
- 12024年中国电机工程学会杯数学建模思路 - 案例:感知机原理剖析及实现
- 2阿里二面:RocketMQ 消费失败了,怎么处理?_rocketmq消费失败
- 3如何选择一款安全高效的数据自动同步工具?
- 4numpy函数_np. c
- 5C++上位软件通过Snap7开源库访问西门子S7-200/合信M226ES数据块的方法_snap7库编译
- 6专注docker安全:Security Scanning
- 7自然语言处理从入门到应用——预训练模型总览:从宏观视角了解预训练模型_大模型预训练的算力
- 8Llama3本地部署与高效微调入门_llama3-8b开源如何部署微调
- 9免费的内网穿透之HTTP穿透(钉钉)_dingtalk-design-cli@latest
- 10Springboot+rabbitMQ(连接多个rabbitMQ)代码实例_springboot连接多个rabbitmq 简单一些
力扣LeetCode138. 复制带随机指针的链表 两种解法(C语言实现)_力扣138
赞
踩
目录
题目链接
138. 复制带随机指针的链表![]() https://leetcode-cn.com/problems/copy-list-with-random-pointer/
https://leetcode-cn.com/problems/copy-list-with-random-pointer/

题目分析
题目定位:
本题属于链表中较为综合的题目,考验做题者的思想以及用代码实现的能力,能够真正理解并做出此题需要对链表有相对熟练的掌握度。
话不多说,先来分析题目:
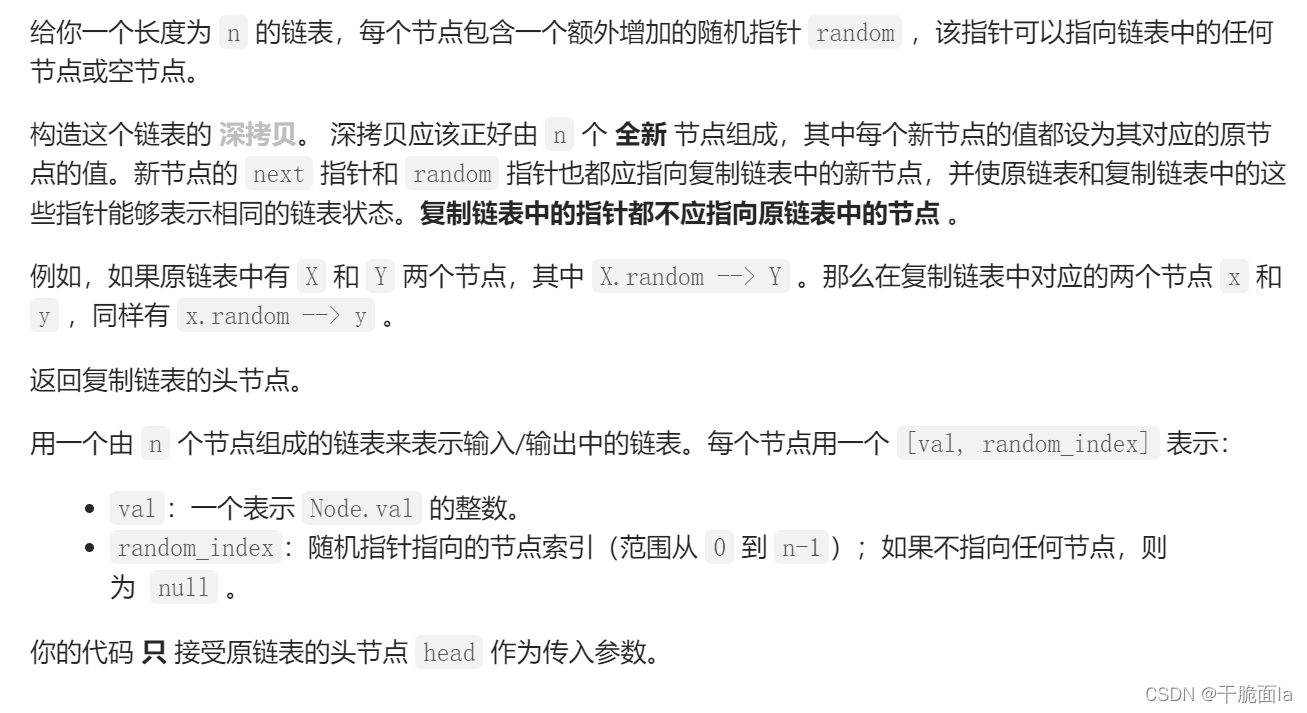
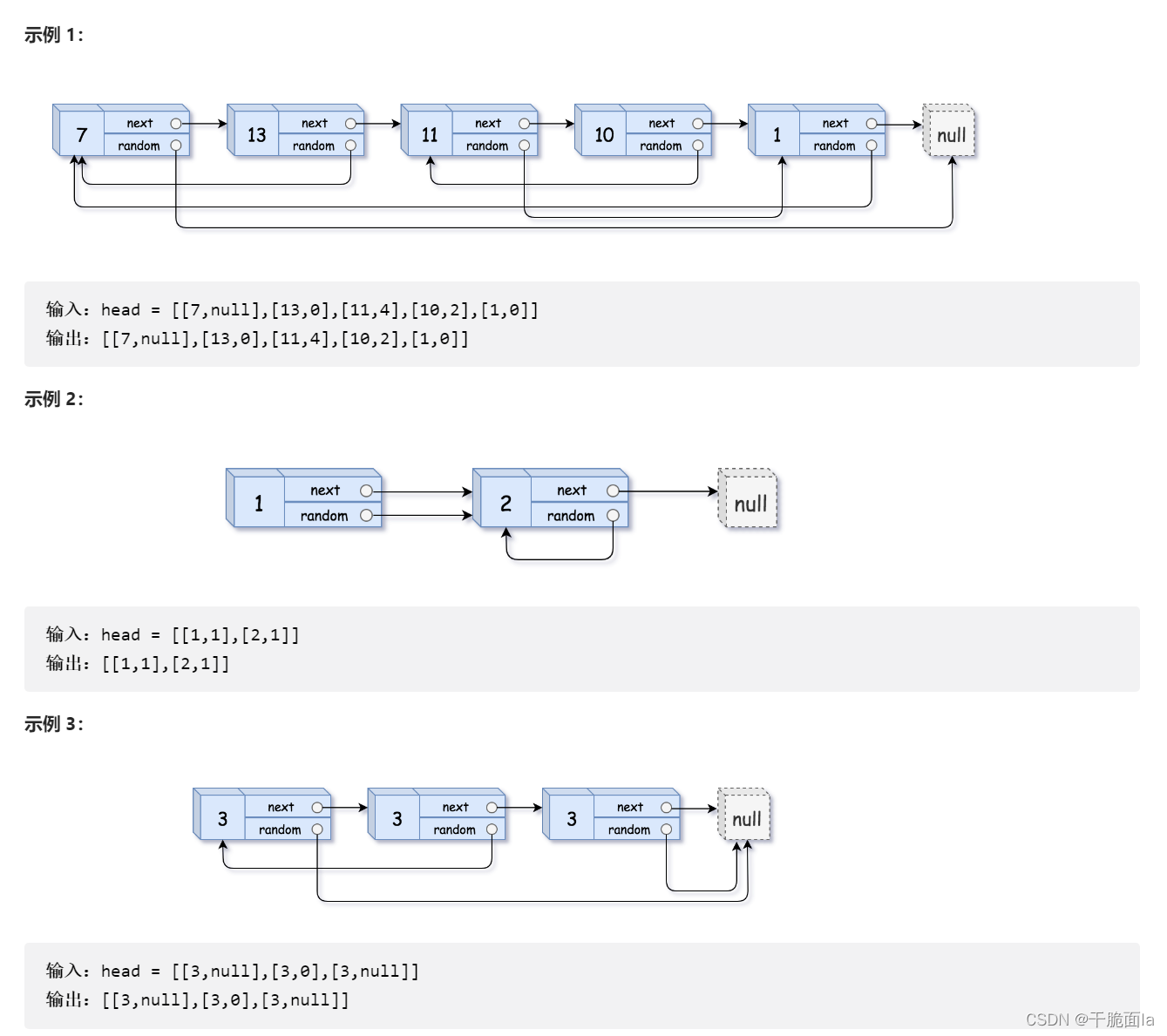
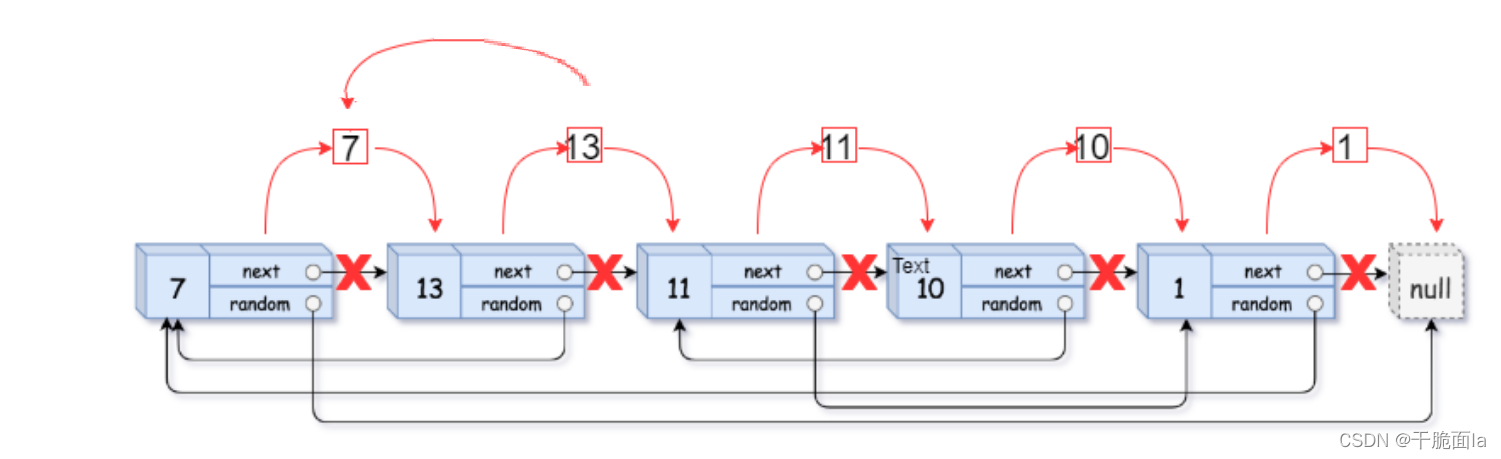
题目是想让我们构造一个链表的拷贝,也就是开辟一块一模一样的链表,但是本题中的链表,又和普通的单链表不一样,如图:
我们发现,链表中每一个节点中的结构体成员除了val和next之外,还有一个random,而random是指向链表中的任意一个节点,甚至可以是NULL。
因此要拷贝这个链表的难度就在于,如何使拷贝的链表中每一个节点的random指向其对应的节点呢?

解题思路
解题思路1(粗暴但是复杂度高)
第1步.先忽略原链表的random指针,对其进行复制,如图: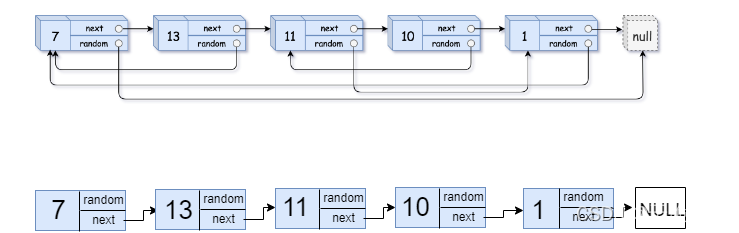
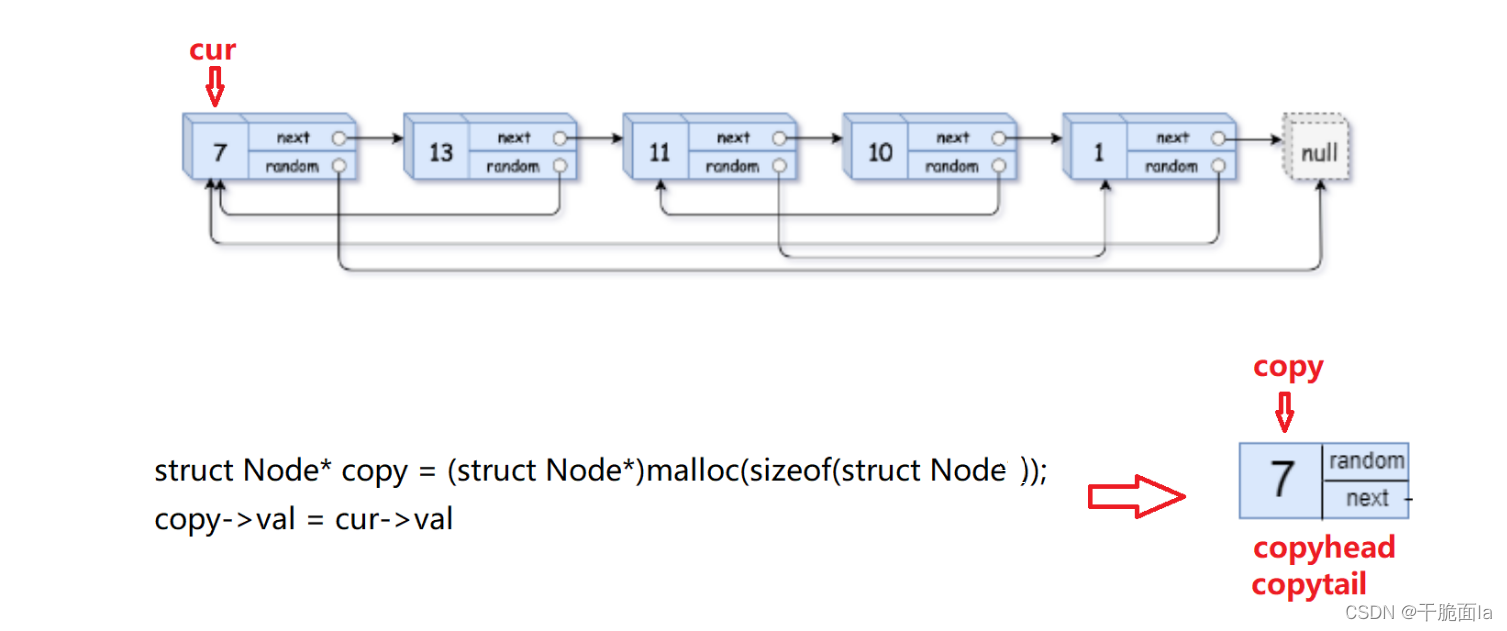
