
- 1Vue3 前端配置代理解决跨域_vue3 跨域
- 2java 正则验证 数字,字母,下划线还有汉字的正则表达式和email_6到18位字母数字下划线两者组合 java
- 3PHP获得微信用户的OpenID,然后再通过OpenID和access_token查询用户信息_怎么查看openai_access_token
- 4【CSDN表情包大全】
- 5Mac中host设置方法
- 6Codeforces Round #737 (Div. 2) C.Moamen and XOR_codeforces round #737 (div. 2) c - moamen and xor
- 7【VScode】手把手教你如何搭建C/C++开发环境_vscode创建c++项目
- 8Ubuntu20.04 :Minimal BASH-like line editing 用Live CD/USB修复ubuntu_minial bash-like line editing
- 9如何在Ubuntu安装MySQL?_ubuntu下载mysql
- 10【Unity3D】sRGB伽马(gamma)空间和sRGB Frame Buffer线性空间的简单介绍_unity图片中的srgb是什么
七千字详解阿里云新一代云计算体系架构 CIPU
赞
踩

文 | 阿里云 杨航

写在前面
近日,阿里云智能总裁张建锋在2022阿里云峰会发布云基础设施处理器CIPU(Cloud Infrastructure Processing Unit),将其定义为替代CPU成为云计算的管控和加速中心。在这个全新体系架构下,CIPU向下对数据中心的计算、存储、网络资源快速云化并进行硬件加速,向上接入飞天云操作系统,将全球数百万台服务器构建为一台超级计算机。
众所周知,传统IT时代,微软Windows+Intel联盟取代了IBM PC霸主地位;移动计算时代,谷歌Android/苹果iOS+ARM共同主导了移动终端的技术架构;那么云计算时代,阿里云飞天操作系统+CIPU组合能发挥什么样的价值?
本文希望通过对CIPU的深入技术解读,回答读者普遍关心的关键问题:CIPU到底是什么?CIPU主要解决哪些问题?CIPU从何而来,未来又将往何处去?

云计算现状
在距离2006年云计算鼻祖AWS先后发布S3和EC2有16年之余,距离2010年BAT针对云计算是否“新瓶装旧酒”之争已有12年历史之时,同时Gartner 2021全球IaaS 收入已达900亿美元的当下,市面上依然存在着一些伪云计算概念,比如,转售IDC硬件、转售CDN等。
云计算行业再次站在了分水岭上,有必要看清楚云的未来到底是什么?什么才是我们需要的云计算?
作为和水、电一样的公共资源和社会基础设施,云的核心特征是“弹性”和“多租 ”。
何谓弹性?
弹性,从广义上讲,是让IT能力轻松跟上用户的业务发展;从狭义上讲,则带给用户无与伦比的灵活性。
先来看广义弹性的价值,简单讲就是充裕的供给能力,“无限索取”。IT计算力已经成为很多业务的支撑性能力。当业务迅猛发展时,如果计算力跟不上,那么业务必然会受到严重的制约。
但是计算力的建设并不是一蹴而就的,从地、电、水到机房建造,从数据中心网络铺设到Internet接入,从服务器选型、定制、采购到部署、上线和运维,从单机房、多机房到跨地域甚至跨大洲,然后是安全、稳定性、容灾、备份……最后是最难的,优秀人才的招聘、培训和保有,这些无一不是耗时、耗力、耗财的事项,谈何容易。而弹性计算的出现,则让计算力的获得变得简单而从容。
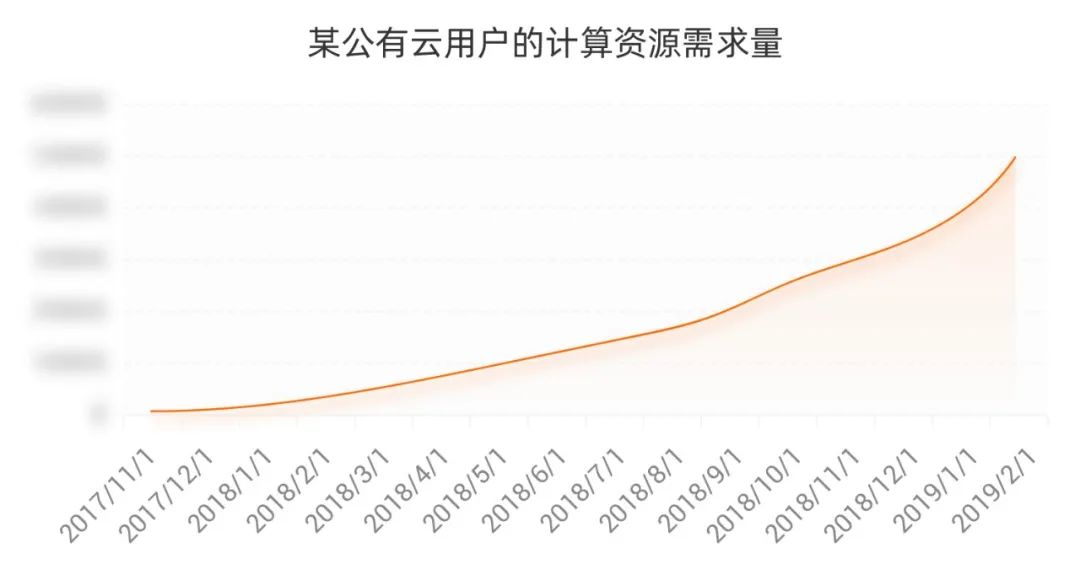
下图展示了一个公有云用户随着业务的极速扩张所购买的计算力的增长曲线,短短15个月,计算力需求从零爆发式增长到了数百万核。弹性计算充裕的计算力供给,让用户业务的发展如虎添翼。
何谓多租?
