- 1Stable Diffusion WebUI 笔记本低显存无魔法本地安装使用(四)--- 安装和启动Stable Diffusion WebUI_stable diffusion web ui 社区
- 2NameNode内存生产配置探究_namenode占用的是什么内存
- 3新钛云服数字化转型服务案例入选Forrester报告!
- 440 个很有用的 Mac OS X Shell 脚本和终端命令_macbook xshell
- 5为什么要来CSDN_为什么要用csdn
- 6六、Git——提交版本管理
- 7开源AI项目:合同检查流程优化,提高工作效率与准确性_ai能够帮我们读懂合同吗
- 8Activity的启动流程详解_am strat启动activity
- 9糟糕程序员的7个通病,你中了几条?_程序员的性格通病
- 10Django3+Vue3进行前后端开发环境搭建_vue3 django
常用SQL命令
赞
踩
应用经常需要处理用户的数据,并将用户的数据保存到指定位置,数据库是常用的数据存储工具,数据库是结构化信息或数据的有序集合,几乎所有的关系数据库都使用 SQL 编程语言来查询、操作和定义数据,进行数据访问控制,作为测试人员,掌握SQL语言是必要的。
我们一般对数据库的数据表进行增删改查的操作,以下是一些常用的SQL命令。
数据表增加数据
我们可以通过insert into语句向表中插入新记录
使用该命令有2种方式:
| 命令形式 | 描述 |
|---|---|
INSERT INTO table_name VALUES (value1,value2,value3,...),(value1_2,value2_2,value3_2,...),...,(value1_n,value2_n,value3_n,...); | 无需指定要插入数据的列名,只需提供被插入的值即可,但需要注意,被插入的表中有多少个字段(即列),则值就必须有多少个,且需要按照表字段排序进行赋值 |
