
- 1在 Windows 下搭建自己的深度学习开发环境_windows搭建深度学习环境
- 2Docker (五)实战案例_docker项目实战案例
- 3算法设计与分析--求解最大连续子序列和问题(分治法、蛮力法、动态规划法)
- 4想成为一名优秀的数据分析师,应该做些什么?_成为一名数据分析师应该做什么
- 5解决Android Gradle plugin requires Java 17 to run. You are currently using Java的具体操作步骤
- 6几个实用的PCB设计通用规则(嵌入式硬件篇)_pcb包地
- 7用Photoshop处理抠图留下的白边
- 8JavaSE学习笔记
- 9Git学习——修复bug_git 版本bug修复
- 10android studio 连接mumu模拟器调试_mumu模拟器 android studio
大模型の升级与设计_大模型的gmask
赞
踩
梳理ChatGLM、LLAMA和Baichuan等模型的升级过程,分析其背后的原因,并展示大型模型如何优化实现升级。
-
0911 更新百川2升级之路,核心点:数据量升级至2.6T,训练过程引入NormHead、Max-z增加训练及推理的稳定性
目前大语言模型在各个领域取得了显著的突破,从ChatGLM、LLAMA到Baichuan等,它们在处理各种自然语言任务时展现出了惊人的性能。然而,随着研究的深入和应用需求的不断扩大,这些大型模型需要不断地进行升级和优化,以满足更高的性能要求和更广泛的应用场景。
在这个过程中,作为研究者和从业者,我们需要深入探讨:大型模型的升级之路是怎样的?升级过程中面临哪些挑战?又是通过怎样的手段和方法实现升级的?本篇博客旨在对此进行深入探讨,梳理ChatGLM、LLAMA和Baichuan等模型的升级过程,分析其背后的原因,并展示大型模型如何优化实现升级。
| 模型升级之路 | 训练Token数 | 序列长度 | 算子改进 | 核心点 |
|---|---|---|---|---|
| ChatGLM->ChatGLM2 | 1T->1.4T | 2K->8K/32K | FlashAttention & Multi Query Attention | Prefix-LM->Decoder-Only |
| LLAMA->LLAMA2 | 1.4T->2T | 2K->4K | - | 更高质量的SFT&RLHF |
| baichuan->baichuan 13b | 1.2T->1.4T | 4K(RoPE)->4K(ALiBi) | FlashAttention | 参数量升级 |
| baichuan->baichuan2 | 1.2T->2.6T | 4K | - | Tokenizer/NormHead/Max-z Loss |
ChatGLM升级之路
首先对比下ChatGLM升级前后各大榜单结果,ChatGLM-6B较ChatGLM2-6B模型在各个榜单中都取得了近20-30%的提升:
MMLU
| Model | Average | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|
| ChatGLM-6B | 40.63 | 33.89 | 44.84 | 39.02 | 45.71 |
| ChatGLM2-6B (base) | 47.86 | 41.20 | 54.44 | 43.66 | 54.46 |
| ChatGLM2-6B | 45.46 | 40.06 | 51.61 | 41.23 | 51.24 |
| ChatGLM2-12B (base) | 56.18 | 48.18 | 65.13 | 52.58 | 60.93 |
| ChatGLM2-12B | 52.13 | 47.00 | 61.00 | 46.10 | 56.05 |
Chat 模型使用 zero-shot CoT (Chain-of-Thought) 的方法测试,Base 模型使用 few-shot answer-only 的方法测试
C-Eval
| Model | Average | STEM | Social Sciences | Humanities | Others |
|---|---|---|---|---|---|
| ChatGLM-6B | 38.9 | 33.3 | 48.3 | 41.3 | 38.0 |
| ChatGLM2-6B (base) | 51.7 | 48.6 | 60.5 | 51.3 | 49.8 |
| ChatGLM2-6B | 50.1 | 46.4 | 60.4 | 50.6 | 46.9 |
| ChatGLM2-12B (base) | 61.6 | 55.4 | 73.7 | 64.2 | 59.4 |
| ChatGLM2-12B | 57.0 | 52.1 | 69.3 | 58.5 | 53.2 |
Chat 模型使用 zero-shot CoT 的方法测试,Base 模型使用 few-shot answer only 的方法测试
GSM8K
| Model | Accuracy | Accuracy (Chinese)* |
|---|---|---|
| ChatGLM-6B | 4.82 | 5.85 |
| ChatGLM2-6B (base) | 32.37 | 28.95 |
| ChatGLM2-6B | 28.05 | 20.45 |
| ChatGLM2-12B (base) | 40.94 | 42.71 |
| ChatGLM2-12B | 38.13 | 23.43 |
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 http://arxiv.org/abs/2201.11903
使用翻译 API 翻译了 GSM8K 中的 500 道题目和 CoT prompt 并进行了人工校对
BBH
| Model | Accuracy |
|---|---|
| ChatGLM-6B | 18.73 |
| ChatGLM2-6B (base) | 33.68 |
| ChatGLM2-6B | 30.00 |
| ChatGLM2-12B (base) | 36.02 |
| ChatGLM2-12B | 39.98 |
所有模型均使用 few-shot CoT 的方法测试,CoT prompt 来自 https://github.com/suzgunmirac/BIG-Bench-Hard/tree/main/cot-prompts
ChatGLM
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。 jkMmBZ
jkMmBZ
glm
ChatGLM2
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
-
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
-
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。对于更长的上下文,我们发布了 ChatGLM2-6B-32K 模型。LongBench 的测评结果表明,在等量级的开源模型中,ChatGLM2-6B-32K 有着较为明显的竞争优势。
-
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
-
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
升级过程
模型结构
模型结构改变:从Prefix-LM回归纯粹的Decoder-Only结构,即SFT过程所有的都通过gMASK在开头进行生成;
代码对比如下: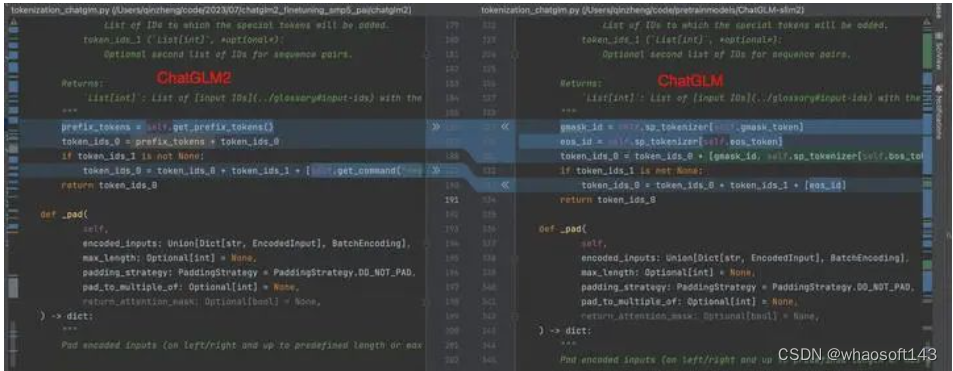 图示如下:
图示如下:
ChatGLM: ChatGLM2:
ChatGLM2: 那么这种改变能够带来什么呢?
那么这种改变能够带来什么呢?