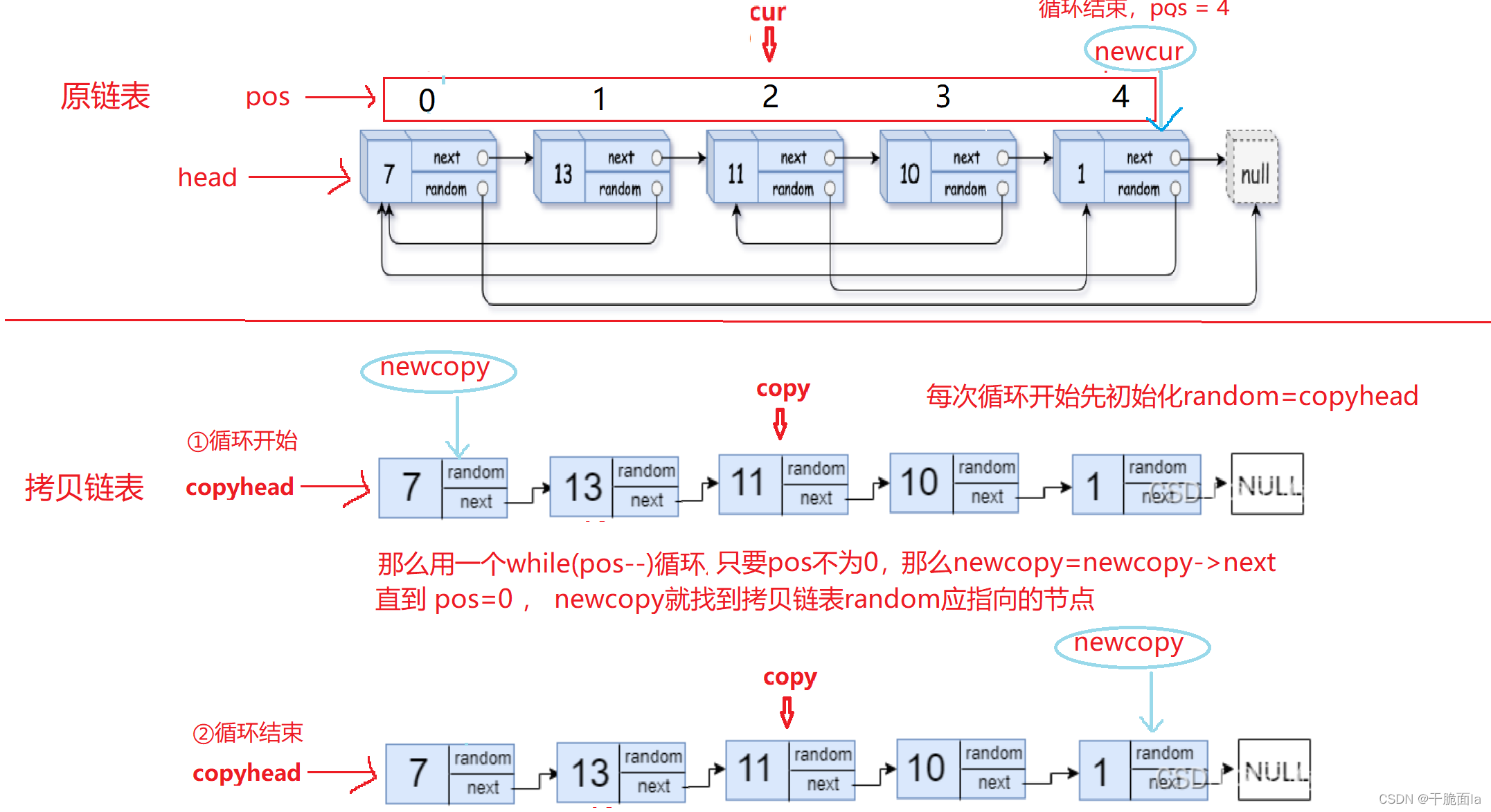
(1)定义两个struct Node*类型的指针copyhead和copytail来储存复制链表的头和尾,并初始化为NULL;并且定义一个struct Node*类型的指针cur指向head
(2)若原链表不为空,则此时cur指向第一个节点。用malloc开辟一块空间作为复制的第一个节点,并定义一个copy指针来保存,并将copy->val改为cur->val,并让copyhead和copytail指向copy节点
(3)让cur移向下一个节点。用malloc开辟一块空间作为复制的第二个节点,并让copy指向它,并将copy->val改为cur->val,先让copytail->next指向copy来连接两个节点,再让copytail指向copy节点(更新尾节点)。
像这样一直循环下去直到cur指向NULL,循环结束,最后再让copytail->next = NULL,此时便完成了第一步的复制操作
此时我们便可以根据图解来写代码

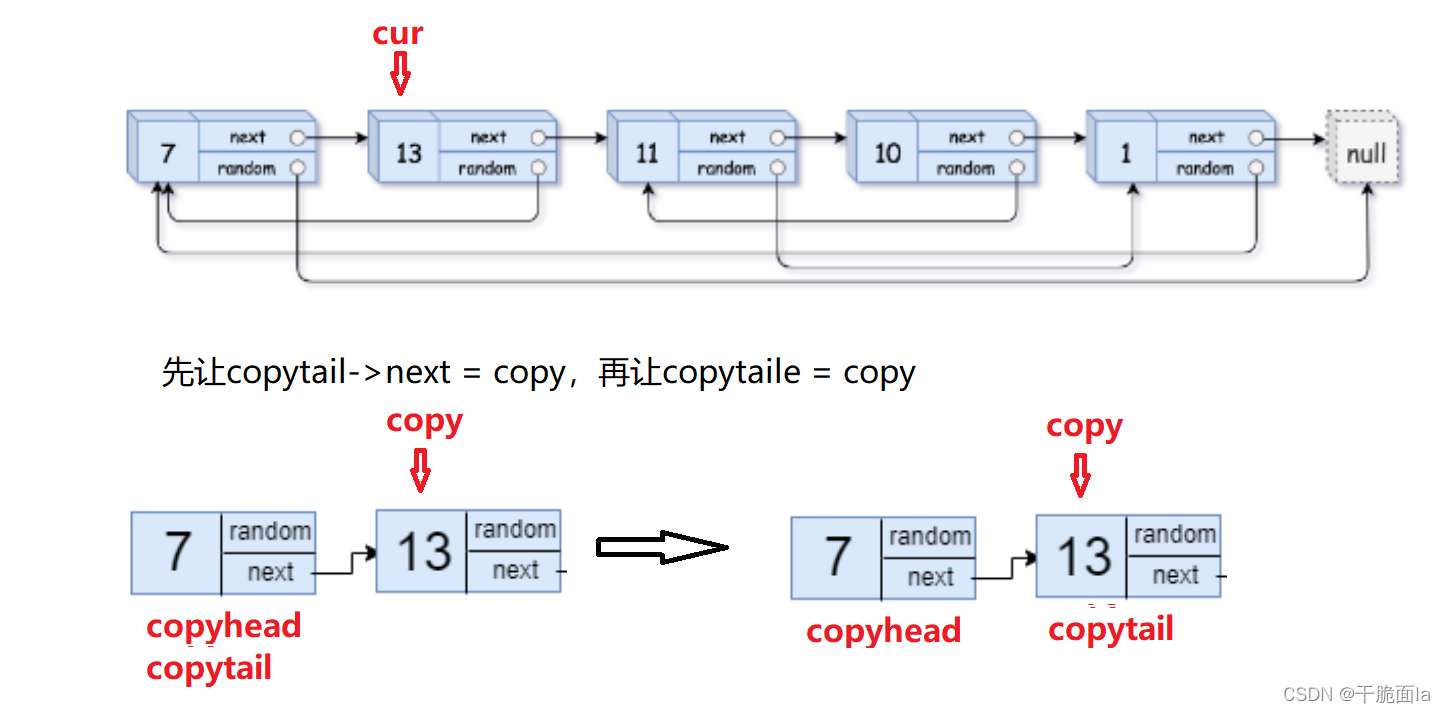
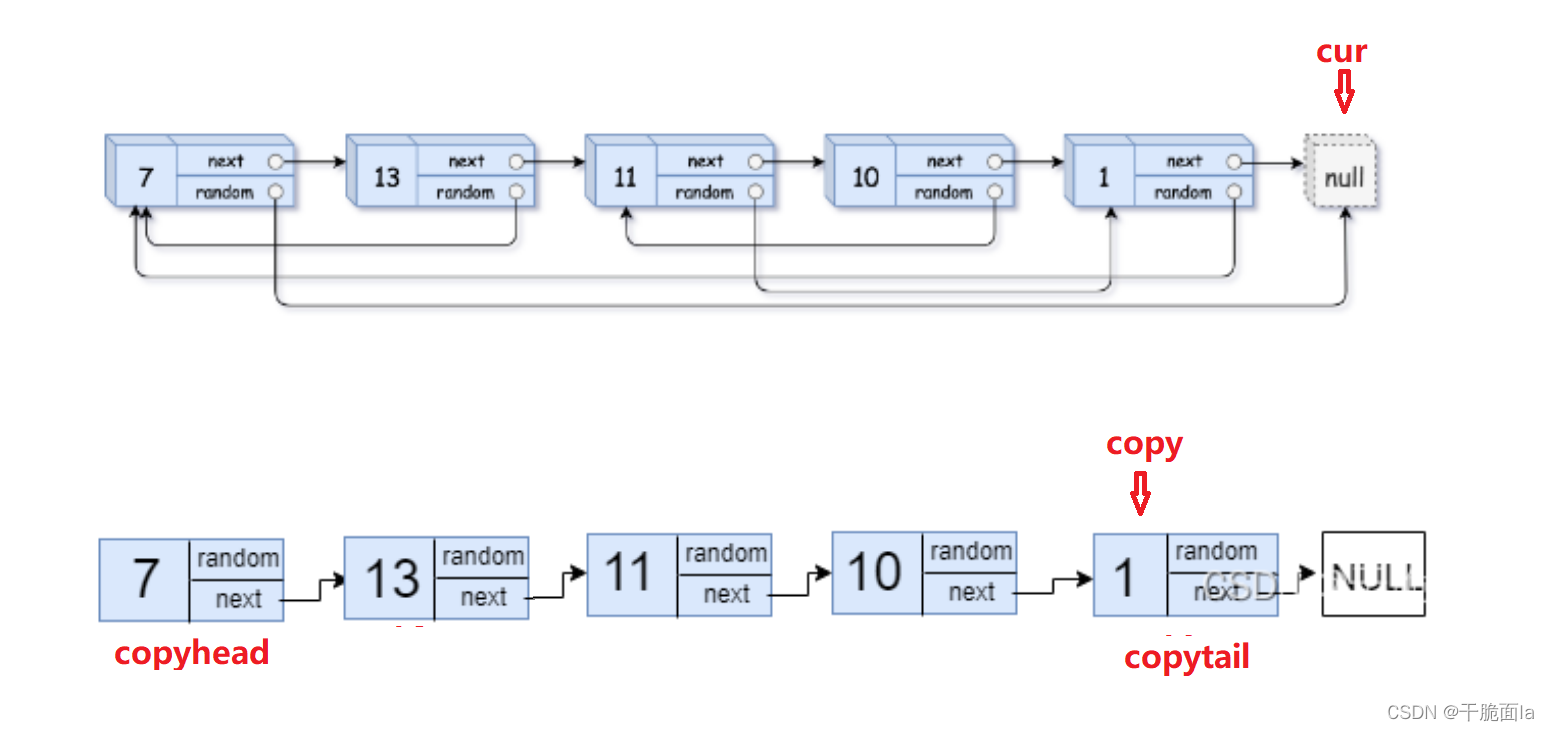
第2步.处理拷贝链表的random指针
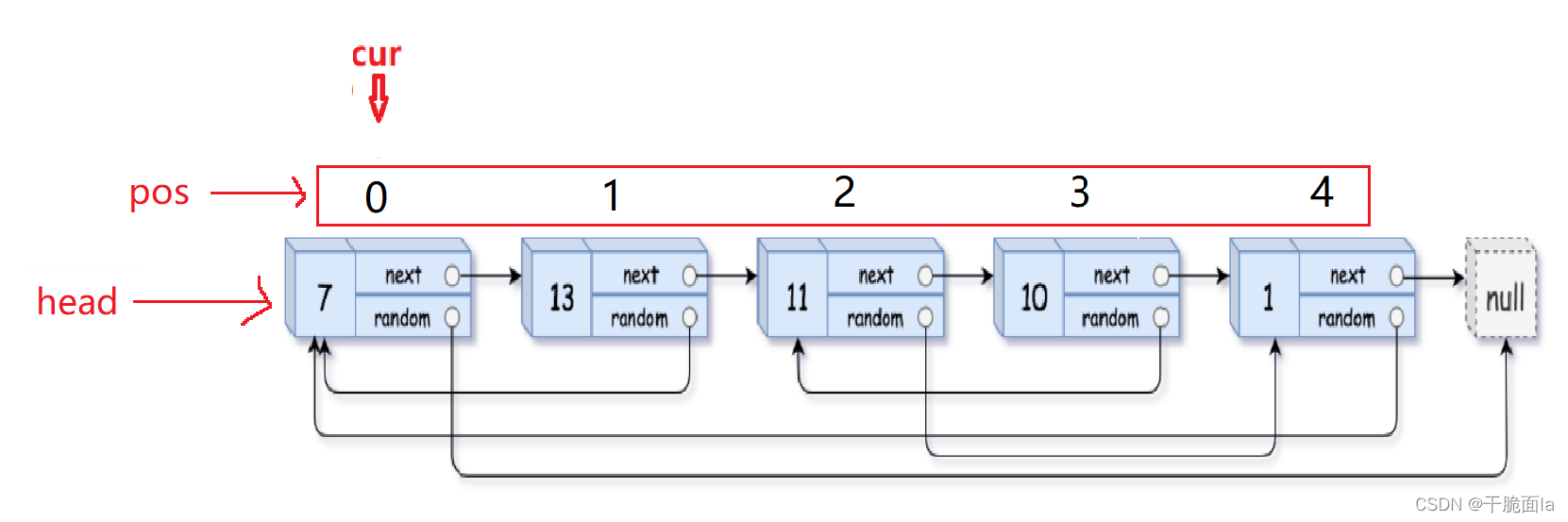