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...),(value1_2,value2_2,value3_2,...),...,(value1_n,value2_n,value3_n,...); | 需要指定列名及被插入的值 ,column与value一一对应,即column1=value1,column2=value2 |
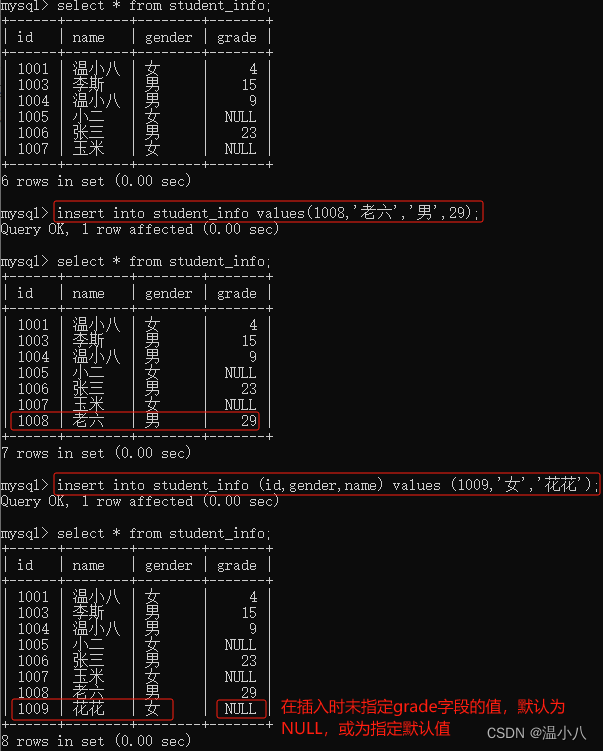
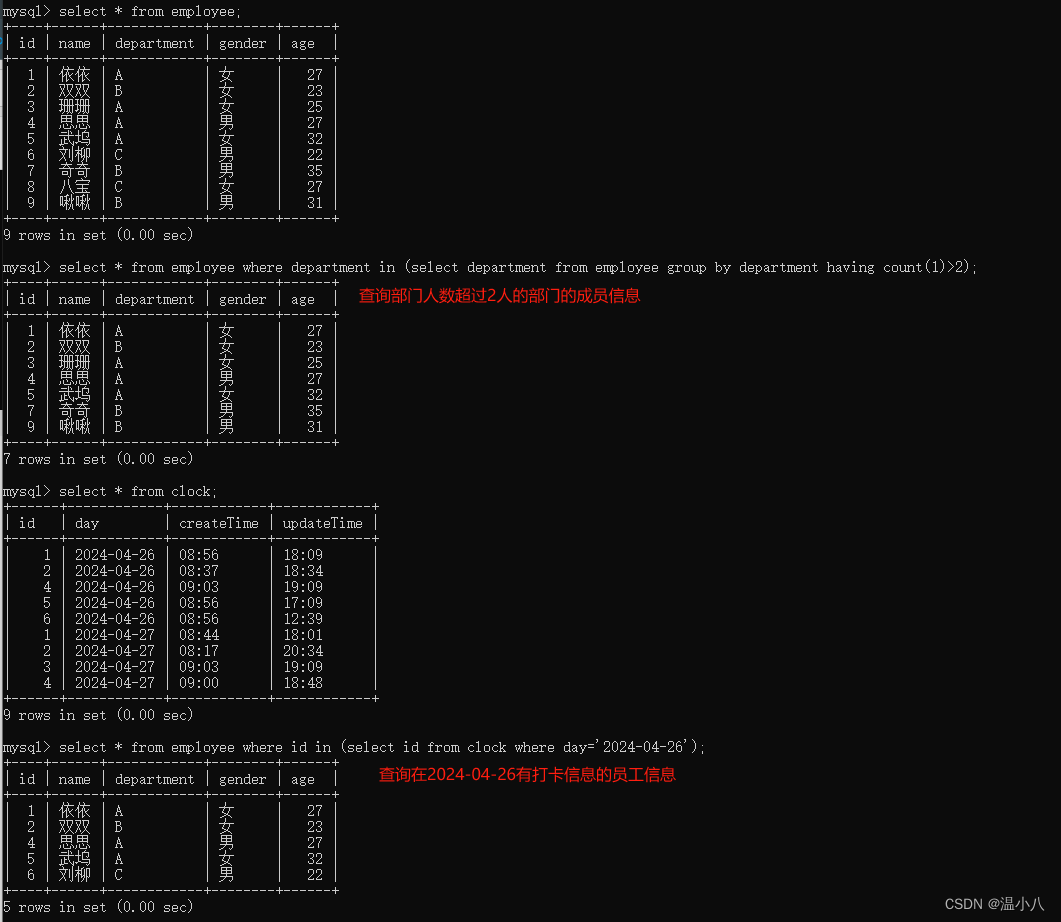
数据表删除数据
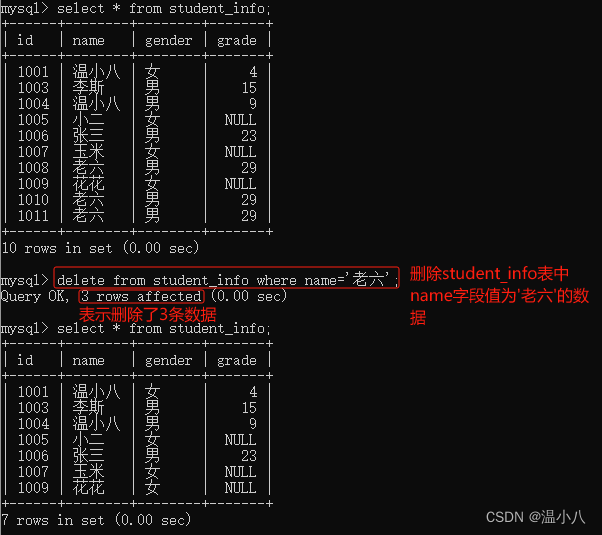
可以用DELETE命令删除指定的数据(工作中慎用,即使使用,必须检查where语句是否正确)
命令:DELETE FROM table_name WHERE xxx;
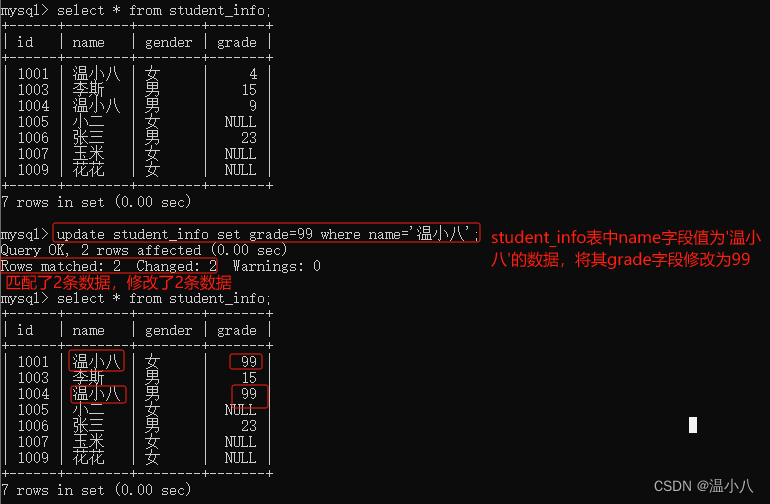
数据表修改数据
如果需要修改表中一些数据,可以使用UPDATE命令
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
- 1
- 2
- 3
数据表查询数据
数据表操作最多的就是查询了,即SELECT语句,
| 命令形式 | 描述 |
|---|---|
SELECT column1, column2, ... FROM table_name [where xxx]; | 查询table_name表符合xxx条件的数据的指定字段值 |
SELECT * FROM table_name [where xxx]; | 查询table_name表符合xxx条件的数据的所有字段值 |
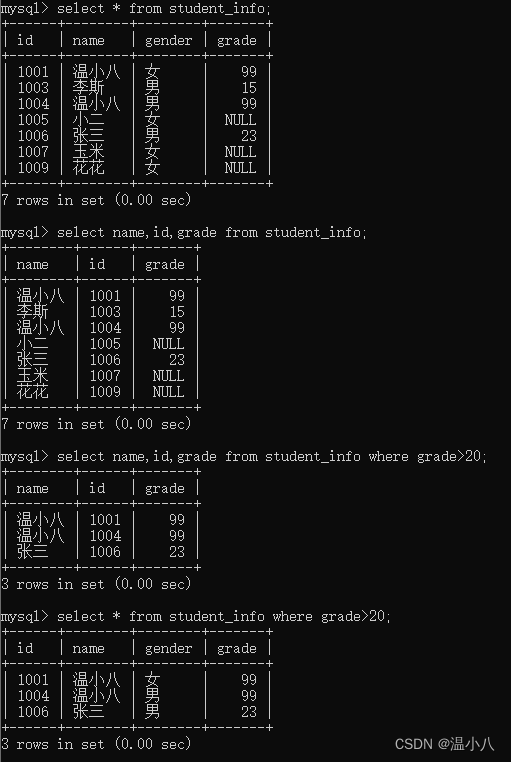
函数
在SELECT语句中,经常会用一些函数对数据进行统计,常用函数如下:
| 函数 | 说明 |
|---|---|
COUNT() | 返回符合条件的数据量 |
MAX() | 返回最大值 |
MIN() | 返回最小值 |