答案就是为模型的训练效率带来了极大的提升。
图片来源:https://github.com/THUDM/ChatGLM2-6B/issues/16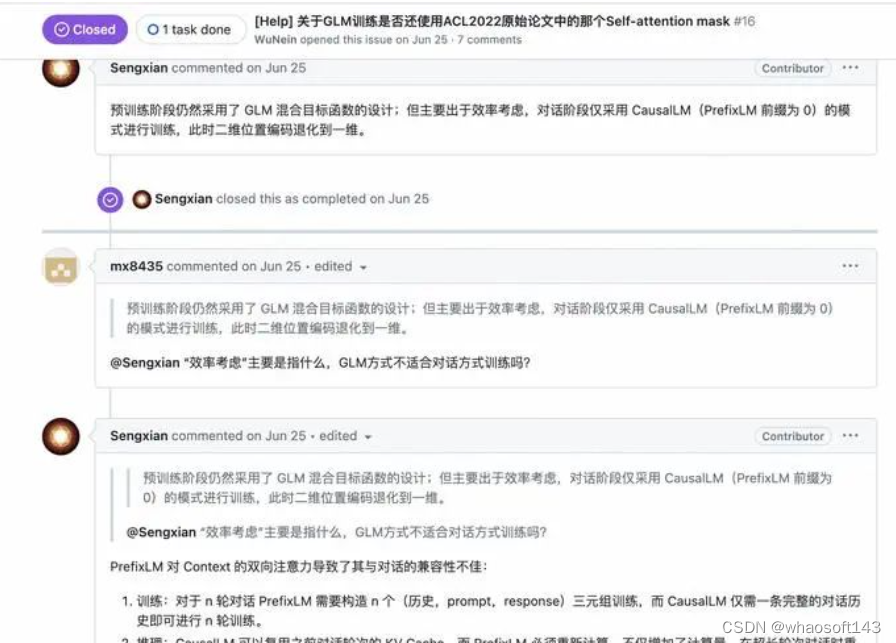 在处理多轮对话的过程中,设有3轮对话,Q1A1,Q2A2,Q3A3,PrefixLM需要构建三条样本:
在处理多轮对话的过程中,设有3轮对话,Q1A1,Q2A2,Q3A3,PrefixLM需要构建三条样本:
-
Q1->A1
-
Q1A1Q2->A2
-
Q1A1Q2A2Q3->A3
而这种数据构建方式带来了严重的数据膨胀问题,影响模型训练的效率。
相反,Decoder-Only模型则可以利用Causal Mask的特性(每一个Token可以看到前面所有Token的真实输入),在一条样本中实现多轮对话:
-
样本构建:Q1 A1 Q2 A2 Q3 A3
-
Loss计算:只需要计算 A1 A2 和 A3 部分
再仔细回顾下,对话session级别训练和拆开训练从原理上有啥区别?
-
session级别训练,效果之一为等价batchsize变大(1个batch可以塞下更多样本),且同一通对话产生的样本在一个bs内。
-
session级别的不同轮次产生的梯度是求平均的,拆开轮次构造训练是求和的,这样除了等价于lr会变大,还会影响不同轮次token权重的分配,另外还会影响norm的计算。
我们用一个简化地例子定量分析下,我们假设两条训练样本分为
1.问:A 答:xx
2.问: A 答:xx 问: B 答:xx 问: C 答:xx
则session级别训练影响梯度为 (Ga+(Ga + Gb + Gc)/3 )/2。对 A,B,C影响的权重分别为,2/3 1/6 1/6。
拆开训练为 (Ga+Ga+ (Ga + Gb)/2 +(Ga + Gb + Gc)/3)/4。对 A,B,C影响的权重分别为,17/24 5/24 1/12。
从上面的权重分布来看,session级别靠后的轮次影响权重要比拆开更大。这也是更合理的,因为大部分场景下,开场白都是趋同和重复的。
序列长度
序列长度:预训练模型在32K长度训练,SFT微调模型在8K长度训练;
 此外,7月31号智谱AI发布了基于ChatGLM2-6B的基础上微调的针对长上下文优化的大模型ChatGLM2-6B-32K,能够更好的处理最多32K长度的上下文。
此外,7月31号智谱AI发布了基于ChatGLM2-6B的基础上微调的针对长上下文优化的大模型ChatGLM2-6B-32K,能够更好的处理最多32K长度的上下文。
此前,ChatGLM2-6B刚发布的时候,官方宣称该模型最高支持32K长上下文输入,但是LM-SYS官方测试显示ChatGLM2-6B在超过8K长度时候表现很糟糕:支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3 。 具体来说,ChatGLM2-6B-32K基于位置插值(Positional Interpolation)的方法对位置编码进行了更新,并在对话阶段使用 32K 的上下文长度训练。在实际的使用中,官方推荐如果上下文长度基本在 8K 以内,建议使用ChatGLM2-6B;如果需要处理超过 8K的上下文长度,推荐使用ChatGLM2-6B-32K。
具体来说,ChatGLM2-6B-32K基于位置插值(Positional Interpolation)的方法对位置编码进行了更新,并在对话阶段使用 32K 的上下文长度训练。在实际的使用中,官方推荐如果上下文长度基本在 8K 以内,建议使用ChatGLM2-6B;如果需要处理超过 8K的上下文长度,推荐使用ChatGLM2-6B-32K。
关于位置插值的介绍,可见博客:RoPE旋转位置编码深度解析:理论推导、代码实现、长度外推
算子优化
算子优化:Flash Attention、Multi-Query Attention提高训练&推理的速度;

本次ChatGLM2-6B上下文从2k扩展到了32k同时也应用了一种叫做 FlashAttention 的技术。flash-attention是一种快速、高效、可扩展的注意力机制,它利用了一种称为哈希感知(hash-aware)的技术,可以根据它们的相似性将输入序列中的元素分配到不同的桶(bucket)中。这样,模型只需要计算桶内元素之间的注意力权重,而不是整个序列。这大大减少了计算量和内存需求,同时保持了较高的精度和表达能力。
LLAMA升级之路
首先对比下LLAMA升级前后各大榜单结果,LLAMA2较LLAMA模型在各个榜单中取得了近10-30%的提升:
MMLU
| Model | Average |
|---|---|
| LLAMA-7B | 35.1 |
| LLAMA2-7B | 45.3 |
| LLAMA-13B | 46.9 |
| LLAMA2-13B | 54.8 |
| LLAMA-65B | 63.4 |
| LLAMA2-70B | 68.9 |
GSM8K
| Model | Accuracy |
|---|---|
| LLAMA-7B | 11.0 |
| LLAMA2-7B | 14.6 |
| LLAMA-13B | 17.8 |
| LLAMA2-13B | 28.7 |
| LLAMA-65B | 50.9 |
| LLAMA2-70B | 56.8 |
LLAMA
LLaMA(Large Language Model Meta AI),由 Meta AI 发布的一个开放且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现,整个训练数据集在 token 化之后大约包含 1.4T 的 token。
关于模型性能,LLaMA 的性能非常优异:具有 130 亿参数的 LLaMA 模型「在大多数基准上」可以胜过 GPT-3( 参数量达 1750 亿),而且可以在单块 V100 GPU 上运行;而最大的 650 亿参数的 LLaMA 模型可以媲美谷歌的 Chinchilla-70B 和 PaLM-540B。
关于训练集,其来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现。整个训练数据集在 token 化之后大约包含 1.4T 的 token。其中,LLaMA-65B 和 LLaMA-33B 是在 1.4万亿个 token 上训练的,而最小的模型 LLaMA-7B 是在 1万亿个 token 上训练的。
模型结构:
-
PreLayerNorm-RMSNorm-Root Mean Square Layer Normalization
-
ROPE旋转位置编码(替换绝对/相对位置编码)
-
SwiGLU激活函数(替换ReLU)-GLU Variants Improve Transformer
LLAMA2
官方页面上的介绍如下: 在模型结构上,主要升级两点:
在模型结构上,主要升级两点:
-
训练数据Token数量从1.4T->2T
-
序列长度从2K->4K
在SFT过程中,LLAMA2强调数据质量的重要性,通过2W的高质量指令数据,激发模型的指令遵循能力。
在RLHF过程中,LLAMA2做了较多工作,对RLHF过程作出了进一步的解释。自建了100W的Reward数据集,训练了两个独立的Reword Model。
整个LLAMA2的论文解读如下: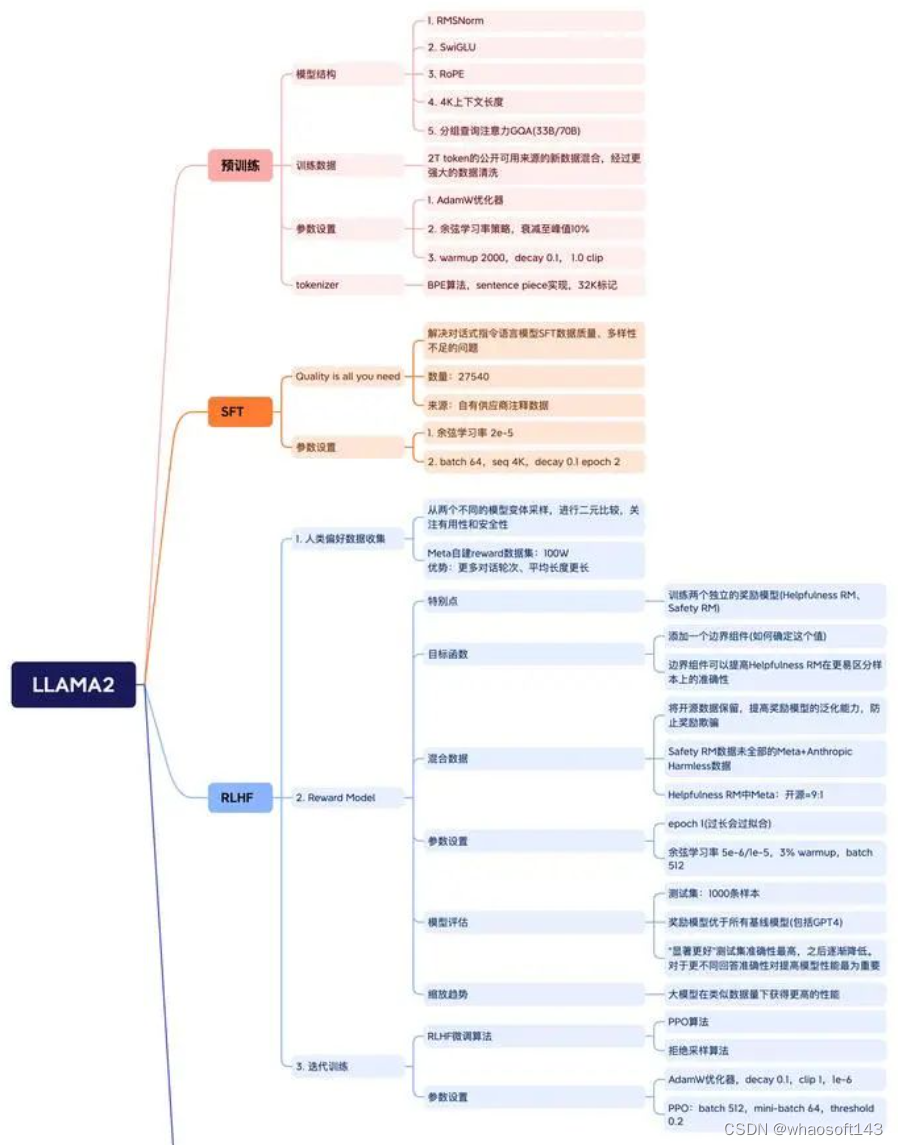
