
- 1女生适不适合软件测试?从薪资、就业、学习、工作难度和加班多方面解读女生适不适合软件测试这一工作_女生做自动化测试怎么样
- 2笔记本电脑怎样连接打印机_国产打印机品牌有哪些?什么值得推荐
- 3iOS ------ 多线程基础
- 4如何保证MQ中消息的顺序性?_怎么保证mq顺序消费
- 5【论文笔记】| 定制化生成PuLID
- 6【程序源代码】奶茶点餐订餐餐饮小程序
- 7毕业设计基于SpringBoot+Vue智慧云办公系统源码+数据库+项目文档_springboot+vue oa流程源码
- 8YashanDB携手慧点科技完成产品兼容认证 助力国产信创生态建设
- 9git 和码云_git码云
- 10微信分享打不开分享界面_微信分享什么都可以了,就是调不起分享按钮
【AI】1968- 谷歌最新开源的 Gemma 模型,秒杀 Llma-2!
赞
踩
Gemma 是什么
Gemma 是一个轻量级、最先进的开放式模型系列,采用了与创建 Gemini 模型相同的研究和技术。Gemma 由 Google DeepMind 和 Google 的其他团队共同开发,其灵感来源于双子座,名字反映了拉丁语 gemma,意为 "宝石"。在发布模型权重的同时,谷歌还将发布相关工具,以支持开发人员创新、促进协作,并指导负责任地使用 Gemma 模型。
以下是需要了解的关键细节:
两种尺寸的模型权重:Gemma 2B 和 Gemma 7B。每种尺寸都发布了预训练和指令调整变体。
新的 “Responsible Generative AI Toolkit” 为使用 Gemma 创建更安全的人工智能应用提供了指导和基本工具。
为所有主要框架的推理和监督微调(SFT)提供了工具链:JAX、PyTorch 和 TensorFlow,以及本地 Keras 3.0。
现成可用的 Colab 和 Kaggle 笔记本,以及与 Hugging Face、MaxText、NVIDIA NeMo 和 TensorRT-LLM 等流行工具的集成,使 Gemma 的上手非常容易。
经过预训练和指令调整的 Gemma 模型可在你的笔记本电脑、工作站或谷歌云上运行,并可在 Vertex AI 和谷歌 Kubernetes Engine (GKE) 上轻松部署。
跨多个人工智能硬件平台的优化确保了行业领先的性能,包括英伟达™(NVIDIA®)GPU 和谷歌云 TPU。
使用条款允许负责任的商业使用和传播。
Gemma 模型与 Gemini 共享技术和基础设施组件,而 Gemini 是目前市场上最大、功能最强的人工智能模型。这使得 Gemma 2B 和 7B 与其他开放模型相比,在其规模上实现了同类最佳的性能。而且,Gemma 模型能够直接在开发人员的笔记本电脑或台式电脑上运行。值得注意的是,Gemma 在关键基准上超过了更大的模型,同时还符合严格的安全和负责任的输出标准。
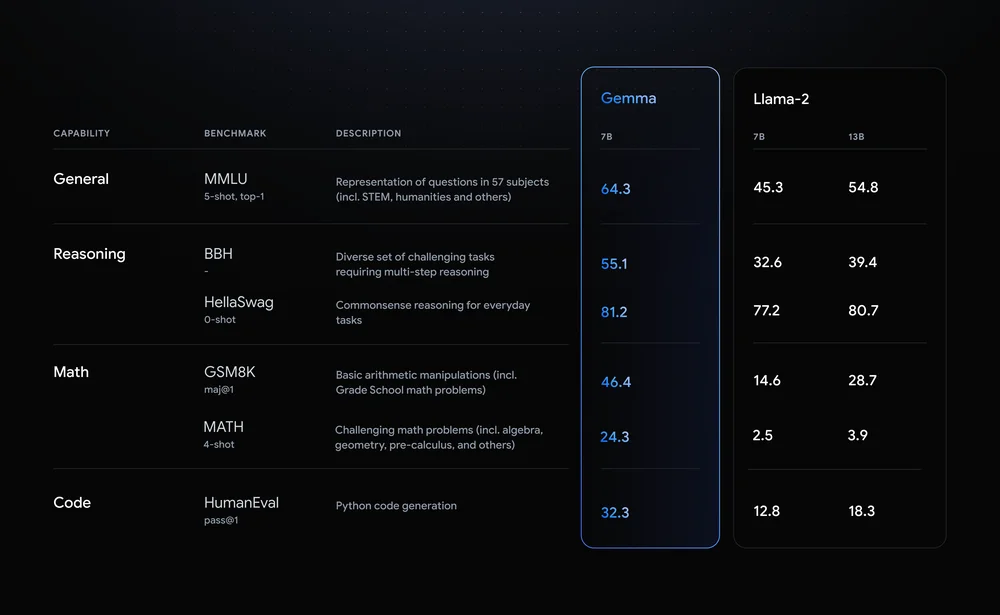
由上图的测评数据来看,Gemma 7B 模型的能力,已经秒杀同级的 Llma-2 7B,而且还完全超越 Llama-2 13B。接下来,本文将介绍如何快速体验最新的 Gemma 模型。
Ollama 运行 Gemma
首先,先确保你电脑已经安装 ollama[1],如果还没安装的话,可以参考 “部署本地的大语言模型,只需几分钟!” 这篇文章。
成功安装 ollama 之后,可以在命令行输入以下命令来运行 Gemma 2b 或 Gemma 7b 模型:
- ollama run gemma:2b
- # Or
- ollama run gemma:7b
运行该命令后,会自动下载 Gemma 2B 或 Gemma 7B 模型。如果你的电脑拥有足够的内存,可以使用以下命令安装非量化的版本,即使用精度更高的版本,以体验更好效果:
- ollama run gemma:2b-instruct-fp16
- # Or
- ollama run gemma:7b-instruct-fp16
除了 ollama 之外,你也可以通过 llama.cpp[2] 或 gemma.cpp[3] 来体验 gemma。
llama.cpp 运行 Gemma
来源:https://github.com/ggerganov/llama.cpp/pull/5631
gemma.cpp 运行 Gemma

来源:https://github.com/google/gemma.cpp
本文介绍了 3 种方式来体验谷歌最新的 Gemma 开源模型,感兴趣的小伙伴,可以体验一下该模型的效果。
参考资料
[1]
ollama: https://ollama.com/
[2]llama.cpp: https://github.com/ggerganov/llama.cpp
[3]gemma.cpp: https://github.com/google/gemma.cpp