(1)查找原链表中的random指向的节点到底是第几个节点,并定义一个变量pos来记录下来
①如果原链表random指向NULL,则不需要找pos
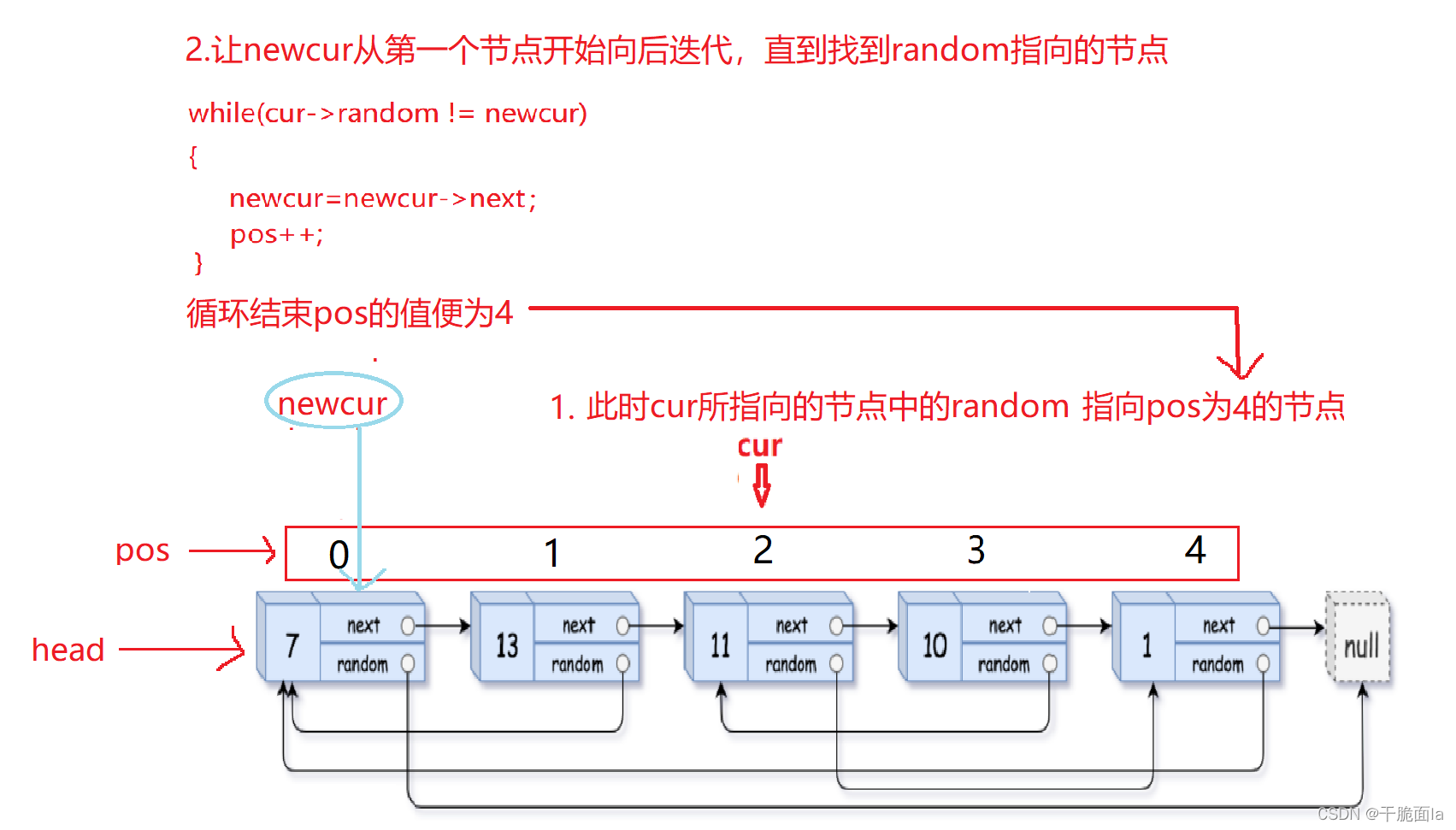
②如果原链表的random指向链表中的节点,每次循环开始可以初始化一个新的指针newcur=head,再对newcur进行迭代,每当newcur向后走一次,pos加一,直到newcur == cur->random的时候,循环结束,举一个例子:
(2)用一个循环来使拷贝链表中random指向其对应的节点
①如果原链表的random指向NULL,那么便很简单:拷贝的random直接置为NULL;
②如果原链表的random指向链表中的节点,每次循环开始可以初始化一个新的指针newcopy=copyhead,那么拷贝的random则可以通过一个循环来找到pos所对应的第几个节点,接着上面的例子:
根据图解我们可以写出代码:
 题解一总结:优点是这种思路比较容易想到并且理解;缺点是由于找到原链表找到random指向的节点的pos的过程,每个节点的复杂度为O(n),又有n个节点,因此这种解法的时间复杂度为O(n²),并不是一个优秀的解法,接下来将为大家讲另一种优秀的解法。
