
热门标签
热门文章
- 1rabbitmq的延迟队列和死信队列的实现(二种方式,超详细)_mq 延时消息 死信队列
- 2Go语言开发利器:几种主流IDE的优势与应用_go语言开发工具
- 3【LangChain】第3篇:Agent代理简介及实践_agent代理程序
- 4如何和hr谈薪资_hr问师兄的薪资
- 5嵌入式单片机之STM32F103C8T6最小系统板电路设计参考_stm32f103c8t6怎么用电池供电
- 6【Lora模型训练过程报错】Error no kernel image is available for execution on the device at line
- 7android测试类Test
- 8经典的Embedding方法Word2vec_word2vec.word2vec
- 9【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)_pipeline语音识别
- 10数字人整合包集合,第六个最好用,附免费下载链接_echomimic musetalk sadtalker 对比
当前位置: article > 正文
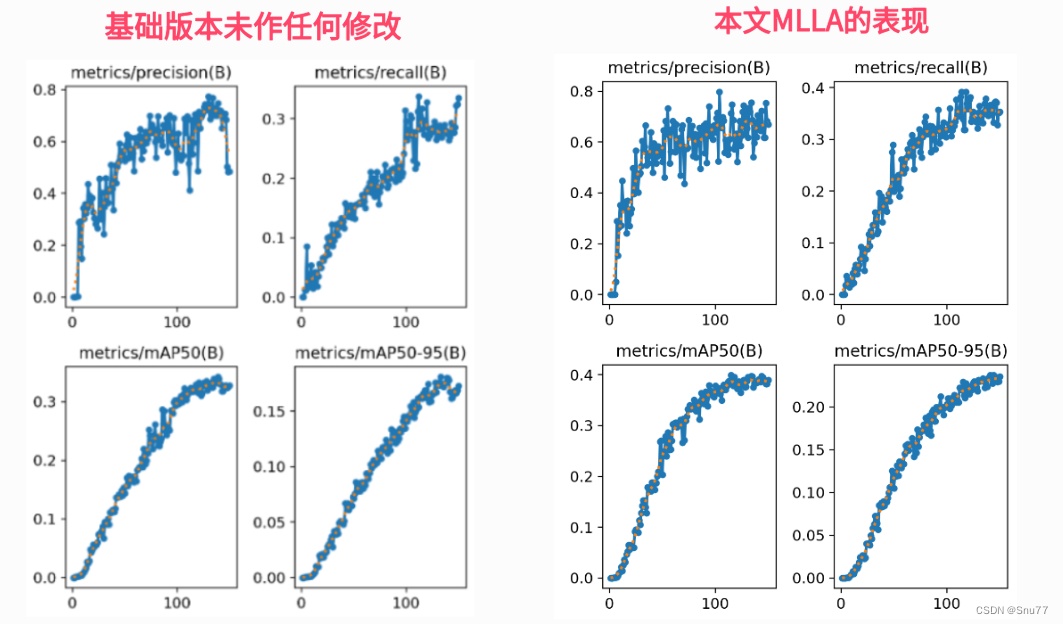
YOLOv8改进 | 添加注意力篇 | 结合Mamba注意力机制MLLA助力YOLOv8有效涨点(全网独家首发)
作者:从前慢现在也慢 | 2024-08-03 01:14:19
赞
踩
mlla
一、本文介绍
本文给大家带来的改进机制是结合号称超越Transformer架构的Mamba架构的最新注意力机制MLLA,本文将其和我们YOLOv8进行结合,MLLA(Mamba-Like Linear Attention)的原理是通过将Mamba模型的一些核心设计融入线性注意力机制,从而提升模型的性能。具体来说,MLLA主要整合了Mamba中的“忘记门”(forget gate)和模块设计(block design)这两个关键因素,同时MLLA通过使用位置编码(RoPE)来替代忘记门,从而在保持并行计算和快速推理速度的同时,提供必要的位置信息。这使得MLLA在处理非自回归的视觉任务时更加有效 ,本文内容为我独家整理全网首发。
目录
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/920815
推荐阅读
相关标签

