
- 1nltk 报错_lookuperror: *************************************
- 2spring boot 利用element框架上传图片_el-upload spring 表单图片上传
- 3window下使用linux子系统及基于wsl2安装docker_wsl 安装docker
- 4链路追踪详解(三):分布式链路追踪标准的演进
- 5element组件点击复选框不选中问题_element ui表格多选框,多选时不符合条件,点击不勾选
- 6大数据到底怎么学:数据科学概论与大数据学习误区
- 7Google 文件系统
- 8SDRAM操作说明——打开DDR3的大门_sdram芯片使用教程
- 9全链路日志追踪traceId(http、dubbo、mq)_链路追踪traceid
- 10NLP-词向量(Word Embedding)-2014:Glove【基于“词共现矩阵”的非0元素上的训练得到词向量】【Glove官网提供预训练词向量】【无法解决一词多义】_创建同义词向量
DDPM(扩散模型):以自己能够理解的角度_ddpm中的1000次
赞
踩
Denoising Diffusion Probabilistic Models
去噪扩散概率模型。总得来说分为两个过程;
-
前向过程(加噪)
- 一个不断加标准高斯噪声(破坏图像)的一个过程。
- 当时间 t t t 足够大时,我们可以认为此时的图像近似为一张纯高斯噪声图像 x T \mathbf{x}_{T} xT。
-
反向过程(去噪)
- 采样一个标准的高斯噪声 x T \mathbf{x}_{T} xT,让网络对其逐步去噪 x T − 1 , x T − 2 , … \mathbf{x}_{T-1}, \mathbf{x}_{T-2}, \ldots xT−1,xT−2,… ,最终得到没有噪声的图像 x 0 \mathbf{x}_{0} x0 。
用粗略的话讲,模型学习在每个时间 t t t 加多少噪声,去多少噪声,那么自然就可以从一张标准的高斯噪声恢复出真实图像。
前向过程
前向过程也称为扩散过程,将真实数据逐步变成噪声。
从单个图像( 原始图像表示为: x 0 \mathbf{x}_{0} x0)来看,我们添加一次 「标准」高斯噪声 ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon}\sim\mathcal{N}(0,\mathbf{I}) ϵ∼N(0,I),得到 x 1 \mathbf{x}_1 x1。记 x i \mathbf{x}_i xi 为对原始图像加 i i i 次噪声后的结果。 当时间 i i i 足够大的时候,数据会被高斯噪声淹没,变成纯正的高斯噪声。

上图的扩散过程从 x 0 \mathbf{x}_{0} x0 一直到 x T \mathbf{x}_{T} xT 就是一个马尔可夫链,表示状态空间中经过从一个状态到另一个状态的转换的随机过程。
- 至于什么是马尔可夫链,后续打算单独讲(简单来讲就是当前状态只于前一个状态有关)
首先第一个问题,加多少次噪声?
在文中,其由一个超参数 T T T控制,即步数。原文 T = 1000 T=1000 T=1000, 即对原始图像加1000次噪声后,其会变成完全的高斯噪声。
那么噪声怎么加呢?