逻辑清晰的读者可能已经隐约感觉到“弹性”和“多租”并非严格的正交和并列关系,那么为什么笔者特意把“多租”上升到“弹性”并列的高度来进行讨论?
严格来说,多租是实现极致弹性和极致社会IT资源效率的必要条件之一。不可否认,私有云确实在一定程度上解决了企业IT资源灵活高效使用的问题,但是私有云和公有云在“多租”这个核心业务特性差异,导致二者之间的天壤之别。
准确完成对云计算的“弹性”和“多租”业务特性的定义,则可以进一步讨论技术实现层面,如何实现“弹性”和“多租 ”功能,如何在极致安全、极致稳定、极致性能、极致成本等四个维度讨论云计算技术实现层面的演进。

IaaS的阿克琉斯之踵
众所周知,IaaS是计算、存储、网络等三大件的IT资源公共服务化;PaaS主要指数据库、大数据、AI等数据管理平台服务化以及K8s云原生和中间件;SaaS则是以微软Office 365、Salesforce等为代表的软件服务化。传统意义上,云计算主要是指IaaS云服务,PaaS和SaaS则是IaaS云平台之上的云原生产品和服务;同时由于本文主题CIPU主要位于IaaS层,因此PaaS和SaaS对CIPU的需求不会在本文重点展开。
为了实现IaaS计算、存储、网络等IT资源灵活按需供给,其核心特点是资源池化、服务多租、弹性供给以及管理运维自动化等。其背后的核心技术则是虚拟化技术。
我们简要回顾一下虚拟化技术和公有云服务的历史:
2003年,XenSource在SOSP发表《Xen and the Art of Virtualization》,拉开x86平台虚拟化技术的大幕。
2006年,AWS发布EC2和S3,拉开了公有云服务的大幕。EC2的核心正是基于Xen虚拟化技术。
可以看出,虚拟化技术和IaaS云计算服务相互成就:IaaS云服务“发现和发掘”了虚拟化技术的业务价值,使得虚拟化技术成为了IaaS云服务的基石;与此同时,虚拟化技术红利让IaaS云服务成为了可能。
从2003年Xen虚拟化技术发轫,到2005年英特尔开始在至强处理器引入虚拟化支持,加入新指令集并改变x86体系架构,使得虚拟化技术大规模部署成为可能,然后2007年KVM虚拟化技术诞生,持续近20年的IaaS虚拟化技术演进,无不是围绕上述更安全、更稳定、更高性能、更低成本等四大业务目标进行演进。
简单回顾历史,我们就可以清晰看到IaaS的阿克琉斯之踵 —— 虚拟化技术之痛。
其一,成本。Xen时代,Xen Hypervisor DOM0消耗XEON一半的CPU资源,也就是只有一半的CPU资源可以对外售卖,可以看到虚拟化云计算税极其沉重。
其二,性能。Xen时代,内核网络虚拟化时延达到150us之巨,网络时延抖动极大,网络转发pps成为企业核心业务的关键瓶颈,Xen虚拟化架构在存储和网络IO虚拟化方面有不可克服的性能瓶颈。
其三,安全。QEMU大量设备仿真代码,对于IaaS云计算毫无意义,而这些冗余代码不仅仅会导致额外资源开销,更进一步导致安全攻击敞口(attack surface)无法根本收敛。
