
- 1Unity 植物大战僵尸(一)_unity 复刻 植物大战僵尸1代
- 2redis数据迁移工具之 RedisShake_redis-shake restore模式
- 3Python项目实战练习:制作小型图书管理系统_python综合训练迷你图书馆
- 4Embedding和Rerank模型介绍_embedding rerank
- 5Hive项目之谷粒影音:ETL清洗原数据、Hive统计视频观看数top10、视频类别top、视频观看数top其所属类别、类别流量top、类别热度top、上传视频用户数量top、类别视频观看top
- 6【华为OD机试真题 JS语言】387、密码输入检测 | 机试真题+思路参考+代码解析 (最新抽中C卷)(本题100%)_密码输入检测od
- 7spark与akka_与Akka建立虚拟电厂
- 82023-2024华为ICT大赛中国区 实践赛网络赛道 全国总决赛 理论部分真题
- 9Docker——开源的应用容器的引擎_开源容器引擎是指什么
- 10python中threading模块_python中threading模块详解
RabbitMQ如何做到不丢不重_生产环境rabbitmq如何保证消息不丢
赞
踩
目录
MQTT协议
先来说下MQTT协议中的3种语义,这个非常重要。
在MQTT协议中,给出了三种传递消息时能够提供的服务质量标准,这三种服务质量从低到高依次是:
At most once:至多一次。消息在传递时,最多会被送达一次。也就是说,没什么消息可靠性保证,允许丢消息。
At least once:至少一次。消息在传递时,至少会被送达一次。也就是说,不允许丢消息,但是允许有少量重复消息出现。
Exactly once:恰好一次。消息在传递时,只会被送达一次,不允许丢失也不允许重复,这个是最高的等级 这个服务质量标准不仅适用于MQTT,对所有的消息队列都是适用的。现在常用的绝大部分消息队列提供的服务质量都是 At least once,包括RocketMQ、RabbitMQ和Kafka都是这样。也就是说,消息队列很难保证消息不重复。
At least once+幂等消费=Exactly once
如何保证消息100%不丢失
消息从生产端到消费端消费要经过3个步骤:
- 生产端发送消息到RabbitMQ;
- RabbitMQ发送消息到消费端;
- 消费端消费这条消息;
所以要保证消息不丢,就得从三个方面入手,分别是生产端、RabbitMQ的Broker端、消费端。三个都保证不丢失,才能保证100%不丢。
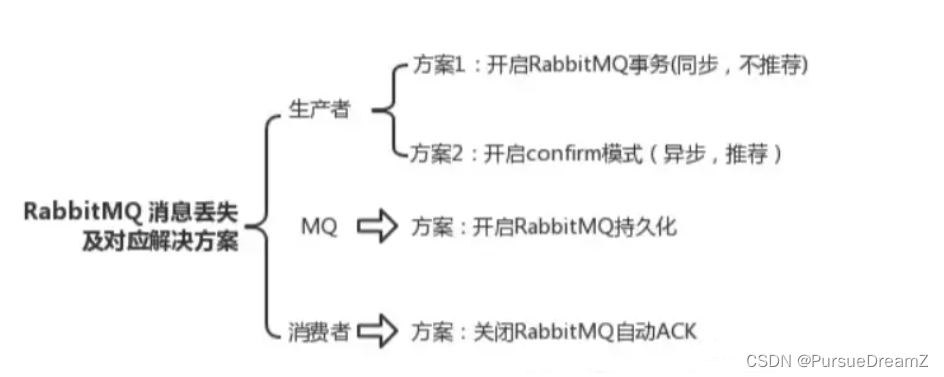
生产端可靠性投递
事务机制:
- // 设置channel开启事务
- rabbitTemplate.setChannelTransacted(true);
-
-
- @Bean
- public RabbitTransactionManager rabbitTransactionManager(ConnectionFactory connectionFactory)
- {
- return new RabbitTransactionManager(connectionFactory);
- }
-
- @Transactional(rollbackFor = Exception.class,transactionManager = "rabbitTransactionManager")
- public void publishMessage(String message) throws Exception {
- rabbitTemplate.setMandatory(true);
- rabbitTemplate.convertAndSend("java",message);
- }
confirm消息确认机制:
- # 开启发送确认
- spring.rabbitmq.publisher-confirm-type=correlated
- # 开启发送失败回退
- spring.rabbitmq.publisher-returns=true
- @Configuration
- @Slf4j
- public class RabbitMQConfig {
-
- @Autowired
- private RabbitTemplate rabbitTemplate;
-
- @PostConstruct
- public void enableConfirmCallback() {
