- 1余弦相似度总结_余弦相似度的特点是什么?
- 2Springboot项目优化篇_一个springboot项目有哪些需要优化的地方
- 3空间面板数据模型及Stata实现_空间面板模型
- 4关于GPT的Open API,看这一篇就够了(教你搭建)_gpt api
- 5android seekbar 大小,SeekBar中的三个宽度
- 6docker安装RabbitMQ_docker 安装rabbitmq
- 7大数据可视化分析基于Python的某地区空气质量数据分析及可视化_空气质量可视化
- 8121-基于stm32单片机出租车计价器收费系统Proteus仿真+程序源码_基于stm32单片机的出租车计价器
- 9【大数据Hive】hive 加载数据常用方案使用详解_hive 加载hdfs分区数据到表
- 10三维重建算法综述|传统+深度学习方式_三维重建综述
【Paper Reading】7.DiT(VAE+ViT+DDPM) Sora的base论文
赞
踩
| 分类 | 内容 |
|---|---|
| 论文题目 | |
| 作者 | William Peebles (UC Berkeley), Saining Xie (New York University) |
| 发表年份 | 2023 |
| 摘要 | 介绍了一类新的扩散模型,这些模型利用Transformer架构,专注于图像生成的潜在扩散模型。这些模型用在latent patches上操作的Transformer替换了常见的U-Net骨架。通过前向传递复杂度分析了可扩展性,显示出具有更高Gflops的模型一致地实现了更低的FID分数。最大的模型在类条件ImageNet生成任务上设定了新的基准。 |
| 引言 | 讨论了跨各种领域(包括NLP和视觉)由Transformer驱动的机器学习的最新进展。强调了在传统使用U-Net架构的扩散模型中,Transformer的潜力。引言为探索基于变压器的扩散模型(DiTs)的可扩展性和有效性奠定了基础。 |
| 主要内容 | 提出了作为扩散模型的可扩展和有效架构的Diffusion Transformers(DiTs),强调了它们的设计、训练和在图像生成任务上的性能。详细讨论了从U-Net到Transformer的过渡,为适应扩散模型而做出的设计选择,以及引入新的图像质量基准。通过改变模型大小和patches大小来探讨DiTs的可扩展性,展示了在FID分数上的显著改进。 |
| 实验 | 通过在256x256和512x512分辨率的类条件ImageNet生成任务上评估DiTs的性能,将它们与先前的最先进模型进行比较。证明了DiTs在图像质量上的优越性,如通过更低的FID分数所证明。还探索了不同条件策略和模型缩放对性能的影响,进一步验证了DiTs在生成高质量图像方面的可扩展性和效率。 |
| 结论 | DiTs在基于扩散的图像生成任务中超越了现有的U-Net模型,受益于Transformer架构的可扩展性和效率。提出了进一步扩展DiTs和探索它们在其他生成任务中应用的潜在未来方向,如文本到图像模型。强调了在类条件ImageNet基准上取得的有希望的结果,作为DiTs潜力的证据。 |
| 阅读心得 |
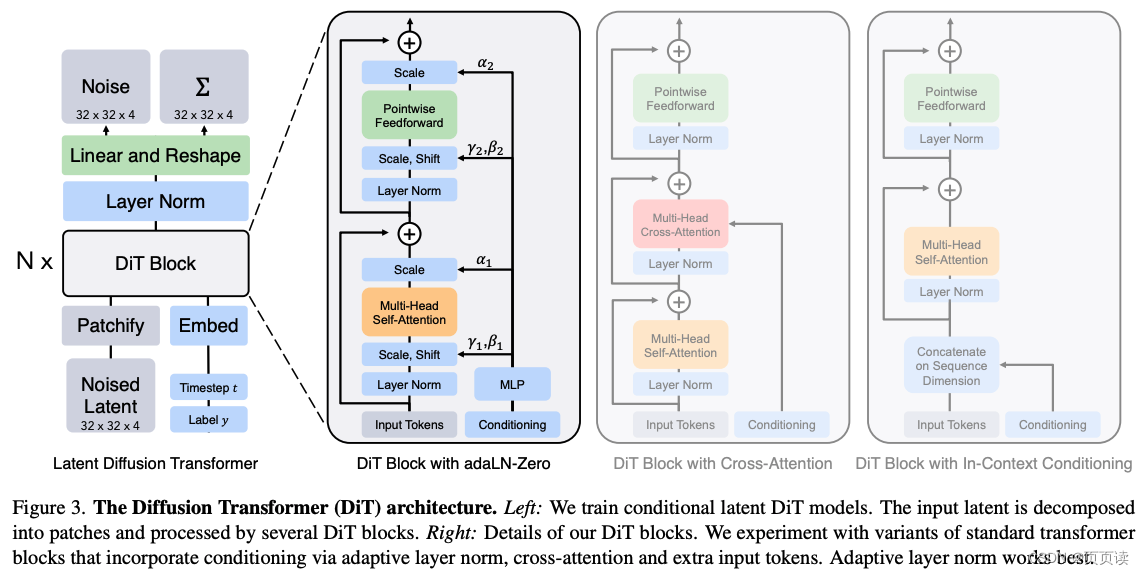
该论文提出了一种综合VAE+ViT+DDPM的基础架构,主要是在latent patches(可以去看VAE)空间进行操作,这样做的好处是首先计算cost会减小很多,例如如果在原始的图片上操作,例如256x256,那在latent patches空间就可以是32x32. Latent patches是指训练一个图像编码器,我们首先可以把原始图像编码为embeding, 也就是E(x), 编码后的空间就是论文中所说的latent patches空间. 另外,论文中对不同结构的DiT Block的变体进行了对比实验,如上图所示. DiT是指 Diffusion Transformer, 类似ViT(Vision Transformer). 实验证明采用adaLN-Zero的变体结构效果最好. 具体的各个变体的说明可以看论文. 亮点:
注:adaLN-zero 是 DiT (Diffusion Image Transformer) 中的一种技术,它是一种自适应层归一化(Adaptive Layer Normalization)方法。在图像生成任务中,归一化是一种重要的技术,用于帮助模型训练和稳定性。adaLN-zero 特别设计用于扩散模型,通过动态调整归一化参数以适应不同的生成阶段和条件,从而提高生成图像的质量和一致性。 |