
热门标签
热门文章
- 12023年元宇宙五大趋势已定 如何夺得先机?_元宇宙未来发展趋势
- 2idea ——idea中Git提交代码到远程仓库回退步骤_idea回退远程仓库代码
- 3[超拟人语音合成] 科大讯飞API的Python实现_科大讯飞python语音对话
- 4壁纸动态-Mac电脑-4K超高清[po破]动态壁纸[解]Dynamic WallPaper 安装使用教程_dynamic wallpaper 18.4版
- 5git clone的时候直接加上用户名和密码_git clone 命令加上用户名
- 6Android 使用ping命令判断当前网络状态_android ping
- 7转载:大数据基础服务平台
- 8YOLOv8优化策略:注意力机制涨点系列篇| 多维协作注意模块MCA,效果秒杀ECA、SRM、CBAM等_mca注意力机制
- 9确定当前Python环境中的site-packages目录位置
- 10数组删除的各种方法
当前位置: article > 正文
【Python爬虫】项目案例讲解,一步步教你爬取淘宝商品数据!_爬虫爬取淘宝商品数据
作者:从前慢现在也慢 | 2024-06-11 23:31:33
赞
踩
爬虫爬取淘宝商品数据
前言
随着互联网时代的到来,人们更加倾向于互联网购物,某宝又是电商行业的巨头,在某宝平台中有很多商家数据,今天带大家使用python+selenium工具获取这些公开的商家数据