加噪声的过程其实是一个加权的过程。比如 $ 0.8\times Image+0.1\times Noise$,我们需要弄清楚的就是权重系数的问题,噪声的权重我们可以称之为扩散率。
直觉上来说,加噪对图像原有的信息应该是是慢慢破坏的(扩散率很低),也就是说扩散率应该是在慢慢增大。这样主要是为了方便网络在逆扩散过程中学习去噪。
也就是说——去噪的过程是先把"明显"的噪声给去除,对应着较大的扩散率;当去到一定程度,逐渐逼近真实真实图像的时候,去噪速率逐渐减慢,开始微调,也就是对应着较小的扩散率。
> 重要公式 1 <
x t = α t x t − 1 + 1 − α t ϵ t , ϵ t ∼ N ( 0 , I ) \mathbf{x}_t=\sqrt{\alpha_t}\mathbf{x}_{t-1}+\sqrt{1-\alpha_t}\boldsymbol{\epsilon}_t,\quad\boldsymbol{\epsilon}_t\sim\mathcal{N}(\mathbf{0},\mathbf{I}) xt=αt xt−1+1−αt ϵt,ϵt∼N(0,I)
原文中还有一个符号是 β t \mathrm{\beta}_t βt , 两者关系是 α t = 1 − β t \mathrm{\alpha}_t = 1 - \mathrm{\beta}_t αt=1−βt,所以有;
x t = 1 − β t x t − 1 + β t ϵ t , ϵ t ∼ N ( 0 , I ) \mathbf{x}_t=\sqrt{1 - \beta_t}\mathbf{x}_{t-1}+\sqrt{\beta_t}\boldsymbol{\epsilon}_t,\quad\boldsymbol{\epsilon}_t\sim\mathcal{N}(\mathbf{0},\mathbf{I}) xt=1−βt xt−1+βt ϵt,ϵt∼N(0,I)
上述公式其实就是提到的 $ a\times Image+ b\times Noise$。其中 I m a g e Image Image 是 x t − 1 \mathrm{x}_{t-1} xt−1, N o i s e Noise Noise 是 ϵ t \mathrm{\epsilon}_t ϵt 。前向过程噪声是在逐步增加,对应着 1 − α t \sqrt{1 - \mathrm{\alpha}_t} 1−αt 在逐步减小。
前向过程: β t \mathrm{\beta}_t βt 在逐步减小, α t \mathrm{\alpha}_t αt 在逐步增大;
对于大多数文章来说,经常出现下面这个式子
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(\mathbf{x}_t|\mathbf{x}_{t-1})=\mathcal{N}(\mathbf{x}_t;\sqrt{1-\beta_t}\mathbf{x}_{t-1},\beta_t\mathbf{I}) q(xt∣xt−1)=N(xt;1−βt xt−1,βtI)
需要说明的是 x t = 1 − β t x t − 1 + β t ϵ t − 1 \mathbf{x}_t=\sqrt{1 - \beta_t}\mathbf{x}_{t-1}+\sqrt{\beta_t}\boldsymbol{\epsilon}_{t-1} xt=1−βt xt−1+βt ϵt−1 和 q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(\mathbf{x}_t|\mathbf{x}_{t-1})=\mathcal{N}(\mathbf{x}_t;\sqrt{1-\beta_t}\mathbf{x}_{t-1},\beta_t\mathbf{I}) q(xt∣xt−1)=N(xt;1−βt xt−1,βtI) 是等价的,参考前置知识中的 「重参数化技巧」 ,$\epsilon=\mu+\mathbf{z}\cdot\sigma $ 表述的就是从 ϵ ∼ N ( μ , σ 2 ) \epsilon\sim\mathcal{N}(\mu,\sigma^2) ϵ∼N(μ,σ2) 中采样的过程。
任意时刻的 x t \mathbf{x}_t xt 由 x 0 \mathbf{x}_0 x0 表示
这里存在一个低效的问题。在马尔可夫链中,当我们需要潜在样本 x t \mathbf{x}_t xt 时,我们必须在马尔可夫链中执行 t − 1 t-1 t−1 步。
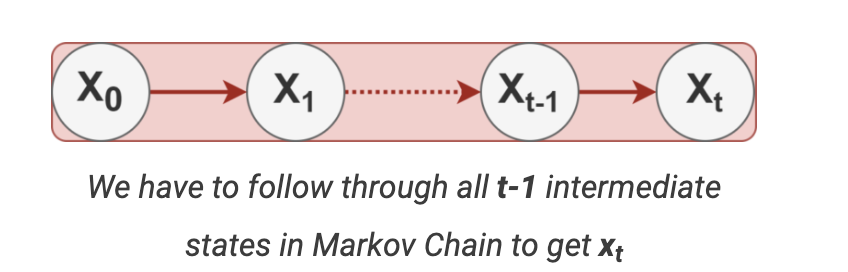
为了解决这个问题,作者优化了步骤,直接从 timesteps = 0(即
x
0
\mathbf{x}_0
x0) 推导到扩散过程中的
x
t
\mathbf{x}_t
xt。
