
- 1机器学习之特征变换-标签和索引的转化_机器学习特征变换
- 2flutter go_router 官方路由(一)基本使用_go_router 用法
- 3华为OD机试真题(Java),根据员工出勤信息,判断本次是否能获得出勤奖(100%通过+复盘思路)_公司用一个字符串来表示员工的出勤信息:
- 4sql更新某个字段_sql更新某个字段的值
- 5vue ECharts 树图修改某节点样式,选中、聚焦改变节点样式等_echart tree 如果有子节点,显示加号
- 6YOLOv8分类识别训练配置详细_yolov8分类命令
- 7微信小程序 --- 事件处理
- 8selenium 下载文件取消安全下载的配置_selenium chrome已阻止不安全的下载
- 9PythonTF-IDF算法对文本进行统计词频_python使用文本数据的test.txt(每一行为一条新闻数据),使用自定义的tf-idf函数(词
- 10使用OpenAI Whipser开源模型实现长音频转录并结合GPT模型做文本翻译_开源语yin转文本
阿里首个MoE大模型Qwen1.5 MoE A2.7B:27亿参数MoE性能媲美70亿参数,推理速度提升74%_qwen2moe
赞
踩
前言
近期,阿里巴巴宣布开源其首个MoE(混合专家)技术大模型——Qwen1.5-MoE-A2.7B,这标志着阿里在人工智能领域的又一重大进展。Qwen1.5-MoE-A2.7B不仅在技术上有所创新,更在性能上实现了突破,其27亿参数的MoE模型在多个基准测试中的性能可以媲美传统的70亿参数模型,同时推理速度提升达到74%。
-
Huggingface模型下载:https://huggingface.co/Qwen
-
AI快站模型免费加速下载:https://aifasthub.com/models/Qwen
技术背景与模型简介
Qwen1.5-MoE-A2.7B模型采用混合专家技术,通过细粒度专家的设计、非从头训练的初始化方法和带有共享及路由专家的路由机制等多项技术创新,使模型在保持较小参数量的同时,能够激活并利用更加精细的计算资源。此模型总参数量为143亿,但每次推理只激活27亿参数,这种设计有效平衡了模型的性能与计算资源的使用效率。
