
- 1实操教学|用Serverless 分分钟部署一个 Spring Boot 应用,真香!
- 2色彩校正及OpenCV mcc模块介绍_有mcc的opencv
- 3文本----简单编写文章的方法(中),后端接口的编写,自己编写好页面就上传到自己的服务器上,使用富文本编辑器进行编辑,想写好一个项目,先分析一下需求,再理一下实现思路,再搞几层,配好参数校验,lomb
- 4【Flink实战系列】Flink+kafka+redis 实时计算 wordcount_flink 读写redis
- 5【ViViT】A Video Vision Transformer 用于视频数据特征提取的ViT详解_视频vit
- 6数据结构之——简说链表
- 7【专题】2024中国汽车业人工智能行业应用发展图谱报告合集PDF分享(附原数据表)...
- 8浅谈Nginx负载均衡原理与实现_nginx 负载均衡 必须在局域网吗为什么
- 9二、Neo4j的使用(知识图谱构建射雕人物关系)
- 10推荐9个好玩的AI作图网站_mental ai
本届挑战赛冠军方案:基于LLM的多场景智能运维_场景应用比赛
赞
踩
本文介绍本届挑战赛冠军得主SRE-Copilot团队的参赛方案:基于LLM的多场景智能运维。
基础架构-SRE,负责字节跳动基础架构部门所有组件的SRE工作,沿着成本、稳定性、效率、服务四条主线,致力于打造高扩展、高可用的生产系统。基础架构-SRE-数据化团队,负责SRE的数据化运营及智能化探索,数据化产品包括基础架构离线数仓与数据门户、资源交付数据化运营系统;智能化方向涵盖异常检测、智能变更、故障诊断、智能限流、运筹优化与大语言模型应用。协同和赋能SRE从DataOPS向AIOps和ChatOPS转变,是我们一直努力的方向。团队成员:王宁,李美珍,何甲,丁文俊。
赛题分析
本次赛题为开放性赛题,探讨的是大语言模型在AIOps领域的应用,基于建行稳定性系统模拟建行生活类APP的真实环境,希望解决企业运维团队面对规模庞大、结构复杂、动态变化的运维数据需要解决的一系列挑战(系统架构复杂,数据量庞大,数据种类多等)。
方案介绍
整体框架
为此我们提出了SRE-Copilot:一套基于大语言模型的多场景智能运维框架,这套框架支持多个智能体Agent的协作与动态编排调度,有计划,记忆,反思与推理等能力,为SRE同学提供智能化服务。我们参考了GPT的思想,也就是通过集成学习的方式,用多个专业的子Agent组合成强大的混合专家(MoE,Mixture of Experts)系统。
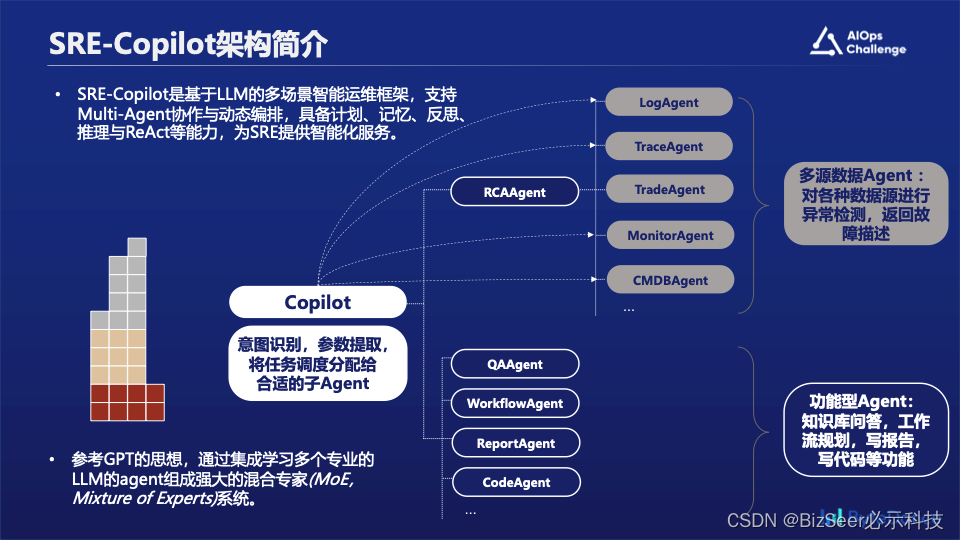
首先我们针对本次比赛提供的多种模态的数据,构建了多个底层的专家Agent,包括:
- 日志类LogAgent:负责对日志类型数据进行异常检测,对日志数据进行检索,根据集群筛选日志
- 调用链类型TraceAgent:负责对调用链数据进行异常检测,进行简单的诊断。
- 交易类型TradeAgent:对交易量等黄金指标进行异常检测
- 主机类型MonitorAgent:对主机类型数据,包括cpu,负载,网络等进行异常检测
- 拓扑类型CMDBAgent:对CMDB信息进行关联,提取&查询CMDB信息 其他:未来对其他类型数据可自由拓展
然后我们在上层定义了多个功能类Agent,包括故障诊断,知识库问答,工作流生成,故障报告生成,代码编写等
在整体架构上我们通过大语言模型把全部功能组合起来,实现意图识别,参数提取,任务调度等功能。
主要运维能力:异常检测
在该场景下,我们通过ReAct框架和CoT思维链的方式来实现了multi-agent的编排与调度。为了更方便表示我们的调度全过程,我们用下图来说明。