 LLAMA2-Chat模型的训练过程如下图,主要包含预训练、SFT、RLHF三个步骤:
LLAMA2-Chat模型的训练过程如下图,主要包含预训练、SFT、RLHF三个步骤: 预训练
预训练
LLAMA2的主要提升点包括:更强大的数据清洗,更新数据组合,增加40%的总训练tokens,加倍上下文长度,以及使用分组查询注意力(GQA)来提高更大模型的推理可扩展性。 模型结构:
模型结构:
-
RMSNorm
-
SwiGLU
-
RoPE
-
4K序列长度
-
分组查询注意力GQA(33B/70B)
SFT
作者发现许多第三方SFT数据集在多样性和质量方面不足,因此他们专注于收集自己的高质量SFT数据。
他们观察到,与使用来自第三方数据集的数百万例子相比,从他们自己的供应商为基础的标注工作中使用较少但质量更高的例子可以显著提高结果。他们发现,数以万计的SFT注释足以实现高质量结果,共收集了27,540个注释。
RLHF
我们主要挑三个核心步骤介绍:数据收集、奖励模型、迭代训练。
人类偏好数据收集 偏好数据如表6所示,其中包含了140WMeta自建的数据集,相比于开源数据集,自建数据集的轮次、对话长度更长。
偏好数据如表6所示,其中包含了140WMeta自建的数据集,相比于开源数据集,自建数据集的轮次、对话长度更长。
奖励模型
LLAMA2训练了两个独立的奖励模型(Helpfulness RM/Safety RM)。
动机:有研究发现(Bai等人,2022a),有时候有用性和安全性之间会存在权衡,这使得单一的奖励模型在这两方面的表现上可能会面临挑战。
为了解决这个问题,作者训练了两个独立的奖励模型,一个针对有用性进行优化(称为有用性奖励模型,Helpfulness RM),另一个针对安全性进行优化(称为安全性奖励模型,Safety RM)。这样可以分别在有用性和安全性方面取得更好的效果,使得Llama 2-Chat在强化学习人类偏好(RLHF)过程中更好地符合人类偏好,提高生成回答的有用性和安全性。
损失函数:
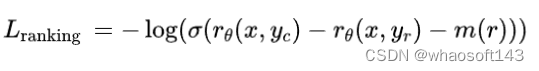
边界m(r)是关于偏好评分的离散函数。作者对那些响应差距较大的的对使用较大的边界,而对那些响应相似的对使用较小的边界(如表27所示)。作者发现这种边界分量可以提高有用性奖励模型的准确性,特别是在两个反应差距更大的样本中。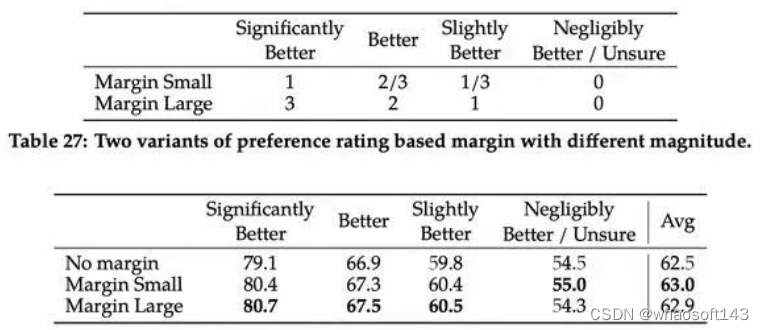 迭代训练
迭代训练
LLAMA2采用了两种强化学习算法:PPO和拒绝采样算法。
这两种强化学习算法主要区别在于:
• 广度:在拒绝采样中,模型为给定的提示探索K个样本,而在PPO中,只有一个生成过程。
• 深度:在PPO中,训练过程中第t步的样本是经过t-1步梯度更新后的模型策略的函数。在拒绝采样微调中,在模型的初始策略下采样所有输出以收集新数据集,然后类似于SFT进行微调。然而,由于采用了迭代模型更新,这两种算法之间的本质区别并不明显。
LLAMA2直到RLHF (V4),仅使用拒绝采样微调。之后将这两种方法结合起来,先对拒绝采样检查点应用PPO,然后再对采样进行拒绝采样。LLAMA2只使用最大的70B Llama 2-Chat模型进行拒绝采样。其他较小的模型则在更大模型的拒绝采样数据上进行微调,从而将大模型的能力转移到较小的模型中。
百川升级之路
首先对比下升级前后各大榜单结果,Baichuan-13B较Baichuan-7B模型在各个榜单中都取得了近20%的提升:
C-Eval
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|---|---|---|---|---|---|
| Baichuan-7B | 38.2 | 52.0 | 46.2 | 39.3 | 42.8 |
| Baichuan-13B-Base | 45.9 | 63.5 | 57.2 | 49.3 | 52.4 |
| Baichuan-13B-Chat | 43.7 | 64.6 | 56.2 | 49.2 | 51.5 |
| Baichuan2-7B-Base | - | - | - | - | 54.0 |
| Baichuan2-13B-Base | - | - | - | - | 58.1 |
MMLU
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|---|---|---|---|---|---|
| Baichuan-7B | 35.6 | 48.9 | 38.4 | 48.1 | 42.3 |
| Baichuan-13B-Base | 41.6 | 60.9 | 47.4 | 58.5 | 51.6 |
| Baichuan-13B-Chat | 40.9 | 60.9 | 48.8 | 59.0 | 52.1 |
| Baichuan2-7B-Base | - | - | - | - | 54.16 |
| Baichuan2-13B-Base | - | - | - | - | 59.17 |
说明:采用了 MMLU 官方的评测方案。
CMMLU
| Model 5-shot | STEM | Humanities | Social Sciences | Others | China Specific | Average |
|---|---|---|---|---|---|---|
| Baichuan-7B | 34.4 | 47.5 | 47.6 | 46.6 | 44.3 | 44.0 |
| Baichuan-13B-Base | 41.7 | 61.1 | 59.8 | 59.0 | 56.4 | 55.3 |
| Baichuan-13B-Chat | 42.8 | 62.6 | 59.7 | 59.0 | 56.1 | 55.8 |
| Baichuan2-7B-Base | - | - | - | - | - | 57.07 |
| Baichuan2-13B-Base | - | - | - | - | - | 61.97 |
说明:CMMLU 是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。采用了其官方的评测方案。
baichuan-7b
Baichuan-7B 是由百川智能开发的一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约 1.2 万亿 tokens 上训练的 70 亿参数模型,支持中英双语,上下文窗口长度为 4096。在标准的中文和英文 benchmark(C-Eval/MMLU)上均取得同尺寸最好的效果。
百川模型结构与LLAMA相近,作了如下的优化:
分词器
参考学术界方案使用 SentencePiece 中的 Byte-Pair Encoding (BPE) 作为分词算法,并且进行了以下的优化:
-
目前大部分开源模型主要基于英文优化,因此对中文语料存在效率较低的问题。我们使用 2000 万条以中英为主的多语言语料训练分词模型,显著提升对于中文的压缩率。
-
对于数学领域,我们参考了 LLaMA 和 Galactica 中的方案,对数字的每一位单独分开,避免出现数字不一致的问题,对于提升数学能力有重要帮助。
-
对于罕见字词(如特殊符号等),支持 UTF-8 characters 的 byte 编码,因此做到未知字词的全覆盖。
-
