
- 1Docker-13:Docker安装Hbase
- 2关于快速排序算法的学习心得_排序实验实训总结
- 3OceanBase 分布式数据库【信创/国产化】- OceanBase 数据库整体架构
- 4RK3588 & Android12 调试 RTL8852BE(wifi篇)_rk8852be
- 5VHDL实现数字频率计的设计_数字频率计设计vhdl
- 6基于SSM的文化遗产的保护与旅游开发系统(有报告)。Javaee项目。ssm项目。
- 7讲真,做Python一定不要只会一个方向!
- 8PC电脑 VMware安装的linux CentOs7如何扩容磁盘?_linux虚拟机安装好之后还能设置磁盘大小码
- 9机器学习介绍_setlabelcol
- 10Cesium 核心概念 核心接口_cesuim可以实现的功能
AI未来十年新范式,生成式人工智能的挑战与机遇_生成式ai+少样本
赞
踩
0 写在前面
2023年3月18日,由中国图象图形学学会(CSIG)主办,合合信息、CSIG文档图像分析与识别专业委员会联合承办的“CSIG图像图形企业行”系列活动将正式举办,通过搭建学术界与企业交流合作平台,为企业创新发展提供科技支撑,为图像图形领域高校师生提供与企业互动机会,集结产学研力量,共同推动图像图形领域的发展。

很荣幸聆听了上海交通大学人工智能研究院常务副院长、人工智能教育部重点实验室主任杨小康教授关于生成式人工智能(Generative AI)的技术分享。在讲座中,我看到了人工智能在图形图像领域日新月异的变化,以及前沿技术赋能生产、生活的无限可能。
1 什么是生成式模型?
杨小康:判别式模型支撑了人工智能的过去十年,而生成式模型是人工智能的未来十年
贯穿讲座中的一个很重要的概念就是生成式模型,那么什么是生成式模型?为什么说生成式模型是人工智能的未来十年呢?
我们知道,机器学习模型主要分为两类:
- 判别式模型(discriminative models)
- 生成式模型(generative models)
对于给定样本 x \boldsymbol{x} x,前者通过对后验概率 P ( y ^ ∣ x ) P\left( \hat{y}|\boldsymbol{x} \right) P(y^∣x)建模求得数据的最优决策边界;后者通过对联合概率 P ( x , y ^ ) P\left( \boldsymbol{x},\hat{y} \right) P(x,y^)建模求得数据各模式的决策边界。
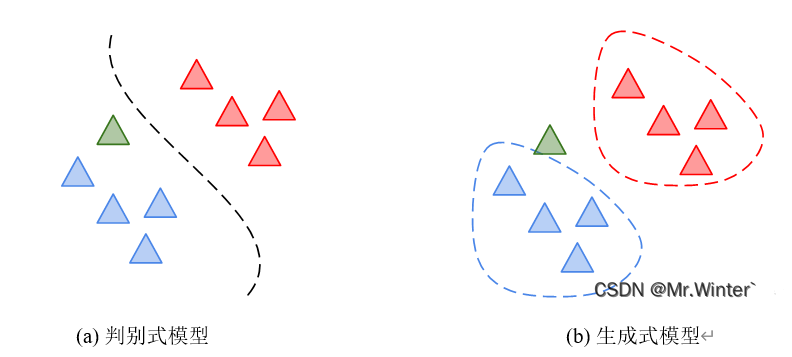
如图所示,判别式模型通过最优决策边界计算 P ( y ^ ∣ x ) P\left( \hat{y}|\boldsymbol{x} \right) P(y^∣x),并选择使 P ( y ^ ∣ x ) P\left( \hat{y}|\boldsymbol{x} \right) P(y^∣x)较大的 y ^ \hat{y} y^作为 x \boldsymbol{x} x的预测值;生成式模型通过比较样本 x \boldsymbol{x} x与模型各模式间的相近程度,即通过联合概率间接计算样本 x \boldsymbol{x} x对各模式的后验概率,并选择使后验概率较大的 y ^ \hat{y} y^作为 x \boldsymbol{x} x的预测值
两类模型的具体对比如表所示
| 项目 | 判别式模型 | 生成式模型 |
|---|---|---|
| 特点 | 寻找最优决策边界,反映不同模式数据间的差异性 | 寻找各模式边界,反映数据全体的统计全貌及不同模式间的相似度 |
| 联系 | 由生成式模型可推导判别式模型,反之不成立 | |
| 本质 | 对后验概率建模 | 对联合概率建模 |
| 实例 | 线性回归、Logistic回归、支持向量机、决策树、神经网络等 | 贝叶斯网络、贝叶斯分类器、隐马尔科夫模型等 |
| 性能 | 学习过程更简单,但不能反映数据本身特性 | 模型信息量更丰富、灵活,但学习过程较复杂 |
| 应用 | 图像文本分类、时间序列预测等 | 自然语言处理等 |
从上面的分析可以看出:生成式模型和判别式模型是两种截然不同的人工智能模型。判别式模型的主要任务是对给定输入进行分类或标记,而生成式模型则是根据给定的条件生成新的数据。
在过去,人们只希望基于已有的给定数据做一些预测和拟合,因此判别式模型得到发展并且很好地解决了大部分任务;而未来,人们将目标转向用生成式模型生成全新数据,进行迁移学习等,也就是常说的人工智能生成内容(AI Generated Content, AIGC)

