

DeepAugment是一个专注于数据扩充的自动化工具。 它利用贝叶斯优化来发现针对您的图像数据集定制的数据增强策略。 DeepAugment的主要优点和特点是:
- 降低CNN模型的错误率(WRN-28-10显示CIFAR10的错误率降低了60%)
- 通过自动化流程可以节省时间
- 比谷歌之前的解决方案——AutoAugment——快50倍
完成的包在PyPI上。你可以通过运行以下命令来在终端上安装它:
$ pip install deepaugment你也可以访问项目的自述文件或运行谷歌Colab笔记本教程。要想了解更多关于我是如何构建这个的,请继续阅读!
引言
数据是人工智能应用中最关键的部分。没有足够的标记数据常常导致过度拟合,这意味着模型将无法归纳为未发现的示例。这可以通过数据扩充来缓解,数据扩充可以有效地增加网络所看到的数据的数量和多样性。它是通过对原始数据集(如旋转、裁剪、遮挡等)应用转换,人为地生成新数据来实现的。然而,确定哪种增强对手头的数据集最有效并不是一项简单的任务。为了解决这个问题,谷歌去年发布了AutoAugment,它通过使用强化学习发现了给定数据集的优化增强。
由于强化学习模块的存在,使用谷歌的AutoAugment需要强大的计算资源。由于获得所需的计算能力代价高昂,因此我开发了一种新的方法——DeepAugment,它使用贝叶斯优化而不是强化学习。
如何获得更好的数据
努力改进数据质量通常比努力改进模型获得更高的投资回报。改进数据有三种主要方法:收集更多的数据、合成新数据或扩展现有数据。收集额外的数据并不总是可行的,而且可能很昂贵。GANs所做的数据合成是很有前途的,但也很复杂,可能与实际的例子有所不同。

另一方面,数据扩充简单且影响很大。它适用于大多数数据集,并通过简单的图像转换完成。然而,问题是确定哪种增强技术最适合当前的数据集。发现正确的方法需要耗时的实验。即使经过多次实验,机器学习(ML)工程师仍然可能找不到最佳选择。
对于每个图像数据集,有效的增强策略是不同的,一些增强技术甚至可能对模型有害。例如,如果使用MNIST digits数据集,应用旋转会使模型变得更糟,因为在“6”上180度旋转会使它看起来像“9”,而仍然被标记为“6”。另一方面,对卫星图像应用旋转可以显著改善结果,因为无论旋转多少次,从空中拍摄的汽车图像仍然是一辆汽车。
DeepAugment:闪电般迅速的autoML
DeepAugment旨在作为一种快速灵活的autoML数据扩充解决方案。更具体地说,它被设计为AutoAugment的更快和更灵活的替代品。(2018年Cubuk等人的博客)AutoAugment是2018年最令人兴奋的发布之一,也是第一种使用强化学习来解决这一特定问题的方法。在本文发表时,AutoAugment的开源版本没有提供控制器模块,这阻碍了用户为自己的数据集使用它。此外,学习增强策略需要15,000次迭代,这需要巨大的计算资源。即使源代码完全可用,大多数人也无法从中受益。
deepaugmented通过以下设计目标来解决这些问题:
1.在保证结果质量的前提下,最小化数据扩充优化的计算复杂度。
2.模块化和人性化。
为了实现第一个目标,与AutoAugment相比,DeepAugment的设计具有以下差异:
- 使用贝叶斯优化代替强化学习(需要更少的迭代)(~100x加速)
- 最小化子模型大小(降低每次训练的计算复杂度)(~20x加速)
- 减少随机扩充搜索空间设计(减少所需的迭代次数)
为了实现第二个目标,即使DeepAugment模块化和人性化,用户界面的设计方式为用户提供了广泛的可能性配置和模型选择(例如,选择子模型或输入自设计的子模型,请参阅配置选项)。
设计扩充策略
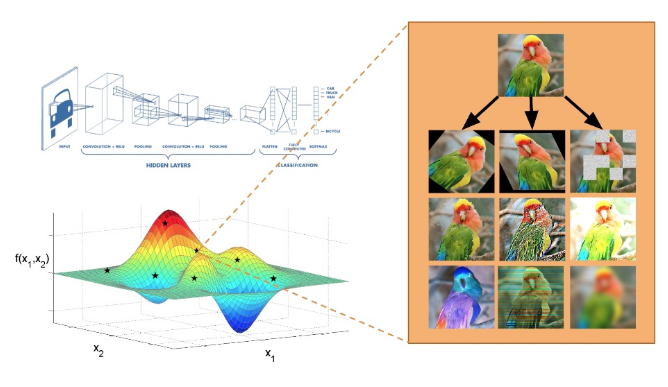
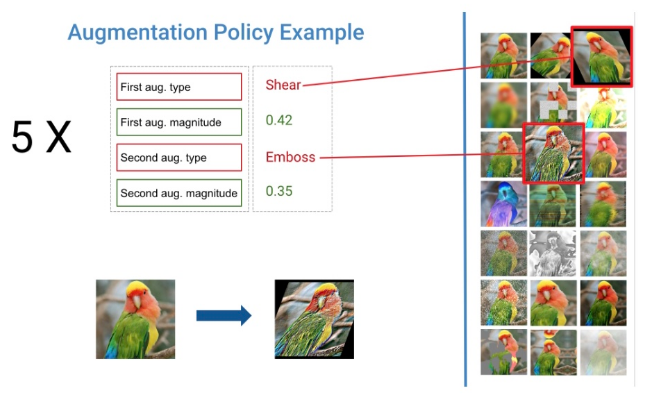
DeepAugment旨在为给定的图像数据集找到最佳的扩充策略。增强策略被定义为五个子策略的总和,这两个子策略由两种类型的增强技术和两个实值[0,1]组成,决定了每种增强技术的应用能力。我使用imgaug包实现了增强技术,imgaug包以其大量的增强技术(见下文)而闻名。

当多样化和随机应用时,增强是最有效的。例如,与其旋转每个图像,不如旋转图像的某些部分,剪切另一部分,然后对另一部分应用颜色反转。基于这一观察,Deepaugment对图像随机应用五个子策略之一(包括两个增强)。优化过程中,每个图像被五个子策略之一增强的概率(16%)相等,而完全不被增强的概率为20%。
虽然这个策略设计受到了autoaugmented的启发,但有一个主要的区别:我没有使用任何参数来应用子策略的概率,以便使策略的随机性更低,并允许在更少的迭代中进行优化。
这个策略设计为贝叶斯优化器创建了一个20维的搜索空间,其中10个维度是分类(增强技术的类型),其他10个维度是实值(大小)。由于涉及到分类值,我将贝叶斯优化器配置为使用随机森林估计器。
DeepAugment如何找到最佳策略
DeepAugment的三个主要组件是控制器(贝叶斯优化器),增强器和子模型,整个工作流程如下:控制器采样新的增强策略,增强器按新策略转换图像,子模型是通过增强图像从头开始训练。
根据子模型的训练历史计算奖励。奖励返回给控制器,控制器使用此奖励和相关的增强策略更新代理模型(请参阅下面的“贝叶斯优化如何工作”一节)。然后控制器再次采样新策略,并重复相同的步骤。此过程循环,直到达到用户确定的最大迭代次数。
控制器(贝叶斯优化器)是使用scikit- optimization库的ask-and-tell方法实现的。它被配置为使用一个随机森林估计器作为其基本估计器,并期望改进作为其获取函数。
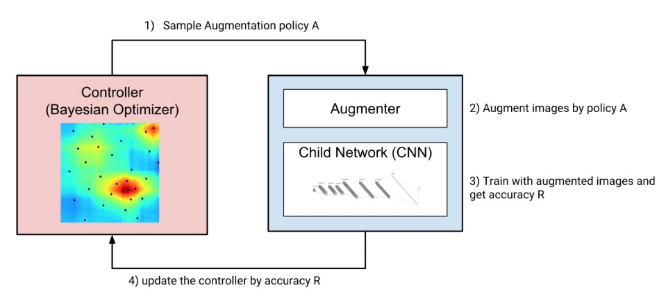
DeepAugment的基本工作流程
贝叶斯优化是如何工作的
贝叶斯优化的目的是找到一组最大化目标函数值的参数。 贝叶斯优化的工作循环可以概括为:
1.建立目标函数的代理模型
2.查找代理上执行得最好的参数
3.使用这些参数执行目标函数
4.使用这些参数和目标函数的得分更新代理模型
5.重复步骤2-4,直到达到最大迭代次数
有关贝叶斯优化的更多信息,请阅读高级的这篇解释的博客,或者看一下这篇综述文章。
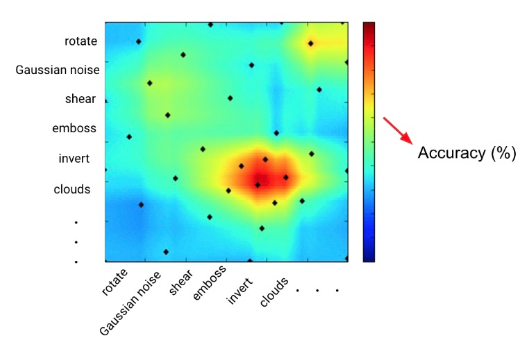
贝叶斯优化的二维描述,其中x和y轴表示增强类型,点(i,j)处的颜色表示用增强i和j所增强的数据进行训练时CNN模型的精度。