题解一总结:优点是这种思路比较容易想到并且理解;缺点是由于找到原链表找到random指向的节点的pos的过程,每个节点的复杂度为O(n),又有n个节点,因此这种解法的时间复杂度为O(n²),并不是一个优秀的解法,接下来将为大家讲另一种优秀的解法。
解题思路2(巧妙并且复杂度低)
第1步 把拷贝节点连接再原节点的后面
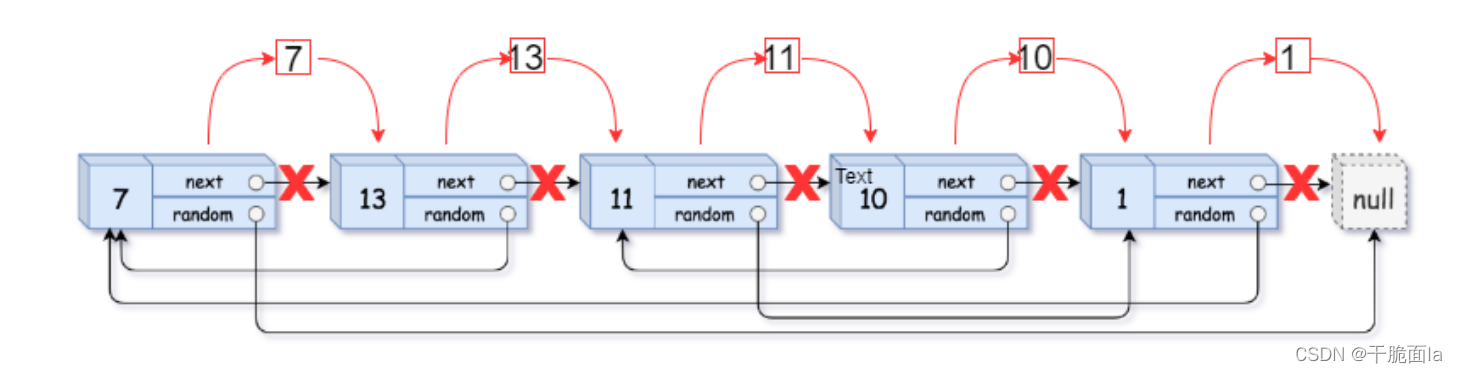
用这种方式处理是为了方便找到拷贝链表的random应该指向第几个节点,random指向的这个节点的下一个节点就是拷贝链表要找的random节点
根据图解我们可以写出代码:
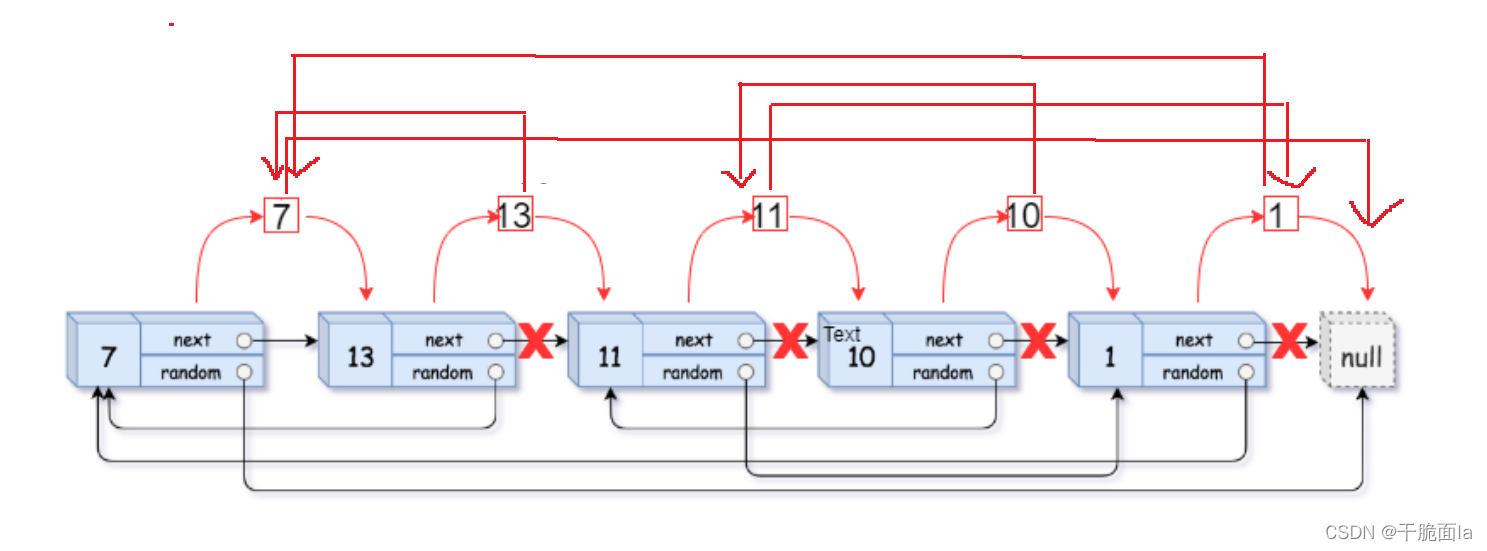
第2步 拷贝原链表的random节点
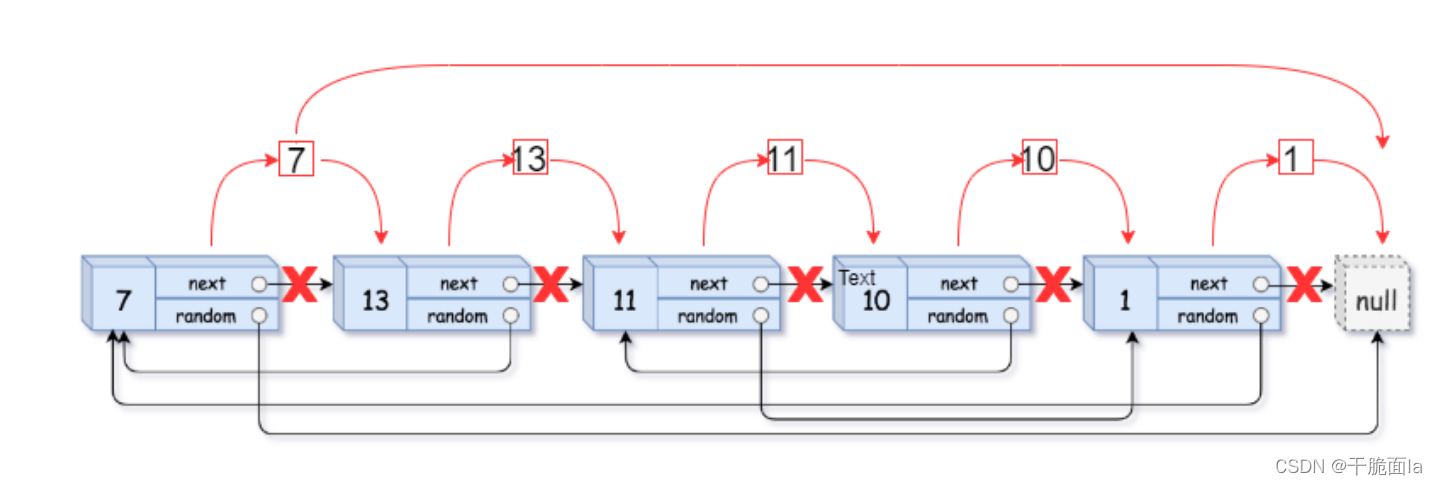
(1)若原链表的节点的random指向NULL,拷贝节点的random也指向NULL
(2)若原链表的节点random指向原链表的其中一个节点,那么random指向的这个节点的下一个节点就是拷贝链表要找的random,以原链表二个节点为例:
(3)实现后题解如下
根据图解我们可以写出代码:
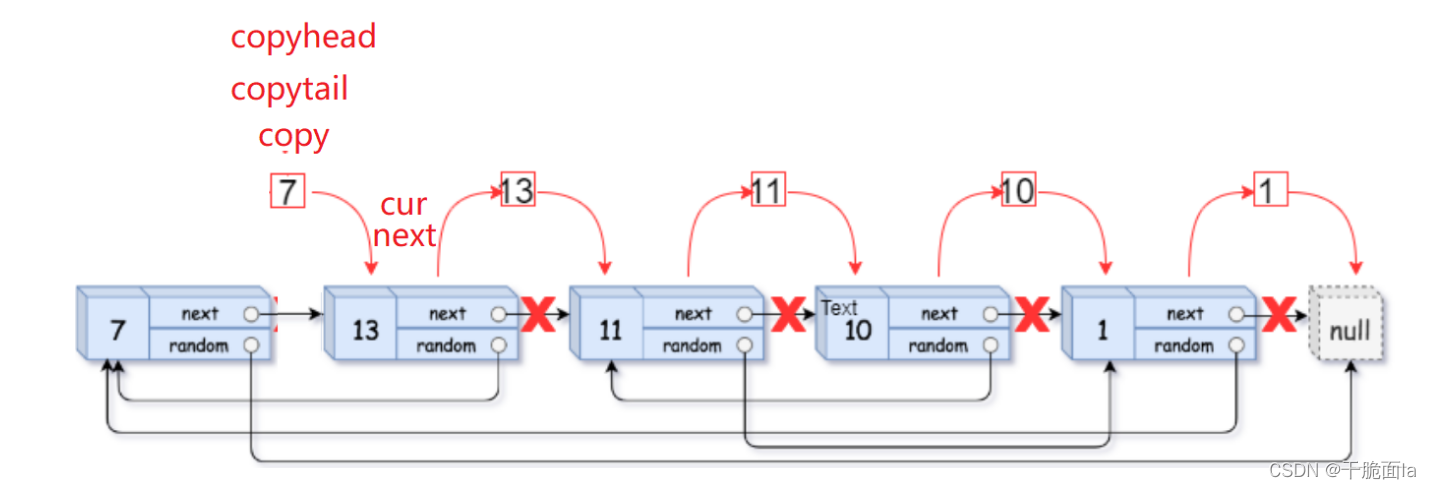
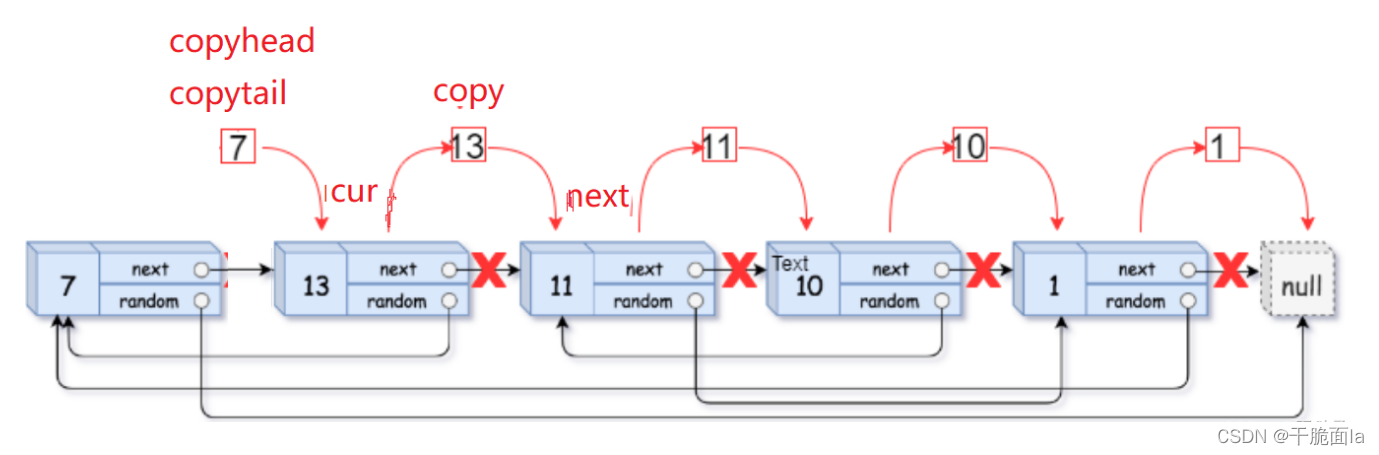
