
- 1MySQL表的增删改查初阶(下篇)
- 2第八章 软件项目团队管理_软件技术支持团队年度规划
- 3MYSQL存储过程用法及优缺点_mysql 存储过程有什么好处
- 4Spark向量化计算在美团生产环境的实践_我们采用的策略是通过在gluten侧调低velox partial aggregation的flus
- 5软件开发技术名词 _软件学科引用技术关键名词
- 6androidstudio旧版本下载_android studio 历史版本下载
- 7服饰数据集_开源服装数据集
- 8腾讯云OpenCloudOS安装ES(elasticsearch7.17.16)
- 9MySQL之体系结构_mysql体系结构
- 10Spark安装与基本操作_头歌spark的安装与使用
聚类算法K-Means原理及 Python 实现_对data.csv中的数据通过计算每个点到每个初始的聚类中心的距离进行分类
赞
踩
聚类
一、聚类任务
在无监督的学习中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭露数据的内在性质及规律,为进一步的数据的分析提供基础,此类学习任务中研究最多、应用最广泛的是聚类。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇,通过这样的划分,每个簇可能对应于一些潜在的类别。聚类过程仅能自动形成簇结构,簇对应的概念语义需由使用者来把握和命名。
下面讨论聚类算法涉及的两个基本问题——性能度量和距离计算
二、性能度量
性能度量也称为聚类的 “有效性指标”,在聚类结果中,我们需通过某种性能度量来评估其好坏,另一方面,若明确了最终将要使用的性能度量,则可直接将其作为聚类过程的优化目标,从而得到符合要求的聚类结果。聚类将样本集 D 划分为若干互不相交的子集,即样本簇,我们希望同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。
聚类性能指标大致分为两类——外部指标、内部指标
1.外部指标
指将聚类结果与某个 “参考模型” 进行比较。

则外部指标主要有:
- Jaccard 系数(简称 JC )
- FM 指数(简称 FMI )
- Rand 指数(简称 RI )
上述性能度量的结果值均在 [0,1] 区间,值越大越好。
2.内部指标

则内部指标主要有:
- DB 指数(简称 DBI )
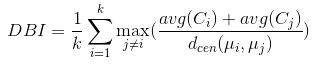
- Dunn 指数(简称 DI )

DBI 的值越小越好,DI 的值越大越好。
三、距离计算
距离度量需要满足一些基本性质:
- 非负性
- 同一性(两点相同时,距离为0)
- 对称性
- 直递性(也称为三角不等式)
我们常将属性划分为 ”连续属性“ 和 ”离散属性“,前者在定义域有无穷多个取值,后者在定义域有有限个取值。在讨论距离计算时,可以再属性上计算距离的为 ”有序属性“,例如定义域 {1,2,3} 的离散属性和连续属性的性质更接近一些,可以直接计算。而定义域 {飞机、火车、轮船} 这样的离散属性不能直接计算距离,称为 ”无序属性“。
常用的有序属性:
- 闵可夫斯基距离
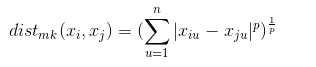
- p=2 时,欧氏距离
- p=1 时,曼哈顿距离
常用的无序属性:
- 令
mu,a 表示在属性 u 上取值为 a 的样本数,

