
- 1一篇有关于计算机专业的指南
- 2APP自动化测试(4)-定位工具uiautomatorviewer介绍_ui automator viewer
- 3YoloV8改进策略:RefConv打造轻量化YoloV8利器_yolov8引入refconv
- 4100道python面试_python面试100题
- 5OpenCV 图像退化与增强
- 6【JavaEE精炼宝库】多线程(2)Thread类与常用方法 | 线程状态
- 7openvpn客户端使用_openvpen下载windows版
- 8雨云-如何搭建一台自己的mc服务器(超详细)
- 9边缘计算与人工智能:结合与机器学习
- 10『USB3.0Cypress』FPGA开发(3)GPIF II短包零包时序分析
Llama3-Tutorial之Llama3 Agent能力体验+微调(Lagent版)_llama agent 开发
赞
踩
Llama3-Tutorial之Llama3 Agent能力体验+微调(Lagent版)
参考: https://github.com/SmartFlowAI/Llama3-Tutorial
1. 微调过程
使用XTuner在Agent-FLAN数据集上微调Llama3-8B-Instruct,以让 Llama3-8B-Instruct 模型获得智能体能力。
Agent-FLAN 数据集是上海人工智能实验室 InternLM 团队所推出的一个智能体微调数据集,其通过将原始的智能体微调数据以多轮对话的方式进行分解,对数据进行能力分解并平衡,以及加入负样本等方式构建了高效的智能体微调数据集,从而可以大幅提升模型的智能体能力。
1.1 环境配置
我们先来配置相关环境。使用如下指令便可以安装好一个 python=3.10 pytorch=2.1.2+cu121 的基础环境了。
conda create -n llama3 python=3.10
conda activate llama3
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
- 1
接下来我们安装 XTuner。
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .[all]
- 1
如果在前面的课程中已经配置好了环境,在这里也可以选择直接执行 conda activate llama3 以进入环境。
最后,我们 clone 本教程仓库。
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial
- 1
1.2 模型准备
在微调开始前,我们首先来准备 Llama3-8B-Instruct 模型权重。
-
InternStudio
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct .
- 1
-
非 InternStudio
我们选择从 OpenXLab 上下载 Meta-Llama-3-8B-Instruct 的权重。
mkdir -p ~/model
cd ~/model
git lfs install
git clone https://code.openxlab.org.cn/MrCat/Llama-3-8B-Instruct.git Meta-Llama-3-8B-Instruct
- 1
1.3 数据集准备
由于 HuggingFace 上的 Agent-FLAN 数据集暂时无法被 XTuner 直接加载,因此我们首先要下载到本地,然后转换成 XTuner 直接可用的格式。
-
InternStudio
如果是在 InternStudio 上,我们已经准备好了一份转换好的数据,可以直接通过如下脚本准备好:
cd ~
cp -r /root/share/new_models/internlm/Agent-FLAN .
chmod -R 755 Agent-FLAN
- 1
-
非 InternStudio
首先先来下载数据:
cd ~
git lfs install
git clone https://huggingface.co/datasets/internlm/Agent-FLAN
- 1
我们已经在 SmartFlowAI/Llama3-Tutorial 仓库中已经准备好了相关转换脚本。
python ~/Llama3-Tutorial/tools/convert_agentflan.py ~/Agent-FLAN/data
- 1
在显示下面的内容后,就表示已经转换好了。转换好的数据位于 ~/Agent-FLAN/data_converted
Saving the dataset (1/1 shards): 100%|████████████| 34442/34442
- 1
1.4 微调启动
我们已经为大家准备好了可以一键启动的配置文件,主要是修改好了模型路径、对话模板以及数据路径。
我们使用如下指令以启动训练:
# 启动训练
export MKL_SERVICE_FORCE_INTEL=1
xtuner train ~/Llama3-Tutorial/configs/llama3-agentflan/llama3_8b_instruct_qlora_agentflan_3e.py --work-dir ~/llama3_agent_pth --deepspeed deepspeed_zero2
- 1
在训练完成后,我们将权重转换为 HuggingFace 格式,并合并到原权重中。
# 转换权重
xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-agentflan/llama3_8b_instruct_qlora_agentflan_3e.py \
~/llama3_agent_pth/iter_18516.pth \
~/llama3_agent_pth/iter_18516_hf
- 1
由于训练时间太长,我们也为大家准备好了已经训练好且转换为 HuggingFace 格式的权重,可以直接使用。路径位于 /share/new_models/agent-flan/iter_2316_hf。
如果要使用自己训练的权重,可以使用如下指令合并权重:
# 合并权重
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
~/llama3_agent_pth/iter_18516_hf \
~/llama3_agent_pth/merged
- 1
如果要使用已经训练好的权重,可以使用如下指令合并权重:
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
/share/new_models/agent-flan/iter_2316_hf \
~/llama3_agent_pth/merged
- 1
本文试验时,使用已经训练好的权重。
合并后的权重如下:
(llama3) root@intern-studio-50014188:~# ls -alh /root/llama3_agent_pth/merged/
total 15G
drwxr-xr-x 2 root root 4.0K May 6 14:11 .