接下来,我们可以了解如何用数学来解释这个扩散过程。给定当前具有一定噪声的图像 x t − 1 \mathrm{x}_{t-1} xt−1, 加入标准高斯噪声噪声 ϵ t − 1 ∼ \mathrm{\epsilon}_{t-1}\sim ϵt−1∼ N ( 0 , I ) \mathcal{N}(0,\mathbf{I}) N(0,I), 得到进一步加噪的图像 x t \mathbf{x}_t xt, 我们可以建模成:
x t = a t x t − 1 + b t ϵ t , ϵ t ∼ N ( 0 , I ) (1) \mathrm{x}_t=a_t\mathrm{x}_{t-1}+b_t\mathrm{\epsilon}_t,\quad\boldsymbol{\epsilon}_t\sim\mathcal{N}(\mathbf{0},\mathbf{I}) \tag{1} xt=atxt−1+btϵt,ϵt∼N(0,I)(1)
因为 x t − 1 \mathrm{x}_{t-1} xt−1 具有的信息更多,因此 a t a_t at 是一个衰减系数,值应该满足 0 < a t < 1 0<a_t<1 0<at<1 ; 同样的噪声系数也满足 0 < b t < 1 0<b_t<1 0<bt<1 。
当我们用 x t − 1 = a t − 1 x t − 2 + b t − 1 ϵ t − 1 \mathbf{x}_{t-1}=a_{t-1}\mathbf{x}_{t-2}+b_{t-1}\boldsymbol{\epsilon}_{t-1} xt−1=at−1xt−2+bt−1ϵt−1 不断展开这个式子, 可以得到:
x
t
=
a
t
x
t
−
1
+
b
t
ϵ
t
=
a
t
(
a
t
−
1
x
t
−
2
+
b
t
−
1
ϵ
t
−
1
)
+
b
t
ϵ
t
=
a
t
a
t
−
1
x
t
−
2
+
a
t
b
t
−
1
ϵ
t
−
1
+
b
t
ϵ
t
=
…
=
(
a
t
…
a
1
)
x
0
+
(
a
t
…
a
2
)
b
1
ϵ
1
+
(
a
t
…
a
3
)
b
2
ϵ
2
+
⋯
+
a
t
b
t
−
1
ϵ
t
−
1
+
b
t
ϵ
t
(2)
除了第一项,后面是多个独立正态分布的的和。 前面有说 ϵ \epsilon ϵ 其实是标准高斯噪声,那么 ϵ i \epsilon_i ϵi 本质上是同属于一个分布 N ( 0 , I ) \mathcal{N}(0,\mathbf{I}) N(0,I) 下的 不同采样。
利用叠加性,他们的和也是一个正态分布,均值为 0, 方差为 ( a t … a 2 ) 2 b 1 2 + ( a t … a 3 ) 2 b 2 2 + ⋯ + a t 2 b t − 1 2 + b t 2 . (a_t\ldots a_2)^2b_1^2+(a_t\ldots a_3)^2b_2^2+\cdots+a_t^2b_{t-1}^2+b_t^2. (at…a2)2b12+(at…a3)2b22+⋯+at2bt−12+bt2.
这样原表达式可以写成
x
t
=
(
a
t
…
a
1
)
x
0
+
(
a
t
…
a
2
)
2
b
1
2
+
(
a
t
…
a
3
)
2
b
2
2
+
⋯
+
a
t
2
b
t
−
1
2
+
b
t
2
ϵ
ˉ
t
,
ϵ
ˉ
t
∼
N
(
0
,
I
)
(3)
重参数化技巧
对高斯分布 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2) 进行采样一个噪声,等价于先从标准高斯分布 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1) 中采样的到一个噪声 z \mathbf{z} z, 乘上标准差 σ \sigma σ,再加上均值 μ \mu μ , 即: ϵ = μ + z ⋅ σ \epsilon=\mu+\mathbf{z} \cdot \sigma ϵ=μ+z⋅σ
这里有一个细节,如果我们把系数的平方和都加起来
(
a
t
…
a
1
)
2
+
(
a
t
…
a
2
)
2
b
1
2
+
(
a
t
…
a
3
)
2
b
2
2
+
⋯
+
a
t
2
b
t
−
1
2
+
b
t
2
=
(
a
t
…
a
2
)
2
a
1
2
+
(
a
t
…
a
2
)
2
b
1
2
+
(
a
t
…
a
3
)
2
b
2
2
+
⋯
+
a
t
2
b
t
−
1
2
+
b
=
(
a
t
…
a
2
)
2
(
a
1
2
+
b
1
2
)
+
(
a
t
…
a
3
)
2
b
2
2
+
⋯
+
a
t
2
b
t
−
1
2
+
b
t
2
=
(
a
t
…
a
3
)
2
(
a
2
2
(
a
1
2
+
b
1
2
)
+
b
2
2
)
+
⋯
+
a
t
2
b
t
−
1
2
+
b
t
2
=
a
t
2
(
a
t
−
1
2
(
…
(
a
2
2
(
a
1
2
+
b
1
2
