
- 1Java接口,超详细整理,适合新手入门_java 接口
- 2闲话Zynq UltraScale+ MPSoC(连载4)——IO资源_hrio和hpio
- 3uni-app配置开发、测试、生产等多环境,process.env_uniapp process.env
- 4深入理解外观模式(Facade Pattern)及其实际应用
- 5git分支合并冲突解决_ugit 冲突文件
- 6XILINX 7系列FPGA_SelectIO_xilinx selectio
- 7龙蜥操作系统上安装MySQL:步骤详解与常见问题解决_龙蜥安装mysql
- 8Navicat实现 MYSQL数据库备份图文教程_navicat备份数据库
- 9【数据结构】线性表:顺序表
- 10ARIMA参数判定_如何通过acf和pacf判断arima的参数
AI通用大模型 —— Pathways,MoE, etc._moe大模型和其他通用大模型的区别
赞
踩
文章目录
- Pathways
- Mixture of Experts(MoE)
- Neural Computation'1991, Adaptive mixtures of local experts
- ICLR'17, Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- ICLR'21, GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- JMLR'22, Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- 2021, GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
- AAAI'22, Go Wider Instead of Deeper
- NAACL'22, MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation
- 大模型训练
Pathways

现今社会AI正在扮演越来越重要的角色,加之在很多领域里面AI也取得了很大的成功;
但为了与更多紧迫挑战任务的深度和复杂性相匹配,将需要新的、更强大的人工智能系统 —— 这些系统可以将人工智能的成熟方法与新兴的研究方向结合起来,从而能够解决我们今天无法解决的问题。为此,谷歌研究院的团队正在研究下一代人工智能架构的元素,called Pathways!一种通用网络的设计思路
现有AI缺憾
- 目前AI模型都是为了解决某个或者某类问题而训练的
- 目前AI模型往往都聚焦到单个感观上(sense)
- 目前AI模型往往都是稠密且低效的
Pathways Can Do
Multiple Tasks
- 模型能解决多种任务
