
热门标签
热门文章
- 1【Python】 pycharm+conda配置虚拟环境_pycharm使用conda虚拟环境
- 2人类最高质量客户端项目chrome源码下载与编译
- 3sublime使用
- 4git 安装包 最新 下载 快速 国内 镜像 地址_git镜像下载
- 5IDEA最新使用教程和技巧保姆级总结(强迫症福音+新手必看)_idea教程
- 6算法——递归与搜索算法_递归搜索
- 7人工智能气象一:深度学习预测浅水方程模式_ai预报前数据的预处理方法
- 8A100 解析:为何它成为 AI 大模型时代的首选?
- 9八股文之Redis篇_八股文redis 数据结构
- 10chatgpt赋能python:Python导入和提取CSV列_python cvs 拷贝列
当前位置: article > 正文
【scau大数据技术与原理1】综合性实验Spark集群的安装和使用——先导篇_spark大数据综合技术应用综合实践
作者:从前慢现在也慢 | 2024-07-12 22:42:44
赞
踩
spark大数据综合技术应用综合实践
Scala简介
- Scala是一门现代的多范式编程语言,运行于Java平台(JVM),并兼容现有的Java程序
- Scala是Spark的原生编程语言,但Spark还支持Java、Python、R作为编程语言
- Scala的优势是提供了REPL(Read-Eval-Print Loop,交互式解释器),提高程序开发效率
- Scala的特性: Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统, Scala语法简洁,能提供优雅的API, Scala兼容Java,运行速度快,能融合到Hadoop生态圈中
相对于Hadoop的优势
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
- Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
Spark生态系统 Ecosystem
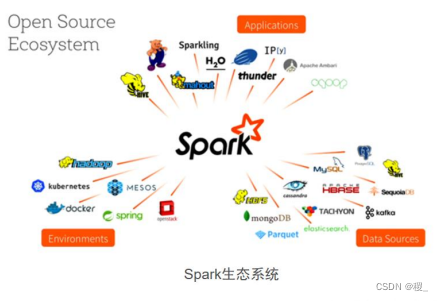
spark同时支持批处理、交互式查询和流数据处理
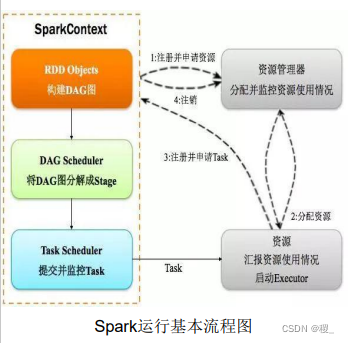
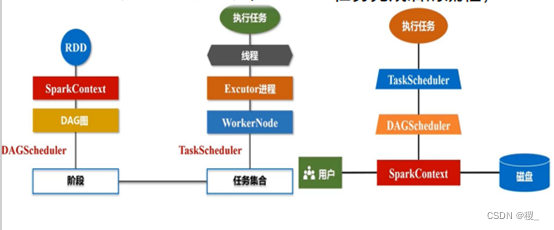
Spark运行架构:
- 集群资源管理器(Cluster Manager)
- 运行作业任务的工作节点WorkerNode
- 每个应用的任务控制节点Driver
- 工作节点上负责具体任务的执行进程(Executor)
一个Application由一个Driver和若干Job构成,一个Job由多个Stage构成,一个Stage由多个没有Shuffle关系的Task组成
Drivers--->Jobs---Stages--->Tasks
应用被分解成多个Job,每个Job包含多个Stage,每个Stage又完成多个任务。
当执行一个Application时,Driver会向集群管理器申请资源,并在节点上启动Executor,同时向Executor发送应用程序代码和文件,然后在Executor上执行Task。运行结束后,执行结果会返回给Driver,或者写到HDFS或者其他数据库中。
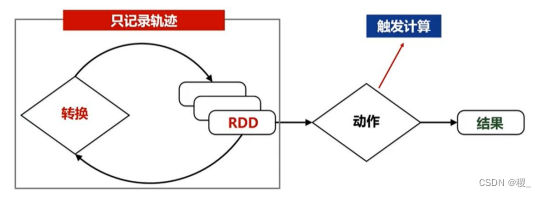
RDD运行惰性调用机制
RDD执行过程实例
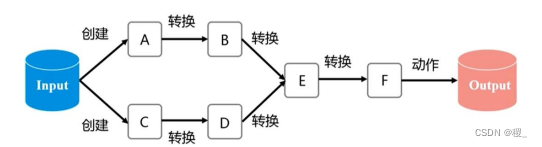
RDD的处理过程被称为一个Lineage(血缘关系),即DAG拓扑排序的结果;优点:惰性调用、管道化、避免同步等待、不需要保存中间结果、每次操作变得简单。
RDD完整运行过程
安装Spark之前需要安装Java环境和Hadoop环境。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/816359
推荐阅读
相关标签