)
+
b
2
2
)
+
…
)
+
b
t
−
1
2
)
+
b
t
2
(4)
我们发现,如果加一个约束 a t 2 + b t 2 = 1 a_t^2 + b_t^2 = 1 at2+bt2=1 ,上面括号里的平方和就为 1 了。同时如果我们记 a ˉ t = ( a t … a 1 ) 2 \bar{a}_t=(a_t\ldots a_1)^2 aˉt=(at…a1)2 , 那么平方和的后面部分,即式 ( 3 ) (3) (3)的方差部分,就可以表示为 1 − a ˉ t 1 - \bar{a}_t 1−aˉt 。 那么式 ( 3 ) (3) (3) 就可以改写:
x t = a ˉ t x 0 + 1 − a ˉ t ϵ ˉ t , ϵ ˉ t ∼ N ( 0 , I ) (5) \mathbf{x}_t=\sqrt{\bar{a}_t}\mathbf{x}_0+\sqrt{1-\bar{a}_t}\bar{\boldsymbol{\epsilon}}_t,\quad\bar{\boldsymbol{\epsilon}}_t\sim\mathcal{N}(\mathbf{0},\mathbf{I}) \tag{5} xt=aˉt x0+1−aˉt ϵˉt,ϵˉt∼N(0,I)(5)
- 我们把 a a a 替换成 α \alpha α
x t = α ˉ t x 0 + 1 − α ˉ t ϵ ˉ t , ϵ ˉ t ∼ N ( 0 , I ) (6) \mathbf{x}_t=\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\bar{\boldsymbol{\epsilon}}_t,\quad\bar{\boldsymbol{\epsilon}}_t\sim\mathcal{N}(\mathbf{0},\mathbf{I}) \tag{6} xt=αˉt x0+1−αˉt ϵˉt,ϵˉt∼N(0,I)(6)
- 接着写出式 ( 6 ) (6) (6) 对应的概率形式
x t ∼ q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) , α ˉ t = ∏ i = 1 t α i (7) \mathbf{x}_t\sim q(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\sqrt{\bar{\alpha}_t}\mathbf{x}_0,(1-\bar{\alpha}_t)\mathbf{I}),\quad\bar{\alpha}_t=\prod_{i=1}^t\alpha_i \tag{7} xt∼q(xt∣x0)=N(xt;αˉt x0,(1−αˉt)I),αˉt=i=1∏tαi(7)
到这里已经是和原论文一致了。这里花一定篇幅来讲解 α \alpha α 和 β \beta β 的系数设置;
同时还有对于均值 α t \sqrt\alpha_t α t 的设置 ,很多博客的观点如下:
- T → ∞ , x T ∼ N ( 0 , I ) T\to\infty\textit{,}x_T\sim\mathcal{N}(0,\mathbf{I}) T→∞,xT∼N(0,I) ,最后是一个标准正态分布,因此前一项的接近0,后项应该设计成一个 1 − α t \sqrt{1 - \alpha_t} 1−αt 的形式。
- α t \sqrt\alpha_t α t 的系数能够稳定保证最后收敛到方差为1的标准高斯分布;
我觉得对于我来说更多的是推导的简洁优雅。毕竟是先有假设 a t 2 + b t 2 = 1 a_t^2 + b_t^2 = 1 at2+bt2=1 , 才会有最后的结果。
整个前向过程是一个后验估计,被表示为:(根据联合概率密度+马尔可夫链性质)
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) (8) q(\mathbf{x}_{1:T}|\mathbf{x}_0)=\prod_{t=1}^Tq(\mathbf{x}_t|\mathbf{x}_{t-1}) \tag{8} q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)(8)
反向过程
扩散过程是从原始数据 x 0 \mathbf{x}_{0} x0 逐渐添加噪声得到 x T \mathbf{x}_{T} xT 。 逆扩散过程就是从 x T \mathbf{x}_{T} xT 逐步去噪得到 x 0 \mathbf{x}_{0} x0,即求:
q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_t) q(xt−1∣xt)
那么 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_t) q(xt−1∣xt) 怎么求呢?
首先加噪过程中 q ( x t ∣ x t − 1 ) q(\mathbf{x}_{t}\mid\mathbf{x}_{t-1}) q(xt∣xt−1) 我们是知道的,因此根据贝叶斯公式有
q ( x t − 1 ∣ x t ) = q ( x t ∣ x t − 1 ) × q ( x t − 1 ) q ( x t ) (9) q(\mathbf{x}_{t-1}\mid\mathbf{x}_t)=\frac{q(\mathbf{x}_t\mid\mathbf{x}_{t-1})\times q(\mathbf{x}_{t-1})}{q(\mathbf{x}_t)} \tag{9} q(xt−1∣xt)=q(xt)q(xt∣xt−1)×q(xt−1)(9)
补充贝叶斯公式:
P ( A ∣ B ) = P ( B ∣ A ) × P ( A ) P ( B ) P(A|B)=\frac{P(B|A)\times P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)×P(A)
多变量贝叶斯公式
P ( A ∣ B , C ) = P ( A , B , C ) / P ( B , C ) P(A|B,C)=P(A,B,C)/P(B,C) P(A∣B,C)=P(A,B,C)/P(B,C)
贝叶斯公式实现了概率反转,即由 P ( B ∣ A ) P(B|A) P(B∣A) 得到 P ( A ∣ B ) P(A|B) P(A∣B)
现在问题是 q ( x t ) q(\mathbf{x}_{t}) q(xt) 和 q ( x t − 1 ) q(\mathbf{x}_{t-1}) q(xt−1) 不知道。当 T T T 足够大的时候, q ( x T ) q(\mathbf{x}_{T}) q(xT) 可以认为就是标准高斯噪声。但是我们并不知道具体的某个样本的值包含多少图像信息,因此我们我们是无法知道 q ( x t ) q(\mathbf{x}_{t}) q(xt) 的。
要想知道 q ( x t ) q(\mathbf{x}_{t}) q(xt) 和 q ( x t − 1 ) q(\mathbf{x}_{t-1}) q(xt−1) ,自然就依赖于一个先决条件,没加噪声的图像 q ( x 0 ) q(\mathbf{x}_{0}) q(x0) 。换句话说, q ( x t ∣ x 0 ) q(\mathbf{x}_{t}\mid\mathbf{x}_0) q(xt∣x0) 和 q ( x t − 1 ∣ x 0 ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_0) q(xt−1∣x0) 我们是知道的。如果我们在 式 ( 9 ) (9) (9) 再加上一个条件 x 0 \mathbf{x}_{0} x0 , 将求解 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_t) q(xt−1∣xt) 转换成求解 q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_t, \mathbf{x}_0) q(xt−1∣xt,x0) 。这样可以得到多元条件分布
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
−
1
,
x
t
,
x
0
)
q
(
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
∣
x
0
)
q
(
x
0
)
q
(
x
t
∣
x
0
)
(10)
- 由于扩散过程是一个马尔可夫过程, x t \mathbf{x}_{t} xt 只和前一个状态 x t − 1 \mathbf{x}_{t-1} xt−1 有关,和 x 0 \mathbf{x}_{0} x0 无关;
- 另外 x 0 \mathbf{x}_{0} x0 是原始样本,是已知的;
那么继续求解 式 ( 10 ) (10) (10) 有
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) (11) q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0) =q(\mathbf{x}_t|\mathbf{x}_{t-1})\frac{q(\mathbf{x}_{t-1}|\mathbf{x}_0)}{q(\mathbf{x}_t|\mathbf{x}_0)} \tag{11} q(xt−1∣xt,x0)=q(xt∣xt−1)q(xt∣x0)q(xt−1∣x0)(11)
那么如何求解 式 ( 11 ) (11) (11) 呢?
