
- 1Python浅聊进程(multiprocessing)和线程(threading)_python multiprocessing threading
- 2Unity shader Reflect 取反问题_shader取相反
- 3opencv之图像拼接_java opencv 图片去重拼接
- 4vue+elementUI中Collapse的title自定义如何阻止冒泡事件_elementui collapse title自定义点击事件
- 5(2)(2.1) Andruav Android Cellular(二)
- 6PyQt5 QTableWidge 一行或一列也可以使用滚动条_pyqt designer设置tablewidget跟随插入行滚动
- 7Unity DOTS《群体战斗弹幕游戏》核心技术分析之3D角色动画_dots可使用的连连看shader
- 8arcpy批量按掩膜提取(用矢量裁剪栅格)_掩膜提取后转矢量
- 9Vue2(一):初识Vue、模板语法、数据绑定、el和data的两种写法、MVVM、数据代理、事件_vue2,data写法
- 10kafka集群搭建(三) -kafka可视化管理工具kafka tool2使用_kafkatool kafka_client_jaasecs.conf
论文笔记:nnU-Net: Self-adapting Frameworkfor U-Net-Based Medical Image Segmentation_nnu-net 低分辨率和高分辨率
赞
踩
0 abstract
U-net 在图像分割中是一个很有用的模型。针对不同的问题,U-net在模型架构、预处理、训练和推导上均有一定的自由度。这些部分对于模型整体表现起到很重要的作用。
这篇论文提出了nnU-net(no-new U-net),这是一个2D & 3D经典U-net基础上, 稳健而又自适应的框架。nnU-net移去了冗余的部分,着重于剩下的对模型表现和泛化能力起作用的部分。
1 introduction
大部分医学图像分割的方法是基于CNN的方法。但是对于不同的问题和不同的数据集,需要特定的模型架构和训练方法。这会使得某一个医学图像分割方法仅在很小的一些情形中有效。
医学分割十项比赛(The Medical Segmentation Decathlon)希望模型能够在10个不同的数据集上都有很好的效果(人体的不同部位)。算法只可以自适应地根据特定的数据集进行调整(不能看到数据之后再人为地进行调整)。
挑战由两个阶段组成:
(1)第一个阶段,比赛参与者可以看到7个数据集,根据这7个数据集设计、优化模型
(2)第二个阶段,模型将会固定(只能自适应地调整),在剩下3个之前不公开的数据集上进行测试
论文认为现有的模型在结构方面的调整可能会导致模型在某一些特定的数据集上过拟合,同时非架构的部分在图像分割任务中更重要。
于是论文提出了 nnU-Net(“no-new-Net”)。他没有使用很多CNN便体重用过的残差链接、密集连接(densenet)以及attention,只是对原始U-Net进行了很少的调整。
但是nnU-Net可以根据给定的图像自动地调整其结构,同时可以自适应地确定其他的步骤。比如预处理(重采样、正则化)、训练(损失函数、优化器、数据增强)、推导、后处理。。。
2 模型
2.1 模型框架
医学图像通常是一个三维图像,所以会有2D U-Net,3D U-Net 和层级U-Net。前两个会生成高分辨的图像分割;层级U-Net则会首先生成低分辨率的分割,然后再生成高分辨率的分割
nnU-Net和原始U-Net的区别不大,nnU-net更多的是在考虑如果为这些模型设置一个自动化的训练过程。
