
- 1CSS的属性【all:inherit】有什么奥秘?
- 2Git版本控制管理——分支_git show-branch
- 3php其他反序列化知识学习
- 4gitconfig 配置文件[credential]使用记录
- 5git clone 出现"error: RPC failed; curl 56 GnuTLS recv error (-9): A TLS packet with unexpected length ...
- 6java基于ssm奶茶店进销存系统_奶茶进销存
- 7【MySQL】数据的导入导出及.sql文件执行_导出数据库脚本的命令
- 8【字符集二】多字节字符vs宽字符
- 9[ project.config.json 文件内容错误] project.config.json: libVersion 字段需为
- 10IO多路复用之POLL【内附可运行代码注释完整】_c io复用 poll
使用 Apache PDFBox 操作PDF文件
赞
踩
简介
Apache PDFBox库是一个开源的Java工具,专门用于处理PDF文档。它允许用户创建全新的PDF文件,编辑现有的PDF文档,以及从PDF文件中提取内容。此外,Apache PDFBox还提供了一些命令行实用工具。

Apache PDFBox提供了创建、渲染、打印、合并、拆分、加密、解密、签名等多种操作PDF文件的功能。PDFBox还包括一个命令行工具,可以用于执行各种PDF处理任务。此外,它还支持文本提取和搜索,以及将PDF转换为其他格式,如图片和文本。PDFBox广泛应用于企业和开发者构建PDF处理相关的应用程序和工具。
Apache PDFBox具备以下主要功能:
- 从PDF文件中提取Unicode文本。
- 将单个PDF文件拆分成多个文件,或将多个PDF文件合并成一个。
- 从PDF表单中提取数据,或填写PDF表单。
- 验证PDF文件是否符合PDF/A-1b标准。
- 使用标准的Java打印API打印PDF文件。
- 将PDF文件另存为图像格式,如PNG或JPEG。
- 从零开始创建PDF文件,包括嵌入字体和图像。
- 对PDF文件进行数字签名。
导入
首先,我们需要确保已经将PDFBox库添加到我的Java项目中。如果你使用的是maven,那么在pom.xml中添加如下依赖:
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.28</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
这里使用的版本是:2.0.28。
Talk is cheap. Show me the code.
接下来,我们将通过代码示例展示如何使用Apache PDFBox来创建PDF文档、读取PDF文件、插入图片以及读取图片。
创建PDF文档
我们可以使用以下代码创建一个简单的PDF文档:
import java.io.File; import java.io.IOException; import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.pdmodel.PDPage; import org.apache.pdfbox.pdmodel.font.PDType1Font; public class CreatePDF { public static void main(String[] args) { PDDocument document = new PDDocument(); PDPage page = new PDPage(); document.addPage(page); PDType1Font font = PDType1Font.HELVETICA_BOLD; try { PDPageContentStream contentStream = new PDPageContentStream(document, page); contentStream.beginText(); contentStream.setFont(font, 12); contentStream.newLineAtOffset(100, 700); contentStream.showText("Hello, World!"); contentStream.endText(); contentStream.close(); document.save(new File("one-more.pdf")); document.close(); System.out.println("PDF created successfully."); } catch (IOException e) { e.printStackTrace(); } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