环境介绍:
- python 3.6
- pycharm
- selenium
- csv
- time
- random
这次的受害者:淘宝购物平台
1. 创建一个浏览器对象
from selenium import webdriver
driver = webdriver.Chrome()
1.2.
- 1
- 2
- 3
2. 执行自动化页面操作
driver.get('https://www.taobao.com/')
driver.maximize_window() # 最大化浏览器
driver.implicitly_wait(10) # 设置浏览器的隐式等待, 智能化的等待
1.2.3.
- 1
- 2
- 3
- 4
到这一步,你就可以自己运行代码看看可不可以自动打开你的浏览器进入淘宝的首页
3. 根据关键字搜索商品, 解决登录
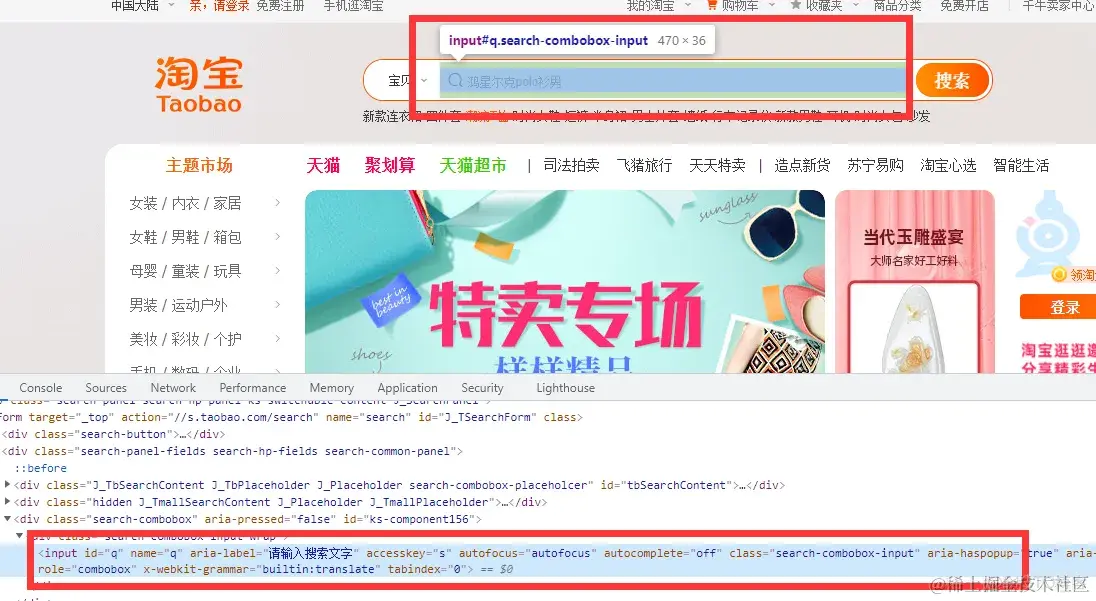
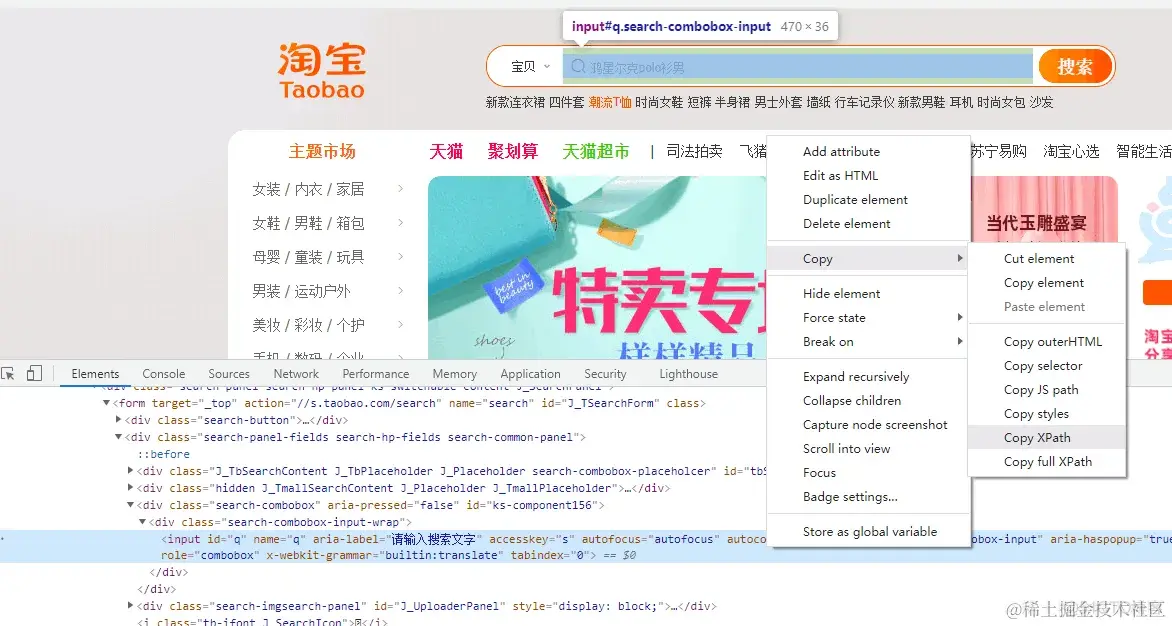
复制它的xpath,用xpath语法提取页面标签的元素
def search_product(keyword):
# 输入框的标签对象
driver.find_element_by_xpath('//*[@id="q"]').send_keys(keyword)
word = input('请输入你要搜索商品的关键字:')
1.2.3.4.5.