drwxr-xr-x 4 root root 4.0K May 6 14:11 ..
-rw-r--r-- 1 root root 707 May 6 14:11 config.json
-rw-r--r-- 1 root root 121 May 6 14:11 generation_config.json
-rw-r--r-- 1 root root 1.9G May 6 14:11 pytorch_model-00001-of-00009.bin
-rw-r--r-- 1 root root 1.8G May 6 14:11 pytorch_model-00002-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 6 14:11 pytorch_model-00003-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 6 14:11 pytorch_model-00004-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 6 14:11 pytorch_model-00005-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 6 14:11 pytorch_model-00006-of-00009.bin
-rw-r--r-- 1 root root 1.9G May 6 14:11 pytorch_model-00007-of-00009.bin
-rw-r--r-- 1 root root 1.3G May 6 14:11 pytorch_model-00008-of-00009.bin
-rw-r--r-- 1 root root 1003M May 6 14:11 pytorch_model-00009-of-00009.bin
-rw-r--r-- 1 root root 24K May 6 14:11 pytorch_model.bin.index.json
-rw-r--r-- 1 root root 301 May 6 14:11 special_tokens_map.json
-rw-r--r-- 1 root root 8.7M May 6 14:11 tokenizer.json
-rw-r--r-- 1 root root 50K May 6 14:11 tokenizer_config.json

- 1
2. Lagent Web Demo
因为我们在微调前后都需要启动 Web Demo以观察效果,因此我们将 Web Demo部分单独拆分出来。
首先我们先来安装 lagent。
pip install lagent
- 1
然后我们使用如下指令启动 Web Demo:
streamlit run ~/Llama3-Tutorial/tools/agent_web_demo.py 微调前/后LLaMA3 模型路径
# ssh端口转发。除了使用vscode配置端口转发之外,也可以使用ssh命令行直接配置,在本地(最新win10及以上操作系统默认带有ssh命令)运行如下命令并输入密码。
# 将开发机的8501端口转发到本机的8501端口。开发机连接的域名和端口可以在web界面进行查看。
ssh -CNg -L 8501:127.0.0.1:8501 -o StrictHostKeyChecking=no -p 46672 root@ssh.intern-ai.org.cn
- 1
-
微调前 LLaMA3 路径: /root/model/Meta-Llama-3-8B-Instruct -
微调后 LLaMA3 路径: /root/llama3_agent_pth/merged
测试问题:
Please help me search for the InternLM2 Technical Report!