我们分析了不同分词器对语料的压缩率,如下表,可见我们的分词器明显优于 LLaMA, Falcon 等开源模型,并且对比其他中文分词器在压缩率相当的情况下,训练和推理效率更高。
| Model | Baichuan-7B | LLaMA | Falcon | mpt-7B | ChatGLM | moss-moon-003 |
|---|---|---|---|---|---|---|
| Compress Rate | 0.737 | 1.312 | 1.049 | 1.206 | 0.631 | 0.659 |
| Vocab Size | 64,000 | 32,000 | 65,024 | 50,254 | 130,344 | 106,029 |
算子优化
采用更高效的算子:Flash-Attention,同ChatGLM2
baichuan-13b
Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。Baichuan-13B 有如下几个特点:
-
更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
-
同时开源预训练和对齐模型:预训练模型是适用开发者的『 基座 』,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
-
更高效的推理:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
-
开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
模型细节
| 模型名称 | 隐藏层维度 | 层数 | 注意力头数 | 词表大小 | 总参数量 | 训练数据(tokens) | 位置编码 | 最大长度 |
|---|---|---|---|---|---|---|---|---|
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2 万亿 | RoPE | 4,096 |
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4 万亿 | ALiBi | 4,096 |
升级过程
-
参数量:baichuan13B较baichuan7B 首先在参数量上翻了一倍,更大的参数量意味着知识的容量更大,通过更多的训练数据(1.2T->1.4T),基座模型的常识能力得以提升;
-
位置编码:从RoPE改成ALiBi,在一定程度的可以进行长度外推(TIPS:RoPE可以进行更长范围的外推);
baichuan2
技术报告:https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
-
Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。
-
Baichuan 2 在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。
分词器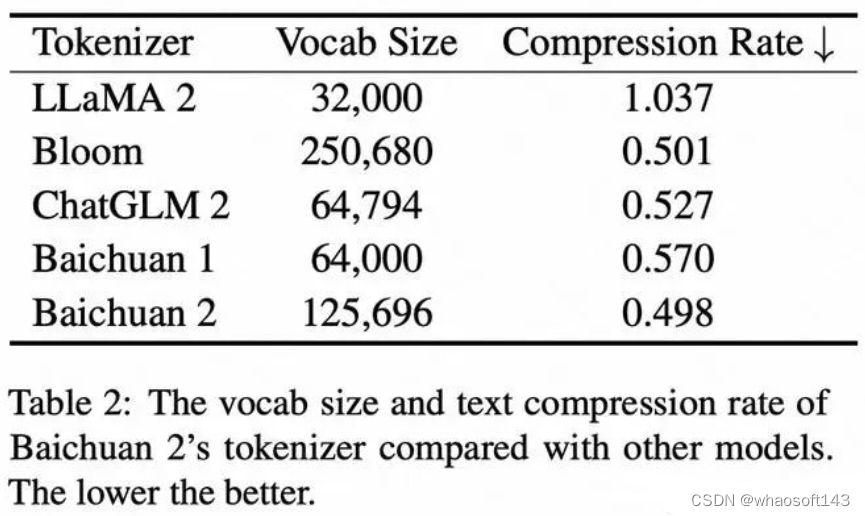
分词器需要平衡的两个关键因素是高压缩率以实现高效的推理(inference)和足够大小的词汇表以保证每个单词嵌入的充分训练。
相对于前代模型,Baichuan 2在分词器方面进行了如下改进:
-
词汇表扩展:Baichuan 2将词汇表的大小从Baichuan 1的64,000扩展到了125,696。这一变化旨在在保证计算效率的同时,充分训练每个词嵌入。
-
数据归一化处理:相比Baichuan 1,Baichuan 2在输入文本的归一化处理上有所不同。Baichuan 2不对输入文本进行任何归一化,并且不添加像Baichuan 1那样的虚拟前缀。
-
处理数字数据:Baichuan 2将数字数据拆分成独立的数字,以更好地编码数值数据。
-
处理代码数据:对于包含额外空格的代码数据,Baichuan 2向分词器中添加了仅包含空格的标记。
模型结构
Positional Embeddings:
-
对于Baichuan 2-7B模型,采用了Rotary Positional Embedding (RoPE)。
-
对于Baichuan 2-13B模型,采用了ALiBi作为位置编码技术。
激活函数和归一化:
-
使用了SwiGLU激活函数,这是GLU的一个变体,经过改进的版本。
-
在注意力层中采用了内存高效的注意力机制。
Tokenizer:
-
对词汇表的大小进行了调整,将其从Baichuan 1的64,000扩展到125,696,以在计算效率和模型性能之间取得平衡。
NormHead:
-
Baichuan 2使用了一种称为NormHead的方法来稳定训练并提高模型性能。NormHead主要用于对输出嵌入进行归一化处理,有助于稳定训练动态,并降低了L2距离在计算logits时的影响。
最大z损失(Max-z loss):
-
引入了最大z损失,用于规范模型输出的logit值,从而提高训练的稳定性并使推断更加鲁棒。
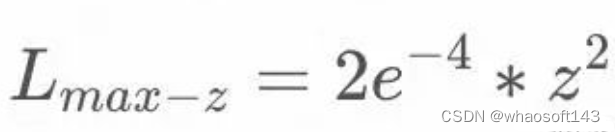
接下来让我们从代码层面,看baichuan2的模型结构改动:
NormHead:完成模型输出的归一化工作
- class NormHead(nn.Module):
- def __init__(self, hidden_size, vocab_size, bias=False):
- super().__init__()
- self.weight = nn.Parameter(torch.empty((vocab_size, hidden_size)))
- nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
- self.first_flag = True
-
- def forward(self, hidden_states):
- if self.training:
- norm_weight = nn.functional.normalize(self.weight)
- elif self.first_flag:
- self.first_flag = False
- self.weight = nn.Parameter(nn.functional.normalize(self.weight))
- norm_weight = self.weight
- else:
- norm_weight = self.weight
- return nn.functional.linear(hidden_states, norm_weight)
-
-
- class BaichuanForCausalLM(BaichuanPreTrainedModel):
- def __init__(self, config, *model_args, **model_kwargs):
- super().__init__(config, *model_args, **model_kwargs)
- self.model = BaichuanModel(config)
- self.lm_head = NormHead(config.hidden_size, config.vocab_size, bias=False)
- ...
