
- 1浅谈阿里 Node 框架 Midway 在企业产品中的应用实践
- 2debezium系列之:理解database.server.name和database.history.kafka.topic
- 3SQL语言的组成_sql中列和行的组成
- 4IPv6 基本首部、地址和过渡_ipv6首部
- 5sql学习之:mysql里关于update from_mysql update from
- 6申请Adobe Firefly权限保姆级教程_adobe firefly is not available in your region.
- 7C++实现大津二值化算法_c++ 二值化图片
- 8JMeter--后置处理器--正则表达式提取器
- 9SSDP_ssdp 协议中,tcp 1900
- 10SQL难点对比分析:IN 和 EXISTS 的用法对比_sql in 和 exsit的差别
Youtube DNN
赞
踩
目录
1. 挑战
(1)规模。很多现有的推荐算法在小规模上效果好,但Youtobe规模很大。
(2)新颖度。Youtobe语料库是动态的,每秒都会有新视频,推荐系统需要能够模拟新上传的内容以及用户的最新行为。即探索和利用机制。
(3)噪音。Youtobe上的历史用户行为本来就很难预测,很少得到用户满意度的真实值,而是对有噪声的隐式反馈信号进行建模。
2. 系统整体结构
由召回和排序组成。召回对用户Youtobe的活动历史建模,从大型语料库中检索出一小部分视频,用户之间的相似度用粗糙的特征来表示,比如视频id,搜索查询token,人口统计数据;排序使用视频和用户的丰富特征,从召回结果里对视频进行打分。
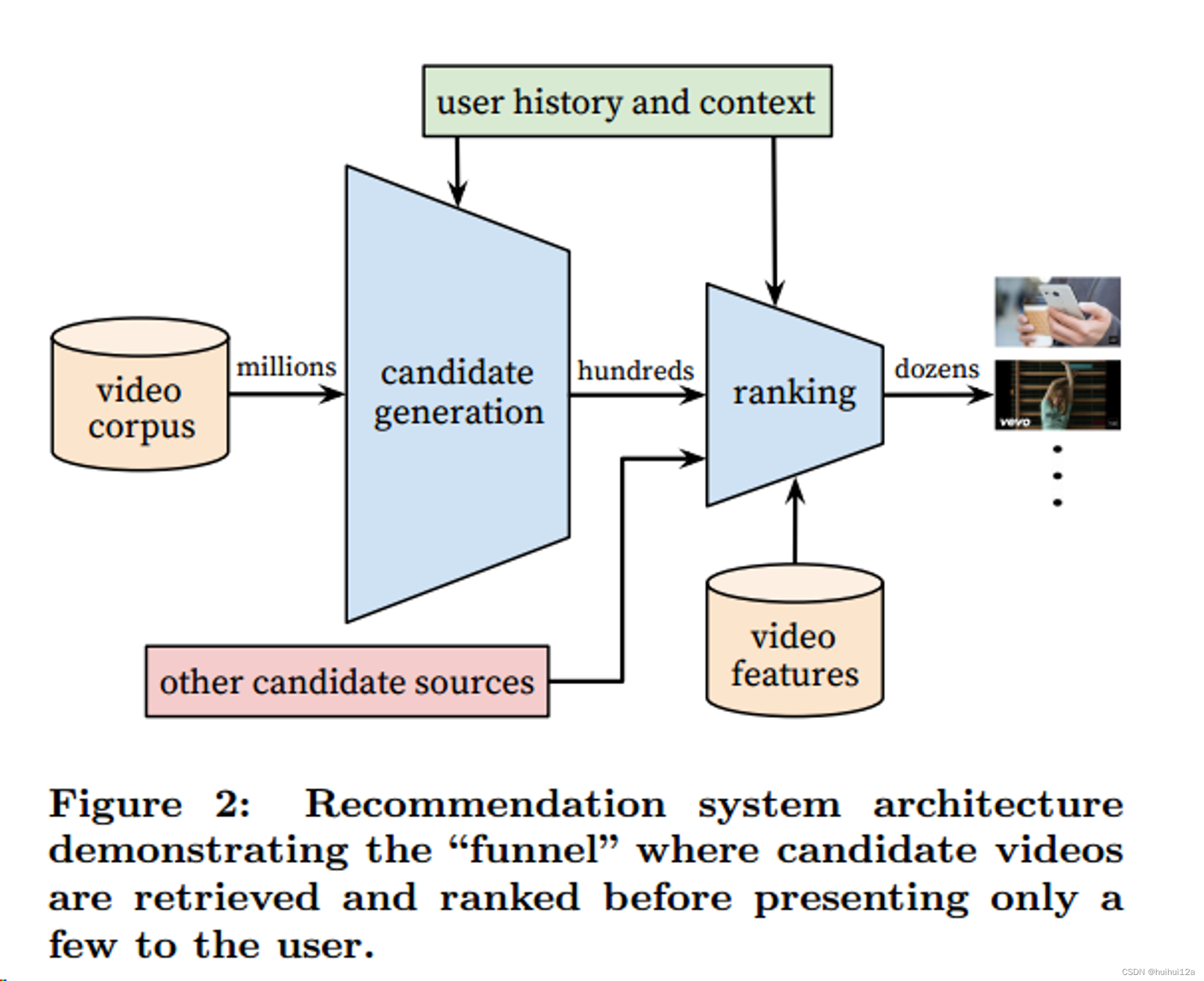
在开发过程中使用离线指标(precision,recall,ranking loss)指导系统的迭代。但是最终确定算法或模型的有效性,要通过现场实验进行A/B测试。在线上实验时,可以衡量CTR、观看时间和许多其他衡量用户粘性的指标,实时A.B测试的结果过不总是和离线实验相关。
3.召回
(1)召回建模为分类
将召回建模为分类问题。将推荐作为极端多分类问题:基于用户U和上下文信息C,在一个数百万的语料库V中,在t时刻准确的预测视频i(类别)。