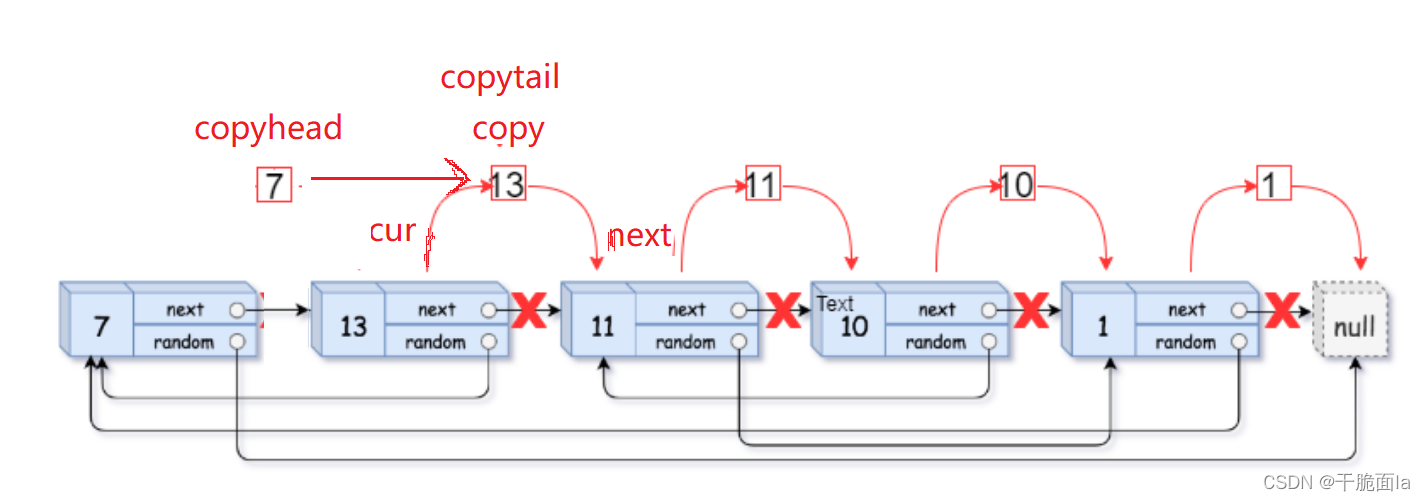
第3步 将拷贝节点与原链表分开
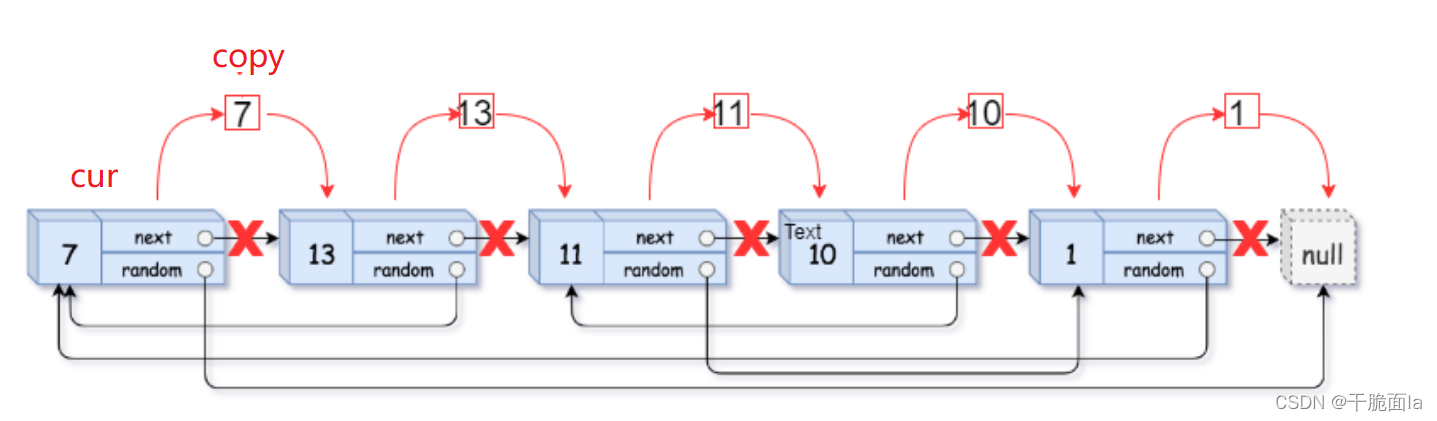
(1)用cur和copy指针来分别使原链表和拷贝链表的节点向后迭代,由于copy随着cur向后迭代,一直跟在cur的后面
因此循环外初始化cur = head,循环内初始化copy = cur->next;
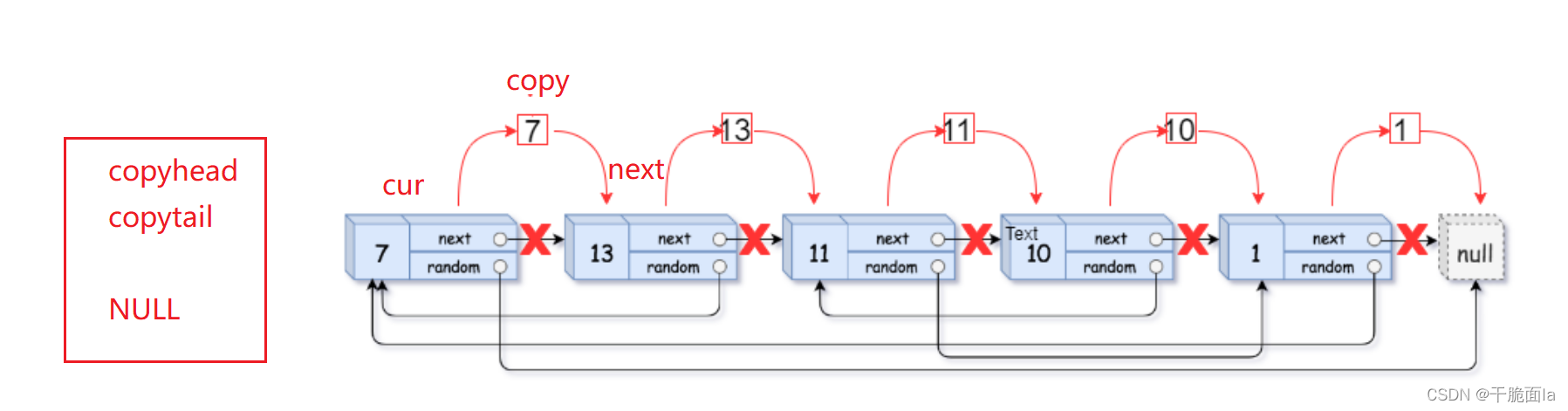
(2)为原链表定义一个next来连接链表;为拷贝链表定义一个copyhead和copytail来返回和连接链表,当原链表第一个节点不为空,才能保证copy的第一个节点不为空,因此copyhead和copytail先置空
循环外初始化copytail = copyhead = NULL,循环内初始化next = copy->next,
(3)当cur指向第一个节点时,进入循环,此时copyhead和copytail为空,使其指向拷贝链表的第一个节点,再使cur->next = next,将cur和next连接起来,并使cur=next往后走,
若cur不为空,再之后就是让copy=cur->next,next = copy->next