现有的AI往往都是从随机参数开始训练的,这代表着不存在任何经验的积累;并且任务是无穷尽的,代表着我们需要训练不可计数的模型,而且模型都是从0到1,每个任务都得需要大量的数据,这是无比沉重的任务
相反,我们想要训练一个模型,它不仅可以处理许多单独的任务,还可以利用并结合现有的技能来更快、更有效地学习新任务。这样,一个模型通过训练完成一项任务——比如,学习航拍图像如何预测景观的高度——可以帮助它学习另一项任务——比如,预测洪水将如何流经该地形。
我们想要一个模型有不同的功能,可以根据需要调用,并拼接在一起执行新的,更复杂的任务-更接近哺乳动物大脑在任务之间进行概括的方式。
Multiple Senses
- 模型能具有多种感知和直觉
人类对外界的感知往往都是多模态信息的整合,而目前AI模型往往都只聚集于单个模态,基本没有融合文本、语音和图像的AI
多感知的模型结果是一个更有洞察力的模型,更不容易出现错误和偏见。
当然,人工智能模型不需要局限于这些熟悉的感官,Pathways 应该需要处理更抽象的数据形式,帮助找到人类发现不同于现有感知的其他sense
Sparse and Efficient
- 模型会变得稀疏连接且更加高效
我们的大脑有许多不同的部分专门负责不同的任务,但我们只在特定的情况下调用相关的部分。你的大脑中有近一千亿个神经元,但你依靠其中的一小部分来解释这个句子。而目前AI模型往往都是稠密的(因为是解决某个具体的任务)
人工智能也可以以同样的方式工作。我们可以建立一个“稀疏”激活的单一模型,这意味着只有通过网络的小路径在需要时被调用。事实上,模型动态地学习网络的哪个部分擅长哪些任务——它学习如何通过模型中最相关的部分路由任务。这种架构的一大好处是,它不仅具有更大的学习各种任务的能力,而且速度更快,更节能,因为我们不需要为每个任务激活整个网络。
例如,GShard和Switch Transformer是我们创建过的两个最大的机器学习模型,但由于它们都使用稀疏激活,因此它们消耗的能量不到类似大小的密集模型的1/10,同时与密集模型一样准确。
现有AI模型往往过于专注于单个任务,而它们本可以擅长许多任务。当他们可以合成几种输入时,他们依赖于一种输入形式。而且,当熟练和专业化的专业知识可以发挥作用时,他们往往会诉诸暴力(穷举)。
Pathways将使单个人工智能系统能够在数千或数百万个任务中进行泛化,以理解不同类型的数据,并以惊人的效率做到这一点——将我们从仅仅识别模式的单一用途模型时代推进到一个更通用的智能系统反映对我们世界的更深入理解并能够适应新需求的时代。
Pathways可以快速适应新的需求,解决世界各地出现的新问题,帮助人类充分利用我们面前的未来
Mixture of Experts(MoE)
- TODO 知乎
Neural Computation’1991, Adaptive mixtures of local experts
- 最早的一篇混合专家模型研究论文,理论基础论文
