
热门标签
热门文章
- 1脑电信号处理与特征提取——1. 脑电、诱发电位和事件相关电位(胡理)_脑电信号波提取
- 2Android中ELF文件结构浅析(一)_安卓elf文件
- 3MachineLearning 30. 机器学习之特征选择森林之神 (Boruta)
- 4树莓派4B学习笔记四--基于Docker搭建Nginx,在Nginx服务器上部署Vue项目_vue项目部署在docker上,使用nginx代理,使用ip访问
- 5如何监听USB插拔_js 如何监听设备有没有插u盘
- 6HarmonyOS4.0系统性深入开发29层叠布局
- 7时域分析——有量纲特征值含义一网打尽_时域特征
- 8html中v-html样式不显示问题_v-html 不显示文字样式
- 9Apache POI 快速入门
- 10三十八、动态规划——背包问题( 01 背包 + 完全背包 + 多重背包 + 分组背包 + 优化)_动态规划背包
当前位置: article > 正文
【情感分析概述】
作者:从前慢现在也慢 | 2024-04-01 15:26:08
赞
踩
【情感分析概述】
一、情感极性分析概述
情感极性分析(Sentiment Polarity Analysis)是自然语言处理技术的一部分,它关注于从文本数据中自动检测和分类情感的倾向性。这种分析能够帮助我们理解人们对于某个主题、产品或服务的感受是积极的、消极的还是中立的。
1. 定义
情感极性分析通过自然语言处理、文本分析和计算语言学方法,识别和提取文本中的主观信息。它通过分析词汇的使用和句子的结构,确定文本表达的情感是正面、负面还是中性。
2. 情感极性的类别
情感极性主要分为三大类:正面、负面和中性。
- 正面情感:表达满意、喜悦、赞赏或其他积极态度的情绪。
- 负面情感:表达不满、悲伤、批评或其他消极态度的情绪。
- 中性情感:既不表达积极也不表达消极态度,可能是客观描述或不包含情感的信息。
3. 应用场景
- 社交媒体监控:分析用户在社交媒体上的评论和帖子,了解公众对特定话题或品牌的情感倾向。
- 市场研究:通过分析消费者评论和反馈,企业可以了解市场趋势,顾客满意度和产品改进的方向。
- 政策分析与公共管理:政府机构可以利用情感分析监控民众对于政策变化的反应,优化公共服务和政策制定。
- 金融市场分析:情感分析可以用来预测股市趋势,通过分析财经新闻和报告中的情绪变化来预测市场动向。
二、情感极性分析的技术方法
情感极性分析的技术可以大致分为两类:基于规则的方法和基于机器学习的方法。这两种方法各有特点,适用于不同的应用场景和数据集。
1. 基于规则的方法
基于规则的方法依靠预先定义的规则来分析文本中的情感。这些规则通常基于语言学知识,如词性、句子结构和特定的情感词汇。
a. 关键词打分
- 工作原理:此方法通过为每个情感词分配正负分数来评估整个文本的情感倾向。文本的情感分数是所有情感词分数的总和,正分表示正面情绪,负分表示负面情绪。
- 优点:实现简单,不需要训练数据。
- 缺点:难以处理含义复杂的文本,如反讽、双关语等。
- 适用场景:适用于语言相对简单且情感表达直接的文本分析。
b. 情感词典的使用
- 工作原理:使用预先定义的情感词典(包含大量的情感词及其情感倾向性评分),通过匹配文本中的词汇来确定文本的情感极性。
- 优点:能够较准确地识别和评估情感词汇。