-
- def forward(
- self,
- input_ids: torch.LongTensor = None,
- attention_mask: Optional[torch.Tensor] = None,
- past_key_values: Optional[List[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = False,
- output_hidden_states: Optional[bool] = False,
- return_dict: Optional[bool] = True,
- **kwargs,
- ) -> Union[Tuple, CausalLMOutputWithPast]:
- return_dict = (
- return_dict if return_dict is not None else self.config.use_return_dict
- )
-
- # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
- outputs = self.model(
- input_ids=input_ids,
- attention_mask=attention_mask,
- past_key_values=past_key_values,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- )
-
- hidden_states = outputs[0]
- logits = self.lm_head(hidden_states)

Max-z Loss: softmax_normalizer对应z^2
- loss = None
- if labels is not None:
- # Shift so that tokens < n predict n
- shift_logits = logits[..., :-1, :].contiguous()
- shift_labels = labels[..., 1:].contiguous()
- # Flatten the tokens
- loss_fct = CrossEntropyLoss()
- shift_logits = shift_logits.view(-1, self.config.vocab_size)
- shift_labels = shift_labels.view(-1)
- softmax_normalizer = shift_logits.max(-1).values ** 2
- z_loss = self.config.z_loss_weight * softmax_normalizer.mean()
- # Enable model parallelism
- shift_labels = shift_labels.to(shift_logits.device)
- loss = loss_fct(shift_logits, shift_labels) + z_loss
如何构建一个好的基座大模型?
在深入探讨了ChatGLM、LLAMA、Baichuan大语言模型的升级之路后,我们将进一步拓展讨论范围,探索大模型所需具备的关键能力、实现这些能力所需的技术手段以及模型结构的设计方法。这将为我们在实际应用中构建和优化大模型提供有力的参考和指导。
接下来的小节内容将从以下几个方面展开讨论:首先,我们将分析大型预训练模型所需要具备的核心能力,如长度外推、常识等;其次,我们将介绍如何利用先进的技术和方法实现这些能力,包括预训练策略、优化算法和损失函数等;最后,我们将针对模型结构进行探讨,分析如何选择合适的LLM(Large Language Model)结构以实现高性能的大型模型。
本小节内容旨在为大家提供一个全面的视角,了解大模型的关键要素,以便在实际工程中构建出更为强大、灵活且高效的大型预训练模型。
大模型所需能力及升级方式
通过对ChatGLM、LLAMA、Baichuan等大型语言模型升级过程的分析,可以发现它们的改进主要集中在基础知识能力的提升和支持的序列长度变化这两个方面。在本小节中,我们将重点梳理并总结这两项关键能力的升级策略。
基础知识
基础知识能力的提升涵盖了多个领域,我们可以通过以下常用评测集来了解这些领域:
-
英文知识 — MMLU
-
中文知识 — C-Eval
-
推理 — GSM8k / BBH
-
代码 — HumanEval / MBPP
-
数学 — MATH
笔者认为升级基础知识能力的主要策略在于提升模型参数量及训练数据,通过更大的参数量及数据使模型更好的拟合相关领域的知识。
而在这个过程中,最重要的是训练数据的质量,以下给出清洗数据的常用方式:
-
无效数据,脏数据过滤
一些无效数据,如意义空泛或模板化的文本(例如HTML代码、Lorem ipsum等)。甚至于在多语言语料库的构建过程中,从网站提取文本用于语言建模也极具挑战性。但这是我们必然要做到的,因为NTP(Next Token Prediction)的方式注定训练模型使用的数据本身就是真实语言世界很好的映射。数据清洗工具,如justext、trafilatura等,能有效剔除HTML模板文本,同时在减少噪音(提高精度)与保留所有有效部分(提高召回率)之间取得平衡。另外一点是,处理网页语料库中无效数据的有效方法之一是利用元数据进行筛选。例如,OpenAI在构建GPT-2用的WebText语料库时,抓取了reddit上点赞数至少为3的所有外部链接,这种启发式方法有助于减少数据集中的噪音,同时确保数据质量。
-
文档长度过滤
一方面,考虑到NTP(Next Token Prediction),从语料库中移除非常短的文档(包含少于约100个标记的文本)可以帮助通过创建连续的文本来建模文本中的依赖关系,从而去除噪音。另一方面,由于大多数语言模型如今都基于Transformer架构,对非常大的文档进行预处理并将其分成所需长度的连续片段是很有用的。
-
机器生成数据过滤