- 1
- 2
- 3
- 4
- 5
- 6
运行代码

前面搞定了搜索框的,现在来写点击搜索按钮的,同样复制它的xpath
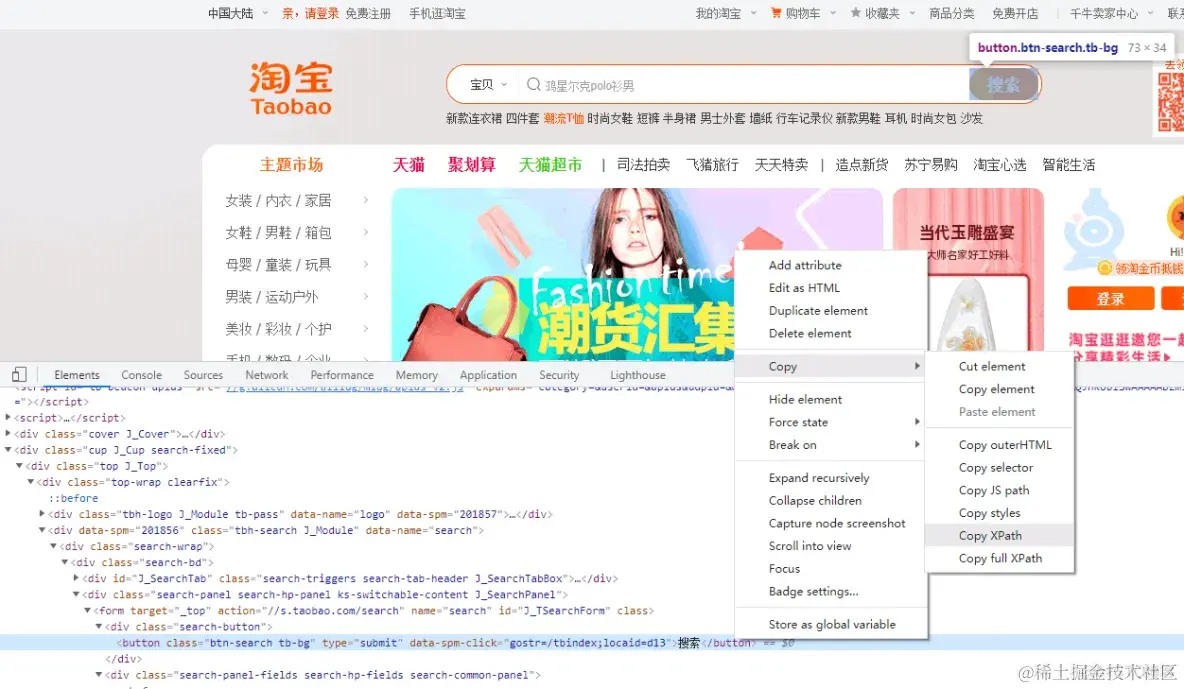
# 为了避免被检测
import time # 时间模块 内置模块
time.sleep(random.randint(1, 3)) # 随机休眠1到3秒
driver.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click()
1.2.3.4.
- 1
- 2
- 3
- 4
- 5
4. 解决登录
点击了搜索按钮以后,会弹出登录界面给你,那就继续解决登录
driver.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(TAO_USERNAME)
time.sleep(random.randint(1, 2))
driver.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(TAO_PASSWORD)
time.sleep(random.randint(1, 2))
driver.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click()
1.2.3.4.5.
- 1
- 2
- 3
- 4
- 5
- 6
5. 解析数据
获取目标数据的div标签
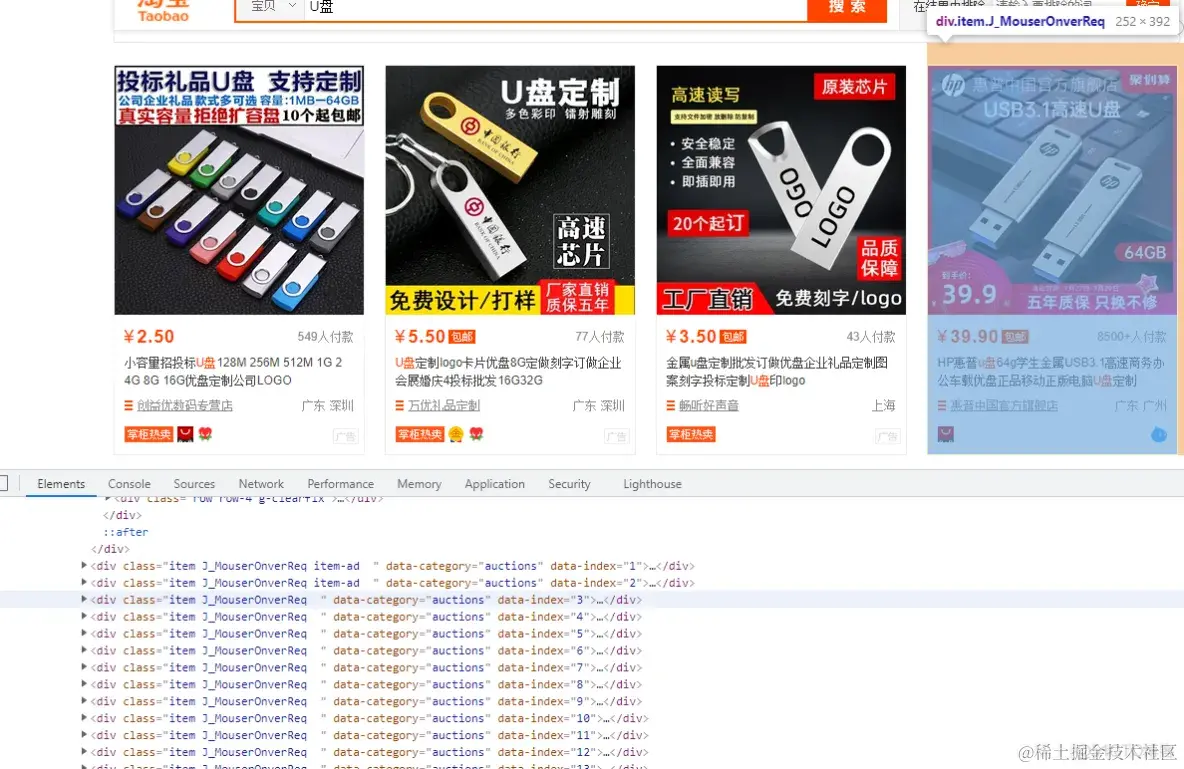
def parse_data():
# 所有div标签
divs = driver.find_elements_by_xpath('//div[@class="grid g-clearfix"]/div/div')
1.2.3.
- 1
- 2
- 3
- 4
用for循环遍历取值
for div in divs: # 二次提取
title = div.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