- 缺点:对于依赖上下文的情感表达效果不佳。
- 适用场景:当文本中的情感表达主要通过情感词汇直接展现时较为有效。
2. 基于机器学习的方法
基于机器学习的方法通过训练模型来自动识别和分类文本的情感极性。这种方法可以处理更复杂的语言特征,适用于各种类型的文本数据。
a. 监督学习方法
- 工作原理:使用带有情感标签的数据集来训练一个分类器,该分类器能够学习文本特征与情感极性之间的关系,从而对新的文本进行情感分类。
- 优点:准确度较高,能够处理复杂的文本特征和隐含的情感表达。
- 缺点:需要大量的标注数据进行训练。
- 适用场景:当有足够的标注数据可用,且文本表达情感较为复杂时。
b. 深度学习方法
- 工作原理:利用深度神经网络(如卷积神经网络CNN,循环神经网络RNN)自动提取文本特征,并进行情感分类。
- 优点:能够自动学习复杂的语言特征,处理更复杂的文本结构和含义。
- 缺点:模型训练需要大量的计算资源和时间。
- 适用场景:适用于大规模文本数据和需要高准确度的情境,尤其是当文本具有复杂的结构和语义时。
三、Python进行情感极性分析
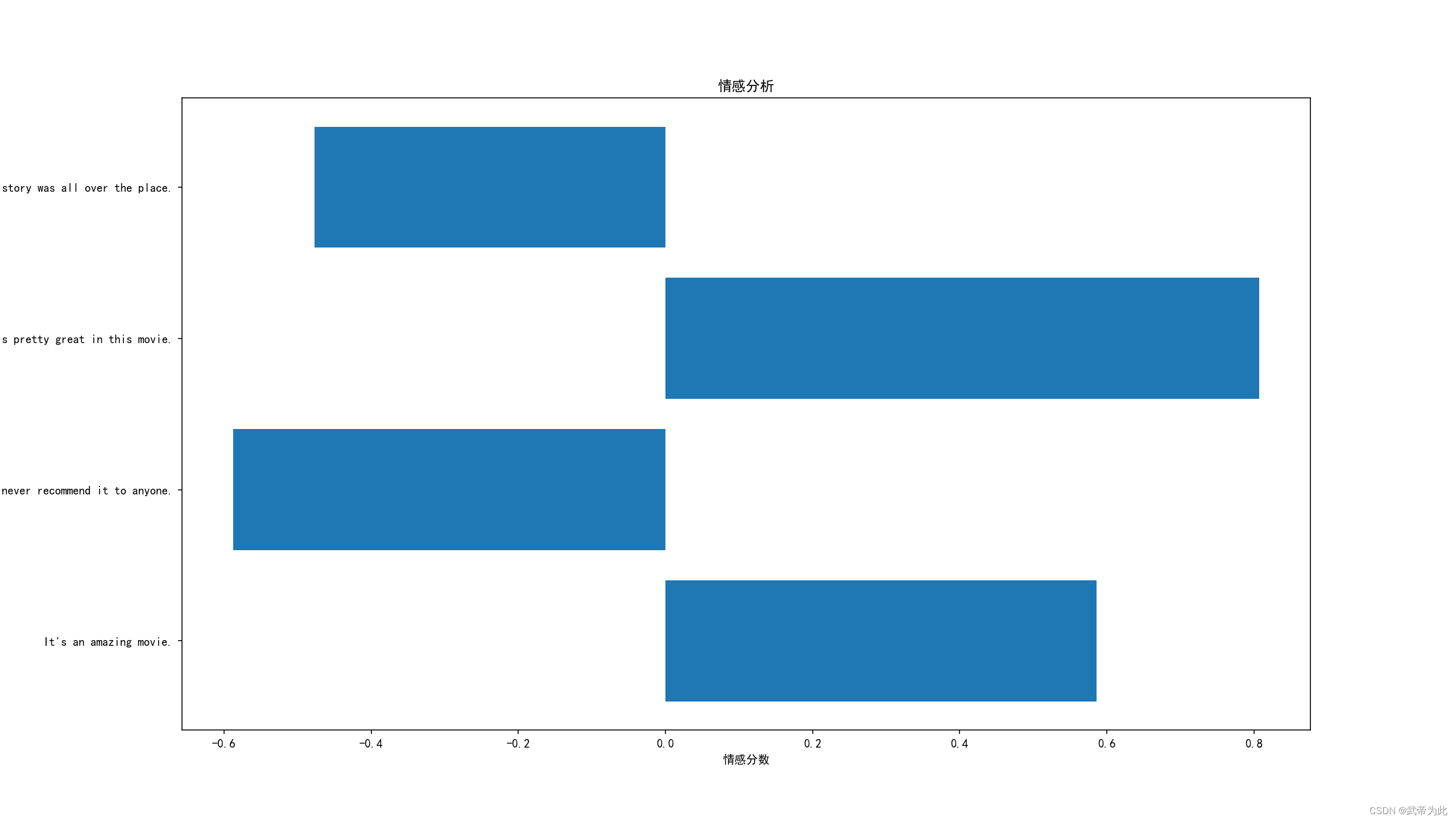
import nltk from nltk.sentiment.vader import SentimentIntensityAnalyzer # 下载情感分析所需的nltk数据 nltk.download('vader_lexicon') # 初始化情感分析器 sia = SentimentIntensityAnalyzer() # 从NLTK示例数据集中加载一些示例评论 reviews = [ "It's an amazing movie.", "This is a dull movie. I would never recommend it to anyone.", "The cinematography is pretty great in this movie.", "The direction was terrible and the story was all over the place." ] # 对每个评论进行情感分析 for review in reviews: scores = sia.polarity_scores(review) print(f"{review} - {scores}") # 可视化情感分析结果 import matplotlib.pyplot as plt # 为每个评论计算情感分析得分 compound_scores = [sia.polarity_scores(review)['compound'] for review in reviews] # 设置中文 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False # 创建一个水平条形图 plt.barh(reviews, compound_scores) plt.xlabel('情感分数') plt.ylabel('评论') plt.title('情感分析') plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/349465
推荐阅读
相关标签