- //confirm 监听,当消息成功发到交换机 ack = true,没有发送到交换机 ack = false
- //correlationData 可在发送时指定消息唯一 id
- rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
- if(!ack){
- //记录日志、落库定时任务扫描重发,同时对开发人员进行通知
- }
- });
-
- //当消息成功发送到交换机没有路由到队列触发此监听
- rabbitTemplate.setReturnsCallback(returned -> {
- //记录日志、落库、同时对开发人员进行通知
- });
- }
- }

一般不推荐事务的模式,因为是同步的会影响性能,所以都会采用异步回调的confirm模式。
RabbitMQ的Broker端投
说三点:
(1)要保证rabbitMQ不丢失消息,那么就需要开启rabbitMQ的持久化机制,即把消息持久化到硬盘上,这样即使rabbitMQ挂掉在重启后仍然可以从硬盘读取消息;
(2)如果rabbitMQ单点故障怎么办,这种情况倒不会造成消息丢失,这里就要提到rabbitMQ的3种安装模式,单机模式、普通集群模式、镜像集群模式,这里要保证rabbitMQ的高可用就要配合HAPROXY做镜像集群模式
(3)如果硬盘坏掉怎么保证消息不丢失
(1)消息持久化
RabbitMQ 的消息默认存放在内存上面,如果不特别声明设置,消息不会持久化保存到硬盘上面的,如果节点重启或者意外crash掉,消息就会丢失。
所以就要对消息进行持久化处理。如何持久化,下面具体说明下:
要想做到消息持久化,必须满足以下三个条件,缺一不可。
1) Exchange 设置持久化
2)Queue 设置持久化
3)Message持久化发送:发送消息设置发送模式deliveryMode=2,代表持久化消息
(2)设置集群镜像模式
我们先来介绍下RabbitMQ三种部署模式:
1)单节点模式:最简单的情况,非集群模式,节点挂了,消息就不能用了。业务可能瘫痪,只能等待。
2)普通模式:消息只会存在与当前节点中,并不会同步到其他节点,当前节点宕机,有影响的业务会瘫痪,只能等待节点恢复重启可用(必须持久化消息情况下)。
3)镜像模式:消息会同步到其他节点上,可以设置同步的节点个数,但吞吐量会下降。属于RabbitMQ的HA方案
为什么设置镜像模式集群,因为队列的内容仅仅存在某一个节点上面,不会存在所有节点上面,所有节点仅仅存放消息结构和元数据。
如果想解决上面途中问题,保证消息不丢失,需要采用HA 镜像模式队列。
下面介绍下三种HA策略模式:
1)同步至所有的
2)同步最多N个机器
3)只同步至符合指定名称的nodes
命令处理HA策略模版:rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
1)为每个以“rock.wechat”开头的队列设置所有节点的镜像,并且设置为自动同步模式 rabbitmqctl set_policy ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}' rabbitmqctl set_policy -p rock ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
2)为每个以“rock.wechat.”开头的队列设置两个节点的镜像,并且设置为自动同步模式 rabbitmqctl set_policy -p rock ha-exacly "^rock.wechat" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
3)为每个以“node.”开头的队列分配指定的节点做镜像 rabbitmqctl set_policy ha-nodes "^nodes." '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
但是:HA 镜像队列有一个很大的缺点就是:系统的吞吐量会有所下降。
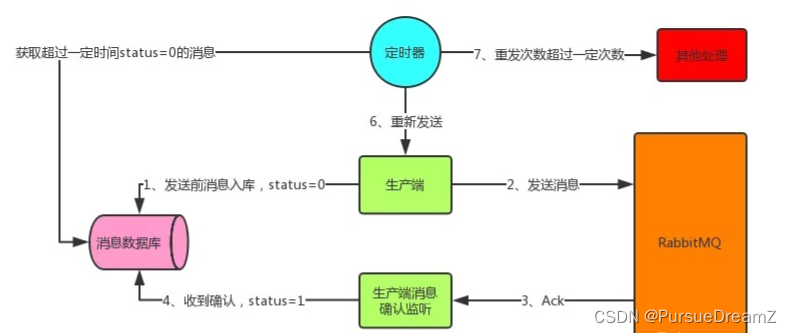
(3)消息补偿机制
为什么还要消息补偿机制呢?难道消息还会丢失,没错,系统是在一个复杂的环境,不要想的太简单了,虽然以上的三种方案,基本可以保证消息的高可用不丢失的问题,
但是作为有追求的程序员来讲,要绝对保证我的系统的稳定性,有一种危机意识。
比如:持久化的消息,保存到硬盘过程中,当前队列节点挂了,存储节点硬盘又坏了,消息丢了,怎么办?