ICLR’17, Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- 理论基础论文
ICLR’21, GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
- 经典工作论文
JMLR’22, Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- 经典工作论文
2021, GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
- 经典工作论文
AAAI’22, Go Wider Instead of Deeper
- 网络设计
NAACL’22, MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation
- 网络设计
大模型训练
Catastrophic forgetting
- 大的预训练模型在做finetuning或者任务迁移的时候,常常出现“灾难性遗忘”
- 所谓灾难性遗忘,就是一个在原始任务上训练好的神经网络在训练完新任务后,在原始任务上的表现崩溃式的降低。
- 而大模型的出现重要原因就是为了多任务head和finetune,有解决的重要性
- 2023‘ A Comprehensive Survey of Continual Learning: Theory, Method and Application
模型参数角度
- 个人理解:大模型的参数量很多,哪些对于原始任务是重要的那些是可以在新任务上继续优化的,这些是未知的;如果经过新任务训练,重要的参数没有被小心保护起来,那么关于原始任务的关键性“记忆经验”很大概率会被遗忘
2016’ Overcoming catastrophic forgetting in neural networks (EWC)
- 提出 EWC, elastic weight consolidation
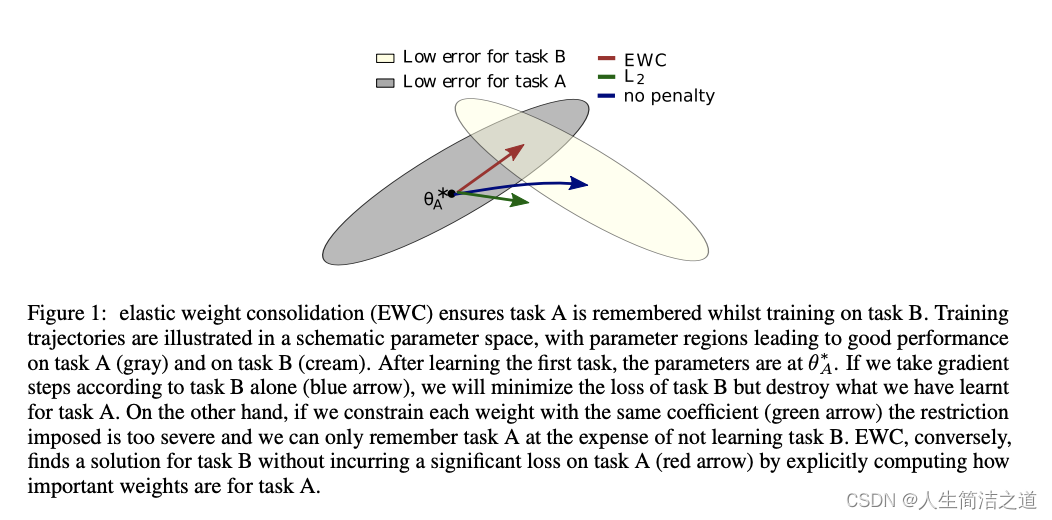
- 不能离开原始任务的参数舒适区,也能靠近新任务的舒适区
2017’ PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning
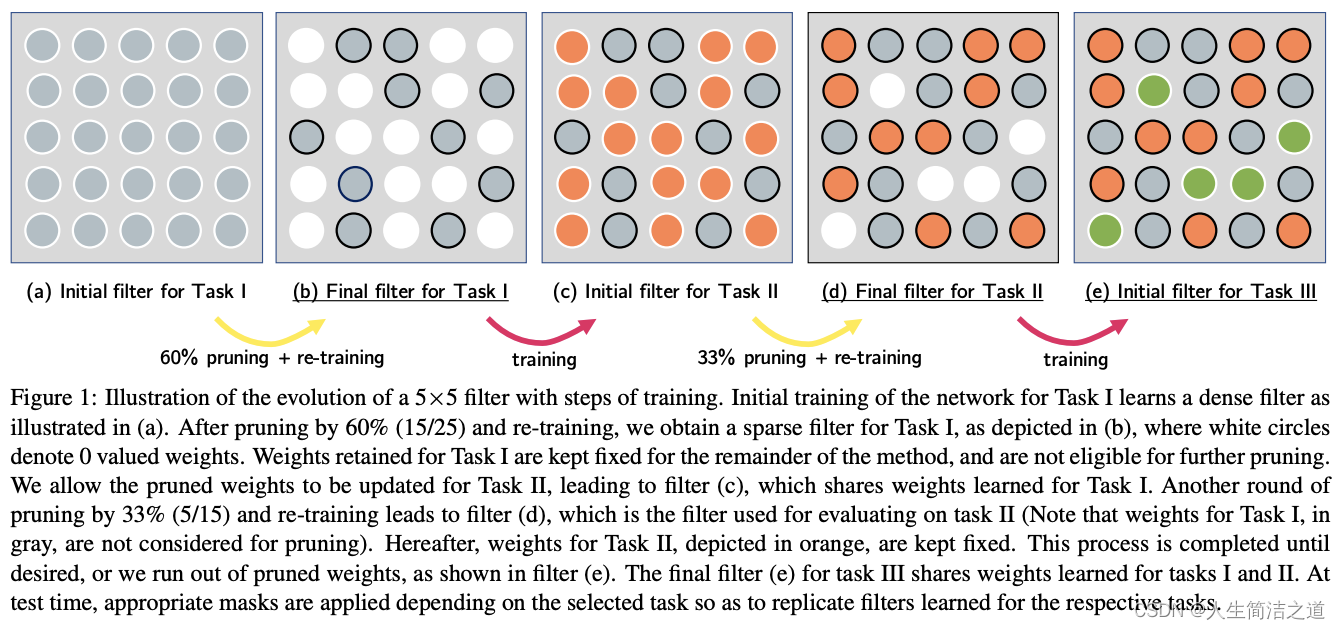
- 根据 lottery Tickets hypothesis假设,网络只有一部分参数是重要的
- 将经过原始任务的模型参数进行网格压缩,冻结重要的参数;新任务只在不重要的参数上面训练
- 但这种参数冻结会导致对于新任务来说,模型的可训练参数量过少;因此需要网络扩张,动态扩张网络
优化算法角度
- 《Essentially No Barriers in Neural Network Energy Landscape》

- 从优化角度看损失曲面,可能原始任务的loss的洼地对应新任务的尖端,导致在新任务训练按照远离原始任务的方向前进