price = div.find_element_by_xpath('.//strong').text + '元' # 商品价格 # 手写
deal = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text # 付款人数 # 手写
name = div.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text # 店铺名称 # 手写
location = div.find_element_by_xpath('.//div[@class="location"]').text # 店铺地址 # 手写
detail_url = div.find_element_by_xpath('.//div[@class="pic"]/a').get_attribute('href') # 详情页地址 # 手写
print(title, price, deal, name, location, detail_url)
1.2.3.4.5.6.7.8.9.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行代码,可以看到获取的数据了
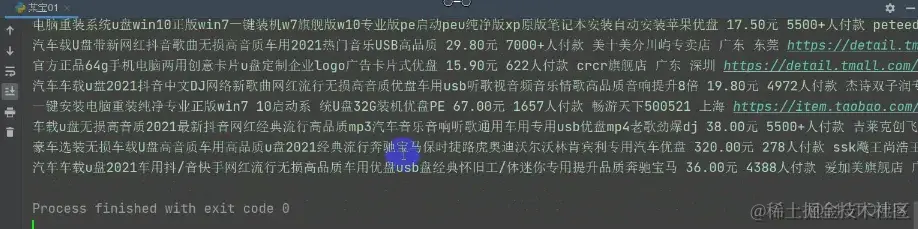
6. 最后一步,保存数据
import csv
with open('淘宝.csv', mode='a', encoding='utf-8', newline='') as f:
csv_write = csv.writer(f) # 实例化csv模块写入对象
csv_write.writerow([title, price, deal, name, location, detail_url])
1.2.3.4.5.
- 1
- 2
- 3
- 4
- 5
- 6
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/705166
推荐阅读

相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

