
- 1【分布式websocket】IM系统中为什么要做心跳!Netty中如何做心跳,客户端如何做断线重连!_netty websocket心跳
- 2erlang rabbitmq源码解析_RabbitMQ面试宝典,赶紧收藏!
- 3〖Python零基础入门篇㉘〗- Python中不同数据类型间的转换_python不同类型数据转换
- 4flowable表梳理
- 5TensorFlow vs PyTorch:深度学习框架的比较研究_tensorflow和pytorch哪个好
- 6hadoop 3.x 无法访问hdfs(50070,8088)的web界面
- 7大模型安全测试入门指南
- 8chatgpt赋能python:Python中出现NaN的原因及相关处理方法_python nan
- 9k-means聚类算法详解_kmeans算法_应用k-means算法解决聚类问题
- 10Android开发者必看避坑指南,字节跳动Android面试全套真题解析在互联网火了
物联网信息处理技术IPT(数据挖掘)第二章2.3-2.4
赞
踩
目录
Cluster Analysis: Basic Concepts聚类分析:基本概念
记录点:DBSCAN: Density-Based Spatial Clustering ofpplications with Noise基于密度的噪声空间聚类应用
记录点:两种找K(聚类数量)法——经验法(简单公式法)和手肘法
Outlier Detection Methods (异常检测方法)
Proximity-Base Approaches: Distance-Based vs. Density-Based Outlier Detection接近基础方法:基于距离和基于密度的离群点检测
2.3 Cluster集群
Cluster Analysis: Basic Concepts聚类分析:基本概念


分类是监督学习,聚类分析是无监督学习


聚类的步骤


Partitioning Methods分割算法


注意这俩区别
记录点:Kmeans和Kmedoids

这里簇用了cluster

首先设K为2,从中间划分两边,算出两边的seed point,然后发现自己阵营的点更靠近对方的seed point,就把这个点划分过去,再重新算两边的seed point,直到不变
这也是下面伪代码的解释


这个弱点:指只能找到局部最优解,而不是全局最优解
![]() 因为用的是欧氏距离,其它的不一定
因为用的是欧氏距离,其它的不一定

前面“弱点”和这里的“问题”不一样
不能用于“飞突”数据集(好像是这个发音

左下角的公式d是某个点p到中心点c的距离,得到的E是非相似性
Eswapping是指除了中心被选点之外的任意一个点,如果有点能使S小于0,那就换成这个点
Kmedoid的简要解释和弱点

Hierarchical Methods分层聚类


这里看AGNES和DIANA的区别
记录点:AGNES(凝聚嵌套)和DIANA(分裂分析)

以两个簇中最近的两个点的距离作为衡量参考
 想要两个簇,画一条平行线,正好穿过两根竖线,看每一根上面是啥集合汇聚过来的
想要两个簇,画一条平行线,正好穿过两根竖线,看每一根上面是啥集合汇聚过来的

 左到右不是一步得到的,要一个一个分裂
左到右不是一步得到的,要一个一个分裂
当一个类内的相似度足够好的话,就没必要继续分裂了

上述分裂法:
就是让一个集里元素之间最大距离都小于这个->![]()

Density-Based Methods基于密度的方法


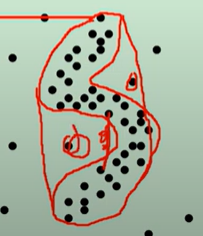 比如我们只要S里面的数据,但由于按照圆形来包裹数据,就把那两个眼里的异常值也算进去了
比如我们只要S里面的数据,但由于按照圆形来包裹数据,就把那两个眼里的异常值也算进去了
空白区、密集区——我们需要根据密度来分类


了解一下上述概念

两个条件

传递性,让区域扩大
记录点:DBSCAN: Density-Based Spatial Clustering ofpplications with Noise基于密度的噪声空间聚类应用

就是找密度联通的最大集合

先让所有点都是未标记状态,随机选一个点P标记,如果这个P是核心对象(检测它的领域),那么P加入C,并设它的领域为N,再看看N里的点是不是被标记,未被标记的话,重复上述
注意第12,和9是并列的,9是找密度联通最大,12是万一P’是别的密度里的(吧)
密度可达,显然是密度连通
P点周围密度不够会被标记为noise
遍历所有点


参数的选择对聚类结果的影响
Evaluation of Clustering聚类评价


记录点:两种找K(聚类数量)法——经验法(简单公式法)和手肘法

轮廓系数,a(o)代表紧凑性,b(o)代表不同类分离程度
2.4 Outlier Analysis异常值分析
Outlier(离群值、异常值)


比如异地登录会以为你被盗号了,和噪声不一样,噪声会存在,但异常点连属性都不一样平时一般不会出现
但异常可能会变成正常,比如异地登录可能是你换地方生活了


 理解这个就行
理解这个就行

Outlier Detection Methods (异常检测方法)

小卖铺说不考

挑出那些不符合已经确定的类的数据


就端水是吧
Statistical Approaches 统计方法


给异常值一些概率

这个就是高中数学大题第一题

这里看看图,感觉也没明说怎么筛选
Proximity-Base Approaches: Distance-Based vs. Density-Based Outlier Detection接近基础方法:基于距离和基于密度的离群点检测
小卖铺说这上面都要考



就是看这个点r为半径的周围区域的点数量够不够
这个公式,是不是要背啊
记录点:基于距离的异常值检测



记录点:基于聚类方法的异常值检测
用kmeans来找异常点,主要作用是分类,有点不懂,感觉这个方法不靠谱


1、3个是优点(无需标记、快速),后2个是缺点(不同聚类方法结果不同、为了聚类要高计算成本)
Classification Approaches分类方法

这里箭头指的是分类方法

单纯地从数据的本身内容区分是否异常值

瓶颈:指结果高度依赖训练集