ReAct框架简介
ReAct的思想参考自论文ReAct: Synergizing Reasoning and Acting in Language Models,它是来自谷歌研究院和普林斯顿大学的一组研究人员在探索了在语言模型中结合推理和行为的潜力后发布的结果。虽然大型语言模型(LLM)推理(思维链提示)和行动(行动计划生成)的能力已经作为单独的主题进行了研究,但这是第一次将这两种能力组合到一个系统中。所以我觉得这是一篇重要的论文,因为ReAct框架允许虚拟代理使用诸如连接到web和SQL数据库之类的工具,所以可以提供几乎无限的扩展。
推理和行动的力量
人类智能的特点是将以任务为导向的行动和关于下一步行动的推理无缝结合。这种能力使我们能够快速学习新任务并做出可靠的决定,而且可以适应不可预见的情况。ReAct的目标就是在语言模型中复制这种协同作用,使它们能够以交错的方式生成推理步骤和特定于任务的操作。
ReAct如何工作的
ReAct提示大型语言模型为给定任务生成口头推理历史步骤和操作。这些提示由少量的上下文示例组成,这些示例指导模型的思考和操作生成。下面的图中给出了一个上下文示例。这些例子引导代理经历一个循环过程:产生一个想法,采取一个行动,然后观察行动的结果。通过结合推理跟踪和操作,ReAct允许模型执行动态推理,这样可以生成高级计划,还可以与外部环境交互以收集额外的信息。
具体例子
如图中所示,我们会构造如下的prompt

此时模型会将问题抛给TradeAgent

通过这种模式,将排障流程进行下去,每个Agent各司其职,我们也对异常检测插件进行了改造,不同于传统的异常检测算法,只返回单独的True/False信息,我们让插件返回故障时刻的描述,更加利于大语言模型的理解,例如:“CPU指标出现突增,网络出入流量突增”,当发现没有额外信息后,就会停止检测,进行根因定位。
主要运维能力:根因定位

RAG框架
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。Meta AI 的研究人员引入了一种叫做检索增强生成(Retrieval Augmented Generation,RAG)(opens in a new tab)的方法来完成这类知识密集型的任务。
检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
通过从更多数据源添加背景信息,以及通过训练来补充 LLM 的原始知识库,检索增强生成能够提高搜索体验的相关性。这能够改善大型语言模型的输出,但又无需重新训练模型。额外信息源的范围很广,从训练 LLM 时并未用到的互联网上的新信息,到专有商业背景信息,或者属于企业的机密内部文档,都会包含在内。
知识库构建
我们会提前定义一些专家的诊断经验和历史故障库。并且将信息转化为高维度空间中的向量。这些知识向量会被存储在向量数据库中。
通常一个专家经验可以由运维工程师或者业务专家来定义,比如:流量突增,内存打满,服务不可用。对应的可能是大量访问带来的问题,此时应该扩容或重启。
历史故障则是经过运维人员确认的一个故障工单,比如:12月1日12点,用户反馈交易不可用。12点05排查到xx集群主机流量突增,内存突增。经过重启后解决。
向量检索
在根因检测阶段,我们会得到上一步异常检测生成的故障摘要。检索模型会从知识库、数据库或外部来源(或者同时从多个来源)抓取相关信息。检索到的这一信息可以作为模型所需要参考来源。
向量模型会基于与输入查询的相关性,对检索到的信息进行排序。分数最高的文档或段落会被选中,以进行进一步的处理。
生成
接下来,生成模型(例如 LLM)会使用检索到的信息来进行根因推断。整体而言,这些回复更加准确,也更符合语境,因为这些回复使用的是检索模型所提供的补充信息。在私域知识方面,这一功能尤其重要。
反思与推理
由于本次比赛使用的是6b的小模型,推理时候的稳定性较差,我们此时引入了“反思”的机制,让模型对自己回答过的根因进行再次判断,进一步提高了根因定位的准确度。
另外,我们惊喜地发现,即使是小模型,在没有专家经验和历史故障的输入时,仍然能对一些简单问题进行根因推断,例如:磁盘写满故障,java虚拟机GC问题等等。
具体例子
如图中所示,我们会构造如下的prompt

