
热门标签
热门文章
- 1经典排序算法的VC实现_vc实现文件按时间顺序排列
- 22024年软件测试最全当前软件测试市场现状,2024年最新跳槽大厂必看
- 3模块化 git管理_gitlab 一个项目多个模块
- 4SpringBoot狂神08-(实现WebMvcConfigurer扩展配置)
- 5网络分析工具介绍_常见的网络分析工具有哪些及其区别
- 6利用python求解规划问题_python规划求解
- 7我好像发现了车载测试面试成功的秘籍
- 8视觉Transformer笔记_transformerconv
- 9Node.js的安装和环境配置以及历史版本_nodejs历史版本安装及环境配置
- 10KAN网络技术最全解析—最热KAN能否干掉MLP和Transformer?(收录于GPT-4/ChatGPT技术与产业分析)
当前位置: article > 正文
论文阅读_大模型优化_DeepSeek-V2
作者:从前慢现在也慢 | 2024-05-20 09:22:54
赞
踩
论文阅读_大模型优化_DeepSeek-V2
英文名称: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model 中文名称: DeepSeek-V2:强大、经济高效的专家混合语言模型 链接: http://arxiv.org/abs/2405.04434v2 代码: https://github.com/deepseek-ai/DeepSeek-V2 作者: DeepSeek-AI 机构: DeepSeek-AI 深度探索公司 日期: 2024-05-07 |
1 读后感
DeepSeek 最近推出的 V2 版本,无疑是当前性价比最高的选择。直观地讲:KIMI 的价格是 12 元/M tokens,Chat 的价格约为 3.5 元/M,GPT 4o 的价格约为 35 元/M。然而,DeepSeek 的价格仅为 1 元/M(这是按照输入计算的,输出通常是输入的两倍,美元兑换按 7 计算)。
我在之前调研代码模型的时候就注意到 DeepSeek 的单模型在排名中很靠前。从论文和网站数据可以看到模型效果在开源领域,甚至在国内开源 + 闭源领域都算是很能打了,因为是一家中文公司,对中文也更加友好。从实验结果来看,它是一种对中文,英文,编码各方面水平比较均衡的模型。