DISTINCT() | 在表中,一个列可能会包含多个重复值,该函数返回所在列去重后的所有值 |
ROUND() | 把数值字段四舍五入入为指定的小数位数 |
COUNT()
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入)
| 函数 | 说明 |
|---|---|
SELECT COUNT(*) FROM table_name[where xxx]; | 返回表中符合where条件的数据的总量 |
SELECT COUNT(column_name) FROM table_name[where xxx]; | 返回表中符合where条件的,且列column_name的值不为NULL的总量,类似于 SELECT COUNT(*) FROM table_name where column_name is not NULL[ and xxx]; |
SELECT COUNT(condition) FROM table_name[where xxx]; | 返回表中符合where条件,且满足condition!=null的数据量 |
SELECT COUNT(condition or NULL) FROM table_name[where xxx]; | 返回表中符合where条件,且满足condition的数据量 |
COUNT(*)和COUNT(column_name)
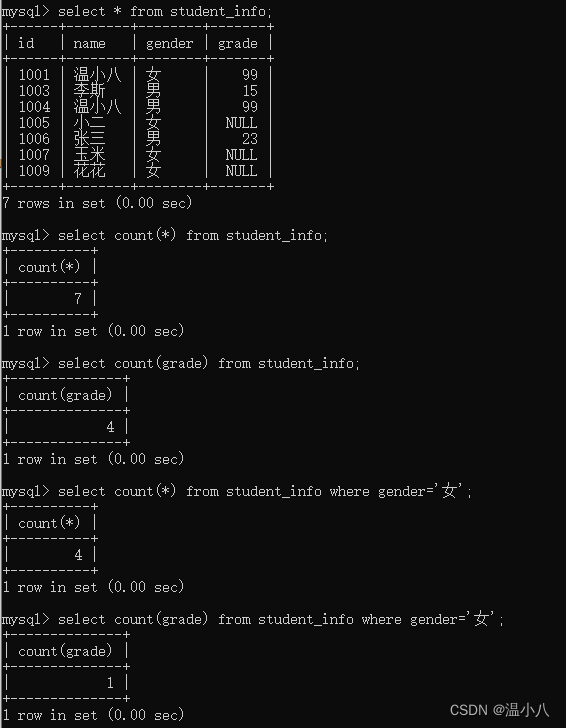
COUNT(condition)
前面说了,COUNT()函数是统计指定条件不为NULL的数据,所以对于SELECT COUNT(condition) FROM table_name[where xxx];语句,只要符合where条件的数据,在condition不为NULL,就会被统计进去,有几种比较常用的用法
我们有时会碰到COUNT(数字)的用法,因为统计指定条件不为NULL的数据,而数字肯定不是NULL,所以COUNT(数字)相当于统计符合where条件的数据量