深度神经网络的任务时学习用户的embedding(用户历史和上下文的函数)。
虽然Youtobe上存在显示的反馈(点赞、踩),作者采用隐式的观看数据去训练模型,这样选择是基于隐式的用户历史的数量级大,显示反馈很稀疏的也能有推荐的视频。
采用负采样技术,有效的训练具有数百万个类的模型,并使用重要性加权来纠正抽样,对于每个示例,真实标签和采样的负类,交叉熵最小。相比于原来的sotfmax分类,速度更快。
没有负采样前,每次迭代要更新所有参数,负采样后,每次迭代只用更新部分参数。
serving时需要计算最有可能的N个视频(类)呈现给用户,在serving时不需要softmax的校准似然,因此评分问题可以简化为点积空间的最近邻搜索,召回模型得到user和item的embedding后,通过embedding最近邻搜索进行模型服务。
(2)召回结构
-
输入层:输入的特征有用户的观看历史,用户搜索历史,用户的人口统计特征,以及example age
用户观看历史中的每个watch都被embedd,然后将用户观看历史行为embedd平均,代表用户的观看历史向量。
每个搜索query都被token化,每个token都被embedd,将tokens embedd平均代表了一个融合的用户历史搜索。
用户人口统计特征里的类别特征经过embedding拼接起来
连续特征归一化
将所有上述特征拼接起来
-
中间层,经过三层Relu激活函数的全连接层
-
输出层:使用softmax作为输出层。线下时是一个多分类(video)问题,并通过负采样技巧,最小化交叉熵损失,提升训练效率,加快训练速度
serving时使用最近邻搜索快速召回。视频embedding的生成:softamx层的参数本质上是一个m×n维的矩阵,m是指最后一层(Relu层)维度,n指的是分类总数(Youtube所有视频的总数),视频Embedding是m×n维矩阵的各列向量。
用户embedding:当输入用户u的特征向量时,最后一层ReLU层的输出向量可以当作该用户的Embedding向量,在模型训练完成后,逐个输入所有用户的特征向量,就可以在最后一个ReLU层得到所有用户的Embedding向量。