众所周知,公有云成立的基础之一是多租环境下的数据安全。而持续提升硬件的可信能力,数据在计算、存储、网络等子系统流动过程中的安全加密能力,在Xen/KVM虚拟化下技术挑战极大。
其四,稳定性。云计算稳定性提升,依赖两大核心技术:底层芯片白盒,以此输出更多RAS数据;以及基于这些稳定性数据的大数据运维。虚拟化系统要进一步提升稳定性,则需要进一步深入计算、网络和存储芯片的实现细节,以此获得更多影响系统稳定性数据。
其五,弹性裸金属支持。诸如Kata、Firecracker等安全容器,多卡GPU服务器在PCIe switch P2P虚拟化开销,头部大用户追求降低极致计算和内存虚拟化的开销,以及VMware/OpenStack支持等需求方面,需要弹性裸金属来支撑这类需求,而基于Xen/KVM虚拟化架构无法实现弹性裸金属。
其六,IO和算力之间的鸿沟持续扩大。我们以Intel XEON 2 Socket服务器为例,分析存储和网络IO以及XEON CPU PCIe带宽扩展能力,与CPU算力的发展做一个简单对比分析:
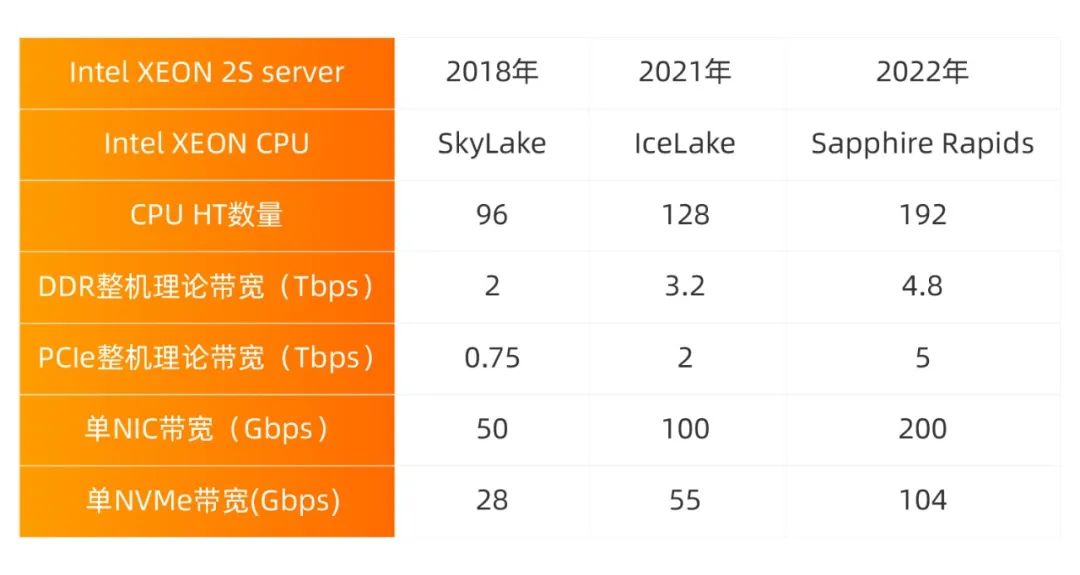
进一步以2018年SkyLake 2S服务器的各个指标(CPU HT数量、DDR整机理论带宽等)为基准,横向对比各个技术指标的发展趋势。以CPU HT数量为例,96HT SkyLake设定为基线1,IceLake 128HT/96HT = 1.3,Sapphire Rapids 192HT/96HT = 2.0,我们可以得到如下Intel 2S XEON服务器 CPU vs. MEM vs. PCIe/存储/网络IO发展趋势:
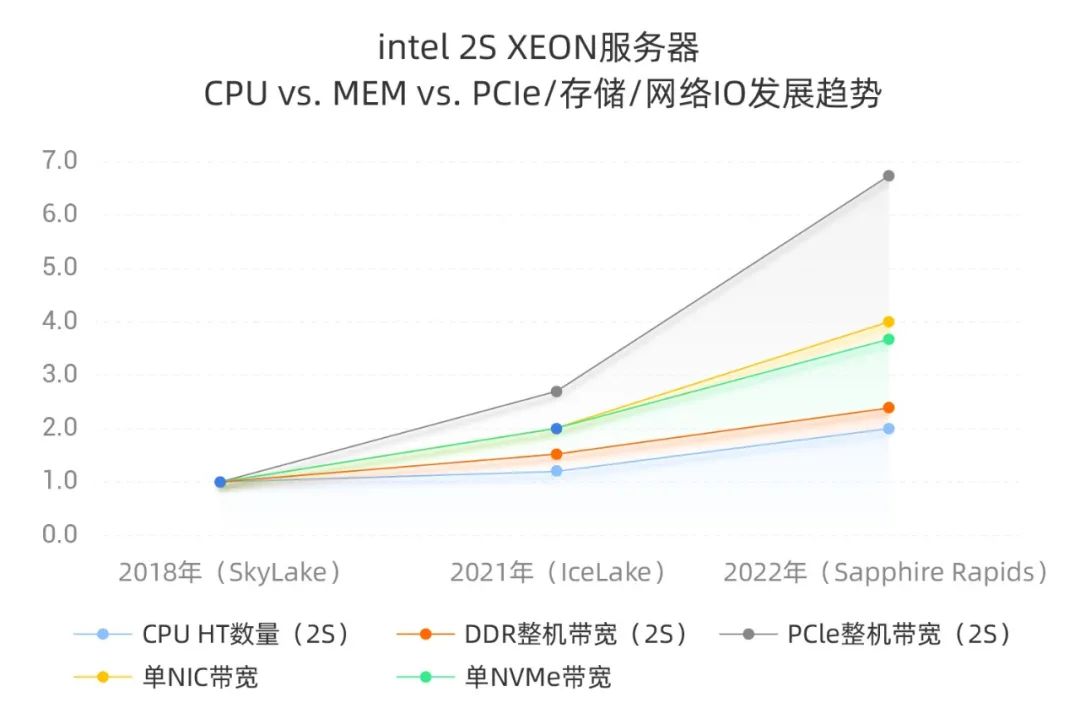
从上图2018年到2022年四年数据对比,我们可以得到如下结论:
1、Intel CPU提升了2倍(未考虑IPC提升因素),DDR带宽提升了2.4倍,因此CPU和DDR带宽是匹配的;
2、单网卡(包含网卡连接的以太交换网络)带宽提升了4倍,单NVMe带宽提升了3.7倍,整机PCIe带宽提升6.7倍,可以看出网络/存储/PCIe等IO能力和Intel XEON CPU的算力之间gap在持续拉大;
3、上图未分析的时延维度数据,由于Intel CPU频率基本保持不变,IPC未有显著提升,因此CPU处理数据的时延会有小幅改进,PCIe和网卡/网络的时延也仅有小幅改进,而存储NVMe和AEP等新一代存储介质,相对于HDD等老一代介质,在时延方面出现了数量级的下降;
4、上述计算、网络、存储等基础设施层面发展的不同步,将对数据库和大数据等PaaS层的系统架构产生关键影响,但这非本文讨论重点。
作为有虚拟化技术背景的人士,看到上述分析,内心一定是沉重的。
因为在Intel VT等计算和内存硬件虚拟化技术普遍部署后,计算和内存虚拟化的开销(包含隔离性、抖动等)已经得到了相当程度的解决。而上述PCIe/NIC/NVMe/AEP等 IO技术突飞猛进发展的同时,如果继续沿用PV半虚拟化技术,在内存拷贝、VM Exit、时延等方面的技术挑战将愈发凸显。

CIPU从何处来?