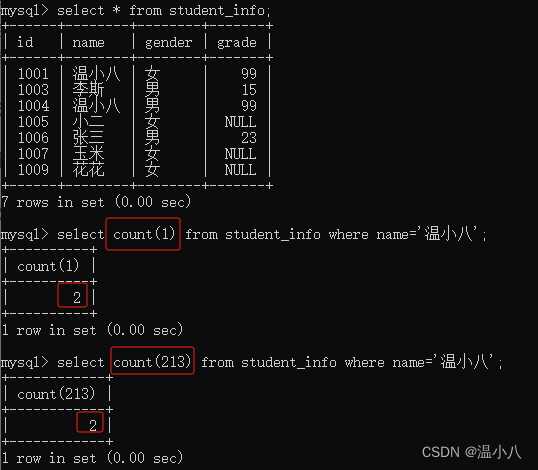
另一种就是条件表达式,我们需要统计的数据量除了要符合where条件外,还需要符合指定条件
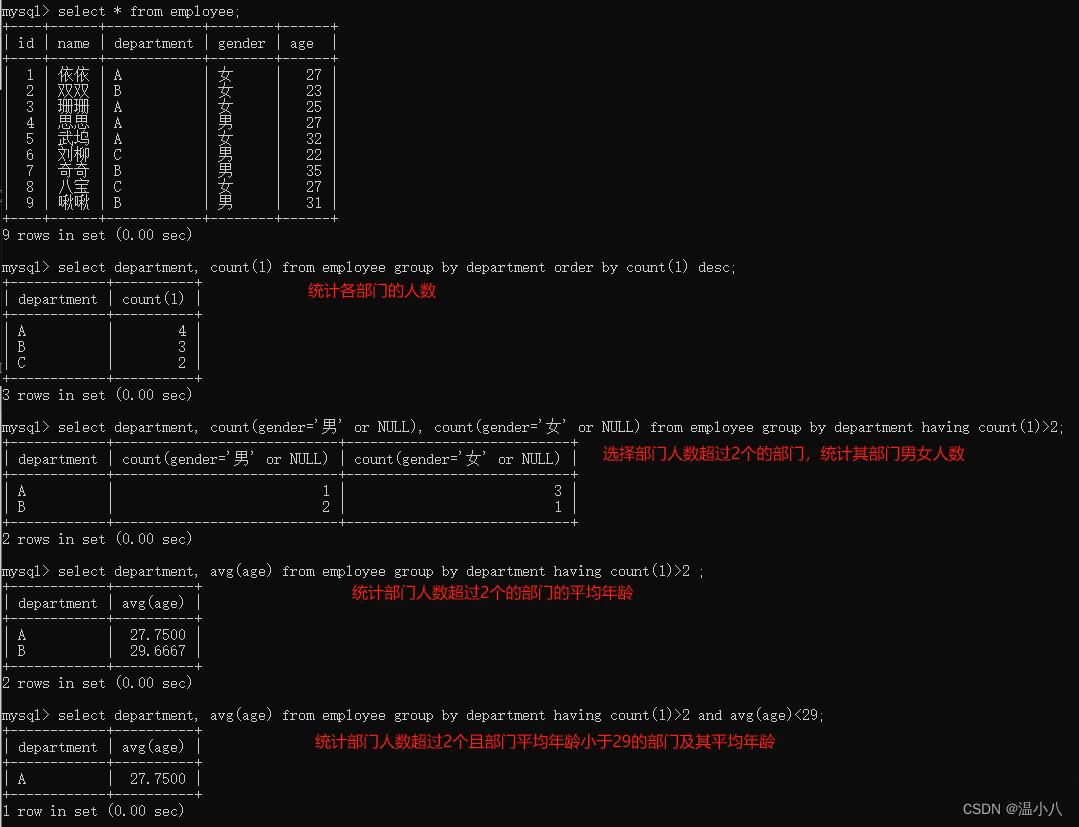
如下图所示,在COUNT()函数里加上了条件表达式,但是条件表达式需要注意的一点是:COUNT()函数是根据值是否为NULL去统计的,所以条件表达式要根据结果为NULL去判断,即如果条件表达式得到的结果是true或false,对于COUNT()函数来说,都是可统计的,因为true和false都不是NULL,所以如果需要统计符合条件的,可以在条件表达式后加上or NULL,如果前面的条件表达式为true时,不会走后面为NULL的设置,如果为false时,则会走后面为NULL的设置
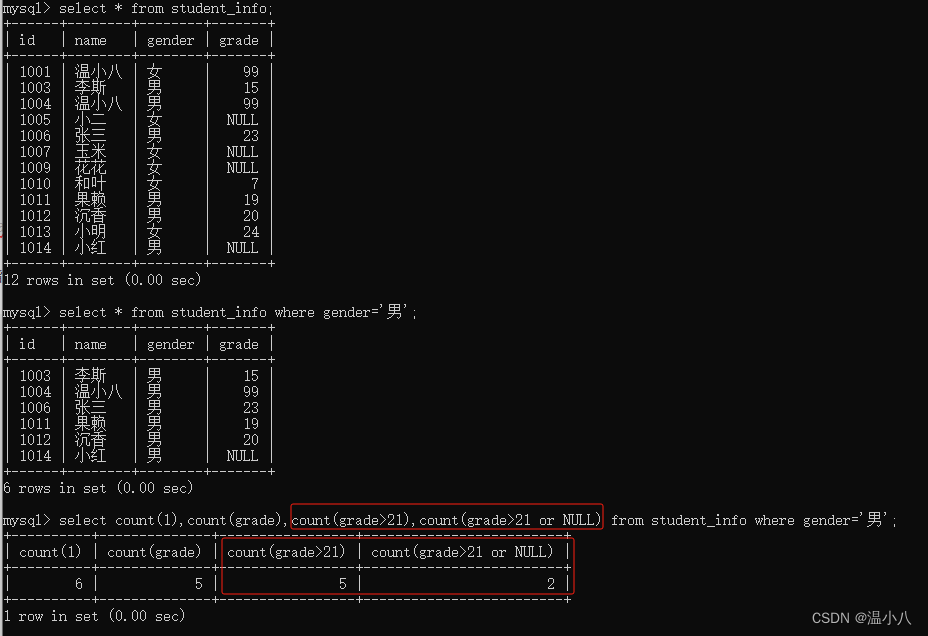
注意:可能有人会有疑问,如果还需要符合指定条件,为什么不在where条件中加上,而是在count()函数中指定?因为有些查询可能比较复杂,比如需要从不同的维度去查询的时候,where条件会将数据范围固定在某些条件中,count()则可以在指定的符合where条件的数据范围中去统计不同维度的数据,具体按照实际需要去使用即可,如下:
如统计男性中grade>20和grade<=20的数据量
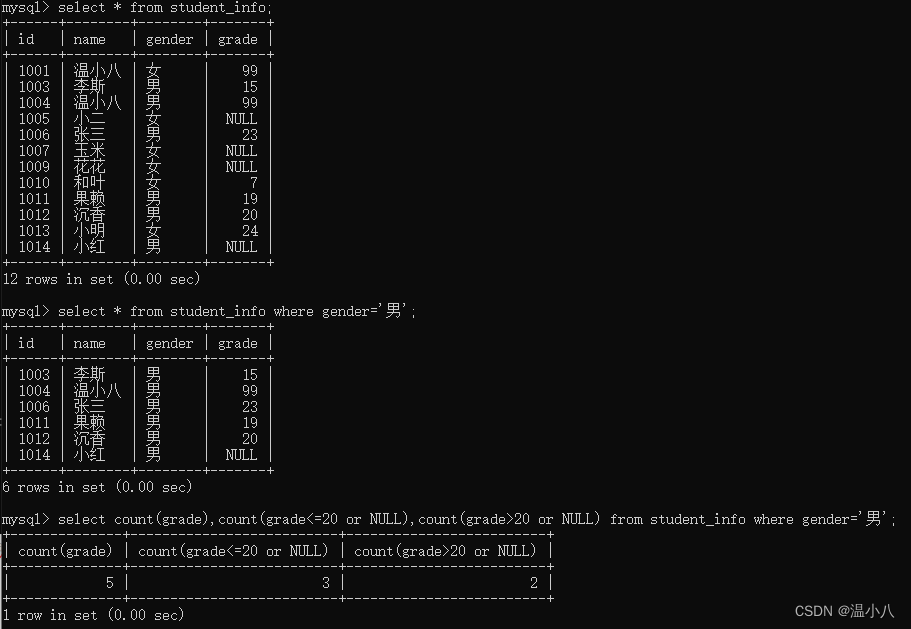
MAX()和MIN()
| 命令 | 使用说明 |
|---|---|
SELECT MAX(column_name) FROM table_name[where xxx]; | 传入的是列名,结果是返回指定列的最大值 |
SELECT MIN(column_name) FROM table_name[where xxx]; | 传入的是列名,结果是返回指定列的最小值 |
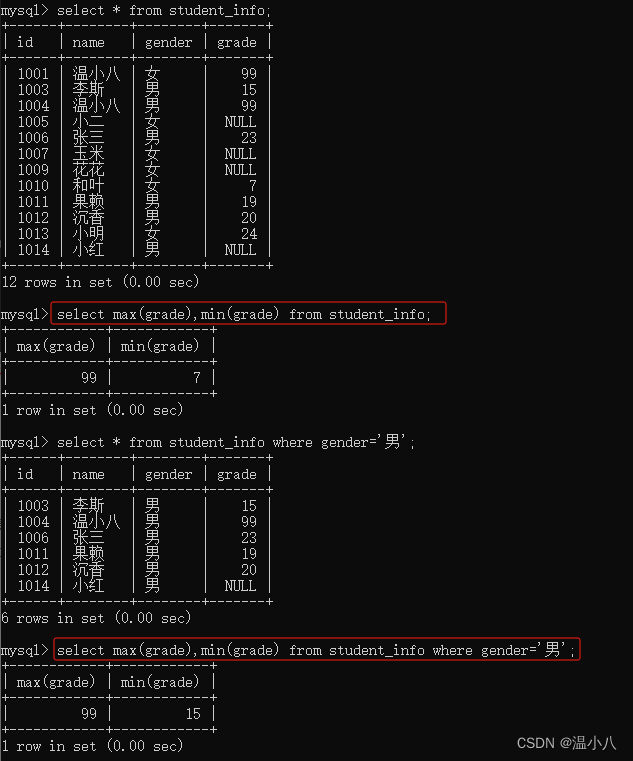
DISTINCT()