训练语言模型的目标之一是捕捉人类语言的分布。然而,网络爬取的数据集包含大量机器生成的文本,例如现有语言模型生成的文本、OCR文本和机器翻译文本。例如,来自http://patents.google.com的数据构成了C4语料库的大部分。该语料库使用机器翻译将来自世界各地专利机构的专利翻译成英语。此外,网络语料库中的数据还包含来自扫描书籍和文档的OCR生成文本。OCR系统并不完美,因此生成的文本与自然英语的分布不同(通常OCR系统会在拼写错误和完全遗漏单词等方面产生可预测的错误)——这点很重要,也很难搞,pdf扫描文档怎么去做还真挺头疼的。虽然很难识别机器生成的文本,但有一些工具,如ctrl-detector,可用于识别和检测机器生成的文本。在为语言建模预处理语料库时,重要的是对语料库中机器生成文本的存在进行表征和记录。
-
去重
从互联网上爬取原始文本创建的数据集往往会导致相同的序列被多次重复出现。例如,在论文《Deduplicating Training Data Makes Language Models Better》中,作者发现在C4数据集中,一个50个单词的序列被重复出现了60000次。事实上,在去重的数据集上训练模型速度更快,并且不太容易导致记忆效应——很不好。最近,研究人员还表明,在重复数据上训练的语言模型容易受到隐私攻击,其中对手从训练模型中生成序列并检测哪些序列来自训练集的记忆。在论文《Deduplicating Training Data Mitigates Privacy Risks in Language Models》中,作者展示了语言模型重新生成训练序列的速率与序列在训练集中的出现次数超线性相关。例如,一个在训练数据中出现10次的序列平均会比一个只出现一次的序列生成1000倍多。去重可以在不同粒度级别上执行。从精确匹配去重到模糊去重工具(例如deduplicate-text-datasets和datasketch),可以帮助减少和去除正在处理的语料库中的冗余文本。正如许多研究人员所指出的,需要理解去重过程需要大量计算资源(CPU和RAM),因为网页爬取数据集的大小,因此建议在分布式环境中运行此类计算。
-
清洗污染数据
这部分还挺保受争议的,可能还没有很细致的标准,不少公司也都挺功利的,就不好说。在NLP领域,我们常说的数据清洗,主要指的是训练数据和测试数据的区分和处理。在大型语言模型的情况下,由于训练和测试数据集都源于互联网,确保二者不发生交叉,这个过程可能颇具挑战。大型语言模型的评估通常会用到基准数据,如问答对,如果这些基准数据在训练数据中出现,可能会导致基准性能的高估。因此,需要进行去污染操作,也就是从训练数据中去除和基准数据集有重叠的部分,保证训练数据集的完整性。OpenAI的研究人员在创建WebText数据集时,就通过剔除所有维基百科内容来实现数据去污染,因为维基百科数据在他们的基准数据集中被广泛使用。另一个案例是EleutherAI的研究人员,他们开发了名为lm-eval harness的软件包,用以实现对基准数据集的去污染。在具体操作中,我们需要关注两类数据污染:
-
输入与输出污染:这种情况下,预训练语料库中存在与下游任务标签相同的数据。对于语言建模等任务,任务标签就是目标文本。如果目标文本在预训练语料库中出现,模型可能会倾向于复制文本,而非真正解决任务。
-
输入污染:这指的是评估样本中并未包含标签的情况,这也可能导致下游任务的性能高估。在进行零样本和少样本评估时,如果预训练数据集中存在与热门基准任务重叠的数据,我们必须重视数据去污染。
-
毒性和偏见控制
尽管网络语料库具有丰富的多样性,但其中也常常弥漫着毒性和偏见内容。如,《RealToxicityPrompts》一文中作者使用PerspectiveAPI指出,OpenWebText与WebText的内容中分别有2.1%与4.3%存在毒性分数超过50%。因此,在训练语言模型时,必须警觉并借助PerspectiveAPI等工具筛选掉预训练数据集中的毒性内容,以防止模型表现出偏见或在下游应用中产生有害内容。一种解决策略是过滤掉"bad words"名单中的文本,比如C4的作者们就采用了这种策略。另一个例子是,PILE数据集的研究者利用spamscanner来对有害内容进行分类。然而,执行此类过滤步骤必须极为谨慎,并需考虑到下游应用,以免过滤器保留下更可能坚持霸权观点的声音。在利用数据进行预训练语言模型之前,对贬损内容和性别/宗教偏见进行深度分析是必要的。
-
个人身份信息控制
在收集大型数据集时,理解与数据集实例相关的法律问题至关重要,尤其是在处理个人身份信息(PII)时,如真实姓名、组织名称、医疗记录、社会安全号码等。根据不同的应用,对这些信息进行遮蔽或删除在预训练语言模型之前是必要的。像presidio和pii-codex这样的工具提供了检测、分析和处理文本数据中个人身份信息的流程,这些工具能帮助确保数据集中的个人信息得到合理处理,以遵守相关隐私法规并保护用户隐私。
序列长度
大语言模型支持的序列长度主要受两方面影响:
-
训练阶段的最大长度
-
模型的长度外推性
第一点训练阶段的最大长度,可以通过DeepSpeed等分布式训练策略,减少模型的显存占用,从而提高训练的序列长度;
第二点模型的长度外推性,则通过位置编码的设计来实现,实现方式见模型结构设计小节。
模型结构设计
在梳理了大型语言模型所需具备的关键能力以及相应升级策略之后,本小节将重点关注大模型结构的设计方法。我们将深入探讨如何构建高效且强大的大型预训练模型。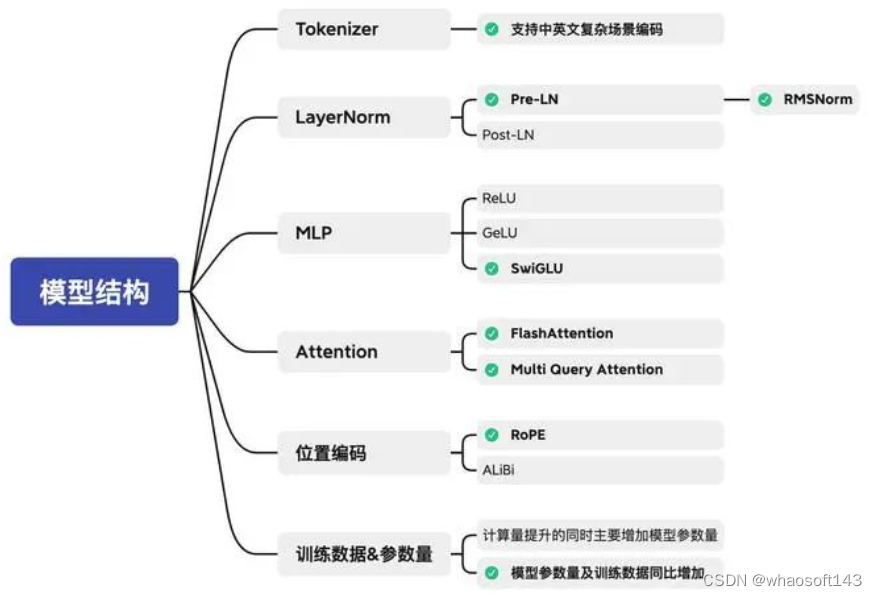 Tokenizer
Tokenizer
参照baichuan提及的Tokenizer设计方式,编码器需要能够处理复杂的中英文任务。
-
目前大部分开源模型主要基于英文优化,因此对中文语料存在效率较低的问题。我们使用 2000 万条以中英为主的多语言语料训练分词模型,显著提升对于中文的压缩率。
-
对于数学领域,我们参考了 LLaMA 和 Galactica 中的方案,对数字的每一位单独分开,避免出现数字不一致的问题,对于提升数学能力有重要帮助。
-
对于罕见字词(如特殊符号等),支持 UTF-8 characters 的 byte 编码,因此做到未知字词的全覆盖。
-
我们分析了不同分词器对语料的压缩率,如下表,可见我们的分词器明显优于 LLaMA, Falcon 等开源模型,并且对比其他中文分词器在压缩率相当的情况下,训练和推理效率更高。
| Model | Baichuan-7B | LLaMA | Falcon | mpt-7B | ChatGLM | moss-moon-003 |
|---|---|---|---|---|---|---|
| Compress Rate | 0.737 | 1.312 | 1.049 | 1.206 | 0.631 | 0.659 |
| Vocab Size | 64,000 | 32,000 | 65,024 | 50,254 | 130,344 | 106,029 |