现在我们存在一个问题,在反向去噪过程中,根据 式 ( 11 ) (11) (11) ,我们发现从 x t \mathbf{x}_{t} xt 推断 x t − 1 \mathbf{x}_{t-1} xt−1 需要建立在 x 0 \mathbf{x}_{0} x0 已知的情况。但去噪过程中, x 0 \mathbf{x}_{0} x0 本身就是我们需要去求解的东西。所以我们需要进一步拆解上述式子。「看看能不能把 x 0 \mathbf{x}_0 x0 消除掉」 。如果消除掉,就不用陷入这种求 x 0 \mathbf{x}_0 x0 必须知道 x 0 \mathbf{x}_0 x0 的困境了。
-
q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}|\mathbf{x}_t) q(xt−1∣xt) 等价于 x t = α t x t − 1 + 1 − α t ϵ t \mathbf{x}_t=\sqrt{\alpha_t}\mathbf{x}_{t-1}+\sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t} xt=αt xt−1+1−αt ϵt 。 写成分布的形式,有 N ( x t ; α t x t − 1 , 1 − α t I ) \mathcal{N}(\mathbf{x}_t;\sqrt{\alpha_t}\mathbf{x}_{t-1},1 - \alpha_t\mathbf{I}) N(xt;αt xt−1,1−αtI) 。 进一步写成概率密度函数的形式, q ( x t − 1 ∣ x t ) ∝ exp ( − 1 2 ( x t − α t x t − 1 ) 2 1 − α t ) = exp ( − 1 2 ( x t − α t x t − 1 ) 2 β t ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_{t})\propto\exp(-\frac{1}{2}\frac{(\mathbf{x}_t-\sqrt{\alpha_t}\mathbf{x}_{t-1})^2}{1-\alpha_t})=\exp(-\frac{1}{2}\frac{(\mathbf{x}_t-\sqrt{\alpha_t}\mathbf{x}_{t-1})^2}{\beta_t}) q(xt−1∣xt)∝exp(−211−αt(xt−αt xt−1)2)=exp(−21βt(xt−αt xt−1)2) 。
-
q ( x t − 1 ∣ x 0 ) q(\mathbf{x}_{t-1}|\mathbf{x}_0) q(xt−1∣x0) 等价于 x t = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ ˉ t − 1 \mathbf{x}_t=\sqrt{ \bar\alpha_{t-1}}\mathbf{x}_{0}+\sqrt{1 - \bar\alpha_{t-1}}\mathbf{\bar\epsilon}_{t-1} xt=αˉt−1 x0+1−αˉt−1 ϵˉt−1 。 写成分布的形式,有 N ( x t − 1 ; α ˉ t − 1 x 0 , 1 − α ˉ t I ) \mathcal{N}(\mathbf{x}_{t-1};\sqrt{ \bar\alpha_{t-1}}\mathbf{x}_{0},1 - \bar\alpha_t\mathbf{I}) N(xt−1;αˉt−1 x0,1−αˉtI) 。 进一步写成概率密度函数的形式, q ( x t − 1 ∣ x 0 ) ∝ exp ( − 1 2 ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 ) 。 q(\mathbf{x}_{t-1}\mid\mathbf{x}_{0})\propto\exp(-\frac{1}{2}\frac{(\mathbf{x}_{t-1}-\sqrt{\bar\alpha_{t-1}}\mathbf{x}_{0})^2}{1-\bar\alpha_{t-1}})。 q(xt−1∣x0)∝exp(−211−αˉt−1(xt−1−αˉt−1 x0)2)。
-
q ( x t ∣ x 0 ) q(\mathbf{x}_{t}|\mathbf{x}_0) q(xt∣x0) 等价于 x t = α ˉ t x 0 + 1 − α ˉ t ϵ t \mathbf{x}_t=\sqrt{\bar\alpha_t}\mathbf{x}_{0}+\sqrt{1 - \bar\alpha_t}\boldsymbol{\epsilon}_{t} xt=αˉt x0+1−αˉt ϵt 。 写成分布的形式,有 N ( x t ; α ˉ t x 0 , 1 − α ˉ t I ) \mathcal{N}(\mathbf{x}_t;\sqrt{\bar\alpha_t}\mathbf{x}_{0},1 - \bar\alpha_t\mathbf{I}) N(xt;αˉt x0,1−αˉtI) 。 进一步写成概率密度函数的形式, q ( x t ∣ x 0 ) ∝ exp ( − 1 2 ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) q(\mathbf{x}_{t}\mid\mathbf{x}_{0})\propto\exp(-\frac{1}{2}\frac{(\mathbf{x}_t-\sqrt{\bar\alpha_t}\mathbf{x}_{0})^2}{1-\bar\alpha_t}) q(xt∣x0)∝exp(−211−αˉt(xt−αˉt x0)2) 。