贝叶斯优化的权衡
目前用于超参数优化的标准方法有随机搜索、网格搜索、贝叶斯优化、进化算法和强化学习,按方法复杂度排序。在超参数优化的精度、成本和计算时间方面,贝叶斯优化优于网格搜索和随机搜索(参见这里的经验比较)。这是因为贝叶斯优化从先前参数的运行中学习,与网格搜索和随机搜索相反。
当贝叶斯优化与强化学习和进化算法进行比较时,它提供了具有竞争力的准确性,同时需要更少的迭代。例如,为了学习好的策略,谷歌的AutoAugment迭代15,000次(这意味着训练子CNN模型15,000次)。另一方面,贝叶斯优化在100-300次迭代中学习良好的策略。贝叶斯优化的经验法则是使迭代次数等于优化参数的次数乘以10。
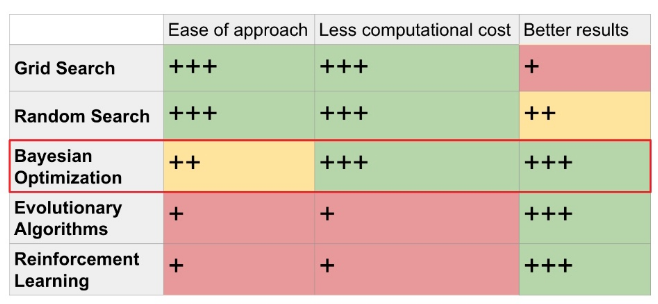
超参数优化方法的直观比较。通过比较类别,加号(+)的数量表示该方法有多好。
挑战及对策
挑战1:优化增强需要大量的计算资源,因为子模型应该从头开始反复训练。大大减慢了我的工具的开发过程。 尽管使用贝叶斯优化使其更快,但优化过程仍然不够快,无法使开发变得可行。
对策:我开发了两种解决方案。首先,我优化了子CNN模型(见下图),这是该过程的计算瓶颈。其次,我以更确定的方式设计了增强策略,使贝叶斯优化器需要更少的迭代。
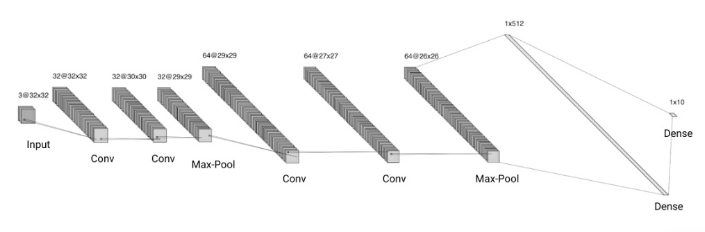
设计子CNN模型。它在AWS p3.2x大型实例(带有112 TensorFLOPS的Tesla V100 GPU)上以32x32图像在约30秒(120个周期)的时间内完成培训。
挑战2:我在DeepAugment的开发过程中遇到了一个有趣的问题。在通过一遍又一遍地训练子模型来优化增强期间,它们开始过度拟合验证集。当我更改验证集时,我发现的最佳策略表现不佳。这是一个有趣的例子,因为它不同于一般意义上的过度拟合,即模型权重过度拟合数据中的噪声。
对策:我没有使用相同的验证集,而是将剩余的数据和训练数据保留为“种子验证集”,并在每次子CNN模型训练时对1000个图像的验证集进行采样(参见下面的数据管道)。这解决了增强过度拟合问题。
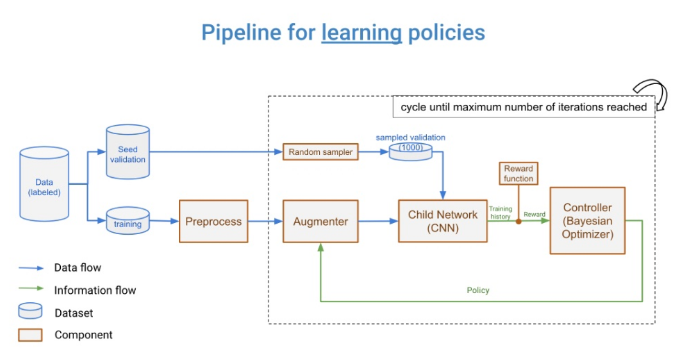
如何集成到ML pipeline中
DeepAugment发布在PyPI上。你可以通过运行以下命令来在终端安装它:
$ pip install deepaugment并且使用方便:
- from deepaugment.deepaugment import DeepAugment
- deepaug = DeepAugment(my_images, my_labels)
- best_policies = deepaug.optimize()
通过配置DeepAugment,可以获得更高级的用法:
- from keras.datasets import cifar10
- # my configuration
- my_config = {
- "model": "basiccnn",
- "method": "bayesian_optimization",
- "train_set_size": 2000,
- "opt_samples": 3,