在预测某用户的视频候选集时,先得到改用的Embedding向量,再在视频Embedding向量空间中利用局部哈希等方法搜索到用户Embedding向量的Top K近邻,就可以得到k个候选视频集合。

使用深度学习代替矩阵分解的优势:任意的连续和类别特征可以很容易的加到模型中。
1)输入特征——输入层
- 搜索历史和观看历史
用户观看历史中的每个watch都被embedd,然后将用户观看历史行为embedd平均,代表用户的观看历史向量。
每个搜索query都被token化,每个token都被embedd,将tokens embedd平均代表了一个融合的用户历史搜索。
- 用户的人口统计特征
用户的人口统计特征可以提供先验信息。
用户的地理区域和设备被embedd并拼接起来,用户的性别、年龄、登录状态直接归一化到[0,1]之间输入到网络
- example age
把样本年龄作为特征训练模型能够准确的表示数据中观察到的上传时间和随时间变化的流行度。建模出视频热度随时间的变化情况
如果没有特征,模型将在训练窗口上预测大约的平均似然。
训练时,定义为训练样本产生的时刻距离当前时刻的时间。在serving时,该特征被设置为0(或略负),反映模型在训练窗口的最后进行预测。改特征本身不包含任何信息,但当该特征在深度神经网络中与其他特征做交叉时,起到了时间戳的作用,通过这个时间戳和其它特征的交叉,保存了其它特征随时间变化的权重,让最终预测包含时间趋势信息。
2)label and context selection
- 在解决推荐问题时,常用代理问题,将对应的结果转移到特定的场景,例如假设预测用户评分可以带来更好的推荐结果,代理问题选择对线上A/B测试重要,难以离线评估。
- 模型训练阶段,训练样本来自Youtube整个产品,而不仅仅是所有观看行为。否则的话推荐系统很难推荐出新的内容,系统会更多地偏向于利用。
- 给用户生成固定长度的训练样本,通过针对每个用户采用固定的长度的训练样本, 能够使得每个用户在损失函数中具有相同的权重, 这种方式防止活跃度高的用户对模型的损失影响较高。
- 丢弃搜索token的顺序信息。需要丢弃查询结果的序列信息, 通过无序的查询token集合来表示用户的查询历史, 使得分类器没有办法直接知道标签的来源。否则主页推荐结果可能全是用户刚刚查询的结果。
