
- 1IDEA快速入门_intellij idea2020.3激活
- 2java实现的经典递归算法三例_经典递归算法java
- 3李德毅 | 人工智能看哲学
- 4手把手教你在云环境炼丹:Stable Diffusion LoRA 模型保姆级炼制教程_炼丹模型训练
- 5使用Python进行机器学习:从基础到实战
- 6[AI]文心一言出圈的同时,NLP处理下的ChatGPT-4.5最新资讯_chtagtp4.5
- 7android edittext显示光标不闪烁_单片机1602液晶屏显示 hello studet come to here
- 8uniapp 使用安卓模拟器运行调试_uniapp 安卓模拟器调试
- 9卡尔曼滤波和互补滤波的区别_互补滤波和卡尔曼滤波
- 10如何短时间通过2022年PMP考试?_pmp考试总结2022
从零创建深度学习张量库,支持gpu并行与自动微分
赞
踩
多年来,我一直在使用 PyTorch 构建和训练深度学习模型。尽管我已经学会了它的语法和规则,但总有一些东西激起了我的好奇心:这些操作内部发生了什么?这一切是如何运作的?
如果你已经到这里,你可能也有同样的问题。如果我问你如何在 PyTorch 中创建和训练模型,你可能会想出类似下面的代码:
- import torch
- import torch.nn as nn
- import torch.optim as optim
-
- class MyModel(nn.Module):
- def __init__(self):
- super(MyModel, self).__init__()
- self.fc1 = nn.Linear(1, 10)
- self.sigmoid = nn.Sigmoid()
- self.fc2 = nn.Linear(10, 1)
-
- def forward(self, x):
- out = self.fc1(x)
- out = self.sigmoid(out)
- out = self.fc2(out)
-
- return out
-
- ...
-
- model = MyModel().to(device)
- criterion = nn.MSELoss()
- optimizer = optim.SGD(model.parameters(), lr=0.001)
-
- for epoch in range(epochs):
- for x, y in ...
-
- x = x.to(device)
- y = y.to(device)
-
- outputs = model(x)
- loss = criterion(outputs, y)
-
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()

但是如果我问你这个后退步骤是如何工作的呢?或者,例如,当你重塑张量时会发生什么?数据是否在内部重新排列?这是怎么发生的?为什么 PyTorch 这么快?PyTorch 如何处理 GPU 操作?这些类型的问题一直让我着迷,我想它们也让你着迷。因此,为了更好地理解这些概念,有什么比从头开始构建自己的张量库更好的呢?这就是你将在本文中学习的内容!

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、张量
为了构建张量库,你需要学习的第一个概念显然是:什么是张量?
你可能有一个直观的想法,张量是包含一些数字的 n 维数据结构的数学概念。但在这里我们需要了解如何从计算角度对这种数据结构进行建模。我们可以将张量视为由数据本身以及描述张量的各个方面(例如其形状或其所在的设备(即 CPU 内存、GPU 内存……))的一些元数据组成。

还有一个你可能从未听说过的不太流行的元数据,称为步幅(stride)。这个概念对于理解张量数据重排的内部原理非常重要,所以我们需要进一步讨论它。
想象一个形状为 [4, 8] 的二维张量,如下图所示:

4x8 Tensor
张量的数据实际上作为一维数组存储在内存中:
![]()
张量的一维数据数组
因此,为了将这个一维数组表示为 N 维张量,我们使用步长。基本思路如下:
我们有一个 4 行 8 列的矩阵。考虑到它的所有元素都是按一维数组上的行组织的,如果我们想要访问位置 [2, 3] 的值,我们需要遍历 2 行(每行 8 个元素)加上 3 个位置。用数学术语来说,我们需要遍历一维数组上的 3 + 2 * 8 个元素:

所以这个‘8’是第二维的步幅。在这种情况下,它是我需要在数组上遍历多少个元素才能“跳”到第二维上的其他位置的信息。
因此,为了访问形状为 [shape_0,shape_1]的二维张量的元素 [i,j],我们基本上需要访问位置 j + i * shape_1的元素
现在,让我们想象一个三维张量:
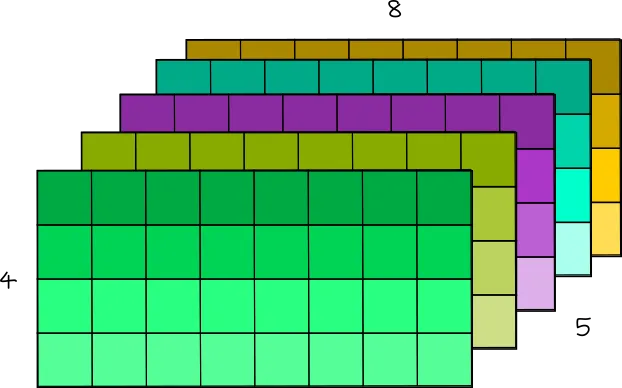
5x4x8 Tensor
你可以将这个三维张量视为矩阵序列。例如,可以将这个 [5, 4, 8] 张量视为 5 个形状为 [4, 8] 的矩阵。
现在,为了访问位置 [1, 2, 7] 处的元素,你需要遍历 1 个形状为 [4,8] 的完整矩阵、2 行形状为 [8] 的矩阵和 7 列形状为 [1] 的矩阵。因此,你需要遍历一维数组上的 (1 * 4 * 8) + (2 * 8) + (7 * 1) 个位置。

因此,要访问一维数据数组中具有 [shape_0, shape_1, shape_2] 的三维张量的元素 [i][j][k],可以执行以下操作:

这个 shape_1 * shape_2是第一维的步幅, shape_2是第二维的步幅,1是第三维的步幅。
然后,为了概括:
![]()
其中每个维度的步幅可以使用下一维张量形状的乘积来计算:

然后我们设置 stride[n-1] = 1。
在我们的形状为 [5, 4, 8] 的张量示例中,我们将有 strides = [4*8, 8, 1] = [32, 8, 1]
你可以自行测试:
- import torch
-
- torch.rand([5, 4, 8]).stride()
- #(32, 8, 1)
好的,但是为什么我们需要形状和步幅?除了访问存储为一维数组的 N 维张量的元素之外,这个概念还可用于非常轻松地操纵张量排列。
例如,要重塑张量,你只需设置新形状并根据它计算新步幅!(因为新形状保证了相同数量的元素):
- import torch
-
- t = torch.rand([5, 4, 8])
-
- print(t.shape)
- # [5, 4, 8]
-
- print(t.stride())
- # [32, 8, 1]
-
- new_t = t.reshape([4, 5, 2, 2, 2])
-
- print(new_t.shape)
- # [4, 5, 2, 2, 2]
-
- print(new_t.stride())
- # [40, 8, 4, 2, 1]
在内部,张量仍然存储为相同的一维数组。 reshape 方法没有改变数组内元素的顺序!这很神奇,不是吗?
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