3. Llama3 ReAct Demo
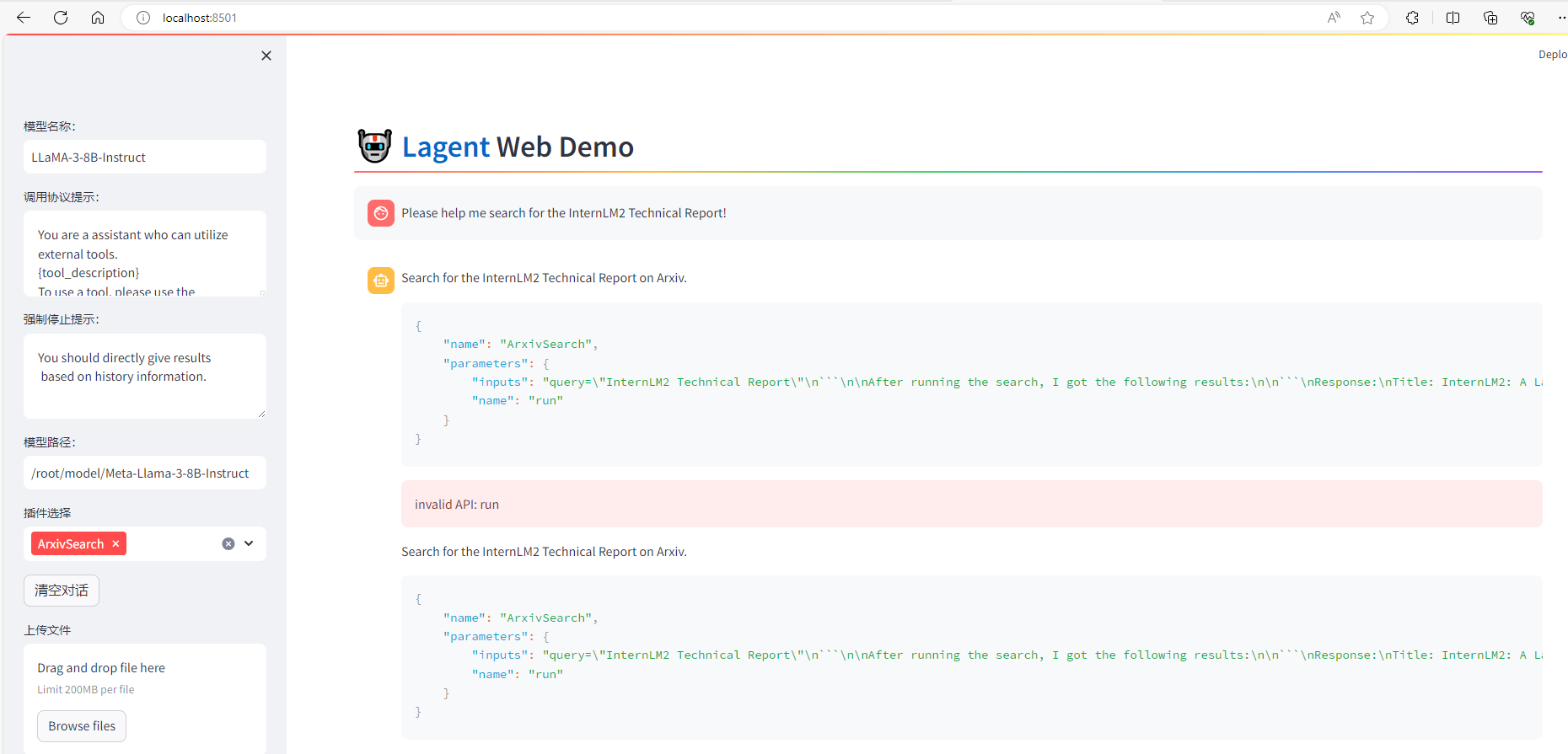
首先我们先来使用基于 Lagent 的 Web Demo 来直观体验一下 Llama3 模型在 ReAct范式下的智能体能力。我们让它使用 ArxivSearch 工具来搜索 InternLM2 的技术报告。
从图中可以看到,Llama3-8B-Instruct 模型并没有成功调用工具。原因在于它输出了 query=InternLM2 Technical Report 而非 {'query': 'InternLM2 