这里为什么要把概率密度函数的形式给拿出来呢?其实是方便运算。
因此 q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 ) × q ( x t − 1 ∣ x 0 ) ÷ q ( x t ∣ x 0 ) q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0) =q(\mathbf{x}_t|\mathbf{x}_{t-1}) \times q(\mathbf{x}_{t-1}|\mathbf{x}_0) \div q(\mathbf{x}_t|\mathbf{x}_0) q(xt−1∣xt,x0)=q(xt∣xt−1)×q(xt−1∣x0)÷q(xt∣x0),写成密度函数的形式为有
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
∝
exp
(
−
1
2
(
(
x
t
−
α
t
x
t
−
1
)
2
β
t
+
(
x
t
−
1
−
α
ˉ
t
−
1
x
0
)
2
1
−
α
ˉ
t
−
1
−
(
x
t
−
α
ˉ
t
x
0
)
2
1
−
α
ˉ
t
)
)
=
exp
(
−
1
2
(
x
t
2
−
2
α
t
x
t
x
t
−
1
+
α
t
x
t
−
1
2
β
t
+
x
t
−
1
2
−
2
α
ˉ
t
−
1
x
0
x
t
−
1
+
α
ˉ
t
−
1
x
0
2
1
−
α
ˉ
t
−
1
−
(
x
t
−
α
ˉ
t
x
0
)
2
1
−
α
ˉ
t
)
)
=
exp
(
−
1
2
(
α
t
β
t
+
1
1
−
α
ˉ
t
−
1
)
x
t
−
1
2
−
(
2
α
t
β
t
x
t
+
2
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
x
t
−
1
+
C
(
x
t
,
x
0
)
)
tips: 技巧性化简,我们所有的转换、化简都是为了求关于 x t − 1 \mathbf{x}_{t-1} xt−1 的条件分布 q ( x t − 1 ∣ x 0 , x 0 ) q(\mathbf{x}_{t-1}\mid{\mathbf{x}_0, \mathbf{x}_0}) q(xt−1∣x0,x0) 。基于此,所以我们把 x t − 1 \mathbf{x}_{t-1} xt−1 给提取出来
C ( x t , x 0 ) = x t 2 − 2 α ˉ t x 0 x t + α ˉ t x 0 2 1 − α ˉ t C(\mathbf{x}_t,\mathbf{x}_0) = \frac{\mathbf{x}_t^2-2\sqrt{\bar{\alpha}_t}\mathbf{x}_0\mathbf{x}_t+\bar{\alpha}_t\mathbf{x}_0^2}{1-\bar{\alpha}_t} C(xt,x0)=1−αˉtxt2−2αˉt x0xt+αˉtx02
C ( x t , x 0 ) C(\mathbf{x}_t,\mathbf{x}_0) C(xt,x0) 为不涉及 x t − 1 \mathbf{x}_{t-1} xt−1 的项,所以忽略
那么上面这个整理的式子究竟有什么用呢? 回顾下,以 x x x 为自变量的高斯分布 N ( x ; μ , σ 2 ) \mathcal{N}(\mathbf{x};\mu, \sigma^2) N(x;μ,σ2) , 其概率密度函数正比于 exp ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) \exp(-\frac12\left.\left(\frac1{\sigma^2}\right.x^2-\frac{2\mu}{\sigma^2}\left.x+\frac{\mu^2}{\sigma^2}\right)\right) exp(−21(σ21x2−σ22μx+σ2μ2)) 。可以发现, 上面式子中 x t − 1 2 \mathbf{x}_{t-1}^2 xt−12 与 x t − 1 \mathbf{x}_{t-1} xt−1 的系数,其中就包含了 q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0) q(xt−1∣xt,x0) 的均值和方差的信息。
我们发现 方差 σ 2 \sigma^2 σ2 就是 x 2 x^2 x2 的系数的倒数。而 x t − 1 2 \mathbf{x}_{t-1}^2 xt−12 的系数为 ( α t β t + 1 1 − α ˉ t − 1 ) (\frac{\alpha_t}{\beta_t}+\frac1{1-\bar{\alpha}_{t-1}}) (βtαt+1−αˉt−11) ,完全只由人工确定的超参数 α \alpha α 和 β \beta β 确定。因此方差是确定的,但是均值与 x t − 1 \mathbf{x}_{t-1} xt−1 的系数 ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) (\frac{2\sqrt{\alpha_t}}{\beta_t}x_t+\frac{2\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}}x_0) (βt2αt xt+1−αˉt−12αˉt−1 x0) 有关。可以发现,除了已知量 α \alpha α 、 β \beta β 和 x t \mathbf{x}_{t} xt ,依然包含着我们想要消除的项 x 0 \mathbf{x}_{0} x0 。