这个代码段创建一个新的PDF文档,并在其第一页上写入"Hello, World!"。我使用了Helvetica Bold字体,并将其大小设置为12。
接下来,我将文本显示在PDF页面上,并使用contentStream.close()方法关闭PDPageContentStream对象。
最后,我将文档保存为"one-more.pdf"文件,然后关闭PDDocument对象。效果如下图:
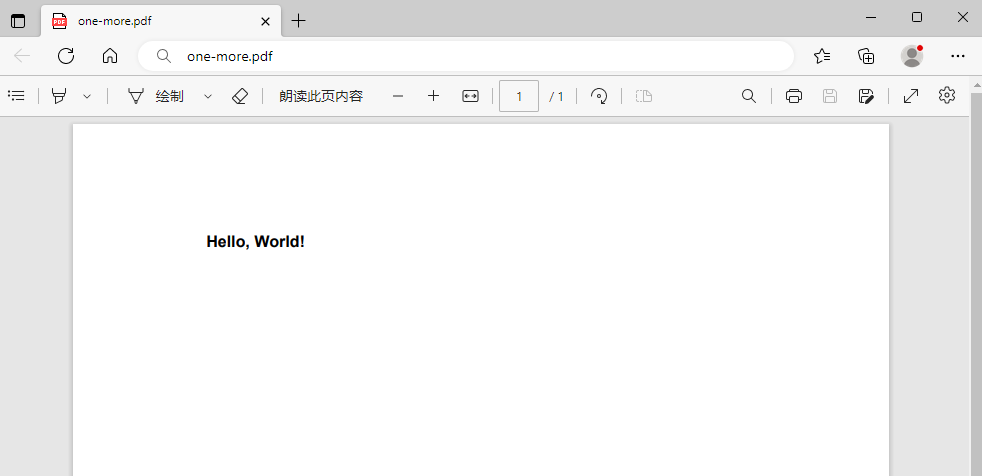
读取PDF文件
我们可以使用以下代码读取PDF文件中的全部内容:
import java.io.File; import java.io.IOException; import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.text.PDFTextStripper; public class ReadPDFExample { public static void main(String[] args) { // 创建文件对象 File file = new File("one-more.pdf"); try { // 创建 PDF 文档对象 PDDocument document = PDDocument.load(file); // 创建 PDF 文本剥离器 PDFTextStripper stripper = new PDFTextStripper(); // 获取 PDF 文件的全部内容 String text = stripper.getText(document); // 输出 PDF 文件的全部内容 System.out.println(text); // 关闭 PDF 文档对象 document.close(); } catch (IOException e) { e.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
首先,创建一个文件对象,然后使用 PDDocument 类的静态方法 load() 加载 PDF 文件并创建一个 PDF 文档对象。
然后,我们创建一个 PDFTextStripper 对象,并使用它的 getText() 方法获取 PDF 文件的全部内容。
最后,我们输出 PDF 文件的全部内容,并关闭 PDF 文档对象。
输出内容就是之前我们写入的:
Hello, World!
- 1
插入图片
我们可以使用以下代码在PDF文件中插入图片:
import java.io.File; import java.io.IOException; import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.pdmodel.PDPage; import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject; public class InsertImageInPDF { public static void main(String[] args) { try { // 加载PDF文件 PDDocument document = PDDocument.load(new File("one-more.pdf")); // 获取第一页 PDPage page = document.getPage(0); // 加载图像文件 PDImageXObject image = PDImageXObject.createFromFile("one-more.jpg", document); // 在指定位置插入图像 PDPageContentStream contentStream = new PDPageContentStream(document, page, AppendMode.APPEND, true, true); contentStream.drawImage(image, 200, 500, image.getWidth(), image.getHeight()); // 关闭流 contentStream.close(); // 保存修改后的PDF文件 document.save("one-more-jpg.pdf"); // 关闭文档 document.close(); System.out.println("PDF created successfully."); } catch (IOException e) { e.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