- "opt_last_n_epochs": 3,
- "opt_initial_points": 10,
- "child_epochs": 50,
- "child_first_train_epochs": 0,
- "child_batch_size": 64
- }
- (x_train, y_train), (x_test, y_test) = cifar10.load_data()
- # X_train.shape -> (N, M, M, 3)
- # y_train.shape -> (N)
- deepaug = DeepAugment(x_train, y_train, config=my_config)
- best_policies = deepaug.optimize(300)

有关更详细的安装/使用信息,请访问项目的自述文件或运行Google Colab笔记本教程。
结论
据我们所知,DeepAugment是第一种利用贝叶斯优化来寻找最佳数据增强的方法。 数据增强的优化是最近的一个研究领域,AutoAugment是解决这一问题的首批方法之一。
Deepaugment对开源社区的主要贡献在于它使进程具有可扩展性,允许用户在不需要大量计算资源的情况下优化扩充策略*。它是非常模块化的,比以前的解决方案AutoAugment快50倍以上。
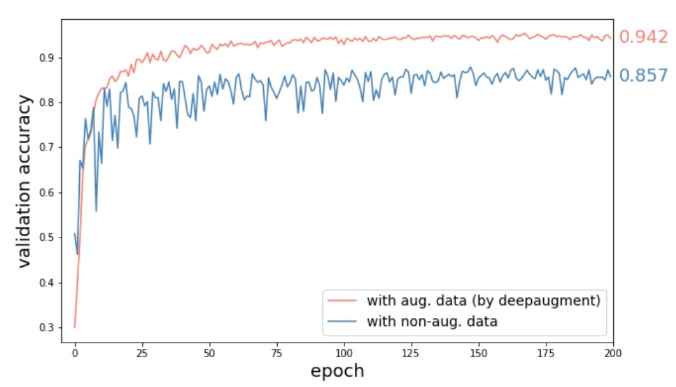
WideResNet-28-10 CNN模型与CIFAR10图像在被Deepaugment发现的策略增强和不增强时的验证精度比较验证精度提高8.5%,相当于减少了60%的误差。
结果表明,使用CIFAR-10小图像数据集的WideResNet-28-10模型与不使用增强的模型和数据集相比,Deepaugment可以减少60%的误差。
Deepaugment目前只优化图像分类任务的增强。它可以扩展到优化对象检测或分割任务,如果你愿意,我欢迎你的贡献。但是,我认为最好的增强策略非常依赖于数据集的类型,而不是任务(例如分类或对象检测)。这意味着无论任务是什么,AutoAugment都应该找到类似的策略,但如果这些策略最终变得非常不同,那将是非常有趣的!
虽然DeepAugment目前适用于图像数据集,但将其扩展到文本、音频或视频数据集将非常有趣。同样的概念也适用于其他类型的数据集。
*使用AWS P3.X2Large实例,DeepAugment在CIFAR-10数据集上花费4.2小时(500次迭代),成本约为13美元。
感谢
我在Insight人工智能研究员计划期间的三个星期内完成了这个项目。我感谢程序总监Matt Rubashkin和Amber Roberts的非常有用的指导,感谢我的技术顾问Melissa Runfeldt帮助我解决问题。我感谢Amber Roberts,Emmanuel Ameisen,Holly Szafarek和Andrew Forrester在这篇博客文章中提出的建议和编辑工作。
想要提升你在数据科学和人工智能领域的职业生涯?申请SV和NYC的截止日期是4月1日!在Insight了解更多关于人工智能程序的信息!
原文链接
本文为云栖社区原创内容,未经允许不得转载。