U-Net可见 机器学习笔记: Upsampling, U-Net, Pyramid Scene Parsing Net_UQI-LIUWJ的博客-CSDN博客

和U-Net相似的是,nnU-Net也在encoder和decoder每“层”中使用两层卷积层。
和U-Net不同的是,nnU-Net的激活函数使用的是leaky ReLU (负数部分的斜率是0.01),同时将batch normalization替换成instance normalization 【也就是每次只对一个样本某一特征各个维度进行归一化(batch normalization是对一个batch内某一特征的各个维度进行归一化)】机器学习笔记:神经网络层的各种normalization_UQI-LIUWJ的博客-CSDN博客_神经网络normalization
2.1.1 2D UNet
直观地说,在 3D 医学图像分割的上下文中使用 2D U-Net 似乎不是最理想的,因为无法聚合和考虑沿 z 轴的有价值信息。 然而,有证据表明如果数据集是各向异性的,传统的 3D 分割方法的性能会下降
2.1.2 3D UNet
3D U-Net 似乎是 3D 图像数据的合适选择方法。 理想情况下可以在整个患者的图像上训练这样的 3D U-Net。
然而实际上,受到可用 GPU 内存量的限制,这使得只能在图像块(patch)上训练此架构。 虽然这对于由较小图像组成的数据集而言不是问题,但对于大图像来说,基于patch的训练可能会妨碍训练。 这是由于架构的视野有限,因此无法收集足够的上下文信息。
2.1.3 U-Net 层级架构
为了解决 3D U-Net 在大图像数据集上的缺点,作者提出了 U-Net 层级架构:
- 首先在下采样图像上训练 3D U-Net(阶段 1)。
- 然后将此 U-Net 的分割结果上采样到原始体素间距,并作为附加(one-hot编码)输入通道传递到第二个 3D U-Net,该 U-Net 在全分辨率的patch上进行训练(阶段 2)。

2.2 网络拓扑结构的动态调整
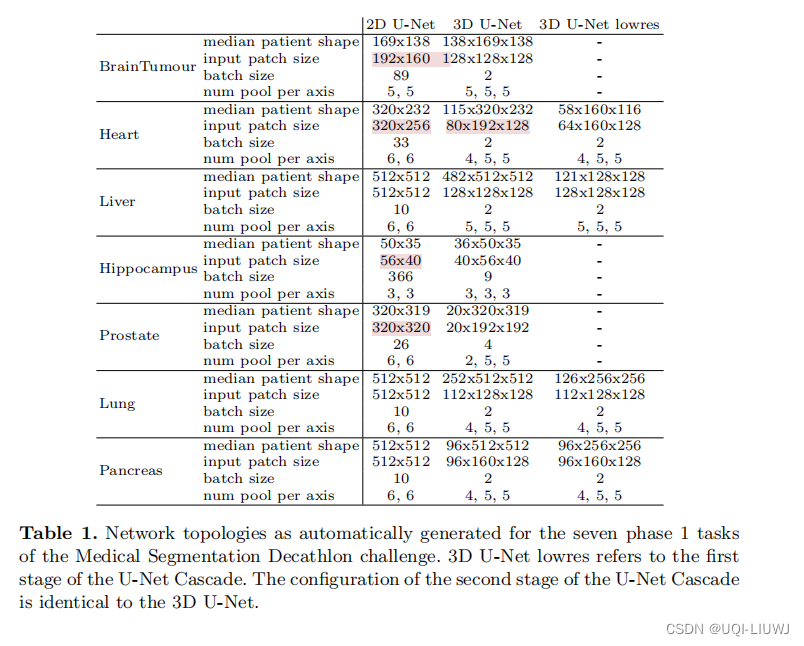
由于图像大小的巨大差异(Liver数据集平均 482 × 512 × 512 V.S Hippocampus数据集 36 × 50 × 35),patch大小和每个轴的池化操作数、卷积层数必须自适应每个数据集,以允许充分聚合空间信息。
除了适应图像几何形状之外,还有一些技术限制,比如可用内存。 在这方面的指导原则是动态权衡batch大小与网络容量,详细介绍如下:
- 将patch size 初始化为图像大小的中位数
- ——>迭代地减少patch size,同时调整网络拓扑架构(网络深度、池化操作数量、池化操作位置、feature map 的尺寸、卷积核尺寸)
- ——>直到网络可以在给定GPU的限制下,且batch 至少是2的情况下,可以被train
2.3 预处理
nnUnet的预处理是在没有任何用户干预的情况下执行的。
2.3.1 Cropping
所有数据都被裁剪到非零值区域。 这对大多数数据集(如肝脏 CT)没有影响,但会减少颅骨剥离脑 MRI 的大小(因此减少计算负担)。
2.3.2 resampling
CNN 本身并不理解体素间距。 在医学图像中,不同的扫描仪或不同的采集协议通常会产生具有不同体素间距的数据集。 为了使我们的网络能够正确学习空间语义,所有患者都被重新采样到各自数据集的中值体素间距,其中三阶样条插值用于图像数据,最近邻居插值用于相应的分割掩码。
2.3.3 层级U-Net的必要性