命令行:
SELECT DISTINCT column1, column2, ... FROM table_name[ where xxx];
描述:将column1, column2, …等字段值均不重复的数据返回(即去重)
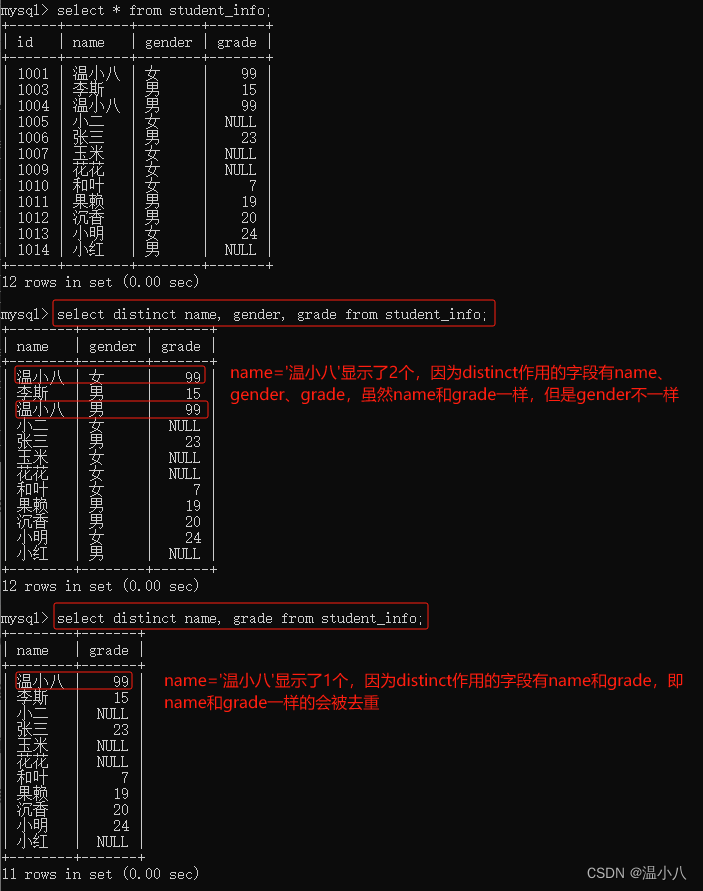
有时候DISTINCT()函数会和其他函数如COUNT()、SUM()一起使用
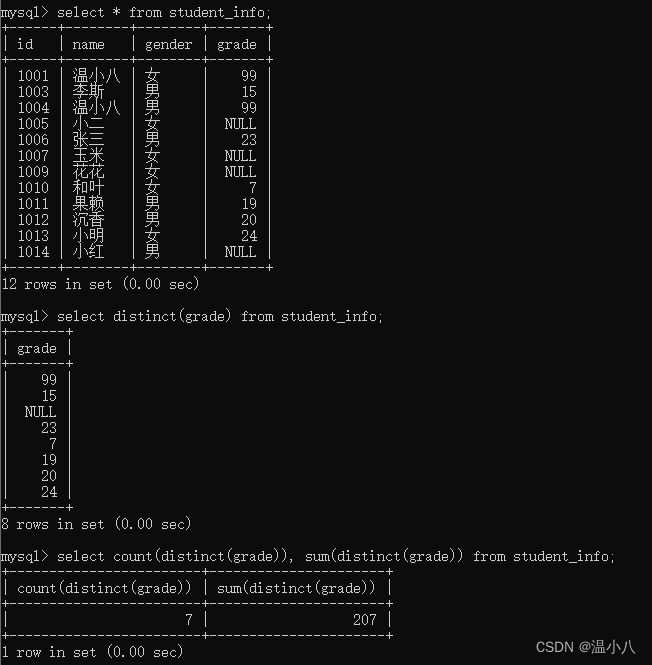
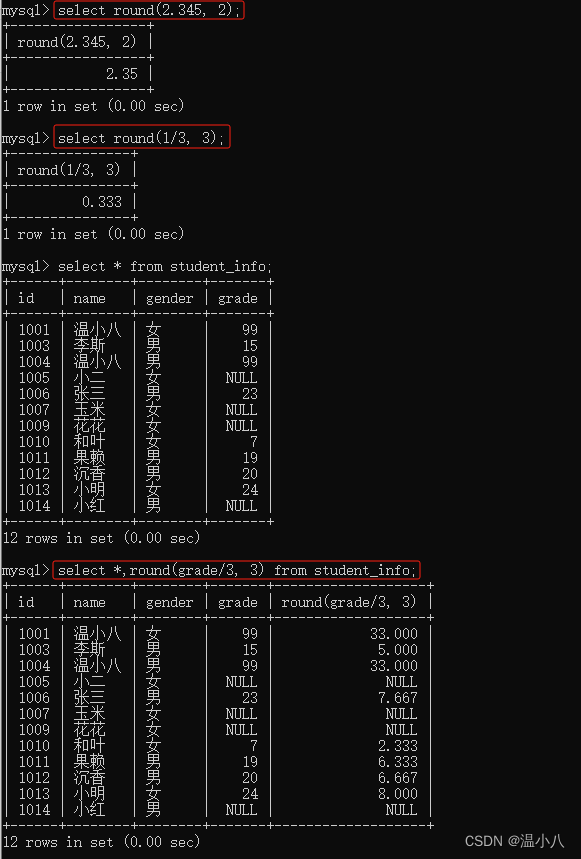
ROUND()
命令:
SELECT ROUND(column_name,decimals) FROM TABLE_NAME;
说明:将column_name列的数值按照指定小数位(decimals)四舍五入
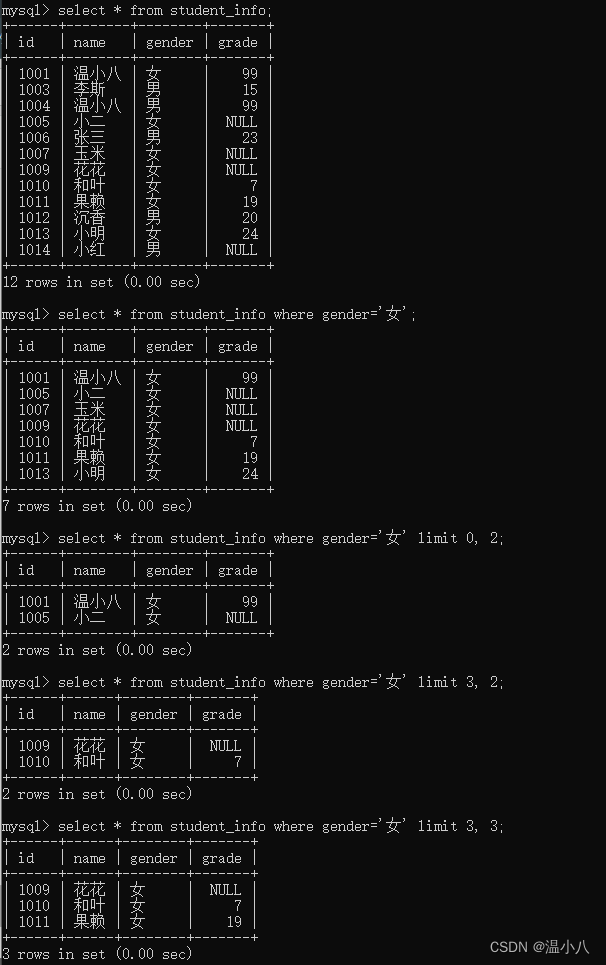
LIMIT
命令行:
select * from table_name [where xxx] limit [offset,] rows
描述:用于限制查询结果返回的数量,常用于分页查询
- offset:偏移量,即从哪个位置开始,如果未提供,则默认从0开始(数据表查询结果的位置从0开始算),如果offset超过了符合where条件的数据量或表的总数据量,则结果返回为空
- rows:取行数量,即最多取多少行
注意:并不是所有的数据库都支持LIMIT,也不是所有支持LIMIT语法的数据库,其LIMIT的用法都一致
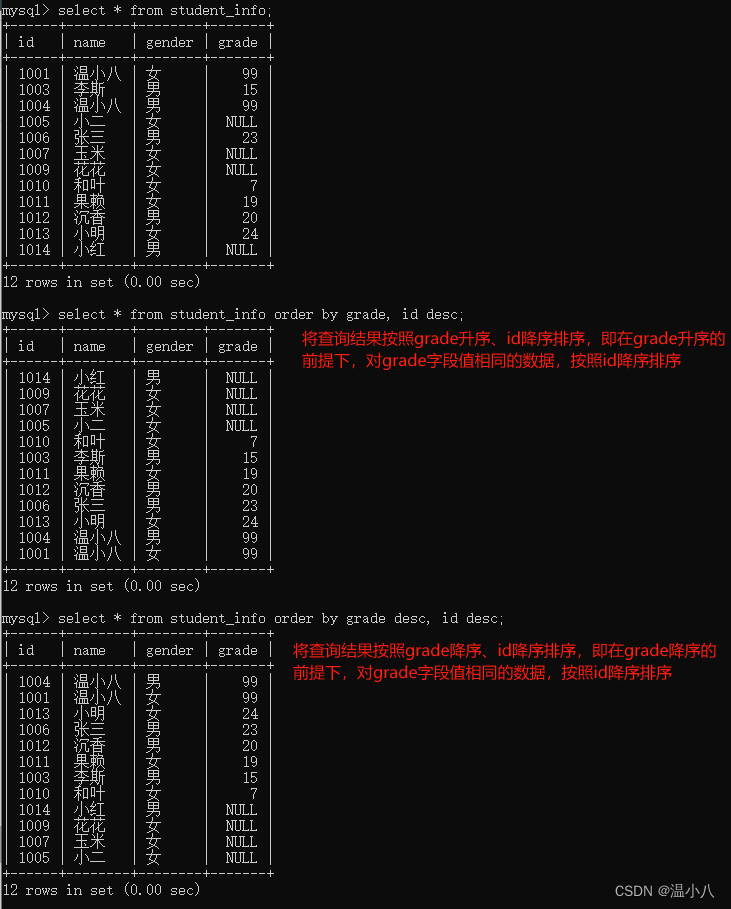
ORDER BY
命令行:
SELECT column1, column2, ... FROM table_name [where xxx] ORDER BY column1, column2, ... ASC|DESC;
描述:对结果集按照一个列或者多个列进行排序(默认升序排序)
- ASC:表示按升序排序。
- DESC:表示按降序排序。