为什么我们需要生成全新数据?
答案很简单:我们希望提高人工智能的工作上限,就不能仅仅依靠它对已有数据的拟合,而是像人一样有一定的创新能力。
生成式模型相比判别式模型的独特优势,使之可以应对更多的任务,例如推动内容开发、视觉艺术创作、数字孪生、自动编程,甚至为科学研究提供AI视角、Al直觉…因此生成式人工智能的未来发展趋势。
针对生成式人工智能,杨小康教授还提出了一个有意思的问题
预计到2025,生成式人工智能产生的数据将占据人类全部数据的10%,那么根据二八原则,当生成式数据超过80%的时候,人类是否全面进入元宇宙?
大家可以思考一下~
2 生成式模型的挑战
挑战与机遇并存,生成式模型带来广阔前景的同时,也存在着非常大的挑战。杨小康教授主要总结了三点:
-
解空间巨大
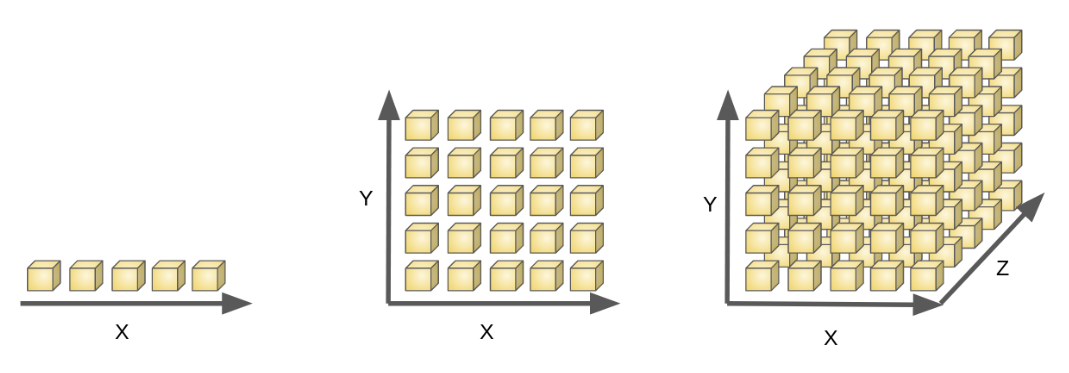
大家对高等代数中的解空间可能比较陌生,但是在人工智能领域有一个更形象的词——维数灾难(curse of dimensionality)。
如何理解这个问题?首先考虑单个特征的情形,假设在样本 x x x任意小邻域 δ \delta δ内都存在样本,则称对样本空间进行了密采样(dense sample)。例如取 δ = 0.01 \delta =0.01 δ=0.01,则在归一化样本平均分布的情况下需要采样100个样本。
然而,机器学习任务中通常面临高维特征空间,若特征维数为40,则要实现密采样就需要 1 0 80 10^{80} 1080个样本——相当于宇宙中基本粒子的总数。所以密采样在高维特征空间中无法实现,换言之,高维特征样本分布非常稀疏,给机器学习训练、算法采样优化带来了困难。这种高维情形下机器学习任务产生严重障碍现象就称为维数灾难,维数灾难还会以指数级的规模造成计算复杂度上升、存储占用大等问题。
-
宏观一致性
以视频生成为例,需要的像素感受野很大。如何预测目标及结构的长期运动变化?杨小康教授指出现在图像三维重建的一个问题是,重建出来的图像在多个角度呈现的宏观结构可能不一致,比如一个人在做转头的动作,重建出来的人像可能差异较大
-
微观清晰度
如何有效逼近多模分布,避免产生模糊预测效果?包括数据不完整、模型不准确、外部干扰等对图像生成造成的影响。例如,在生成图像时,模型可能会将一些细节部分模糊化或缺失,导致生成的图像与原始图像相比缺乏细节。
3 自主智能新架构
前面说过,生成式模型是全新的人工智能模式,核心是让AI创造出新数据。这就要求AI需要像人一样具有对世界的理解,以及基于此的创新能力。
然而,动物和人类表现出的学习能力和对世界的理解,远远超出了 AI 和机器学习系统。一个青少年可以在大约 20 小时的练习中学会开车,小朋友可以在只需要很少的交流后就学会语言沟通,人类可以在他们从未遇到过的情况下采取行动。
相比之下,无论是传统的判别式模型还是现在着力发展的生成式模型,都需要花费比人类大几个量级的试验进行训练,以便在训练期间可以覆盖最意外的情况。尽管如此,我们最好的AI系统在现实世界任务——例如自动驾驶中仍远未达到人类可靠性。
这是否意味着当下的人工智能学习模式,和人工智能模型的发展产生不适配?杨小康教授以此引出图灵奖得住LeCun提出的全新自主智能架构