通过上面的内容,我们基本阐述清楚了IaaS云计算在技术层面面临的问题和挑战,本章节我们将对CIPU技术发展史做一个综述,目的是回答一个问题:CIPU从何而来?毕竟“不了解历史,则无法看清未来”。
细心的读者如果对上文的“六大虚拟化技术之痛”有进一步思考和分析,应该可以看出6个痛点有一个方面的共性:都在或多或少地讨论IO虚拟化子系统的成本、安全和性能。因此符合逻辑的技术解决思路应该是从IO虚拟化子系统入手。而回望过去20年的技术发展史,也确实印证了上述推导逻辑。
本文仅选取两个关键技术,来阐述CIPU从何处来:
其一,IO硬件虚拟化–Intel VT-d
IO虚拟化子系统存在巨大的需求和技术鸿沟,Intel自然会重点解决。DMA直接内存存取,以及IRQ中断请求在虚拟化条件下的改进,以及对应PCIe标准化组织的跟进,肯定会成为必然。
从IOMMU地址翻译到中断remapping和posted interrupt,从PCIe SR-IOV/MR-IOV到Scalable IOV,其具体技术实现细节不在本文讨论之列,网上相关资料可谓汗牛充栋,感兴趣的可自行搜索研读。
而笔者在此罗列Intel VT-d IO硬件虚拟化技术的唯一目的是想说:CPU IO硬件虚拟化技术的成熟,是CIPU技术发展的前置关键技术依赖。
其二,网络处理器(NPU)和智能网卡
CIPU另一个设计思路来自通信领域(特别是数通技术)。数通出身的人士,肯定对以太网交换芯片、路由芯片、fabric芯片等特别熟悉,而这其中网络处理器(Network Processor Unit,NPU。特别指出本文网络NPU,非AI Neural Processing Unit)是数通领域的一个关键支撑技术。
2012年前后,由于受运营商诸多美好愿望驱动(是否能够大规模落地按下不表,但是人总是要有希望,否则“和咸鱼有何差别”),无论是在通信领域的无线核心网还是宽带接入服务器(BRAS)中(如下图),NFV(网络功能虚拟化)都成为重点研发方向。
一言以蔽之,NFV就是通过标准x86服务器,标准以太交换网、标准IT存储等IT标准化和虚拟化的基础设施,来实现通信领域的网元功能,以此摆脱传统通信烟囱式和垂直化的非标紧耦合软硬件系统,从而达到运营商降本增效和提升业务敏捷度。

(图片来源:ETSI NFV Problem Statement and Solution Vision)
而NFV运行在IT标准化和虚拟化的基础设施之上,肯定会遇到相当多技术难题。而这些技术难题之一就是:NFV作为网络业务,相对于IT领域典型的在线交易/离线大数据等业务,对于网络虚拟化技术要求有很大差别。NFV天然对高带宽吞吐(默认线速带宽处理)、高pps 处理能力以及时延和抖动等都有更为严格的要求。
此时,传统NPU进入了SDN/NFV的技术需求视野,不过这一次是把NPU放置到网卡之上而已,而配置NPU的网卡则被称为智能网卡(Smart NIC)。
可以看到,通信NFV等业务希望部署到标准化和虚拟化的IT通用基础设施之上,然后遇到网络虚拟化性能瓶颈。同时期,IT domain公有云虚拟化技术遭遇了IO虚拟化技术瓶颈。它们在2012年前后,不期而遇。至此,网络NPU、智能网卡等传统通信技术开始进入IT domain的视野。