LayerNorm
LayerNorm分为Pre-LN和Post-LN两种,有研究发现Post-LN在训练过程中不稳定,因此目前大模型基本都采用Pre-LN的训练方式。 LayerNorm计算方式:
LayerNorm计算方式:
首先计算均值与方差: RMSNorm计算方式:
RMSNorm计算方式:
RMSNorm假设均值为0,只针对方差进行归一化,训练速度更快且效果差距不大。
MLP
MLP小节主要涉及激活函数的选择。
Relu
ReLU是一种非常流行的激活函数,其数学表达式如下: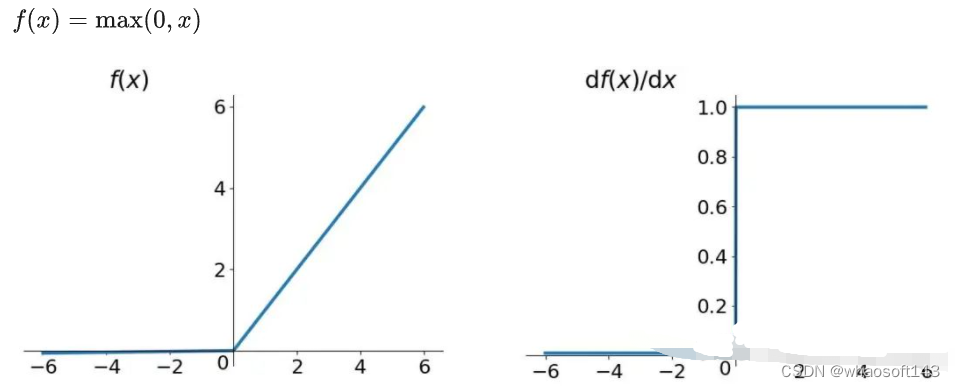 Gelu
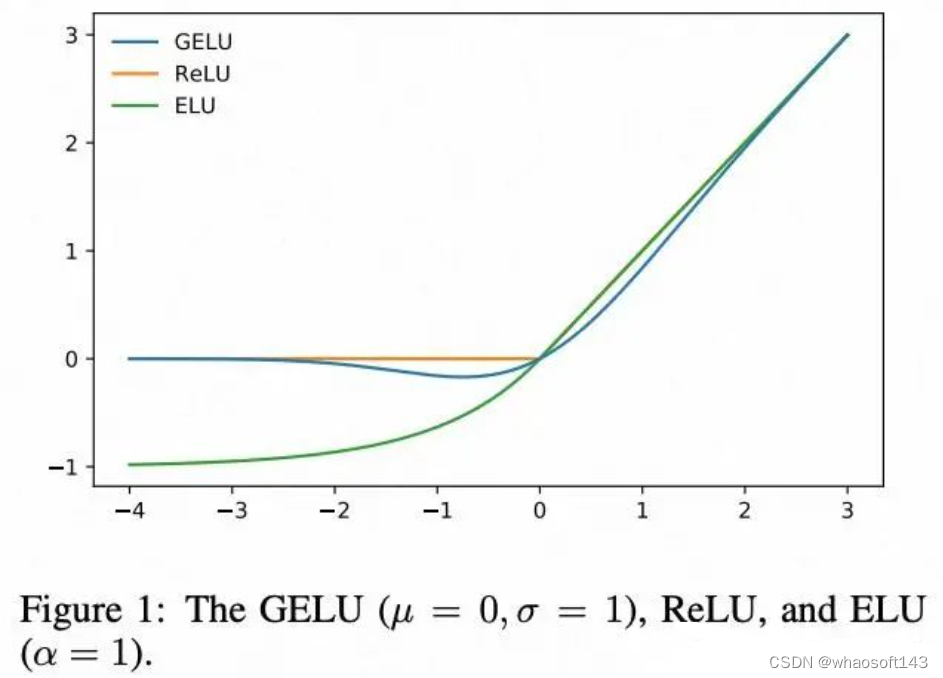
Gelu
高斯误差线性单元激活函数(Gaussian Error Linear Units(GELUS))的数学表达式如下:
Bert中GeLU代码如下:
- def gelu(input_tensor):
- cdf = 0.5 * (1.0 + tf.erf(input_tensor / tf.sqrt(2.0)))
- return input_tesnsor*cdf
SwiGLU&GeGLU
SwiGLU 和 GeGLU都是Noam Shazeer在文章中探索的激活函数变体
具体的,需要先了解门线性单元(Gated Linear Unit, GLU)这个基本的双线性函数,为
 作者并没有对激活函数提出的原理和动机做过多描述,论文本身是对各类激活函数变种效果的对比尝试,可以看到SwishGLU和GeGLU是可以取得最小误差的,而在大模型中也得到了广泛应用。
作者并没有对激活函数提出的原理和动机做过多描述,论文本身是对各类激活函数变种效果的对比尝试,可以看到SwishGLU和GeGLU是可以取得最小误差的,而在大模型中也得到了广泛应用。
Attention
Attention层主要针对Attention的算子进行优化,加速模型的推理和部署。
FlashAttention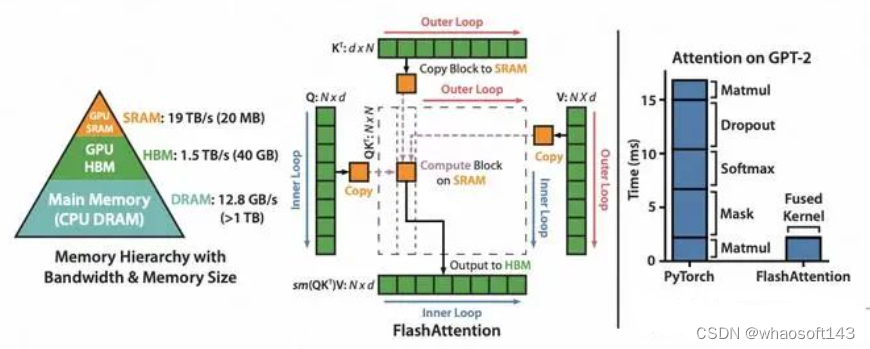 动机:当输入序列(sequence length)较长时,Transformer的计算过程缓慢且耗费内存,这是因为self-attention的time和memory complexity会随着sequence length的增加成二次增长。
动机:当输入序列(sequence length)较长时,Transformer的计算过程缓慢且耗费内存,这是因为self-attention的time和memory complexity会随着sequence length的增加成二次增长。 往往(例如GPT2中N=1024,d=64),因此FlashAttention会快很多。下图展示了两者在GPT-2上的Forward+Backward的GFLOPs、HBM、Runtime对比(A100 GPU):
往往(例如GPT2中N=1024,d=64),因此FlashAttention会快很多。下图展示了两者在GPT-2上的Forward+Backward的GFLOPs、HBM、Runtime对比(A100 GPU): GPU中存储单元主要有HBM和SRAM:HBM容量大但是访问速度慢,SRAM容量小却有着较高的访问速度。例如:A100 GPU有40-80GB的HBM,带宽为1.5-2.0TB/s;每108个流式多核处理器各有192KB的片上SRAM,带宽估计约为19TB/s。可以看出,片上的SRAM比HBM快一个数量级,但尺寸要小许多数量级。
GPU中存储单元主要有HBM和SRAM:HBM容量大但是访问速度慢,SRAM容量小却有着较高的访问速度。例如:A100 GPU有40-80GB的HBM,带宽为1.5-2.0TB/s;每108个流式多核处理器各有192KB的片上SRAM,带宽估计约为19TB/s。可以看出,片上的SRAM比HBM快一个数量级,但尺寸要小许多数量级。
综上,FlashAttention目的不是节约FLOPs,而是减少对HBM的访问。重点是FlashAttention在训练和预测过程中的结果和标准Attention一样,对用户是无感的,而其他加速方法做不到这点。
Multi Query Attention
论文地址:https://arxiv.org/pdf/1911.0215
MQA 是 19 年提出的一种新的 Attention 机制,其能够在保证模型效果的同时加快 decoder 生成 token 的速度。 从上图表中可以看到,MQA 在 encoder 上的提速没有非常明显,但在 decoder 上的提速是很显著的。
从上图表中可以看到,MQA 在 encoder 上的提速没有非常明显,但在 decoder 上的提速是很显著的。  从论文的解释中可以看到,MQA 让所有的头之间 共享 同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
从论文的解释中可以看到,MQA 让所有的头之间 共享 同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
即:MQA 实际上是将 head 中的 key 和 value 矩阵抽出来单独存为一份共享参数,
而 query 则是依旧保留在原来的 head 中,每个 head 有一份自己独有的 query 参数。
代码实现:
实现方式很简单,将原维度直接变成头数*维度的总和。
- # Multi Head Attention
- self.Wqkv = nn.Linear( # 【关键】Multi-Head Attention 的创建方法
- self.d_model,
- 3 * self.d_model, # 有 query, key, value 3 个矩阵, 所以是 3 * d_model
- device=device
- )
-
- query, key, value = qkv.chunk( # 【关键】每个 tensor 都是 (1, 512, 768)
- 3,
- dim=2
- )
-
-
- # Multi Query Attention
- self.Wqkv = nn.Linear( # 【关键】Multi-Query Attention 的创建方法
- d_model,
- d_model + 2 * self.head_dim, # 只创建 query 的 head 向量,所以只有 1 个 d_model