U-Net Cascade 的必要性由以下启发式确定:如果重采样数据的中值形状的体素是 3D U-Net 可作为输入patch处理的体素的 4 倍以上(batch大小已经为 2时) ,它符合 U-Net Cascade 的条件——>该数据集会被重新采样到较低的分辨率。 这是通过将体素间距增加 2 倍来完成的(降低分辨率),直到满足上述标准。
——>如果数据集是各向异性的,则首先对较高分辨率的轴进行下采样,直到它们与低分辨率轴匹配,然后才同时对所有轴进行下采样。
2.3.4 正则化
对于CT扫描图,训练集中所有segmentation mask中的value会被收集,整体的数据集会先被clip到[0.5,99.5]百分位,然后通过收集的数据的mean和标准差进行正则化。
对于MRI以及其他的图像,直接进行正则化即可
2.4 训练过程
所有模型都是从头开始训练的,并在训练集上使用五折交叉验证进行评估。
loss function是Dice 和交叉熵的结合
对于目前大多数的图像分割任务来说,使用最多评价指标就是Dice相似系数 (Dice Similarity Coefficient, D S C ) 。Dice系数是计算两个样本之间的相似度,即考察两个样本之间重叠的范围。Dice系数值范围通常在0-1之间。若为1,则证明两个样本完全重合;若为0,则证明两个样本没有相同的像素。
其中TP(True Positive)为判定为正样本,事实上也是正样本;
TN(True Negative) 为判定为负样本,事实上也是负样本;
FP(False Positive)为判定为正样本,事实上 为负样本;
FN(False Negative)为判定为负样本,事实上为正样本。

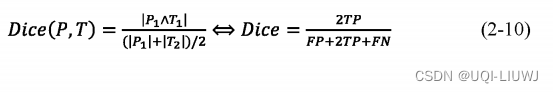
优化器选择Adam,学习率是3*10^-4
2.4.1 数据增强
从有限的训练数据训练大型神经网络时,必须特别注意防止过度拟合。 我们通过利用多种数据增强技术来解决这个问题。 在训练期间动态应用了以下增强技术:随机旋转、随机缩放、随机弹性变形、伽马校正增强和镜像。
我们分别为 2D 和 3D U-Net 定义数据增强参数集。 这些参数不会在数据集之间修改。
如果 3D U-Net 的输入块大小的最大边长是最短边长的两倍多,则应用三维数据增强可能不是最佳的。 对于适用此标准的数据集,我们使用我们的 2D 数据增强,并将其应用于每个样本的切片。
U-Net Cascade 的第二阶段接收上一步的segmentation作为附加输入通道。 为了防止强协同适应,我们应用随机形态算子(腐蚀、扩张、打开、关闭)并随机删除这些segmentation的连接分量。
2.5 Inference
由于我们训练的基于patch的性质,所有推理也是基于patch的。 由于网络准确度随着靠近patch的边界而降低,所以在聚合patch之间的预测时,我们将靠近中心的体素的权重高于靠近边界的体素。 选择补丁以按补丁大小/ 2 重叠,我们通过沿所有有效轴镜像所有patch进一步利用测试时间数据增强。
将平铺预测和测试时间数据增强相结合会产生分割,其中每个体素的决策是通过聚合多达 64 个预测(在患者中心使用 3D U-Net)获得的。
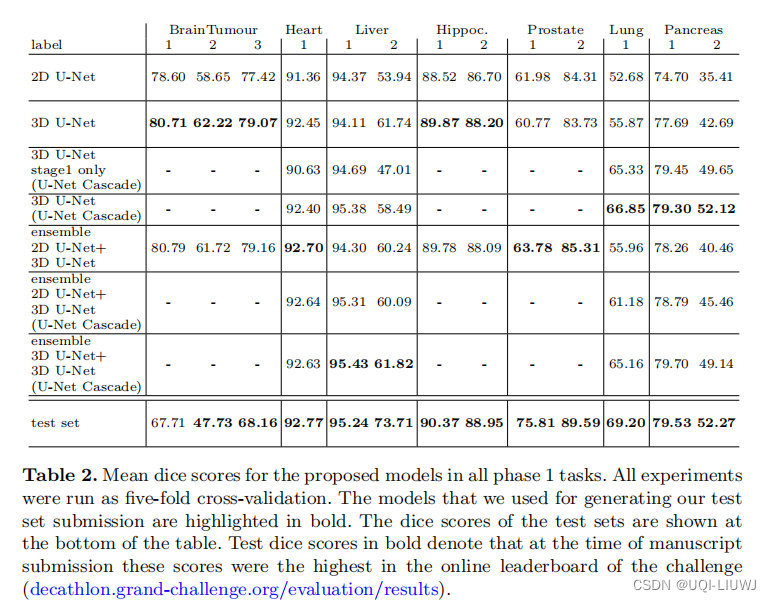
3 实验部分
4 结论
在本文中,我们提出了用于医疗领域的 nnU-Net 分割框架,该框架直接围绕原始 U-Net 架构 构建,并动态调整自身以适应任何给定数据集的细节。 基于我们的假设,即非架构修改可能比最近提出的一些架构修改更强大,该框架的本质是自适应预处理、训练方案和推理的彻底设计。 适应新分割任务所需的所有设计选择均以全自动方式完成,无需手动交互。

