
热门标签
热门文章
- 1Pyspark Windows测试环境部署(Hadoop、Spark、IDEA)、Pyspark读取Mysql数据、Spark-submit命令提交Pyspark程序_spark需要windows的mysql吗?
- 2HDL Bits刷题记录,counter1000,1Hz计数器_from a 1000 hz clock, derive a 1 hz signal, called
- 3使用React创建一个web3的前端_入门web3前端
- 4MongoDB启动命令
- 5AI通用大模型 —— Pathways,MoE, etc._moe大模型和其他通用大模型的区别
- 6本地部署Llama3教程,断网也能用啦!_llma3本地部署
- 7浙江大学软件学院人工智能保研面经2021_浙大软院推免面试名单
- 8月薪15~20k的前端面试问什么?(1),2024年最新面试官必问的技术问题之一有哪些
- 9leetcode 53. 最大子数组和
- 10什么是UI设计?_ui设计 csdn
当前位置: article > 正文
spark中的cache和checkpoint_spark cache checkpoint
作者:代码探险家 | 2024-06-19 01:21:57
赞
踩
spark cache checkpoint
cache 缓存级别
DataFrame 的 cache 默认采用 MEMORY_AND_DISK
RDD 的 cache 默认方式采用 MEMORY_ONLY
释放缓存和缓存
缓存:(1)dataFrame.cache (2)sparkSession.catalog.cacheTable(“tableName”)
释放缓存:(1)dataFrame.unpersist (2)sparkSession.catalog.uncacheTable(“tableName”)
缓存和检查点区别
1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依 赖。
2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通 常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存中读取数据即可,否则需要再从头计算一次 RDD。
分区
1)默认采用 Hash 分区
缺点:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有 RDD 的 全部数据。
2)Ranger 分区: 要求 RDD 中的 KEY 类型必须可以排序。
3)自定义分区 根据需求,自定义分区。
SparkSQL 中 RDD、DataFrame、DataSet
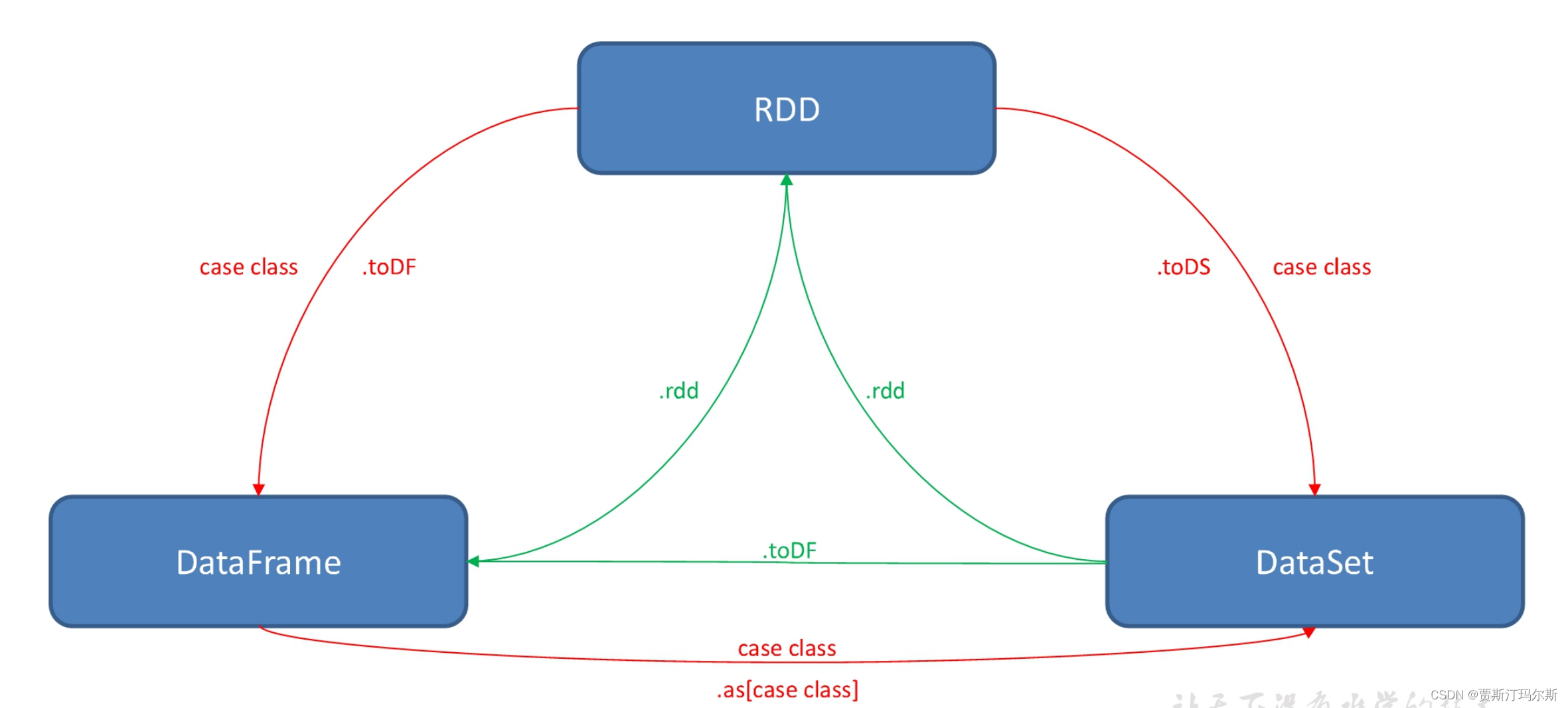
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/734903
推荐阅读
相关标签