时至今日,在解决云计算IO虚拟化这个问题上,可以看到智能网卡、DPU、IPU等仍然被大家混用。原因之一,确实它们有深刻的血脉联系;同时如此之多和如此混乱的名称,也源自于通信领域跨界到IT领域的工程师以及美国多家芯片大厂对云业务需求和场景的不熟悉。

CIPU定位
在相关前置技术储备的基础之上,这里我们给出CIPU的定义及定位。
CIPU(Cloud Infrastructure Processing Unit,云基础设施处理器),顾名思义,就是把IDC计算、存储、网络基础设施云化并且硬件加速的专用业务处理器。
计算器件、存储资源、网络资源一旦接入CIPU, 就云化为虚拟算力,被云平台调度编排,给用户提供高质量弹性云计算算力集群。
CIPU架构由以下部分组成:
1、IO硬件设备虚拟化
通过VT-d的前置支撑技术,实现高性能的IO硬件设备虚拟化。同时考虑公有云OS生态兼容,设备模型应该尽最大努力做到兼容。因此实现基于virtio-net、virtio-blk、NVMe等业界标准IO设备模型,成为了必须。
同时注意到IO设备的高性能,那么在PCIe协议层面的优化则至关重要。如何减少PCIe TLP通信量、降低guest OS中断数量(同时平衡时延需求),实现灵活的硬件队列资源池化,新IO业务的可编程和可配置的灵活性等方面,是决定IO硬件设备虚拟化实现优劣的关键。
2、VPC overlay网络硬件加速
上文已对网络虚拟化的业务痛点做了简要分析,在这里我们进一步对业务需求进行展开:
需求1:带宽线速处理能力
需求2:极致E2E低时延和低时延抖动
需求3:不丢包条件下的高pps转发能力
而实现层面,Xen时代内核网络虚拟化,到KVM架构下基于DPDK vSwitch用户态网络虚拟化,面临如下问题:
1、网络带宽和CPU处理能力的差距日渐拉大
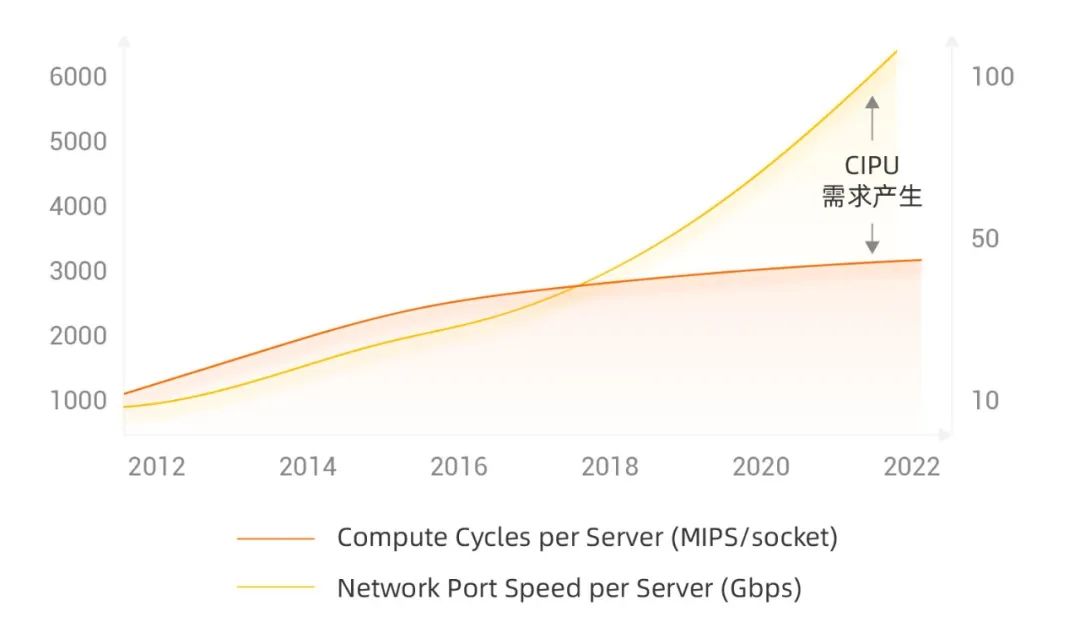
(数据来源:xilinx)
2、DPDK纯软件网络转发性能优化瓶颈凸显
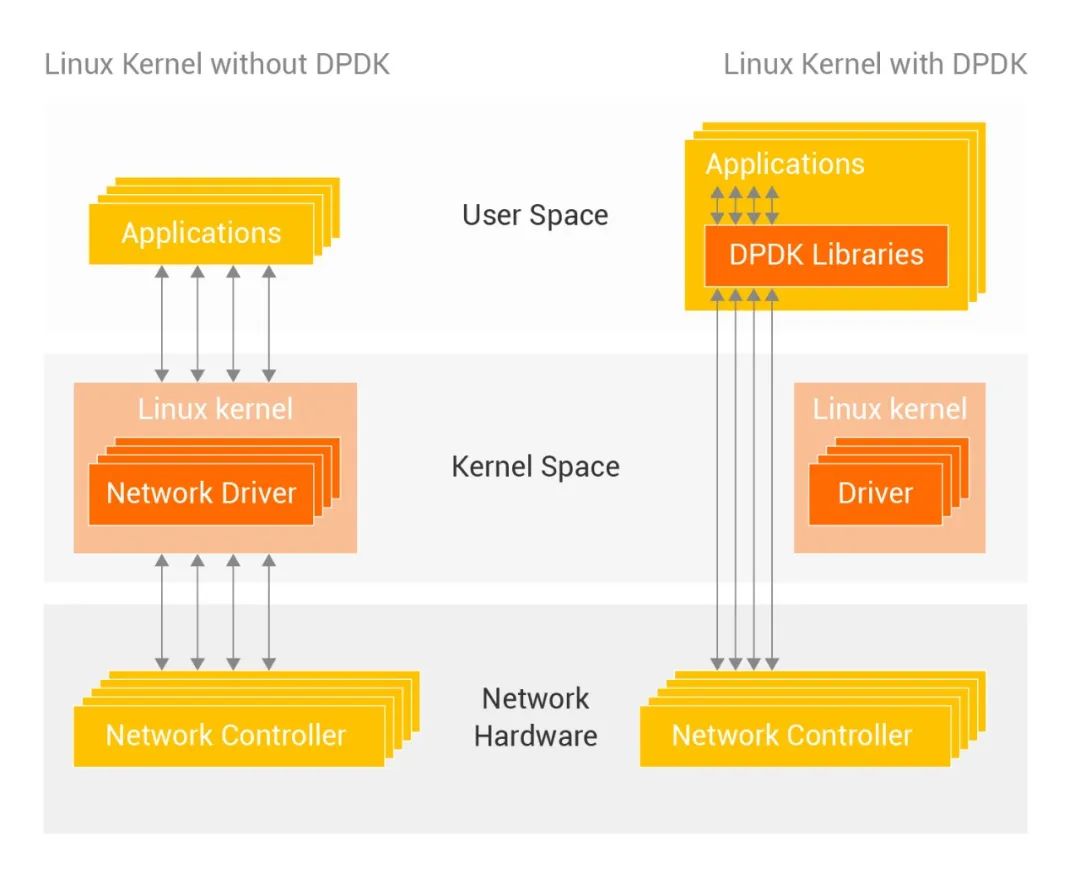
对上述两个问题做进一步分析,可以看出如下三个根本困难:
100Gbps+大带宽数据移动,导致“冯诺依曼内存墙”问题突出;
CPU标量处理网络虚拟化业务,并行性瓶颈明显;
基于软件的数据路径处理,时延抖动难以克服。
此时,基于硬件转发加速的业务需求诞生,技术实现层面可以分为:
类似于MNLX ASAP、Intel FXP、Broadcom trueflow等基于可配置的ASIC转发技术
基于many core的NPU技术
FPGA可重配置逻辑实现转发技术
Intel FXP等基于可配置的ASIC转发技术,具备最高的性瓦比和最低的转发时延,但是业务灵活性就比较捉襟见肘;基于many core的NPU技术,具备一定的转发业务灵活性,但是PPA(power-performance-area)效率和转发时延无法和可配置ASIC竞争。FPGA可重配置逻辑实现转发技术,time to market能力有很大优势,但是对于400Gbps/800Gbps转发业务,挑战很大。
