神经机器翻译技术、Attention与Seq2Seq、Transformer_引用from .attention import seq_transformer
- 6Python 这几种方法进行机器学习特征筛选,有效提升模型性能_rfe变量筛选
- 7对自注意力(self-attention)的理解以及基于pytorch的简易示例_pytorch self attention
- 8一文看懂四种基本的神经网络架构_tcp 神经网络
- 9C# 进行AI工程开发-基础篇
- 10PaddleNLP:基于 LLaMA 和 Vicuna 的对话机器人_cannot import name 'llamaforcausallm' from 'paddle
Python数据清洗_python 数据清洗
赞
踩
数据清洗是指对原始数据进行筛选、过滤和清理,以去除不必要的数据、修复错误数据、填补缺失值等。数据清洗可以采用各种方法,包括使用正则表达式、删除无用数据列、去重、替换异常值等。其中,缺失值是数据清洗中最常见的问题,可以使用中位数、平均数、众数或者插值法来填充缺失值。
当我们进行数据分析和建模时,首先要面对的问题之一就是数据清洗。数据清洗是指对原始数据进行筛选、过滤和修复,以确保数据的质量和准确性。以下将介绍数据清洗的重要性,并结合Python代码详细讲解常用的数据清洗方法。
为什么需要数据清洗?
数据是我们进行分析和建模的基础,但现实中的数据往往存在各种问题,例如缺失值、异常值、重复值等。如果直接使用原始数据进行分析,可能会导致错误的结果和不准确的模型。因此,数据清洗是必不可少的步骤,它可以帮助我们:
(1)增加数据的可靠性:通过清洗数据,我们可以去除无效或错误的数据,提高数据的可靠性和准确性。
(2)减少偏差和误差:数据清洗可以排除异常值和噪声数据,减少对模型的干扰,提高建模结果的准确性和稳定性。
(3)提高模型的泛化能力:通过清洗数据,我们可以剔除不具有代表性的数据,避免模型对特定数据集过度拟合,提高模型的泛化能力。
常用的数据清洗方法
下面我们将介绍几种常用的数据清洗方法,并结合Python代码进行演示。
1.去除重复值
重复值是指数据中存在完全相同的样本或特征。重复值可能会导致模型的偏差和过拟合问题。常见的处理重复值的方法有:
删除重复值:可以直接删除重复的样本或特征列。
去重的概念:删除某个序列或是表格中某个序列中的重复数据。
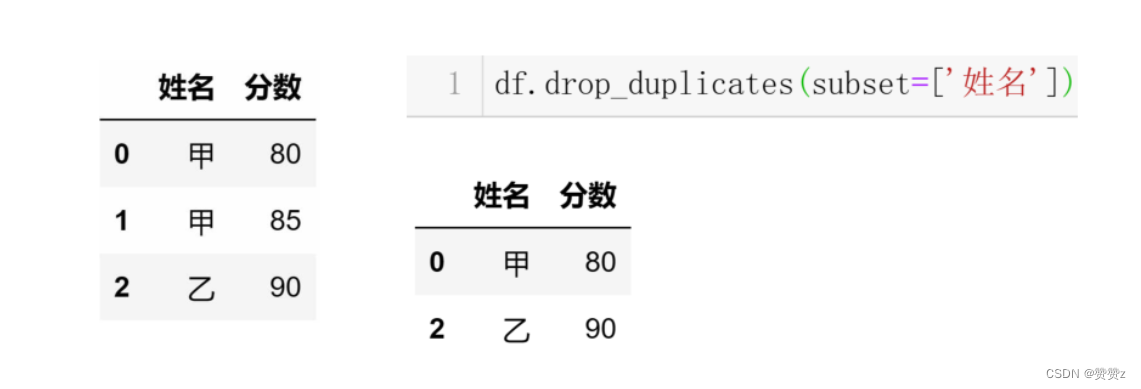
去重方法: DataFrame表格和Series序列对象内置方法drop_ duplicates()
语法结构:表格/序列对象.drop_ duplicates(subset= None ,keep= first', inplace=False)
| 参数 | 作用 |
| subset | 当去重对象是表格对象时使用,指定去重依据的字段 |
| keep | 指定去重后保留哪一行,first表示第一 行,last表示最后一行 |
| inplace | 表示去重是否对在原始数据对象上进行 |
通过subset参数指定通过哪一列数据来去重。
下面是使用pandas库进行重复值处理的代码示例:
- import pandas as pd
-
- # 读取数据
- data = pd.read_csv('data.csv')
-
- # 删除重复值
- data.drop_duplicates(inplace=True)
2. 缺失值处理
在现实的数据的产生场景中,由于人为原因或系统原因导致的数据缺失问题。
缺失值是指数据中的空值或者NaN值,可能会影响数据分析和建模的结果。常见的处理缺失值的方法有:
(1)查看数据的缺失值:
表格对象.isnull()方法返回数据是 否缺失的布尔值矩阵。
表格对象.isnull().sum()返回各列的缺失值数量。

(2)删除法处理缺失值:可以直接删除包含缺失值的样本或特征列,但这可能会导致数据量的减少,因此需要谨慎使用。
语法结构:表格对象. dropna(axis=0,how= "any' subset=None,inplace=False)
| 参数 | 作用 |
| axis | 指定删除行或者列,默认为0,表示删除行 |
| how | 对表格对象多个字段的缺失值进行删除时使用,'any'表示任何一个字段有缺失就删除,'all'表示所有字段都缺失才删除。 |
| subset | 指定要删除的缺失值来自哪一(几) 列 |
| inplace | 表示是否对原数据生效,默认为False |
(3)替换法处理缺失值:
替换法:使用某个数据去替换缺失值的处理方法,又叫填充法。
语法结构:序列对象.illna(values= 需要替换的值, inplace= False)
平均值法:-般对数值型序列使用。
众数法:一般对类别型序列使用。
特殊值法:一般在能够判断缺失数据和其他数据有不同特征时使用。
(4)插值法:可以使用插值法填充缺失值,例如使用均值、中位数或者前后值进行插值。
下面是使用pandas库进行缺失值处理的代码示例:
- import pandas as pd
-
- # 读取数据
- data = pd.read_csv('data.csv')
-
- # 删除缺失值
- data.dropna(inplace=True)
-
- # 使用均值填充缺失值
- data.fillna(data.mean(), inplace=True)
3. 异常值检测
异常值检测是指对原始数据中的异常值进行识别和处理。异常值是指与其他数据点相比明显不同或者远离正常范围的数据点,包括离群值、错误值、异常值等。异常值检测可以采用各种方法,包括箱线图、Z-Score方法、DBSCAN聚类方法等。通过检测和处理异常值,可以避免其对模型的影响,提高数据分析和建模的准确性。
异常值是指与其他数据点明显不同或者远离正常范围的数据点。异常值检测可以使用统计方法、箱线图或者聚类方法等。常见的处理异常值的方法有:
(1)删除异常值:可以直接删除包含异常值的样本或特征列,但需要谨慎判断。
(2)替换异常值:可以使用均值、中位数或者插值法来替换异常值。
下面是使用numpy库进行异常值检测的代码示例:
- import numpy as np
-
- # 读取数据
- data = np.array([1, 2, 3, 100, 5, 6, 200])
-
- # 计算均值和标准差
- mean = np.mean(data)
- std = np.std(data)
-
- # 设置阈值
- threshold = 2
-
- # 检测异常值
- outliers = []
- for i in data:
- z_score = (i - mean) / std
- if np.abs(z_score) > threshold:
- outliers.append(i)
-
- # 替换异常值为均值
- for outlier in outliers:
- data[data == outlier] = mean

总结:数据清洗是数据分析和建模过程中必不可少的一步,它可以帮助我们提高数据的可靠性、减少偏差和误差、提高模型的泛化能力。常见的数据清洗方法包括去除重复值、处理缺失值和检测异常值。数据清洗是保证数据质量和准确性的重要步骤,它能够提高数据分析和建模的结果的准确性和可靠性。在实际应用中,根据具体情况选择合适的数据清洗方法,可以帮助我们得到更好的分析和建模结果。