此时模型会给出推断,并且匹配到对应的预案进行止损.
辅助运维能力:多场景集成

在辅助运维能力这部分,我们基于大语言模型的使用tools的能力,把散落的各个运维场景进行统一集成。对用户进行意图识别,自动编排调用不同的工具去解决用户的问题。
总结与展望
我们觉得将大语言模型引入到AIOps领域,可能会解决一些AIOps领域的痛点问题,比如:
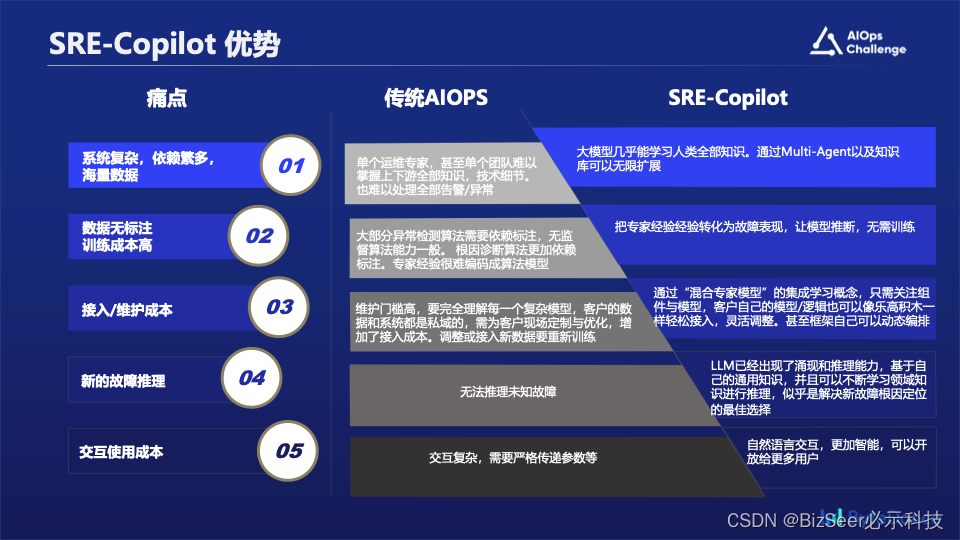
- 当前各个公司的系统架构愈发复杂,各种组件依赖越来越多,很难有一个专家,甚至一个团队精通全部架构/组件的技术细节。当发现问题时候,通常是快速拉起多个组件的同学进行协同定位。而LLM可以学习近乎无限的知识,也可以通过设计多个专家Agent的方式进行编排调度无限拓展。
- 传统AIOps算法大多依赖统计方法,异常检测&根因诊断大部分算法都依赖于数据的标注。专家的经验很难编码到模型里,而LLM基于检索增强的方式,极大地降低数据标注成本和重新训练的成本。
- 在接入维护方面,传统AIOps当遇到新客户/私域知识/业务经验/数据变动等情况时,通常只能重新训练,而通过多Agent多方式,客户甚至可以将自己的逻辑经验轻松接入。
- 对于未知的故障,由于没有训练过,传统AIOps算法无法推理,但是LLM通过通用知识的学习,可以进行一些简单的推断。
- 最后就是在交互方面,LLM也极大地降低了交互成本,让用户更加易用。
未来展望

我们在这次比赛中,将大语言模型LLM与智能运维AIOps结合,在可能的场景做了一些尝试性的探索,很感谢评委老师们的肯定与认可。在未来,我们希望可以将这套框架在生产环境中落地并且迸发业务价值。同时,也期待业界涌现出更智能的通用模型,更强大的专业模型,更丰富的使用场景。