此时技术实现层面的tradeoff原则:商用IPU/DPU芯片由于需要覆盖更多目标客户,会趋向于牺牲一定PPA效率和转发时延,来获得一定的通用性;而云厂商CIPU会基于自身转发业务进行更多的深度垂直定制,从而获得更极致PPA效率和更极致转发时延。
3、EBS分布式存储接入硬件加速
公有云存储要实现9个9的数据持久性,且计算和存储要满足弹性业务需求,必然导致存算分离,EBS(阿里云块存储)必须在计算机头高性能、低时延地接入机尾的分布式存储集群。
具体需求层面:
EBS作为实时存储,必须实现E2E极致低时延和极致P9999时延抖动;
实现线速存储IO转发,诸如200Gbps网络环境下实现6M IOPS;
新一代NVMe硬件IO虚拟化,满足共享盘业务需求的同时,解决PV NVMe半虚拟化IO性能瓶颈。
计算initiator和分布式存储target之间的存储协议,一般云厂商均会高度垂直优化定制;而CIPU对EBS分布式存储接入硬件加速的核心点就在于此。
4、本地存储虚拟化硬件加速
本地存储,虽然不具备诸如EBS 9个9的数据持久性和可靠性,但是在低成本、高性能、低时延等方面仍然具备优势,对计算cache、大数据等业务场景而言是刚需。
如果做到本地盘虚拟化之后,带宽、IOPS、时延的零衰减,同时兼具一虚多、QoS隔离能力、可运维能力,是本地存储虚拟化硬件加速的核心竞争力。
5、弹性RDMA
RDMA网络在HPC、AI、大数据、数据库、存储等data centric业务中,扮演愈来愈重要的技术角色。可以说,RDMA网络已经成为了data centric业务差异化能力的关键。而公有云上如何实现普惠化的RDMA能力,则是CIPU的关键业务能力。
具体需求:
基于云上overlay网络大规模部署,overlay网络可达的地方,RDMA网络可达;
RDMA verbs生态100%兼容,IaaS零代码修改是业务成败的关键;
超大规模部署,传统ROCE技术基于PFC等data center bridging技术,在网络规模和交换网络运维等诸多方面,已经难以为继。云上弹性RDMA技术需要摆脱PFC和无损网络依赖。
弹性RDMA在实现层面,首先要迈过VPC低时延硬件转发这一关;然后在PFC和无损网络被抛弃的当下,传输协议和拥塞控制算法的深度垂直定制优化就成为了CIPU必然之选。
6、安全硬件加速
用户视角看云计算,“安全是1”——没有安全这个“1”,其他业务能力均是“0”。
因此,持续加强硬件可信技术、VPC 东西向流量全加密、EBS和本地盘虚拟化数据全量加密,基于硬件的enclave技术等,是云厂商持续提升云业务竞争力的关键。
7、云可运维能力支撑
云计算的核心是service(服务化),从而实现用户对IT资源的免运维。而IaaS弹性计算可运维能力的核心是全业务组件的无损热升级能力和虚拟机的无损热迁移能力。
此时涉及到CIPU和云平台底座之间的大量软硬件协同设计。
8、弹性裸金属支持
弹性裸金属在具体定义层面必须实现如下八项关键业务特征:
同时,云计算弹性业务必然要求弹性裸金属、虚拟机、安全容器等计算资源的并池生产和调度。
9、CIPU池化能力