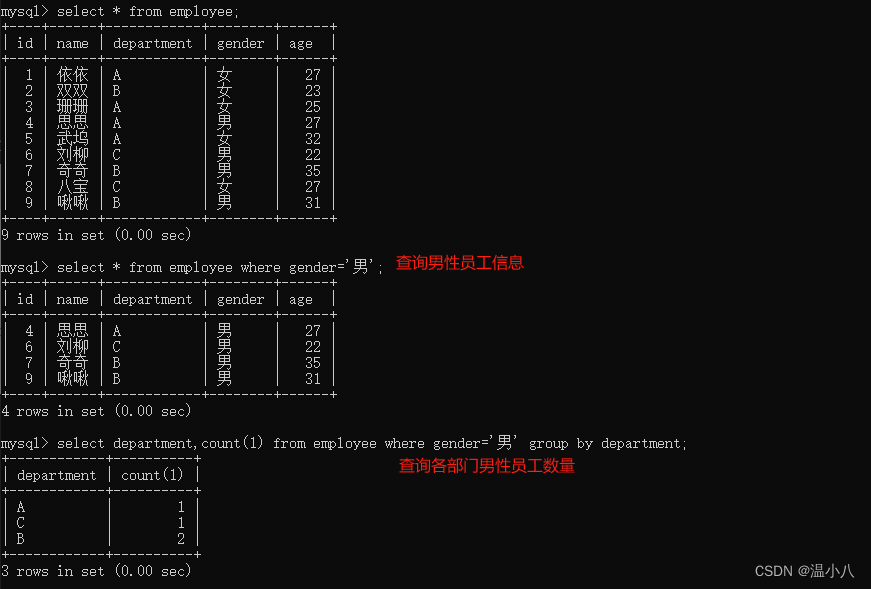
分组查询GROUP BY和HAVING 子句
分组,即按照指定特征(列),将特征相同(字段值相同)的分为同一个组,不同的特征分为不同组,在数据表中,可以理解为按照某些列中,每一行数据的指定列的值进行区分,若这些列的值相同,则分为同一组,不相同,则不在同一个组。在用来分组的列上我们可以使用 COUNT()、 SUM()、MAX()等函数进行数据统计。
命令行:
SELECT column1, aggregate_function(column2) FROM table_name WHERE condition GROUP BY column1;

注意,如果SQL语句里有where子句,GROUP BY是对where子句筛选后的数据进行分组,不是对整张表进行分组
有时候我们需要对分组后的数据进行过滤,则可以使用HAVING,HAVING是对分组后的数据进行过滤
命令行:
SELECT column_1, aggregate_function(column_2) FROM table_name WHERE condition GROUP BY column_1,...,cloumn_n HAVING aggregate_function(column_xx)xxx;
EXISTS 运算符
命令行:
SELECT xx FROM table_name WHERE [not] EXISTS (SELECT xxx);
描述:EXISTS用于判断查询子句是否有记录,如果有至少一条记录存在返回 True,否则返回 False(如果where子句返回True,则显示该数据行,如果where子句返回False,则不显示该数据行)
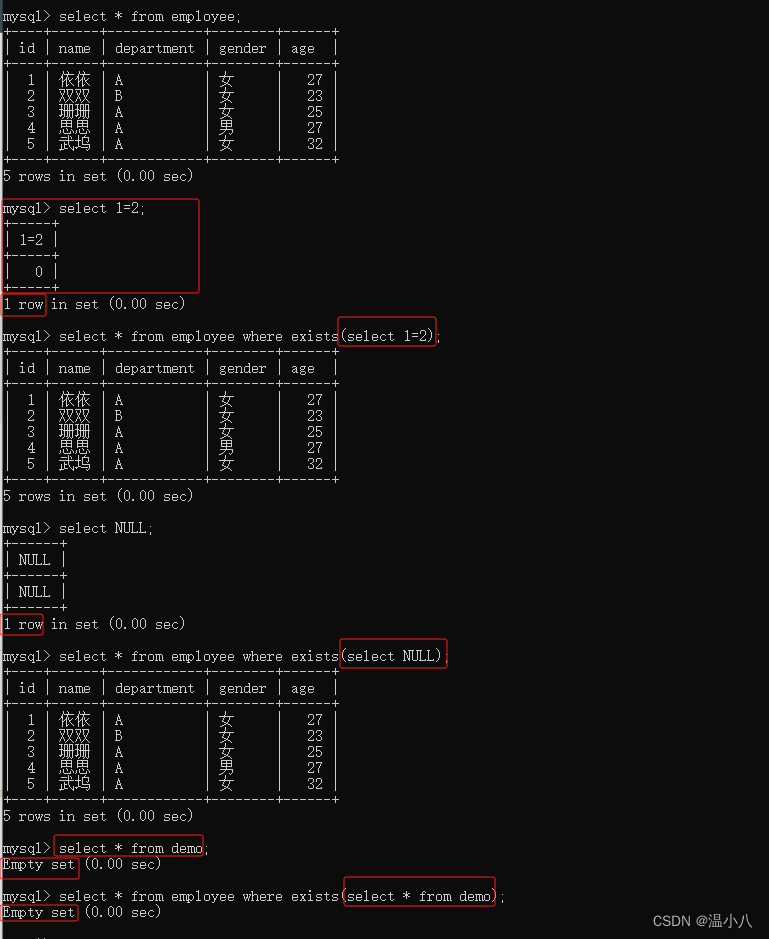
如下图所示,select 1=2和select NULL都会返回1行记录,根据EXISTS子句如果有至少1条记录返回True,得到where子句一直为True,所有数据行被返回;由于select * from demo;返回了空集合(即1条记录都没有),所以EXISTS子句返回了False,即where子句一直为False,所以数据行都没有被返回。