1)生产端首先将业务数据以及消息数据入库,需要在同一个事务中,消息数据入库失败,则整体回滚
2)根据消息表中消息状态,失败则进行消息补偿措施,重新发送消息处理。
消费端
ACK机制改为手动
RabbitMQ的自动ack机制默认在消息发出后就立即将这条消息删除,而不管消费端是否接收到,是否处理完。
我们需要进行手动消费
- #开启手动ACK,消费消息的时候,就必须发送ack确认,不然消息永远还在队列中
- spring.rabbitmq.listener.simple.acknowledge-mode=manual
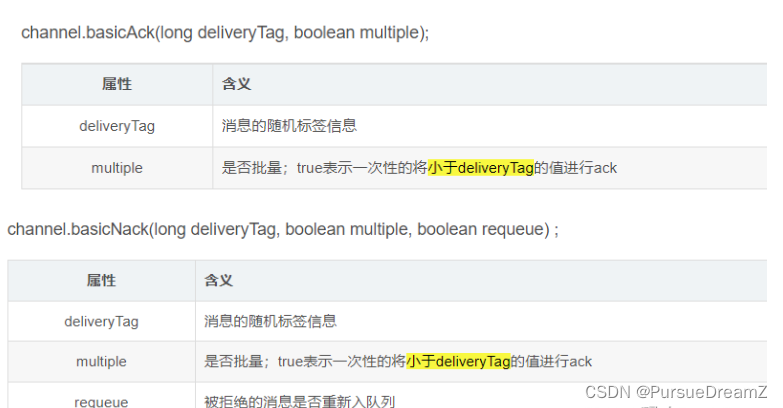
basicNack 方法的第三个参数代表是否重回队列,通常代码的报错并不会因为重试就能解决,所以可能这种情况:继续被消费,继续报错,重回队列,继续被消费…死循环。
一定要有重发消息次数的限制,或者干脆不入队,发送到Redis进行下记录也行。一般就不会再次入队了,而是记录并通知开发人员,进行手动处理
-
-
- @RabbitHandler
- @RabbitListener(queuesToDeclare = @Queue(RabbitMQConfig.RABBITMQ_DEMO_TOPIC))
- public void process(String msg, Message message, Channel channel) {
- long tag = message.getMessageProperties().getDeliveryTag();
- Action action = Action.SUCCESS;
- try {
- System.out.println("消费者RabbitDemoConsumer从RabbitMQ服务端消费消息:" + msg);
- if ("bad".equals(msg)) {
- throw new IllegalArgumentException("测试:抛出可重回队列的异常");
- }
- if ("error".equals(msg)) {
- throw new Exception("测试:抛出无需重回队列的异常");
- }
- } catch (IllegalArgumentException e1) {
- e1.printStackTrace();
- //根据异常的类型判断,设置action是可重试的,还是无需重试的
- action = Action.RETRY;
- } catch (Exception e2) {
- //打印异常
- e2.printStackTrace();
- //根据异常的类型判断,设置action是可重试的,还是无需重试的
- action = Action.REJECT;
- } finally {
- try {
- if (action == Action.SUCCESS) {
- //multiple 表示是否批量处理。true表示批量ack处理小于tag的所有消息。false则处理当前消息
- channel.basicAck(tag, false);
- } else if (action == Action.RETRY) {
- //Nack,拒绝策略,消息重回队列
- channel.basicNack(tag, false, true);
- } else {
- //Nack,拒绝策略,并且从队列中删除
- channel.basicNack(tag, false, false);
- }
- channel.close();
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
- }
总结
如果需要保证消息在整条链路中不丢失,那就需要生产端、mq自身与消费端共同去保障。
生产端:对生产的消息进行状态标记,开启confirm机制,依据mq的响应来更新消息状态,使用定时任务重新投递超时的消息,多次投递失败进行报警。
mq自身:开启持久化,并在落盘后再进行ack。如果是镜像部署模式,需要在同步到多个副本之后再进行ack。
消费端:开启手动ack模式,在业务处理完成后再进行ack,并且需要保证幂等。
通过以上的处理,理论上不存在消息丢失的情况,但是系统的吞吐量以及性能有所下降。