考虑到通用计算和AI计算在网络、存储和算力等方面的需求差异巨大,CIPU必须具备池化能力。通用计算通过CIPU池化技术,显著提升CIPU资源利用率,从而提升成本层面的核心竞争力;同时又能够在一套CIPU技术架构体系下,满足AI等高带宽业务需求。
10、计算虚拟化支撑
计算虚拟化和内存虚拟化的业务特性增强,云厂商均会对CIPU有不少核心需求定义。

CIPU体系架构溯源
经过第五章对CIPU业务的完整定义,我们需要对CIPU的计算体系架构进一步理论溯源。只有计算机工程实践上升到计算机科学视角,才能更为清晰地洞察CIPU的实质,并为下一步的工程实践指明技术方向。这必然是一条从自发到自觉的提升之路。
第三小节我们得出一个结论:“单网卡(包含网卡连接的以太交换网络)带宽提升了4倍,单NVMe带宽提升了3.7倍,整机PCIe带宽提升6.7倍,可以看出网络/存储/PCIe等IO能力和Intel XEON CPU的算力之间gap在持续拉大。”
如果仅根据上述结论进行判断,必然会认为CIPU硬件加速是算力offloading(卸载)。但是事情显然并没有如此简单。
XEON算力可以简化为:ALU等计算处理能力 + 数据层级化cache和内存访问能力。对于普遍的通用计算(标量计算),XEON的超标量计算能力,可谓十分完美。而矢量计算,XEON的AVX512和SPR AMX,定向优化的软件性能会大超预期,同时GPU和AI TPU等异构计算对于矢量计算实现了计算的高度优化。
因此,CIPU要在通用标量计算和AI矢量计算等业务领域,去完成XEON ALU算力和GPU stream processor的offloading显然不现实。
如下图,Intel精确定义workload算力特征,以及最佳匹配算力芯片:
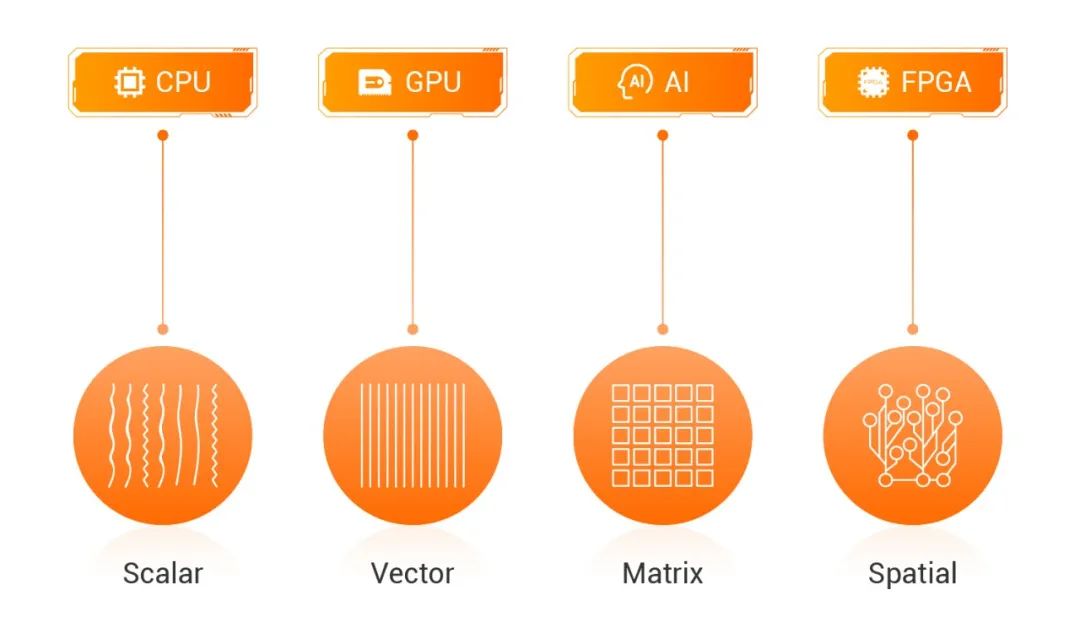 (图片来源:Intel)
(图片来源:Intel)
那么问题来了,CIPU这个socket,最适合的业务workload有什么共同特征?
深入分析第五小节的10个业务,可以看出它们的共同业务特征:在数据流动(移动)过程中,通过深度垂直软硬件协同设计,尽最大可能减少数据移动,以此提升计算效率。因此,CIPU在计算机体系架构视角的主要工作是:优化云计算服务器之间和服务器内部的数据层级化cache、内存和存储的访问效率(如下图所示)。
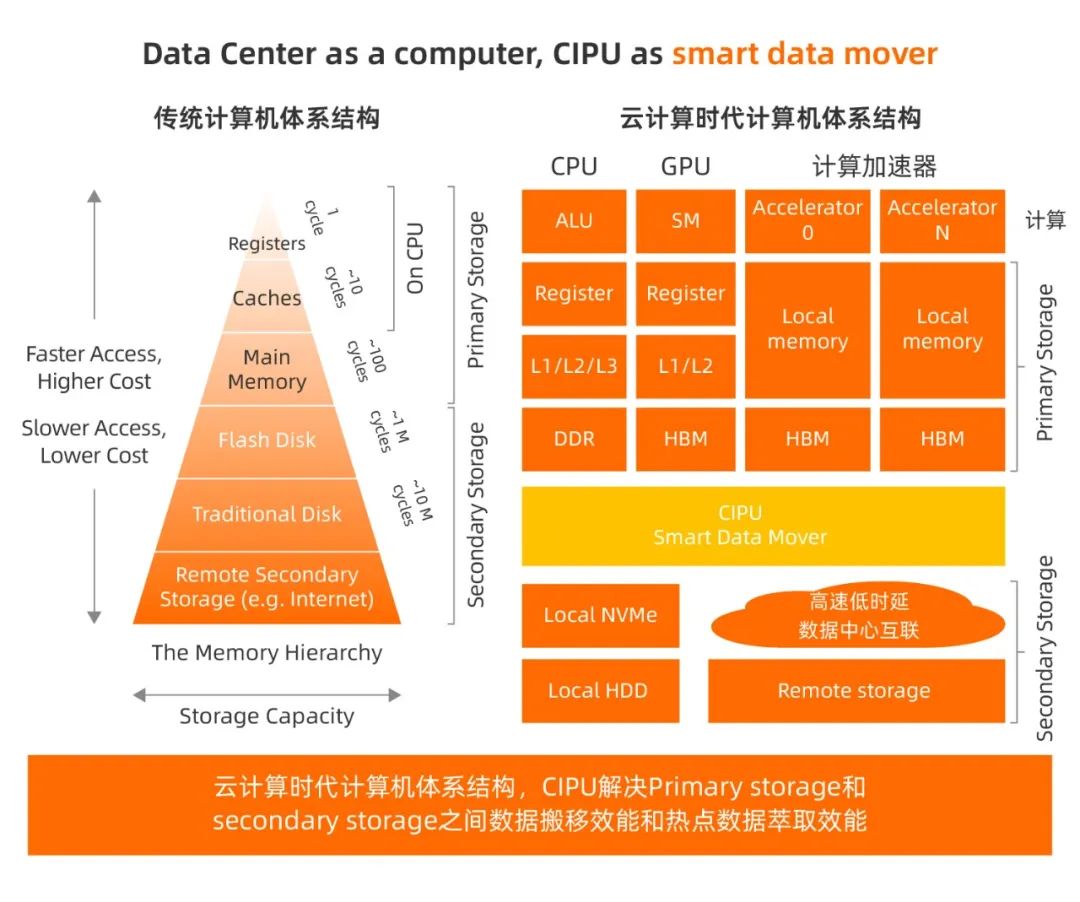
行文至此,谨以Nvidia首席计算机科学家Bill Dally的精辟阐述“Locality is efficiency, Efficiency is power, Power is performance, Performance is king.”作为小结。
那既然CIPU硬件加速不单单是算力卸载,那它是什么?先摆出答案:CIPU是随路异构计算。
Nvidia/Mellanox已经持续倡导in networking computing(近网络计算)多年,CIPU随路异构计算和它是什么关系?存储领域,也存在多年的computational storage、in storage computing以及near data computing(近数据计算)等概念,CIPU随路异构计算和它们又是什么关系?