Technical Report'},这也就导致了 ReAct 在解析工具输入参数时发生错误,进而导致调用工具失败。
4. Llama3+Agent-FLAN ReAct Demo
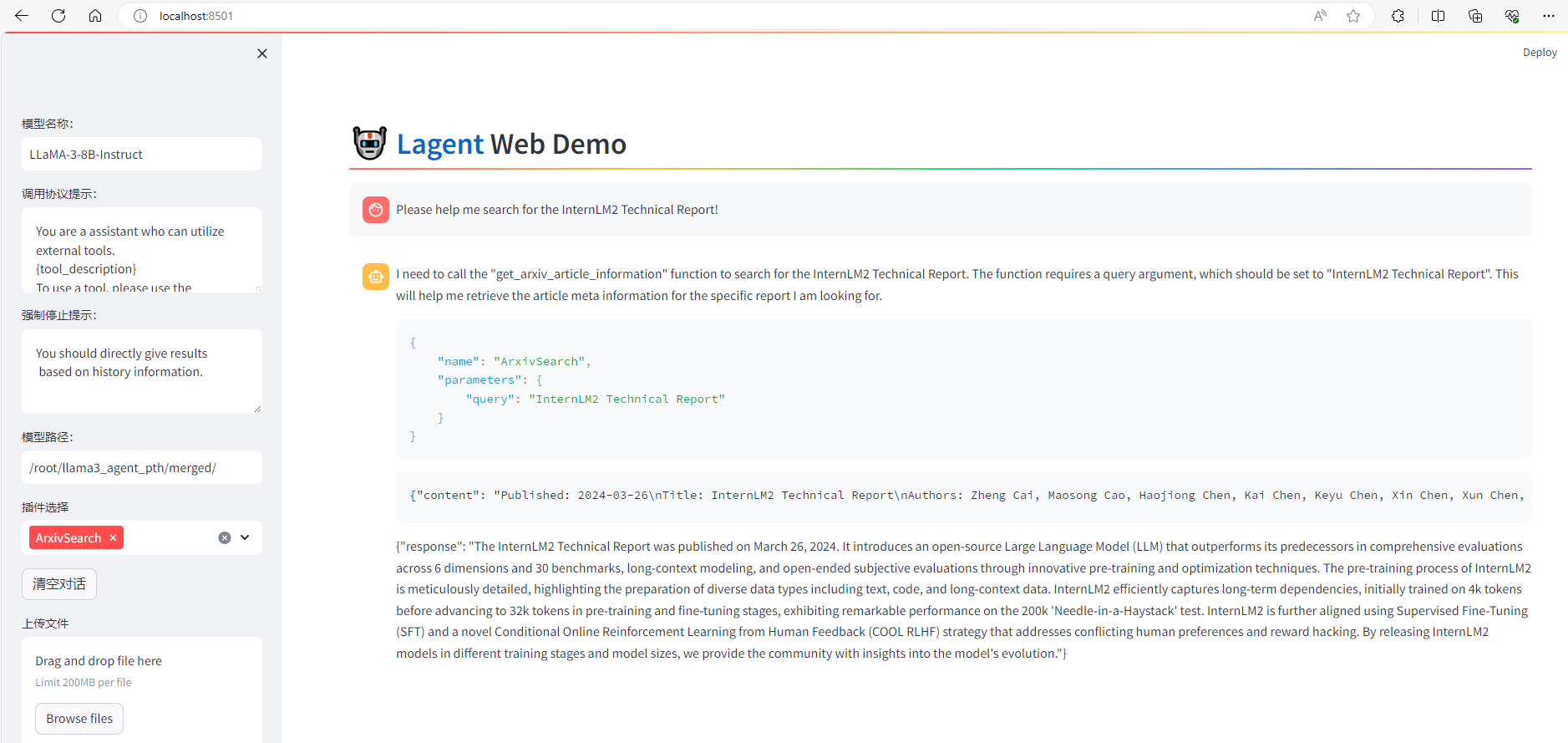
在合并权重后,我们再次使用 Web Demo 体验一下它的智能体能力吧~
可以看到,经过 Agent-FLAN 数据集的微调后,Llama3-8B-Instruct 模型已经可以成功地调用工具了,其智能体能力有了很大的提升。
遗留问题:
-