DeepSeek 是一个开源模型,理论上可以在本地部署,但 MoE 的方式虽然快速,却占用大量内存,硬件成本也高。比起这样,购买他们的服务可能更划算。
本篇就来看看 DeepSeek 是如何实现降本增效的。
2 摘要
- 目标:DeepSeek-V2 是一个 MoE 语言模型,其特点是经济高效的训练和推理。
- 方法:DeepSeek-V2 采用了创新的架构,包括 Multi-head Latent Attention(MLA)和 DeepSeekMoE。MLA 通过将 Key-Value(KV)缓存显著压缩为潜在向量,确保了高效的推理;而 DeepSeekMoE 通过稀疏计算实现了经济高效的模型训练。
- 结论:与 DeepSeek 67B 相比,DeepSeek-V2 表现更强,同时节省了 42.5% 的训练成本,将 KV 缓存减少了 93.3%,并将最大生成吞吐量提升了 5.76 倍。
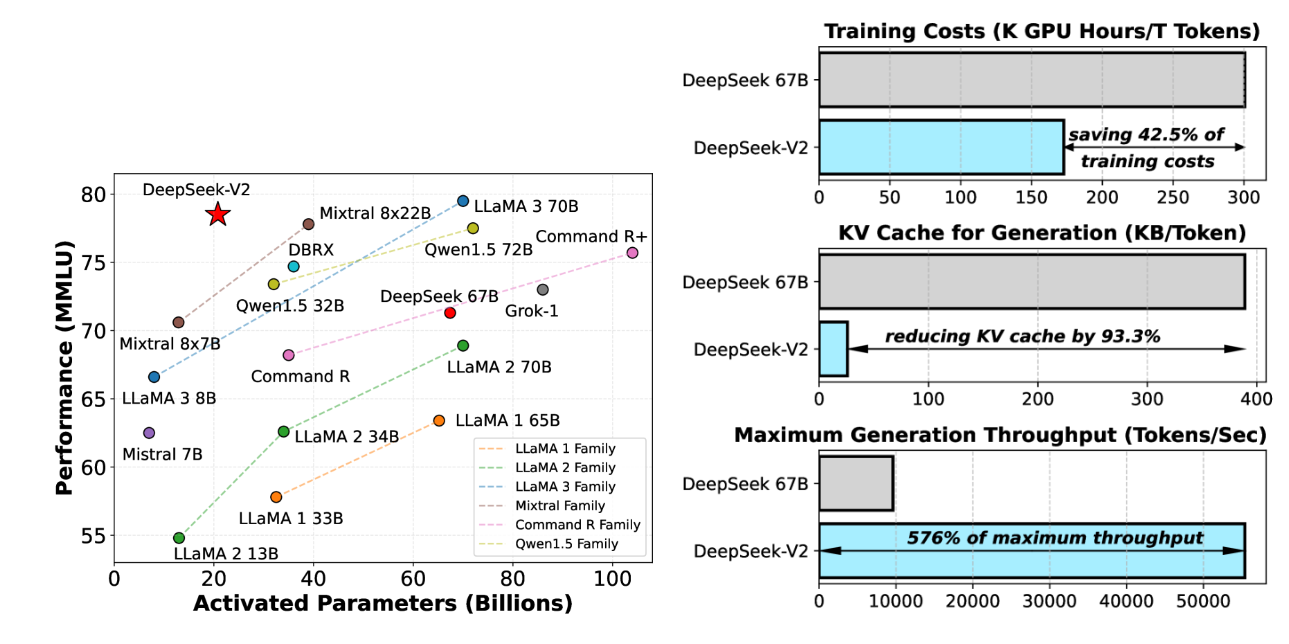
图 -1,左侧展示模型的理解能力,右侧展示成本和效率的改进。
3 方法
3.1 模型参数
- 总共包含了 236B 参数
- 其中每个 token 激活的参数为 21B
- 支持 128K 个 token 的上下文长度
3.2 架构改进
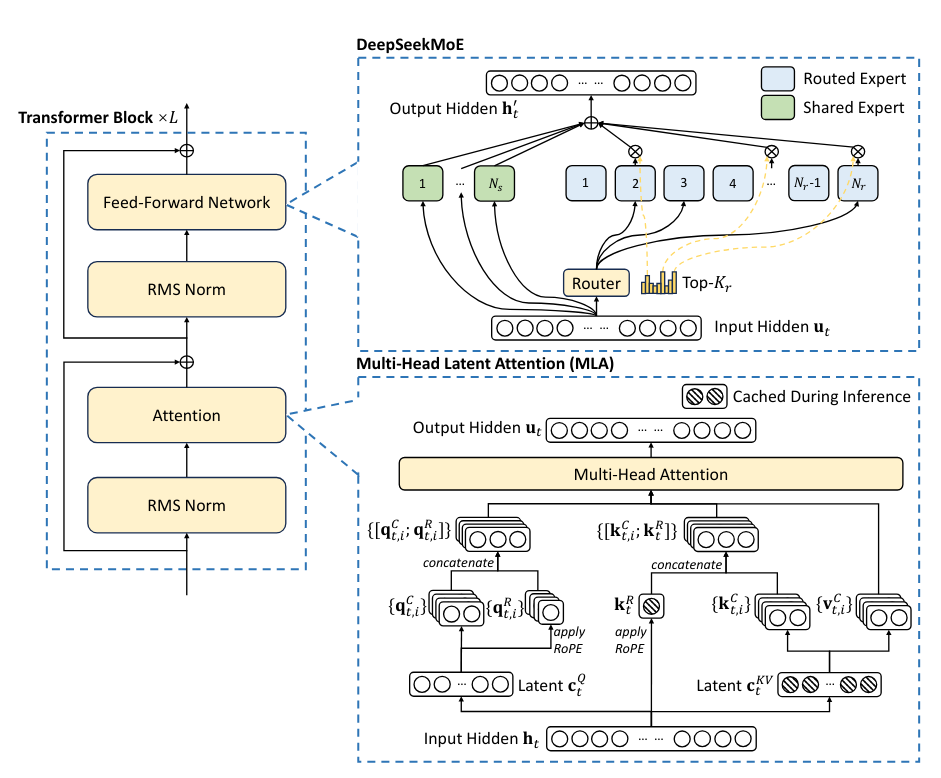
- 对于前馈网络(FFN),采用细粒度的专家分割和共享的专家隔离,以提高专家专业化的潜力。论文阅读_MoE_Switch Transformers
- 多头潜在注意力(MLA),配备低秩键值联合压缩的注意力机制。从而提高了推理效率,下面展开说明 MLA。
3.2.1 Multi-Head Latent Attention 多头潜在注意力
多头注意力(MHA)的键值(KV)缓存(Vaswani et al.,2017)对推理 LLMs 效率构成了重大障碍。为了减少 KV 缓存,提出了多查询注意力(MQA)和分组查询注意力(GQA)。它们需要较小量级的 KV 缓存,但它们的表现不如 MHA。
这篇文章中提出了低秩键值结合压缩。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/597116
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