在这个例子中,我们加载了一个名为“one-more.pdf”的PDF文件,获取了第一页,并加载了一个名为“one-more.jpg”的图像文件。
然后,我们使用drawImage()方法在PDF文档中的指定位置插入了图像。
最后,我们将修改后的文档保存到名为“one-more-jpg.pdf”的新文件中,并关闭文档。效果如下图:
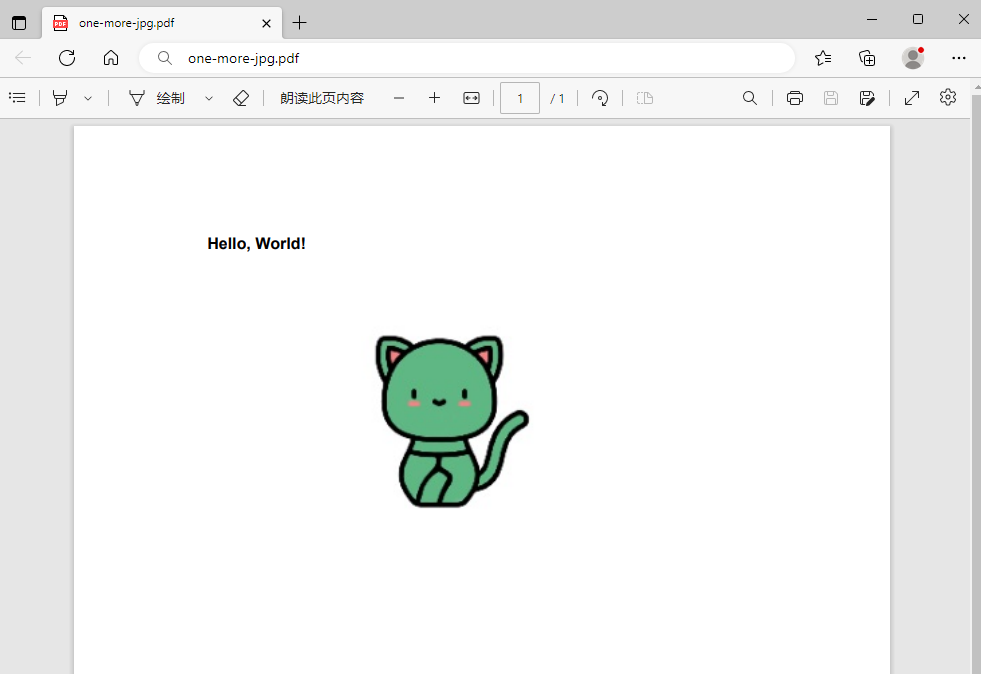
读取图片
我们可以使用以下代码在PDF文件中读取图片:
import java.io.IOException; import java.util.List; import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.pdmodel.PDPage; import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject; public class ReadPDFImagesExample { public static void main(String[] args) { try { // 加载PDF文件 PDDocument document = PDDocument.load(new File("one-more-jpg.pdf")); PDPageTree pageTree = document.getPages(); // 遍历每个页面 for (PDPage page : pageTree) { int pageNum = pageTree.indexOf(page) + 1; int count = 1; System.out.println("Page " + pageNum + ":"); for (COSName xObjectName : page.getResources().getXObjectNames()) { PDXObject pdxObject = page.getResources().getXObject(xObjectName); if (pdxObject instanceof PDImageXObject) { PDImageXObject image = (PDImageXObject) pdxObject; System.out.println("Found image with width " + image.getWidth() + "px and height " + image.getHeight() + "px."); String fileName = "one-more-" + pageNum + "-" + count + ".jpg"; ImageIO.write(image.getImage(), "jpg", new File(fileName)); count++; } } } document.close(); } catch (IOException e) { e.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
在此示例中,我们使用PDDocument类从指定的PDF文件中加载文档,并遍历每个页面以查找其中的图像。
对于每个页面,我们获取其资源(包括图像)并检查其中是否存在图像。
如果存在,则我们遍历它们,并使用PDImageXObject对象获取它们的属性,例如宽度和高度。
然后,使用ImageIO把图片保存到本地文件系统。
输出如下:
Page 1:
Found image with width 150px and height 150px.
- 1
- 2
结尾
Apache PDFBox 是一款功能丰富的工具,除了上述特性外,还有许多其他功能等待我们去探索和挖掘。如果您对 Apache PDFBox 有任何疑问或想了解更多功能,请随时在评论区向我提问,或者直接访问官方网站:https://pdfbox.apache.org/。