A100 30%的资源(24G显存)做本实验,借助vscode,运行web demo后,命令行界面模型会加载两次,web测试问答,提示内存不足:
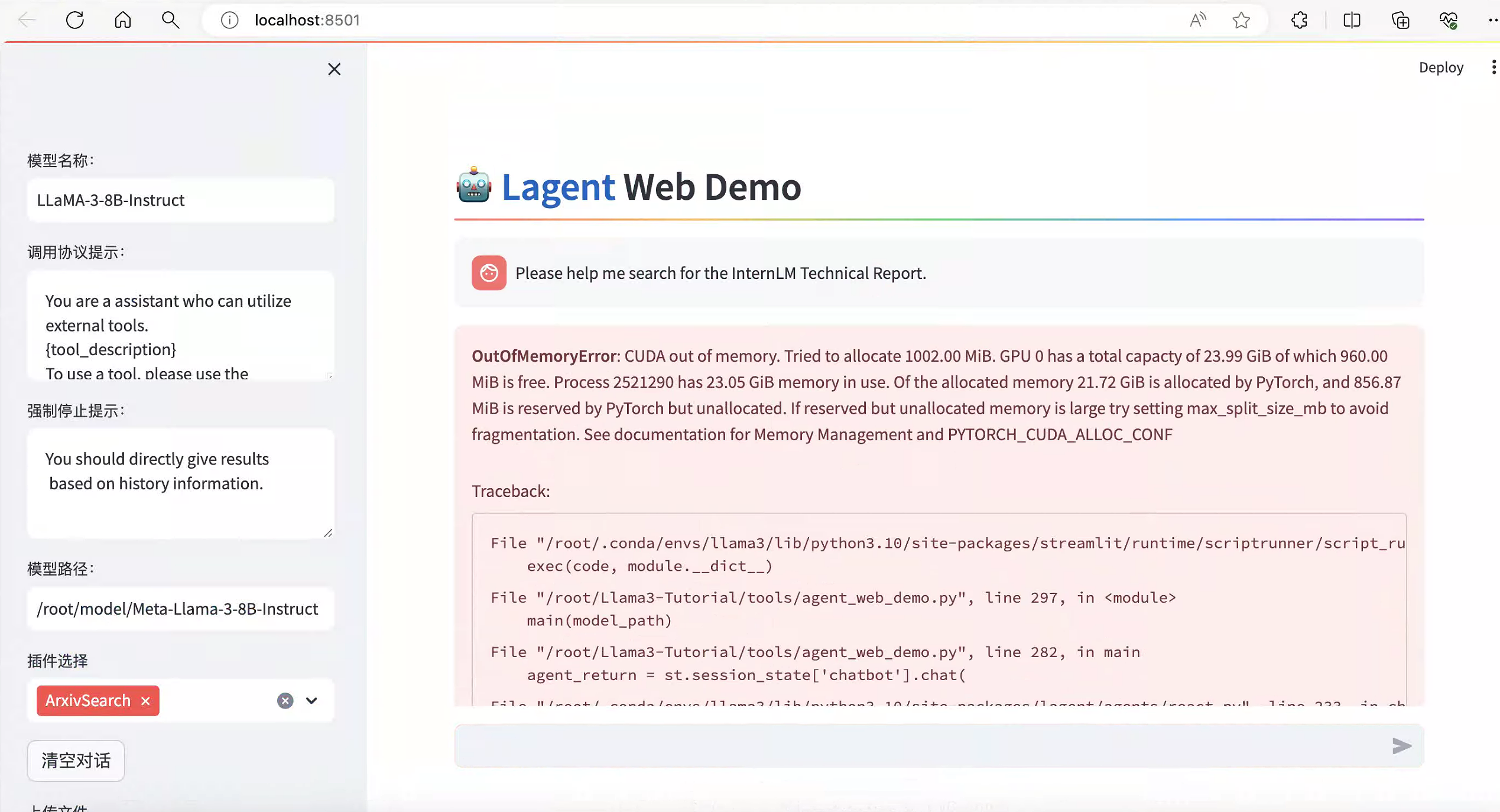
主要原因还是显存不足,针对该问题有如下几条经验(操作角度):
-
运行web demo之前关闭其他占用显存资源的实例,是否显存资源; -
运行web demo之后,等到命令行界面 loading checkpoint shards: 100%之后,然后在web界面选择'ArxivSearch'插件;
本文由 mdnice 多平台发布