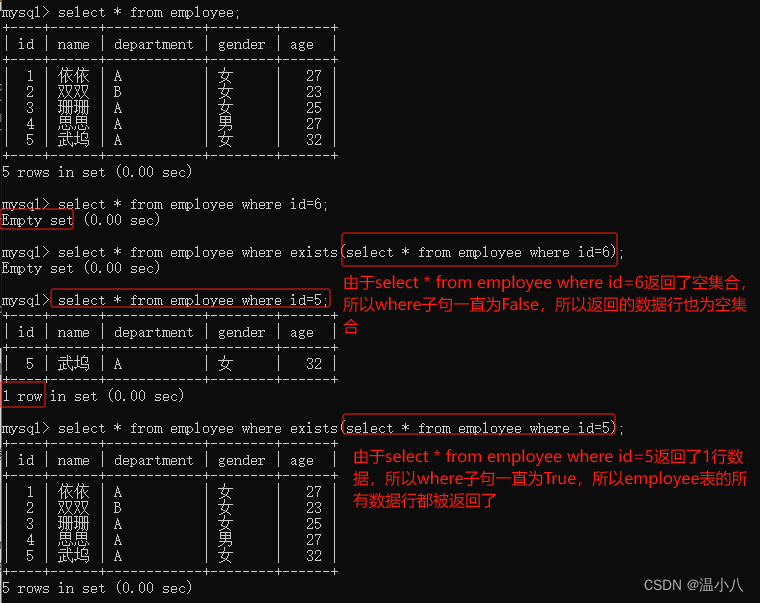
根据上面的例子,可以很容易理解以下的例子:
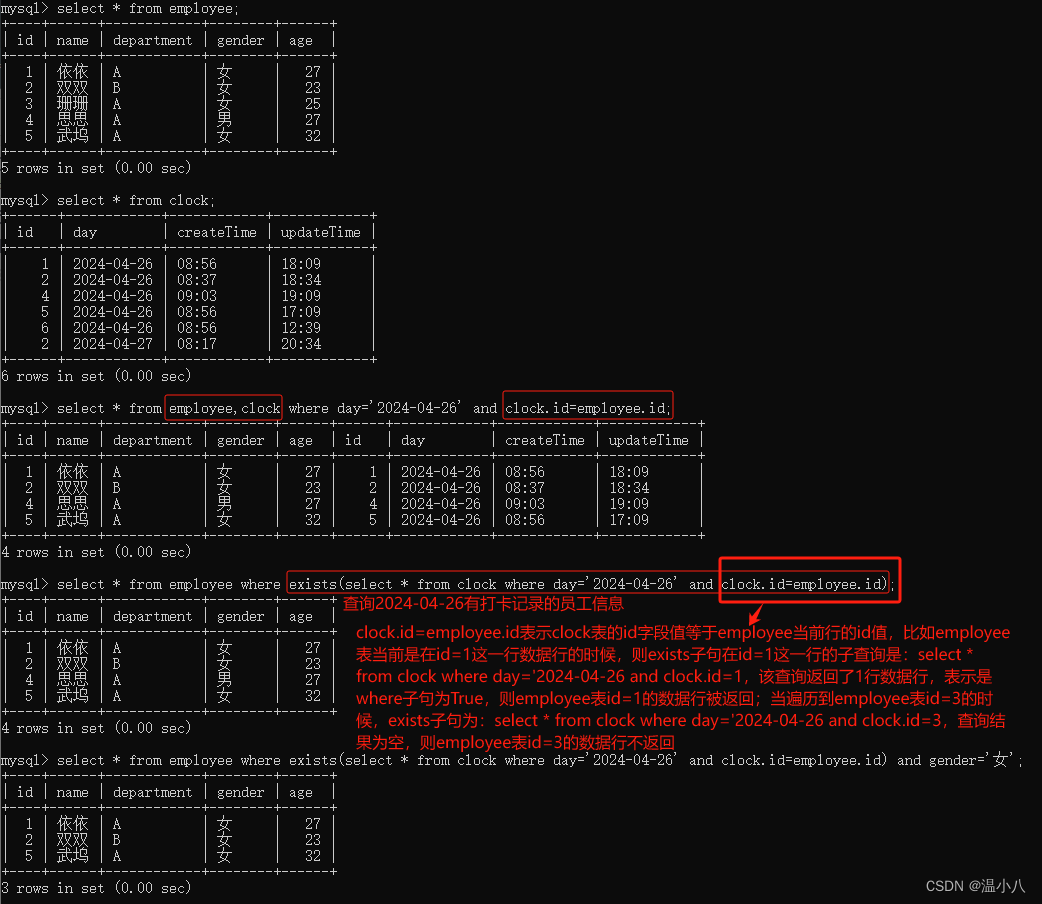
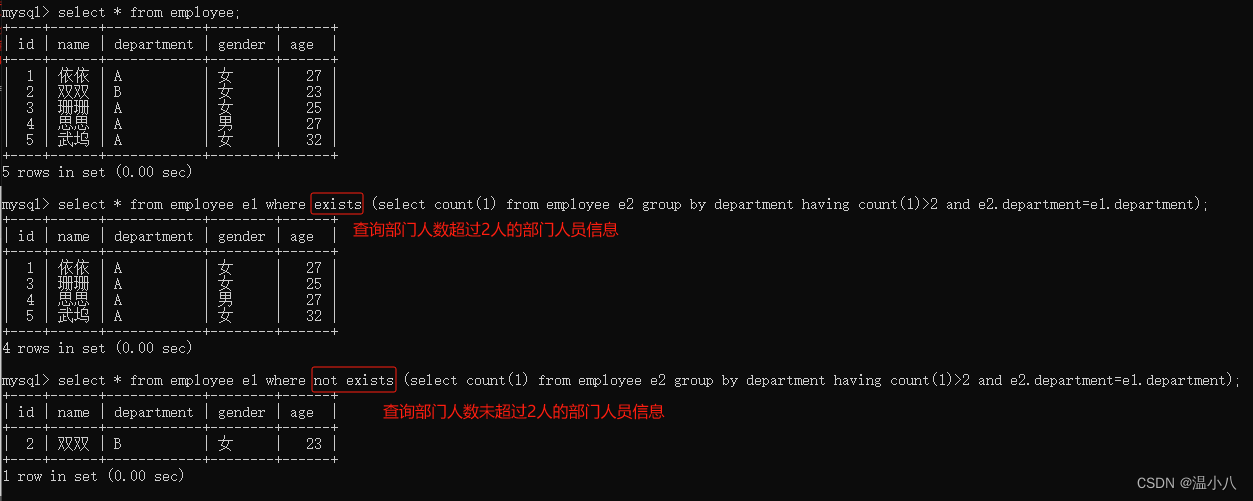
JOIN子句
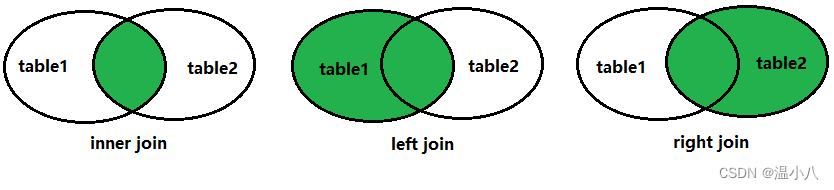
JOIN相关子句是用于将两个或者多个表结合起来,再进行相关操作
| 函数 | 说明 |
|---|---|
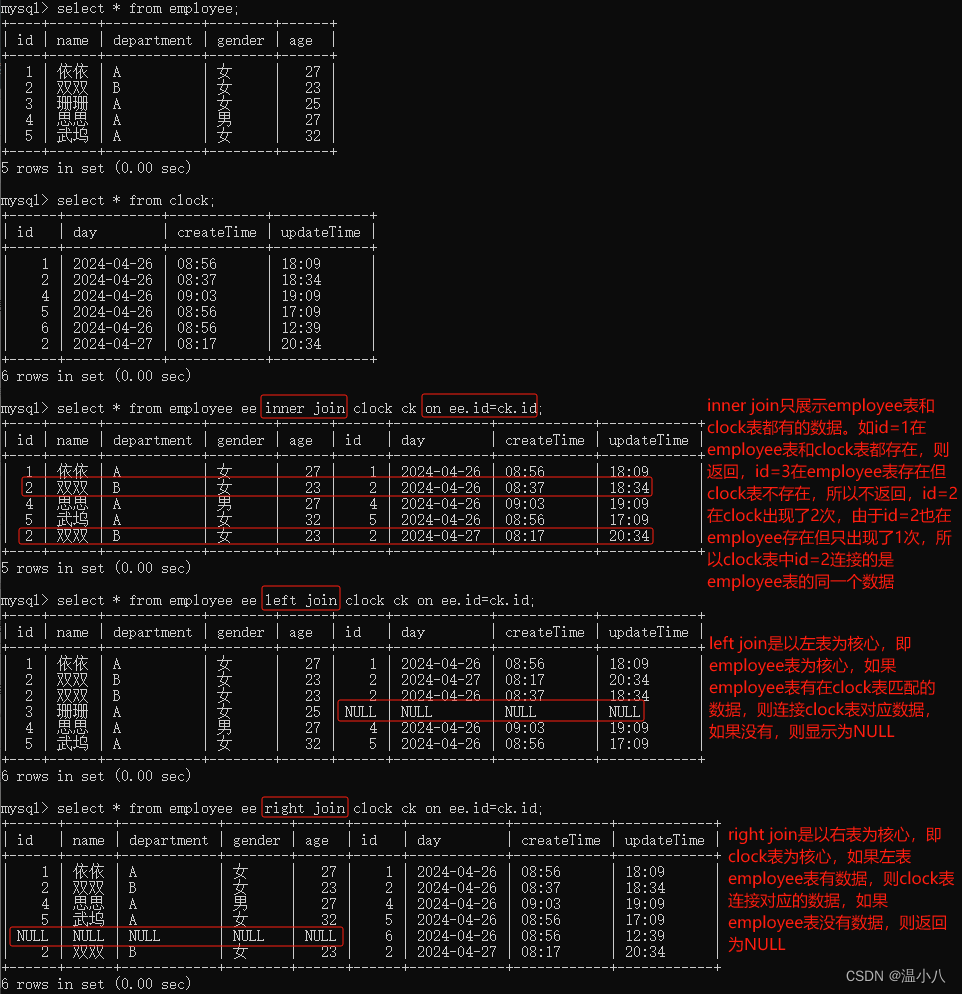
inner join | 内连接,以连接条件(on t1.column1=t2.column1)作为判断,如果column1对应的值在2个表中都有数值,则进行数据行连接并返回,如果在其中一个表中没有对应值,则不返回 |
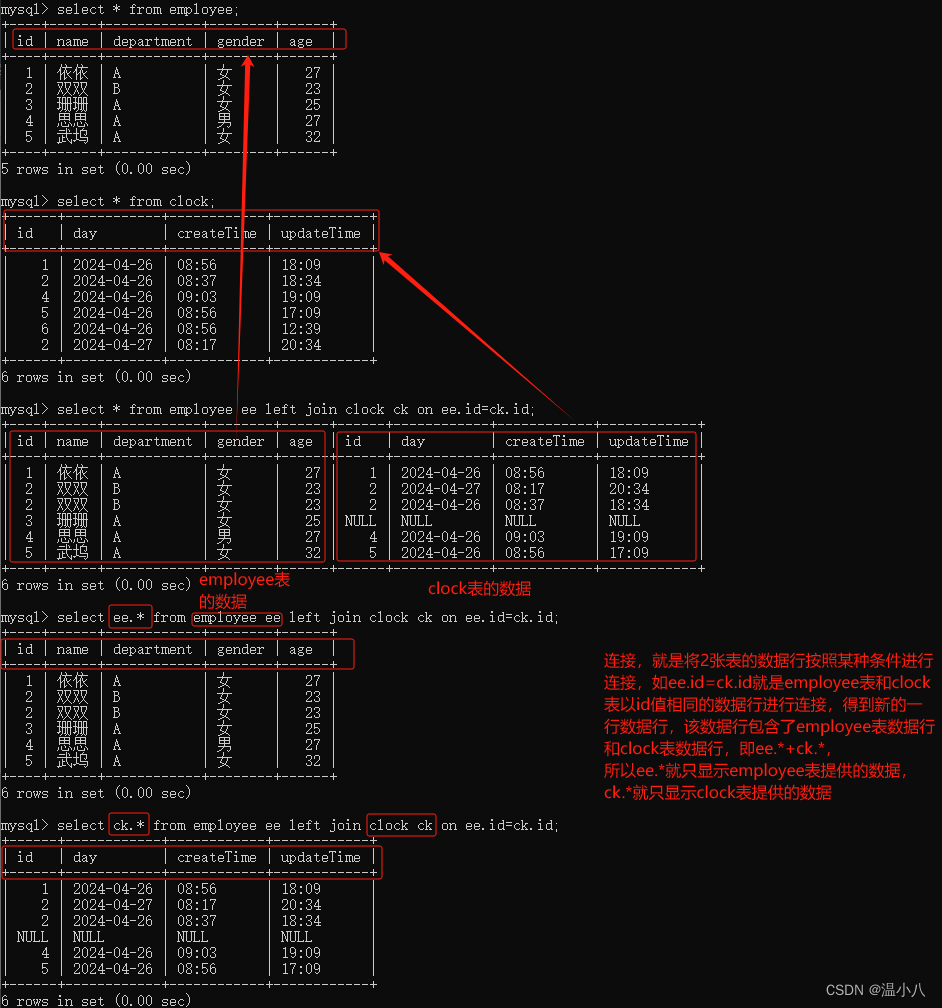
left join | 左连接,以左表为核心进行连接,即以连接条件(on t1.column1=t2.column1)作为判断,如果左表的column1字段值在右表column1字段中有同样的值,则进行数据行连接并返回,如果在右表column1字段中有没有同样的值,则以右表所有字段值为NULL与左表对应数据行进行连接然后返回 |
right join | 右连接,以右表为核心进行连接,即以连接条件(on t1.column1=t2.column1)作为判断,如果右表的column1字段值在左表column1字段中有同样的值,则进行数据行连接并返回,如果在左表column1字段中有没有同样的值,则以左表所有字段值为NULL与右表对应数据行进行连接然后返回 |
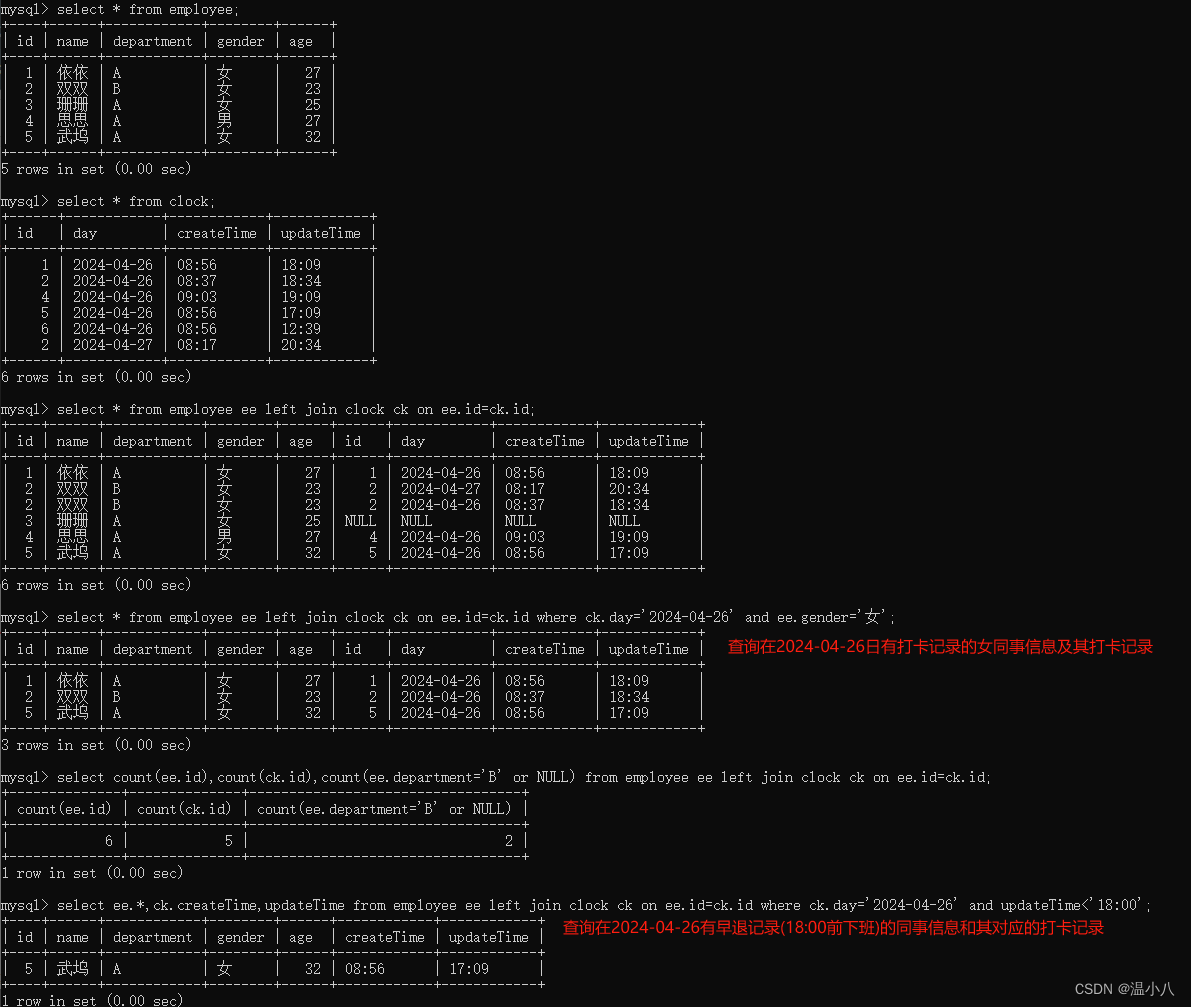