- 策略:
- 原始任务在训练的时候,尽量处于平坦区域,等价于提升泛化能力,这个模型更鲁棒,易于迁移
- 找连通路径,Essentially No Barriers in Neural Network Energy Landscape 2018:认为神经网络的所有极小值都是联通的,并且给出了一个寻找极小值的路径算法
- 低纬度正交方式更新:Orthogonal gradient descent for continual learning,神经网络是超级高维度的算法,只要新任务上面更新网络的时候,在和原始任务无关的方向进行更新就行了,保证在优化新任务的时候产生的梯度和原始任务产生的梯度在一个低秩空间是垂直的
多任务联合优化
- 这就是和多任务网络相关的问题了,一般是预训练一个主干网络,然后在上面连多任务head。通过新任务和预训练任务的相关性设计新任务head的大小,以及分支的stage等等。
仿生学启发角度、
2019’ REMIND Your Neural Network to Prevent Catastrophic Forgetting
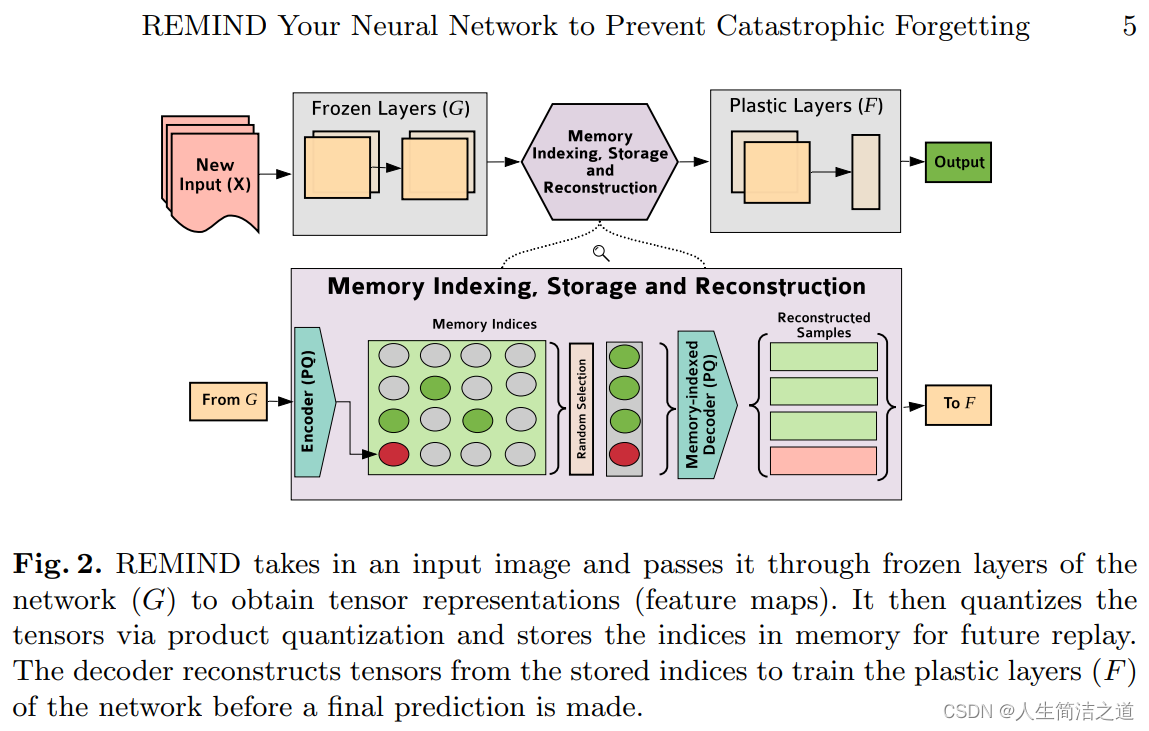
- 复习:专门把特征图存起来,量化以后放在一个类似于记忆库的地方,之后在新任务上训练的时候从这个记忆库里重构出记忆和新数据一起训练。
2022’ Sleep-like unsupervised replay reduces catastrophic forgetting in artificial neural networks
- 神经科学研究表明,睡眠对巩固人的记忆非常重要。而睡眠巩固记忆的方法是大脑自己放电;激活和强化某些神经连接,起到巩固记忆的目的。等于是一种随机的复习。
- 提出 Sleep Replay Consolidation (SRC) 理论:对一个神经网络模拟睡眠。方法超级简单,就是给一个神经网络输入噪音信号,这些噪音信号激活的连接往往和原始任务有关,直接强化这些连接就可以了
Continual Learning
- 局部网络共享的增量方法:Incremental Learning in Deep Convolutional Neural Networks Using Partial Network Sharing
- 纤维丛理论:Realizing Continual Learning through Modeling a Learning System as a Fiber Bundle
- DeepMind的贝叶斯方法:Functional Regularisation for Continual Learning
- 自动化所余山团队的正交化方法:Continual learning of context-dependent processing in neural networks