在上图所示的自主智能架构中包含多个模块,其中的核心也是最复杂的组件是世界模型,因为要实现通用人工智能,最关键的一点是让机器了解世界是如何运转的,掌握广泛的现实知识,并依据此进行推理。
世界模型可以
- 估计感知模块未提供的关于世界状态的缺失信息,例如杨小康教授介绍的神经流体、物理仿真推理工作;
- 预测世界的合理未来状态,由表征世界状态不确定性的潜在变量进行参数化,这是AI学会推理的基础
4 持续学习与表征解耦
世界模型有一个关键的问题:它必须能够表征世界状态的多种可能预测。然而,自然世界不是完全可以预测的,特别是包含具有对抗性的智能体时尤其如此。但即使世界只包含无生命的物体,它们的行为仍然是混乱的,其状态不能完全观察到。因此,在思考世界模型构建方法时,必须考量
杨小康:世界模型的核心问题是使用什么样的学习范式来训练世界模型;以及世界模型采用什么架构,如何用于决策?
毫不夸张的说,未来几十年阻碍人工智能发展的真正障碍是为世界模型设计架构以及训练范式。
4.1 学习范式
什么叫做学习范式?其实就是一种学习的规范方法。
世界模型中一个难点是灾难性遗忘,因为待学习的视觉控制任务是持续变化的,任务间存在先后顺序,和人一样,学习了新知识的AI就会对旧知识有所淡忘。例如,AI对机械臂的运动轨迹预测不准,对环境中其他物体的形貌预测模糊等等;另一个难点称为多重分布漂移,简单来说,就是在学习过程中假设标签分布固定,而只有输入数据分布的漂移而世界模型由于进行自回归训练,输出视频预测结果,因此不仅存在输入数据分布漂移,还存在输出数据分布漂移,以及不同任务间时空动态信息的分布漂移。

可想而知,如果不采取一个好的学习范式,世界模型的泛化能力并不高。针对此,杨小康教授介绍了三种前沿方法:
- 混合世界模型:变分推断+混合高斯,在各任务上学习独立的隐变量先验,缓解时空动态分布漂移
- 预测式经验回放:经验回放其实是强化学习中的一个概念,原理是通过固定上一任务学习好混合世界模型参数,用于在后续任务上回放旧任务上的图像序列,回放结果与当前任务的真实数据混合,重新训练世界模型M,缓解输入和输出分布漂移
- 持续世界模型:训练任务流式到来,训练环境不断变化;持续学习结束后,回测各历史任务,使持续预测学习中的任意阶段都能很好的保持已学习的时空动态信息,生成结果运动明确,物体清晰
4.2 学习架构
世界模型的第二个问题是学习架构,这里采用的核心思想是解耦。杨小康教授举了个例子来说明什么是解耦:当你驱车前往某地,你的驾驶行为不会对其他人的驾驶产生直接影响,每个人都是独立的智能个体,因此可以抽象出来分别考虑,这就是解耦。
解耦后,可以采用分布式的方法降低计算复杂度和整体系统的架构难度。同时,可对未来自然演变做独立外推从而构建有模型强化学习算法。例如,在自动驾驶场景中,驾驶员决策前,提前预判未来环境中可能的趋势——其他车辆的运动,并作出相应决策