- device=device, # 而 key 和 value 不再具备单独的头向量
- )
-
- query, key, value = qkv.split( # query -> (1, 512, 768)
- [self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96)
- dim=2 # value -> (1, 512, 96)
- )
即K,V的维度从d_model转成self.head_dim
在 MQA 中,除了 query 向量还保存着 8 个头,key 和 value 向量都只剩 1 个「公共头」了。
这也正好印证了论文中所说的「所有 head 之间共享一份 key 和 value 的参数」。
剩下的问题就是如何将这 1 份参数同时让 8 个头都使用,
代码里使用矩阵乘法 matmul 来广播,使得每个头都乘以这同一个 tensor,以此来实现参数共享:
- def scaled_multihead_dot_product_attention(
- query,
- key,
- value,
- n_heads,
- multiquery=False,
- ):
- q = rearrange(query, 'b s (h d) -> b h s d', h=n_heads) # (1, 512, 768) -> (1, 8, 512, 96)
- kv_n_heads = 1 if multiquery else n_heads
- k = rearrange(key, 'b s (h d) -> b h d s', h=kv_n_heads) # (1, 512, 768) -> (1, 8, 96, 512) if not multiquery
- # (1, 512, 96) -> (1, 1, 96, 512) if multiquery
- v = rearrange(value, 'b s (h d) -> b h s d', h=kv_n_heads) # (1, 512, 768) -> (1, 8, 512, 96) if not multiquery
- # (1, 512, 96) -> (1, 1, 512, 96) if multiquery
-
- attn_weight = q.matmul(k) * softmax_scale # (1, 8, 512, 512)
- attn_weight = torch.softmax(attn_weight, dim=-1) # (1, 8, 512, 512)
-
- out = attn_weight.matmul(v) # (1, 8, 512, 512) * (1, 1, 512, 96) = (1, 8, 512, 96)
- out = rearrange(out, 'b h s d -> b s (h d)') # (1, 512, 768)
-
- return out, attn_weight, past_key_value
位置编码
这里列出常见大模型应用的RoPE和ALiBi位置编码,从选择方式上更倾向于RoPE,可以通过位置插值等方式进行更长的长度外推。 whaosoft aiot http://143ai.com
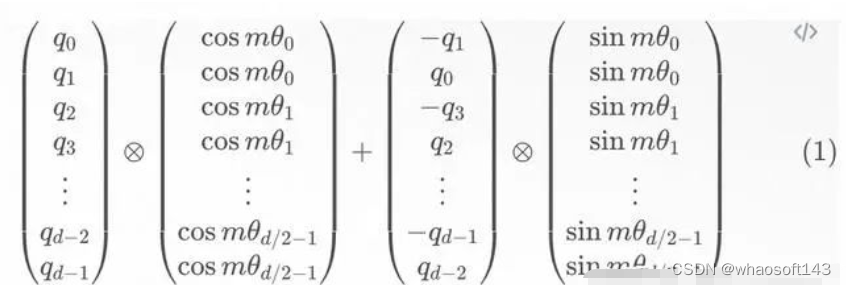
RoPE
-
实现方式:

ALiBi

实现方式:
本文的做法是不添加position embedding,然后添加一个静态的不学习的bias,如上图: 优势:
优势:
-
减少了需要训练的Embedding,加快训练速度
-
较原位置编码,具有更好的长度外推性
训练数据&参数量
详细内容见LLM训练指南:Token及模型参数准备,这里给出关键性结论,模型计算量增加时,训练数据和参数量应该保持同比增加:
| Parameters | FLOPs | FLOPs (in Gopher unit) | Tokens |
|---|---|---|---|
| 400 Million | 1.92e+19 | 1//29,968 | 8.0 Billion |
| 1 Billion | 1.21e+20 | 1//4,761 | 20.2 Billion |
| 10 Billion | 1.23e+22 | 1//46 | 205.1 Billion |
| 67 Billion | 5.76e+23 | 1 | 1.5 Trillion |
| 175 Billion | 3.85e+24 | 6.7 | 3.7 Trillion |
| 280 Billion | 9.90e+24 | 17.2 | 5.9 Trillion |
| 520 Billion | 3.43e+25 | 59.5 | 11.0 Trillion |
| 1 Trillion | 1.27e+26 | 221.3 | 21.2 Trillion |
| 10 Trillion | 1.30e+28 | 22515.9 | 216.2 Trillion |
总结
经过对ChatGLM、LLAMA和Baichuan大型语言模型升级之路的深入探讨,以及对LLM结构选型的全面分析,我们可以得出以下结论:
-
大型预训练模型的升级过程主要体现在基础知识能力的提升和支持的序列长度变化。通过增加模型参数量和优化训练数据质量,模型可以更好地拟合各个领域的知识,并进一步提高模型性能;通过增加训练长度和调整位置编码外推性,支持更长的序列。
-
在模型结构设计方面,选择合适的LLM结构对于实现高性能的大型预训练模型至关重要。通过引入合适的LayerNorm和激活函数,提高训练的稳定性;通过引入高效的算子,如Flash Attention和Multi Query Attention,可以在保持模型性能的同时显著提高计算效率;通过引入RoPE或ALiBi位置编码,提高模型的长度外推性。
-
在构建和优化大型预训练模型时,不仅要关注模型的性能和计算效率,还应重视数据质量、去重、去污染、毒性与偏见控制以及个人信息保护等方面的问题。这将有助于使模型在实际应用中更具安全性、鲁棒性和可靠性。
总之,本文通过深入剖析ChatGLM、LLAMA和Baichuan模型的升级路径,以及探讨大型语言模型结构选型,为大家提供了一个系统性的视角,梳理了大型预训练模型的关键要素。我们希望这些知识能够为大家在实际工程中构建更强大、灵活且高效的大型预训练模型提供有力的参考和指导。