答案很简单:CIPU 随路异构计算 = 近网络计算 + 近存储计算
进一步对比分析,可以加深对随路异构计算的理解:GPU、Google TPU、Intel QAT等,均可以总结分类为: 旁路异构计算;CIPU位于网络和存储必经之路,因此它的分类为:随路异构计算。

CIPU&IPU&DPU
DPU:Data Processing Unit,从业内信息来看,应该源自Fungible;而这个名字真正发扬光大和名噪一时,则要归功于Nvidia的大力宣传推广。在Nvidia收购Mellanox之后,NVidia CEO 黄仁勋对行业趋势的核心判断:数据中心的未来将是CPU、GPU和DPU三足鼎立,并以此为Nvidia Bluefield DPU造势。
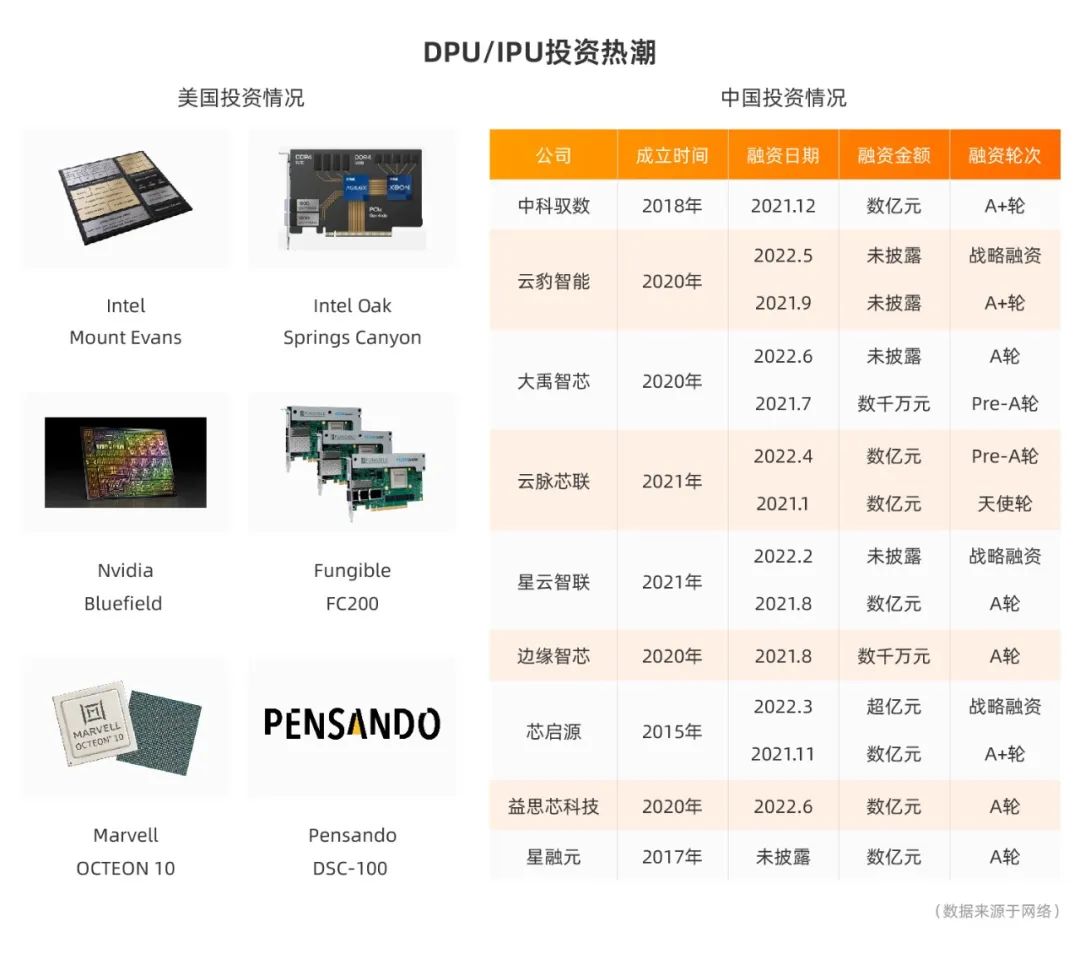
从上图可见,中美两国掀起了一轮DPU/IPU技术投资热潮,但是笔者的判断是:这个socket必须基于云平台软件底座(CloudOS)的业务需求,完成CloudOS + CIPU深度软硬件协同设计。只有云厂商才能发挥出这个socket的最大价值。
在IaaS领域,云厂商追求“北向接口标准化,IaaS零代码修改,兼容OS和应用生态;同时往下做深基础,进一步追求软硬件深度垂直整合”,这背后的技术逻辑是“软件定义,硬件加速”。
阿里云自研了飞天云操作系统及多款数据中心核心部件,技术家底深厚。基于云平台底座软件,进行深度软硬件垂直整合,推出CIPU,是阿里云的必由之路。
还值得一提的是,云平台操作系统在长期和大规模的研发和运营中沉淀出来的业务理解和知识积累,以及这个过程中构建的垂直完备研发技术团队,才是CIPU的题中之义。芯片和软件不过是这些知识固化的一种实现形式。