操作符
IN和NOT IN
| 命令 | 说明 |
|---|---|
SELECT/UPDATE/DELETE xxx WHERE column IN (value1, value2, ...); | 指定列(column)的值要在IN指定的范围内 |
SELECT/UPDATE/DELETE xxx WHERE column NOT IN (value1, value2, ...); | 指定列(column)的值要不在IN指定的范围内 |
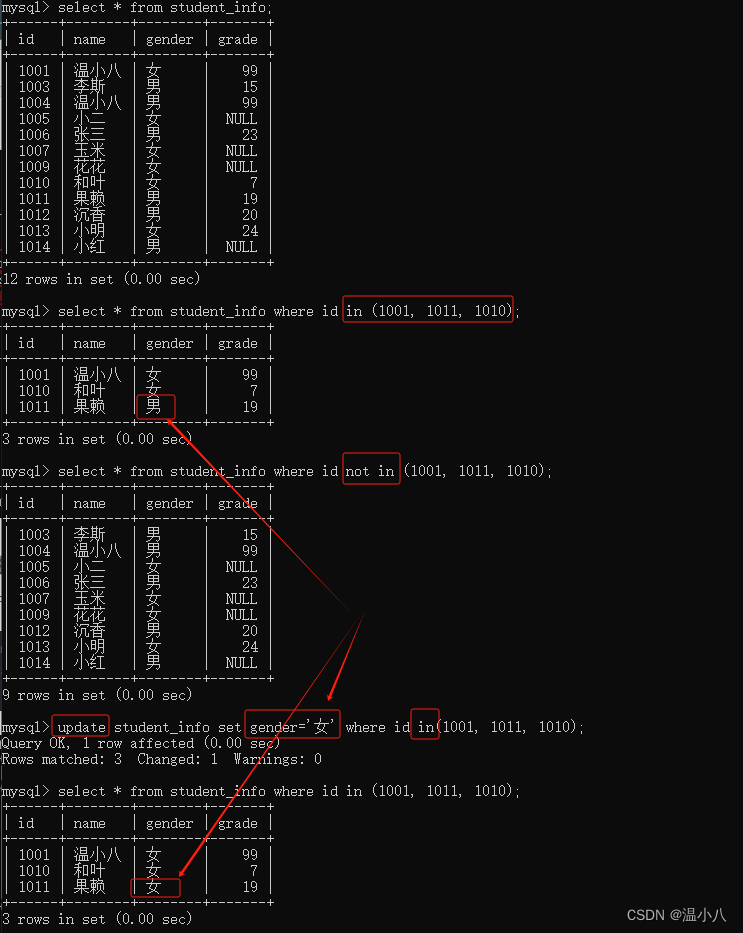
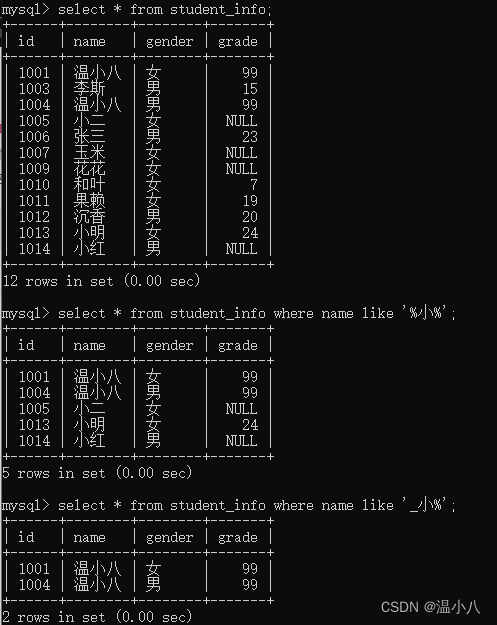
LIKE
命令:
SELECT/UPDATE/DELETE xxx WHERE column LIKE pattern;
描述:column列的值要模糊匹配指定模式
模式设置的有2个较常用的符号:
| 命令 | 说明 |
|---|---|
% | 匹配0个或多个字符 |
_ | 匹配一个字符 |
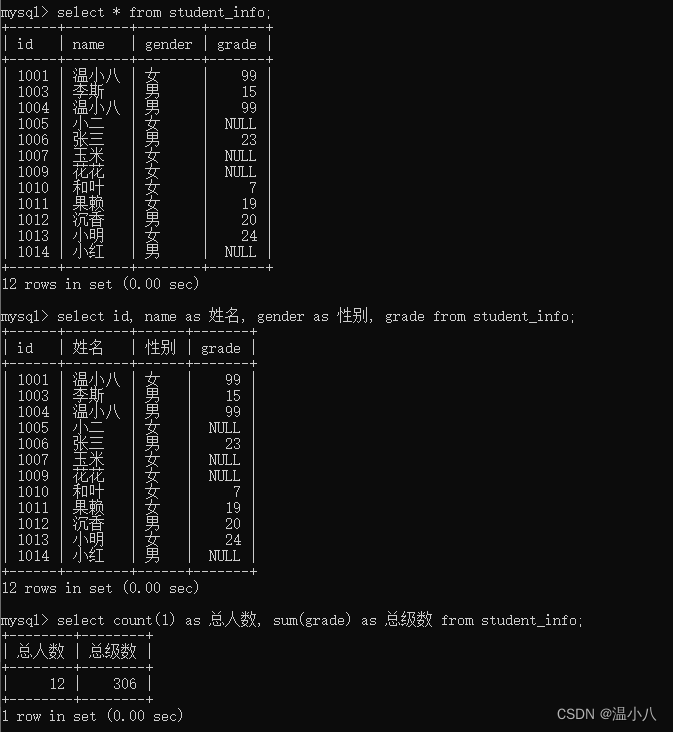
AS别名
别名,是为了让列名称或表名称的可读性更强,而给字段名称或表取的名称
给列名称取别名命令:SELECT column_name1 AS 别名1, column_name2 AS 别名2,... FROM table_name;
有时候一个SQL执行语句中有多张表,这个时候就需要给表取别名来增强可读性
给表取别名命令:SELECT 别名.column_name1, 别名.column_name2,... FROM table_name [as] 别名;

嵌套子查询
嵌套子查询可以简单理解为在where语句中嵌套了select语句
命令行:
SELECT/UPDATE/DELETE xxx WHERE column IN/=/like (select column from xxx [where xxx]);
注意:嵌套的select语句查询的结果集必须是指定列column的结果集