我们先整理一下有( α t + β t = 1 \alpha_t + \beta_t = 1 αt+βt=1 and α ˉ t = ∏ i = 1 T α i \bar{\alpha}_t=\prod_{i=1}^T\alpha_i αˉt=∏i=1Tαi):
1 σ 2 = α t β t + 1 1 − α ˉ t − 1 = α t − α ˉ t + β t β t ( 1 − α ˉ t − 1 ) = 1 − α ˉ t β t ( 1 − α ˉ t − 1 ) (13) \frac{1}{\sigma^2} = \frac{\alpha_t}{\beta_t}+\frac1{1-\bar{\alpha}_{t-1}} = \frac{\alpha_t-\bar{\alpha}_t+\beta_t}{\beta_t(1-\bar{\alpha}_{t-1})} = \frac{1 - \bar{\alpha}_t }{\beta_t(1-\bar{\alpha}_{t-1})} \tag{13} σ21=βtαt+1−αˉt−11=βt(1−αˉt−1)αt−αˉt+βt=βt(1−αˉt−1)1−αˉt(13)
⟹ σ 2 = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t (13-1) \Longrightarrow {\sigma^2} = \color{green}{\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\cdot\beta_t} \tag{13-1} ⟹σ2=1−αˉt1−αˉt−1⋅βt(13-1)
2
μ
σ
2
=
(
2
α
t
β
t
x
t
+
2
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
(14)
⟹
μ
=
(
α
t
β
t
x
t
+
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
⋅
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
⋅
β
t
=
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
x
0
(14-1)
现在 μ \mu μ 是一个只关于 x 0 \mathbf{x}_{0} x0 和 x t \mathbf{x}_{t} xt 的式子。我们记做 μ ~ t ( x t , x 0 ) \tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t,\mathbf{x}_0) μ~t(xt,x0) , 简化为 μ ~ t \tilde{\boldsymbol{\mu}}_t μ~t ;
前面说了在反向扩散阶段, x 0 \mathbf{x}_{0} x0 是不知道的。但是根据 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) \mathbf{x}_0=\frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t-\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}_t) x0=αˉt 1(xt−1−αˉt ϵt) ,有
μ
~
t
=
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
ϵ
t
)
=
(
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
1
α
ˉ
t
)
x
t
−
1
−
α
t
1
−
α
ˉ
t
⋅
α
t
ϵ
t
=
(
α
t
−
α
ˉ
t
α
t
⋅
(
1
−
α
ˉ
t
)
+
1
−
α
t
(
1
−
α
ˉ
t
)
⋅
α
t
)
x
t
−
1
−
α
t
1
−
α
ˉ
t
⋅
α
t
ϵ
t
=
1
α
t
(
x
t
−
1
−
α
t
1
−
α
ˉ
t
ϵ
t
)
到这一步,我们已经把 x 0 \mathbf{x}_{0} x0 给消掉了。只要知道了 ϵ t \boldsymbol{\epsilon}_t ϵt , 我们就可以把 μ ~ t \tilde{\boldsymbol{\mu}}_t μ~t 给算出来,进而得到 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}\mid\mathbf{x}_t) q(xt−1∣xt),采样出 x t − \mathbf{x}_{t-} xt−,完成去噪的过程。
参考
简单基础入门理解Denoising Diffusion Probabilistic Model,DDPM扩散模型
What are Diffusion Models?
由浅入深了解Diffusion Model