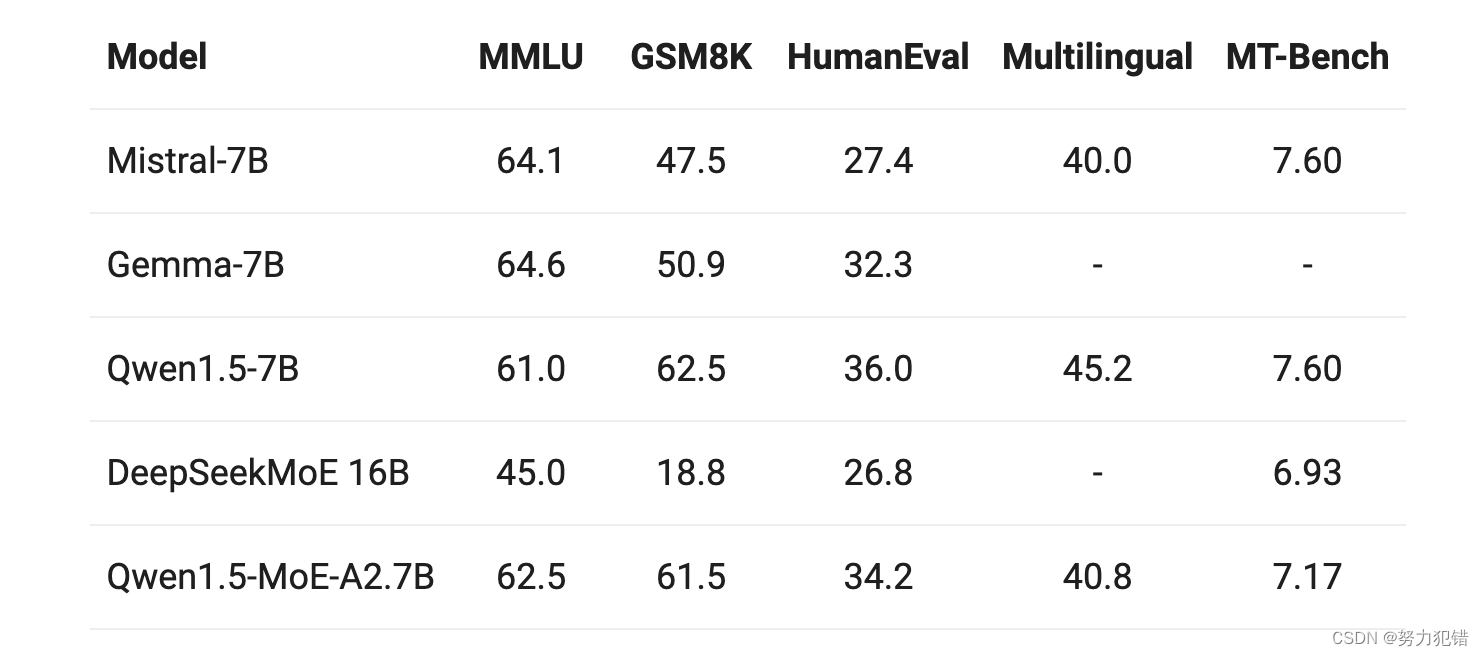
性能比较
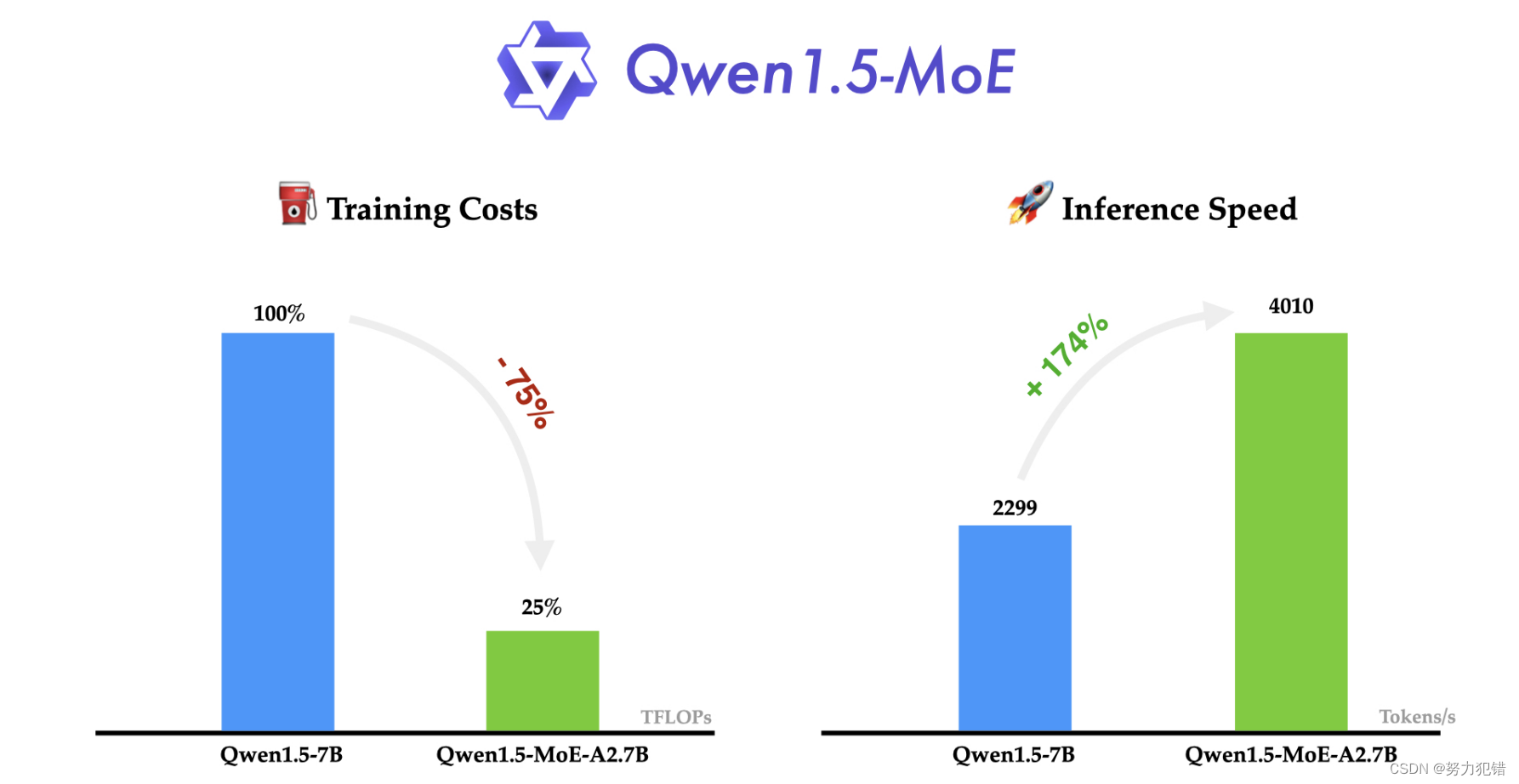
在公布的性能比较数据中,Qwen1.5-MoE-A2.7B模型与当前市场上同类70亿参数模型相比,在多个关键性能指标上均展现出了优秀的竞争力。特别是在推理速度上,该模型在NVIDIA A100-80G GPU上的生成速度可以达到每秒4000个tokens,显著超越了其他同类模型,充分展示了MoE技术在提高模型效率方面的强大潜力。
训练成本与推理效率
MoE模型的训练成本与dense模型存在显著差异。尽管MoE模型通常拥有更多的参数,但由于其稀疏性,训练开销可以显著降低。我们先对比各个模型的三个关键参数,分别是总参数数量、激活参数数量和Non-embedding参数:

不难看出,尽管Qwen1.5-MoE的总参数量较大,但Non-embedding激活参数量远小于7B模型。在实践中,观察到使用Qwen1.5-MoE-A2.7B相比于Qwen1.5-7B,训练成本显著降低了75%。
应用前景
Qwen1.5-MoE-A2.7B模型的开源,不仅对阿里自身在AI领域的技术积累和应用能力是一次重大提升,也为广大AI研究者和开发者提供了更多的可能性。借助此模型,用户可以在保持高性能的同时,有效降低计算资源消耗,为AI的广泛应用开辟了新的道路。
结论
通过对Qwen1.5-MoE-A2.7B模型的详细介绍和性能分析,我们可以看到,混合专家技术为AI模型的发展带来了新的视角和方法。阿里此次开源的Qwen1.5-MoE-A2.7B不仅在技术上有所创新,更在性能上实现了突破,为未来AI模型的发展方向提供了重要的参考。
模型下载
Huggingface模型下载
https://huggingface.co/Qwen
AI快站模型免费加速下载
https://aifasthub.com/models/Qwen