针对表征解耦,杨小康教授主要介绍的是自动驾驶场景,他指出通过状态解耦,可以基于对自然状态的独立推演,生成更具有“危险预判能力”的驾驶策略。
总之,解耦架构可以使世界模型的表征难度下降,各组件间依赖降低,在线计算效率提升,是主流学习架构之一。
5 生成式AI与元宇宙
元宇宙(Metaverse)是指一个虚拟的、完全由计算机技术构建的多人在线世界,其概念最早出现在科幻小说中,如尼尔·斯蒂芬森的《雪崩》和安德鲁·尼克松的《Ready Player One》。这个世界是一个可交互的、持久存在的虚拟空间,可以模拟真实世界的各种场景和活动,并允许用户在其中创建、定制和掌控自己的数字化身份。在元宇宙中,用户可以像在现实世界中一样进行各种活动,例如购物、社交、游戏、学习、工作等。用户可以与其他玩家互动,建立社交关系,并在元宇宙中建立自己的数字资产,例如虚拟地产、虚拟货币、虚拟商品等。这些数字资产可以在元宇宙中进行交易,并且可以与现实世界的资产进行交换或转化。

在元宇宙中,人依然是世界的主体,而生成式人工智能就给数字虚拟人的建模提供了有力的工具。使用生成式人工智能,可以大规模、高效地产生高拟真、可泛化、可驱动的虚拟数字人,相比传统计算机图形学的方法可以降低元宇宙数字人的成本。
杨小康教授还介绍了几种前沿方法,例如鲁棒纹理补全的生成对抗网络、基于物理的隐式可微渲染函数等。
元宇宙的发展将会带来许多潜在的商业机会和经济影响。例如,元宇宙中的数字资产可以为开发者和用户带来收入,从而促进元宇宙经济的发展。此外,元宇宙还可以为各种行业提供新的营销和广告机会,从而扩大市场规模。最后,元宇宙也可能会改变人类社会的基本结构和价值观,例如重新定义工作、教育和社交关系的本质。从元宇宙发展的角度看,生成式人工智能的意义重大。
6 智慧文档:赋能数字化转型

上海交通大学模式识别与智能系统博士郭丰俊进一步介绍了合合信息在智能文档处理方面的最新工作,深刻体现了前沿技术赋能数字化转型的源动力。郭丰俊老师主要讲解了
- ROI提取:单区域提取、多区域提取
- 形变矫正:倾斜透视矫正、弯曲矫正
- 图像恢复:阴影去除、摩尔纹去除、反光去除
- 质量增强:清晰度提升、增强锐化
- …
等众多文档智能处理技术及其应用场景,例如表格矫正、文件手写擦除、电子屏幕去除摩尔纹干扰等。


这些智能文档处理应用极大提高了信息的处理效率和精度。与人工处理相比,智能文档处理具有更高的处理速度和准确性,能够自动化地进行数据抽取、识别、分类和分析等操作。这样,企业和个人可以更快地完成文件处理,减少重复性工作和出错率,提高工作效率。同时,也有助于信息的共享和利用。智能文档处理技术可以将数据转化为结构化的信息,使得文档内容更容易被计算机识别和处理。这样一来,不同部门和人员可以更方便地共享文件和信息,并快速获取所需的数据,从而促进了企业内部信息的流动和协作。
听完郭丰俊老师的讲解,深刻体会到智能文档处理技术对数字化转型的推动作用。相信通过应用智能文档处理技术,企业和个人可以更好地管理和利用信息,提高生产和服务的质量和效率。
7 结语
我相信,在不久的将来,生成式人工智能会更智能化和自适应,它们能够更好地理解我们的语言和文化背景,并适应不同场景和情境;更加多样化和具有创造力,以图像、音频、视频等多种模态,为人类带来更加丰富多彩的体验。同时,人工智能会更加可信和安全,能够识别和纠正错误和偏见,并能够避免生成虚假信息和恶意内容。
最后,感谢合合信息这次以图文智能处理与多场景应用技术展望为主题的系列技术交流活动,让我近距离接触学术界、工业界领军人物带来的前沿技术和研究成果分享。近年来,合合信息在智能文字识别技术先后在ICDAR、ICPR等人工智能国际竞赛中斩获15项冠军,学术成果在CVPR、AAAI、ACL等顶会上发表,相关项目获中国图象图形学学会(CSIG)科技进步奖二等奖。

除了技术深度,在科技温度上合合信息也展现了自己的能力,例如钟鼎文识别、古彝文识别、甲骨文金文识别等,相信未来合合信息会给我们带来更多期待。

