
热门标签
热门文章
- 1【ARMv9 DSU-120 系列 6.1 -- PPU power and reset control】_arm ppu
- 2JS防抖和节流详解_js 节流
- 3使用git clone命令出现error: RPC failed; curl 18 transfer closed with outstanding read data remaining问题_tortoisegit git clone 拉取项目时报错 rpc failed; curl 18
- 4你知道RocketMQ消息队列吗?_rocketmq默认队列
- 5【K哥爬虫普法】某博士爬虫团伙贩卖个人信息,被一网打尽!
- 6网络安全最全微服务高并发秒杀实战_基于令牌桶实现库存(2),2024年最新掌握这些知识点再也不怕面试通不过
- 7客户端Nacos的安装,启动,及在IDEA中属性相关配置,与Eureka的相关属性配置_idea nacos配置
- 82024 应届校招经验分享(互联网篇)_互联网校招
- 9lda主题模型困惑度_nlp中的主题模型
- 10数据结构——二叉树的遍历及应用_以二叉链表作为二叉树的存储结构,编写以下算法: (1)输出二叉树的先序遍历序列、中
当前位置: article > 正文
Spark计算引擎介绍_spark 技术引擎
作者:从前慢现在也慢 | 2024-06-16 16:31:04
赞
踩
spark 技术引擎
1. Spark是什么
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。
Spark是加州大学伯克利分校的AMP实验室(Algorithms, Machines and People Lab)开源的类Hadoop MapReduce的通用并行框架,拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是Job(工作)中间输出的结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是一种与Hadoop相似的开源集群计算环境,但是两者之间存在一些不同之处,这些不同之处使Spark在某些工作负载方面表现得更加优越,换句话说,Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark是在Scala语言中实现的,它将Scala用作应用程序框架。与Hadoop不同,Spark和Scala能够紧密集成,其中的Scala可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建Spark是为了支持分布式数据集上的迭代作业,但是实际上它是对Hadoop的补充,可以在Hadoop文件系统中并行运行。通过名为Mesos的第三方集群框架可以支持此行为。Spark可以用来构建大型的、低延迟的数据分析应用程序。
2. Spark生态体系
Spark属于BDAS(伯利克分析栈)生态体系。
- MapReduce属于Hadoop生态体系之一,Spark则属于BDAS生态体系之一。
- Hadoop包含了MapReduce、HDFS、HBase、Hive、ZooKeeper、Pig、Sqoop等。
- BDAS包含了Spark GraphX、Spark SQL(相当于Hive)、Spark MLlib、Spark Streaming(消息实时处理框架,类似Storm)、BlinkDB等。
Spark的生态体系示意图如下。
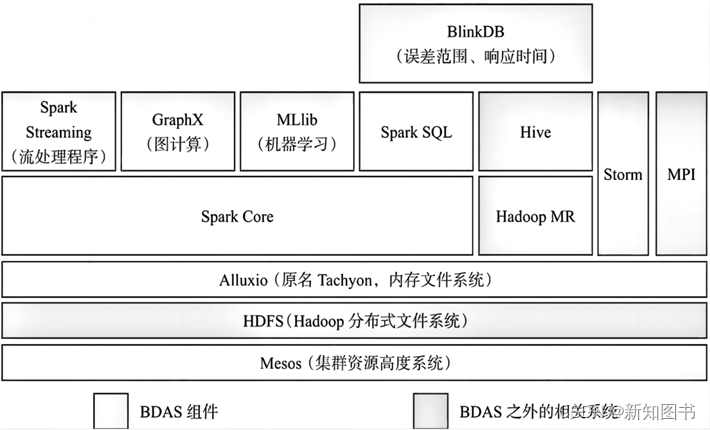
3.Spark运行模式
Spark有5种运行模式,其中Local是单机模式,其他4种都是集群模式:
- Local:Spark运行在本地模式上,用于测试、开发。本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境。
- Standlone:Spark运行在独立集群模式上。Spark中的各个角色以独立进程的形式存在,并组成Spark集群环境。
- Hadoop YARN:Spark运行在YARN上。Spark中的各个角色运行在YARN的容器内部,并组成Spark集群环境。
- Apache Mesos:Spark中的各个角色运行在Apache Mesos上,并组成Spark集群环境。
- Kubernetes:Spark中的各个角色运行在Kubernetes的容器内部,并组成Spark集群环境。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/727391
推荐阅读
相关标签