- 随机选择一个用户观看,并把观看之前的用户行为作为输入。许多协同过滤方法通过随机地保留一个项目, 然后从其他观影历史预测这个留出项来选择标签和上下文。 这种方法泄露了未来信息。
4. 排序
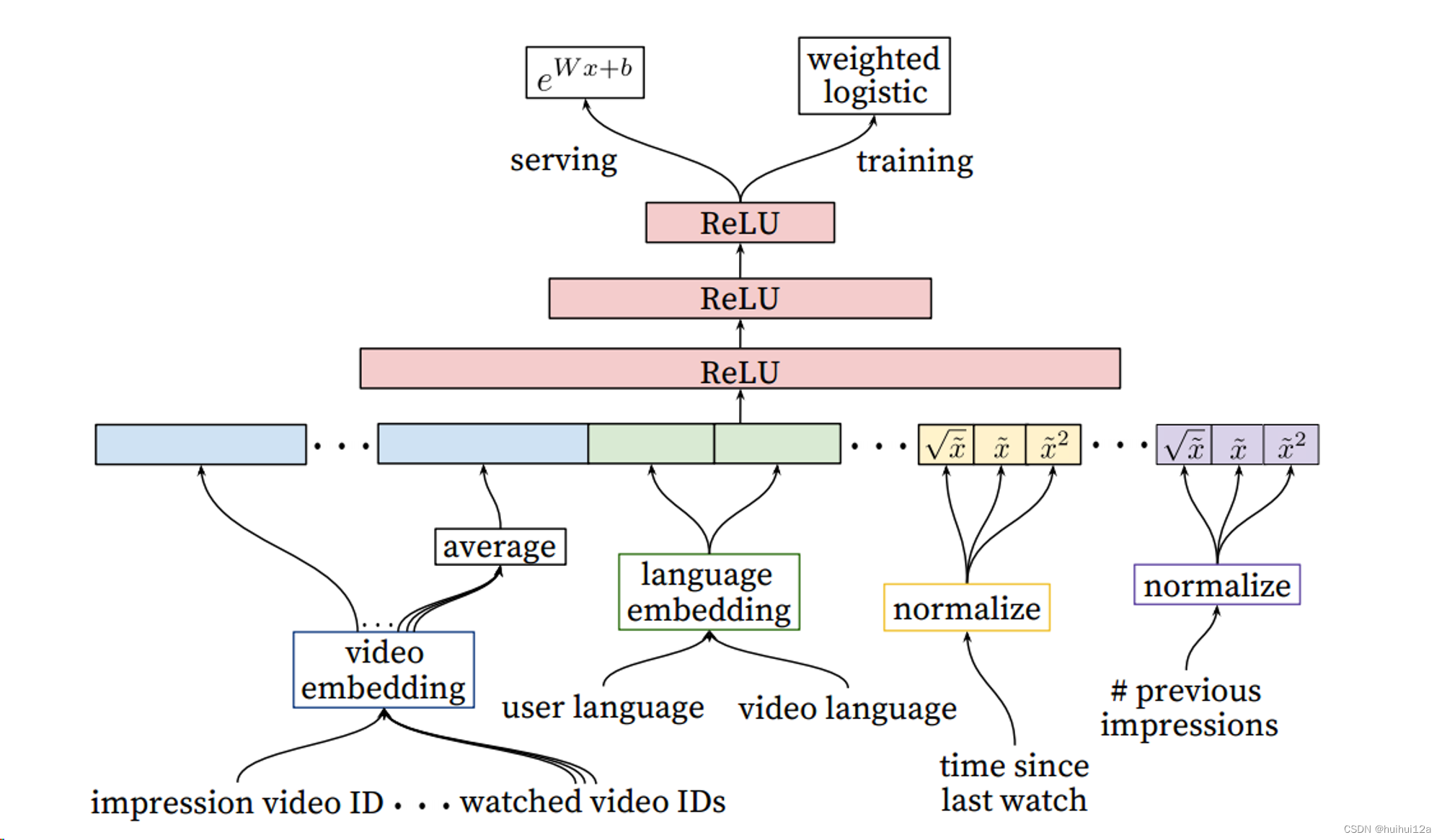
排序模型的结构和和召回模型很相似,但是输入和输出之间有些区别。相比于生成模型需要对几百万候选集进行粗筛,排序模型只需要对几百个候选视频进行排序,可以以内更多特征。
1)输入层特征
- 当前候选视频Embedding
- 用户观看过的最后N个视频Embedding的平均值
- 用户语言的Embedding和当前后续那视频语言的Embedding
- 该用户自上次观看同频道视频的时间
刚看过某个频道的视频,用户大概率会继续看
- 该候选视频已经曝光给用户的次数
避免同一视频对用户的持续无效曝光,尽量增加新用户看到新视频的可能性。
除了归一化的连续特征本身,还有这些连续特征的非线性变换,例如x^2,,引入特征的非线性,给网络更强的表达能力。
2)中间层
三层Relu网络
3)输出层
排序模型选择加权逻辑回归作为其输出层,模型服务阶段选择$e^{Wx+b}$函数。
从Youtube商业模式出发,增加用户观看时长才是其推荐系统最主要的优化目标,因此在训练排序模型时,每次曝光期望观看时长应该作为更合理的优化目标。为了可以直接预估观看时长,Youtube将正样本的观看时长作为其样本权重,负样本权重未单位权重,用加权逻辑回归进行训练,就可以让模型学到用户观看时长信息。


5. 训练和测试样本的处理
(1)召回模型把推荐问题转换为多分类问题。
在预测下一次观看时,整个视频物料都是候选类别。采用负采样训练方式减少了每次预测的分类数量,从而加快了整个模型的收敛速度,
(2)在对训练集的预处理过程重,没有采用原始用户日志,而是对每个用户提取等数量的训练样本。
减少高度活跃用户对模型损失的过度影响,使模型偏向活跃用户的行为模式,忽略更广大的长尾用户的体验。
(3)在处理测试集时,没有采用经典的留一法,而是以用户最近一次观看作为测试集。
避免引入未来信息,产生数据数据穿越问题。

