
- 1从零开始 - 在Python中构建和训练生成对抗网络(GAN)模型
- 2深入浅出Electron如何解决第三方库绕开electron-builder签名配置_electron builder 打包 不签名dll
- 3Windows设置Redis为开机自启动
- 4✨使用Python进行线性规划求解,高端操作亮瞎你的双眼(文末技术彩蛋)_python自带规划求解器是什么
- 5数据质量监控实践_数据质量监控的背景
- 6栈和队列的异同_栈和队列为什么只能在端点处进行操作
- 7【自然语言处理】环境搭建01_自然语言处理环境搭建
- 8渗透测试 ( 6 ) --- SQL 注入神器 sqlmap_sql注入工具
- 9NLP中BERT模型详解_nlp bert
- 10linux下查看文件的权限,Linux下查看文件权限、修改文件权限的方法
噪声嵌入提升语言模型微调性能
赞
踩
在自然语言处理(NLP)的快速发展中,大模型(LLMs)的微调技术一直是研究的热点。最近,一篇名为《NEFTUNE: NOISY EMBEDDINGS IMPROVE INSTRUCTION FINETUNING》的论文提出了一种新颖的方法,通过在训练过程中向嵌入向量添加噪声来提升模型的微调性能。这一发现为LLMs的进一步优化提供了新的思路。
传统的LLMs通常在原始网络数据上进行训练,然后针对较小但经过精心策划的指令数据集进行微调。这种指令微调对于发挥LLMs的潜力至关重要,而模型的实用性很大程度上取决于我们如何充分利用这些小型指令数据集。NEFTune的核心思想是在微调过程中的前向传播阶段向训练数据的嵌入向量添加随机噪声。这一简单的技巧可以在没有额外计算或数据开销的情况下显著提升指令微调的结果。实验表明,使用噪声嵌入对原始LLM(如LLaMA-2-7B)进行微调时,其在AlpacaEval上的性能从29.79%提升至64.69%,显示出约35个百分点的显著提升。

NEFTune(Noisy Embedding Instruction Fine Tuning)是一种新颖的微调技术,它通过在训练过程中向嵌入向量添加噪声来增强语言模型的性能。这种方法的核心思想是利用随机噪声作为一种正则化手段,以减少模型对训练数据的过度拟合,并提高其泛化能力。以下是NEFTune方法的详细说明:
噪声嵌入的引入
在传统的语言模型微调中,模型的嵌入层会将输入的词汇映射为固定长度的向量,这些向量随后会被用来生成模型的输出。NEFTune方法在这一过程中引入了随机噪声,具体做法是在嵌入向量的前向传播过程中添加一个随机噪声向量。
噪声的生成与缩放
NEFTune生成的噪声向量是通过独立同分布(iid)均匀分布 采样得到的,然后通过一个缩放因子
采样得到的,然后通过一个缩放因子 对整个噪声向量进行缩放。其中,L 是序列长度,d 是嵌入维度,而α 是一个可调参数。
对整个噪声向量进行缩放。其中,L 是序列长度,d 是嵌入维度,而α 是一个可调参数。
这个缩放规则借鉴了对抗性机器学习文献中的噪声缩放规则,它会产生一个期望欧几里得范数约为  的随机向量。
的随机向量。
训练过程
NEFTune的训练过程从数据集中采样一个指令,将其标记转换为嵌入向量。然后,与标准训练不同的是,NEFTune会向这些嵌入向量添加一个随机噪声向量。具体来说,算法的步骤如下:
- 初始化从预训练模型中得到的模型参数 θ。
- 重复以下步骤直到满足停止条件或达到最大迭代次数:
- 从数据集 D 中采样一个minibatch的数据和标签(Xi,Yi)。
- 将输入Xi 转换为嵌入向量
 。
。 - 采样一个噪声向量ϵ,并将其缩放后加到嵌入向量上,得到噪声嵌入
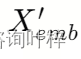 。
。 - 使用噪声嵌入
 进行预测
进行预测 。
。 - 根据损失函数
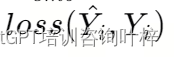 更新模型参数θ。
更新模型参数θ。
实验效果
实验结果表明,NEFTune在多个数据集上显著提升了模型的文本质量。例如,在7B规模的模型上,AlpacaEval的平均提升为15.1%。此外,即使是经过多轮RLHF调整的高级聊天模型(如LLaMA-2-Chat),也能通过NEFTune获得额外的性能提升。
结论
NEFTune通过在嵌入层引入噪声,作为一种数据增强手段,有效地提高了语言模型在指令微调任务上的性能。这种方法简单易行,且不需要额外的计算或数据开销,为LLMs的微调提供了一种有效的改进策略。