捋清楚结构就可以写出循环体框架:
(4)当cur指向第二个节点时,copyhead和copytail此时不为空,copy也指向拷贝的第二个节点,因此用copytail->next = copy连接两节点,再使copytail = copy使其向后迭代
捋清关系我们便可以补全循环体
完整代码:
- struct Node* copyRandomList(struct Node* head) {
- //1.链接链表
- struct Node* cur = head;
- while(cur)
- {
- //提前储存原链表下一个节点的地址
- struct Node* next = cur->next;
- //为原链表的拷贝开辟空间
- struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
- copy->val = cur->val;
- //链接原链表和拷贝节点
- cur->next = copy;
- copy->next = next;
- //迭代往下走
- cur = next;
- }
- //2.拷贝原链表的random节点
- cur = head;
- while(cur)
- {
- struct Node* copy = cur->next;
- if(cur->random == NULL)
- {
- copy->random = NULL;
- }
- else
- {
- copy->random = cur->random->next;
- }
- cur = copy->next;
- }
- //3.将拷贝节点与原链表分开
- cur = head;
- struct Node* copyhead = NULL;
- struct Node* copytail = NULL;
- while(cur)
- {
- struct Node* copy = cur->next;
- struct Node* next = copy->next;
- if(copyhead == NULL)
- {
- copyhead = copytail = copy;
- }
- else
- {
- copytail->next = copy;
- copytail = copy;
- }
- cur->next = next;
- cur = next;
- }
- return copyhead;
- }


题解二总结:由于第二种解题思路用巧妙的连接方式,使拷贝链表的random不需要通过对原链表的每一个节点遍历也能找到,大大降低了时间复杂度,这种解法的时间复杂度为O(n)。


