
- 1最好的商业模式_切高端客户背后的原理
- 2【算法浅析】2019年CCF算法习题部分整理_ccf cat算法比赛题目
- 3无法启动Mysql服务器?net start Mysql服务器原来只需要这一步_net start mysql无法启动
- 4NLP语种检测的基准对比测试_lid.176.bin
- 5粉丝福利 | CSDN机器学习之心博主粉丝福利
- 6线程池 - C++_c++线程池
- 7ClassFinal安全加密工具基本使用_classfinal怎么用
- 8基于Flink构建实时数仓实践
- 9Linux下配置和使用Java开发OpenCV_linux 中使用opencv java
- 10mysql查询中的分组,排序及多表连接_mysql分组多表链接
Data-to-Text文献学习·《Learning to Select, Track, and Generate for Data-to-Text》_data to text
赞
踩
一、总述
数据到文本生成是NLG的一项任务,用于从结构化或非结构化数据生成描述,包括体育评论、天气预报、来自维基百科信息框的传记文本以及来自股票价格的市场评论。运用神经网络来处理这一任务已经成为主流,且结合attention和copy机制的encoder-decoder架构已被成功使用,并获得较好的结果。然而,尽管生成的文本流畅度增高了,但是生成文本与输入的关联性并不太高,即存在描述不一致的问题。
有两个作用:一是用来去记住那些已经被参考了的数据记录,二是去更新 ,这意味着被参考的数据记录将对文本生成阶段产生影响。
本文模型可以决定是否参考数据记录集,选择哪些记录
被提及,并且如何去表达数字。被选择的数据记录将用于
的更新。
为方便论文展示,此处先作变量声明:

(1)是一个二元变量,用于决定模型是否在t时刻参考了x;
(2)表示了在t时刻的显著实体;
(3)表示t时刻的显著属性(NCP里的type);
(4)用于判定数值型数据用何种方式表达(阿拉伯数字还是英文)
为了保持对显著实体的追踪,在摘要生成阶段,本文模型在每一个时刻都要预测上述随机变量。由于空间局限性,模型省略了偏置变量。
符号声明:
:实体集
:类型集
3.1初始化
3.2显著对象的转换
这里的显著对象包含着实体和其类型,本文用如下概率去决定在t时刻是否进行转换
![]()
若该概率值很高,那么就转换对象。在进行转换时,模型需要去决策转换到哪个实体和类型上,并生成下一个词汇,并同时更新,继而更新
。若不进行转换,那么t时刻和t-1时刻的
相同
3.3对象选择和追踪
当模型决定参考一个新的数据记录时(此时),将会选一个实体和一个类型。与此同时,它还通过将有关选定实体和属性的信息放入记忆向量
来跟踪显著性实体,模型开始选择主题实体,并在主题实体发生变化时更新记忆状态。模型通过以下公式来进行实体选择:

其中,表示在t时刻时,以及被提及的实体所组成的集合,其中s指上一次提起该实体的时刻。当实体被变换时,模型将用以下式子进行计算:
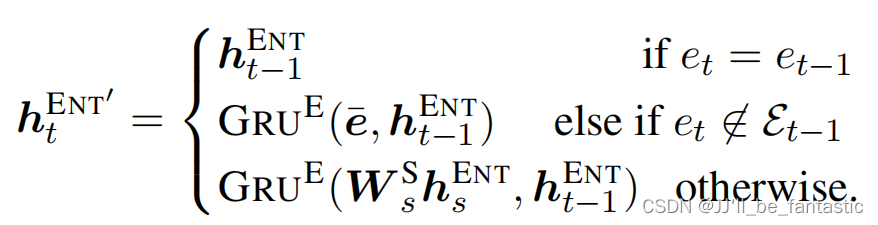
并用如下公式进行类型的选择:
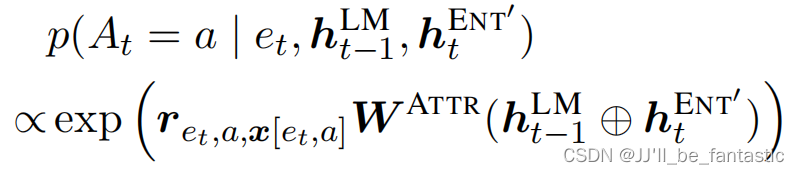
此时将会进一步更新,用如下式子计算:
![]()
也就是说,进行一次transition,由于要转换实体和类型,故需要分两步更新。
3.4摘要生成
有了两个hidden state,用作语言模型,
用作追踪模型,基于此,模型生成t时刻的单词
。同时,本文模型也引入了copy机制,可从
中复制词汇。对于数值型数据,由于有两种表达方式,即阿拉伯数字型和英文单词型,需用以下公式来决定用哪一种形式:
![]()
当模型决定用新的数据记录时(),将通过以下公式更新语言模型的hidden state:
![]()
此时,输出的单词由以下公式计算:
![]()
此时将会由以下公式更新:
![]()
其中是
向量。
3.5学习目标
最大化以下式子:


