
- 1淘宝双11大数据分析(Spark 分析篇)_1. 将没有设定阈值的测试集结果存入到mysql数据中,查询数据库dbtaobao的rebuy表的
- 2基于大数据爬虫技术的图书推荐系统与可视化平台设计和实现_电子图书推荐系统的研究与实现能够为用户提供更加精准和个性化的阅读推荐,从而优
- 3继万字谏言后,Python Web 怎么学,看这篇就够了!
- 4成为鸿蒙(HarmonyOS NEXT)开发 #DAY01_鸿蒙 next helloworld
- 5mlc-llm 推理优化和大语言模型搭建解析
- 6mysql 函数和存储过程demo_$$gdatefrom
- 7Gensim-TFIDF,LDA,LSI实战_lda tfidf
- 8制作img文件
- 9TypeError: ‘int‘ object is not subscriptable_int object is not subscriptableend table end of lo
- 10c语言-文件操作详解(一键三连)_c语言写入文件
20个 K8S集群常见问题总结,建议收藏
赞
踩
问题1:K8S集群服务访问失败?

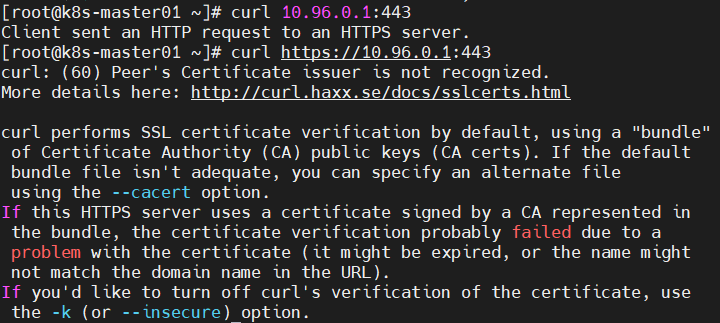
原因分析:证书不能被识别,其原因为:自定义证书,过期等。
解决方法:更新证书即可。
问题2:K8S集群服务访问失败?
curl: (7) Failed connect to 10.103.22.158:3000; Connection refused
原因分析:端口映射错误,服务正常工作,但不能提供服务。
解决方法:删除svc,重新映射端口即可。
kubectl delete svc nginx-deployment
问题3:K8S集群服务暴露失败?
Error from server (AlreadyExists): services "nginx-deployment" already exists
原因分析:该容器已暴露服务了。
解决方法:删除svc,重新映射端口即可。
问题4:外网无法访问K8S集群提供的服务?
原因分析:K8S集群的type为ClusterIP,未将服务暴露至外网。
解决方法:修改K8S集群的type为NodePort即可,于是可通过所有K8S集群节点访问服务。
kubectl edit svc nginx-deployment
问题5:pod状态为ErrImagePull?
readiness-httpget-pod 0/1 ErrImagePull 0 10s

原因分析:image无法拉取;
![]()

解决方法:更换镜像即可。
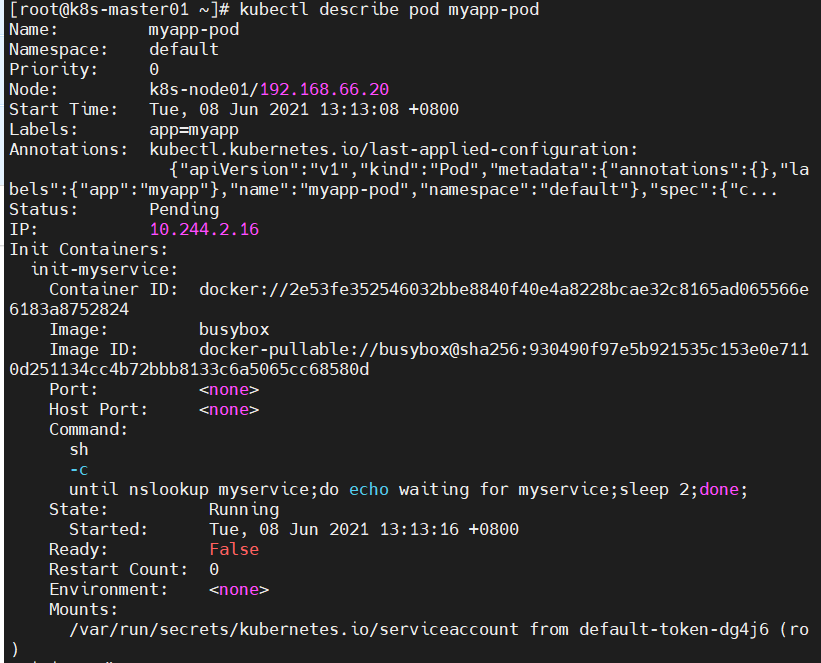
问题6:创建init C容器后,其状态不正常?
- NAME READY STATUS RESTARTS AGE
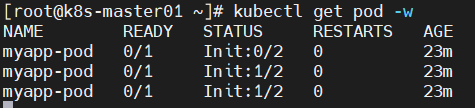
- myapp-pod 0/1 Init:0/2 0 20s
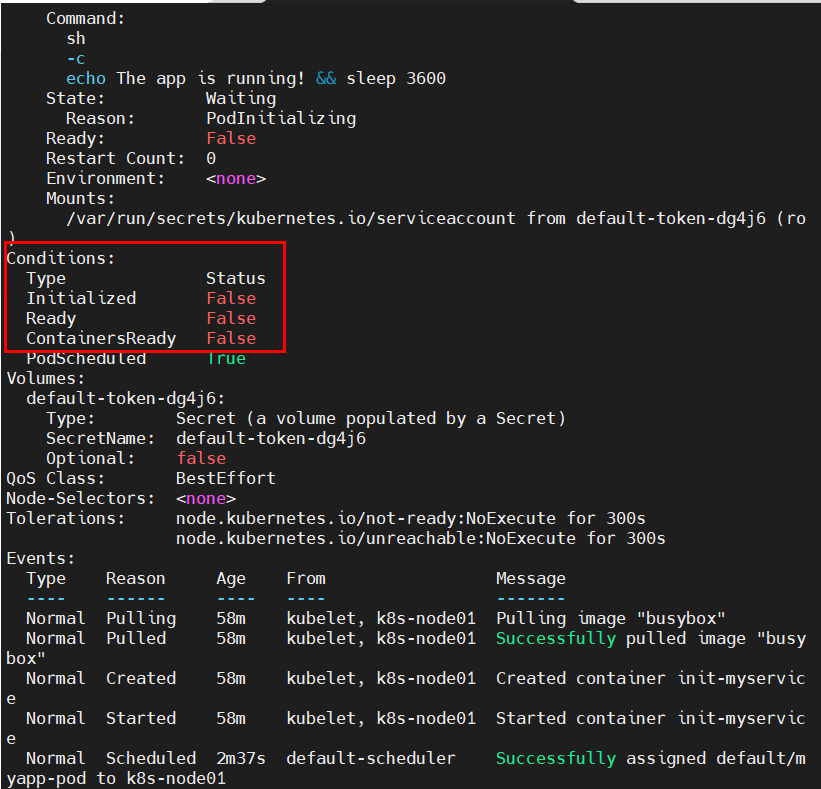
原因分析:查看日志发现,pod一直出于初始化中;然后查看pod详细信息,定位pod创建失败的原因为:初始化容器未执行完毕。
Error from server (BadRequest): container "myapp-container" in pod "myapp-pod" is waiting to start: PodInitializing
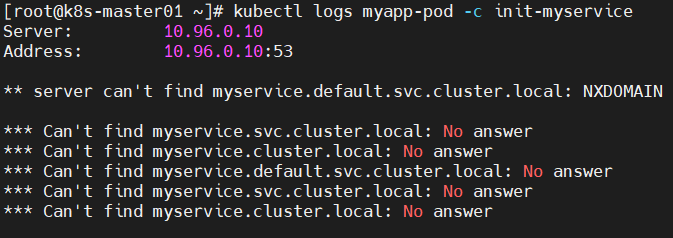
- waiting for myservice
-
- Server: 10.96.0.10
- Address: 10.96.0.10:53
-
- ** server can't find myservice.default.svc.cluster.local: NXDOMAIN
- *** Can't find myservice.svc.cluster.local: No answer
- *** Can't find myservice.cluster.local: No answer
- *** Can't find myservice.default.svc.cluster.local: No answer
- *** Can't find myservice.svc.cluster.local: No answer
- *** Can't find myservice.cluster.local: No answer
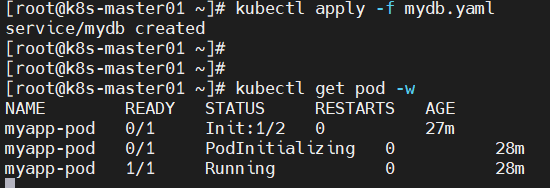
解决方法:创建相关service,将SVC的name写入K8S集群的coreDNS服务器中,于是coreDNS就能对POD的initC容器执行过程中的域名解析了。
kubectl apply -f myservice.yaml

- NAME READY STATUS RESTARTS AGE
-
- myapp-pod 0/1 Init:1/2 0 27m
- myapp-pod 0/1 PodInitializing 0 28m
- myapp-pod 1/1 Running 0 28m
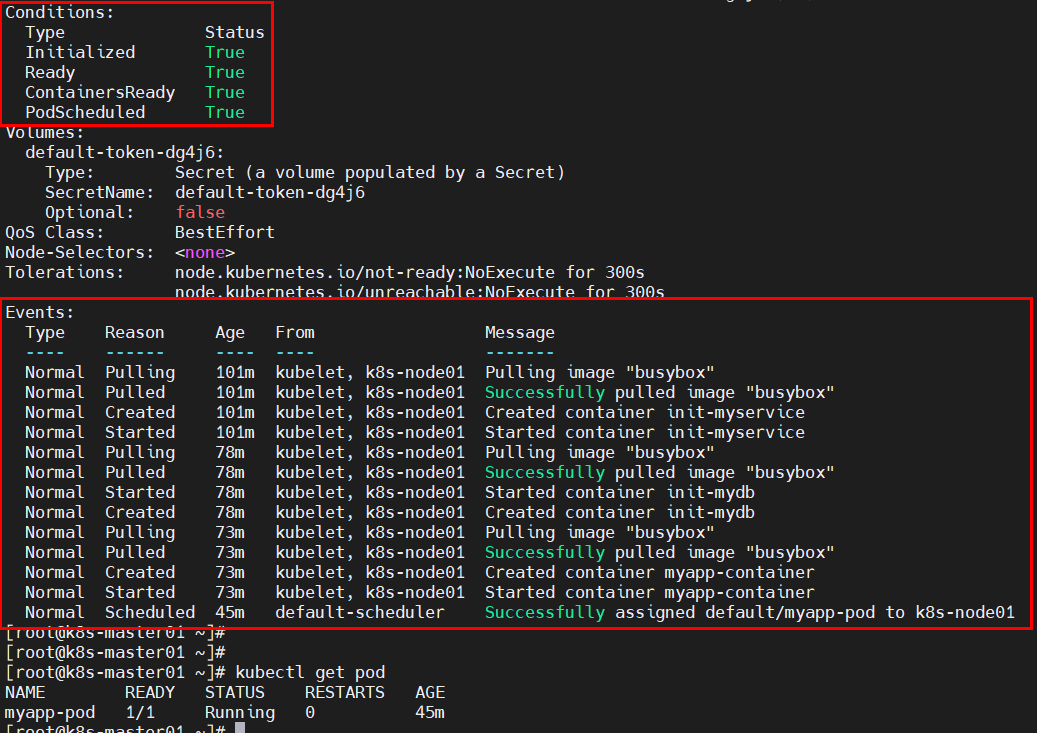
问题7:探测存活pod状态为CrashLoopBackOff?
原因分析:镜像问题,导致容器重启失败。
解决方法:更换镜像即可。
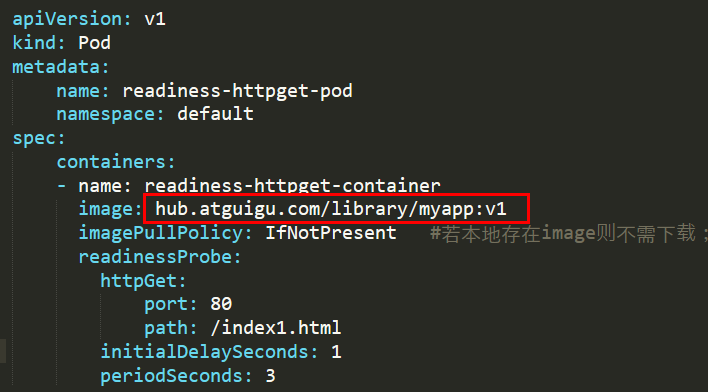

问题8:POD创建失败?
- readiness-httpget-pod 0/1 Pending 0 0s
- readiness-httpget-pod 0/1 Pending 0 0s
- readiness-httpget-pod 0/1 ContainerCreating 0 0s
- readiness-httpget-pod 0/1 Error 0 2s
- readiness-httpget-pod 0/1 Error 1 3s
- readiness-httpget-pod 0/1 CrashLoopBackOff 1 4s
- readiness-httpget-pod 0/1 Error 2 15s
- readiness-httpget-pod 0/1 CrashLoopBackOff 2 26s
- readiness-httpget-pod 0/1 Error 3 37s
- readiness-httpget-pod 0/1 CrashLoopBackOff 3 52s
- readiness-httpget-pod 0/1 Error 4 82s
原因分析:镜像问题导致容器无法启动。
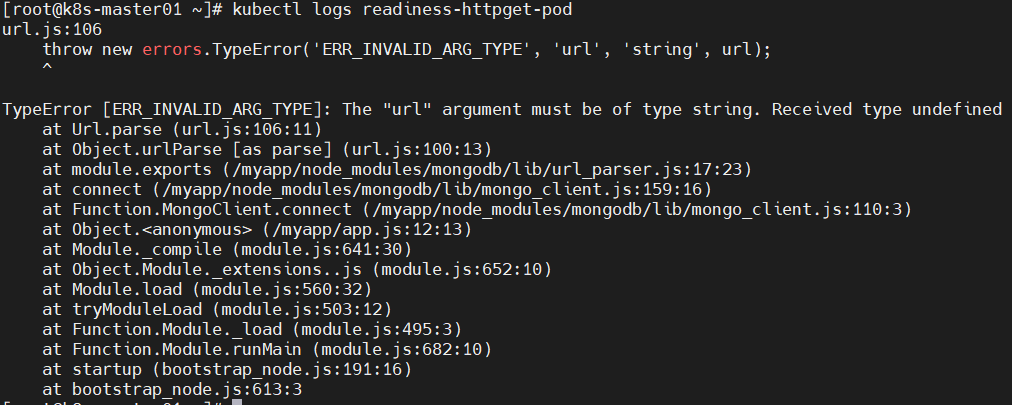
解决方法:更换镜像。
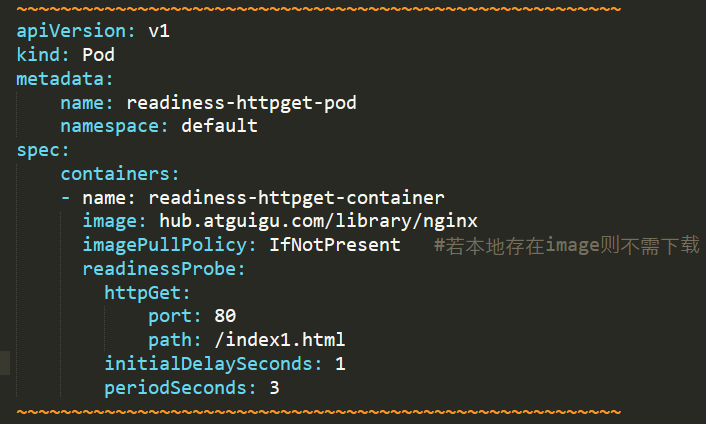
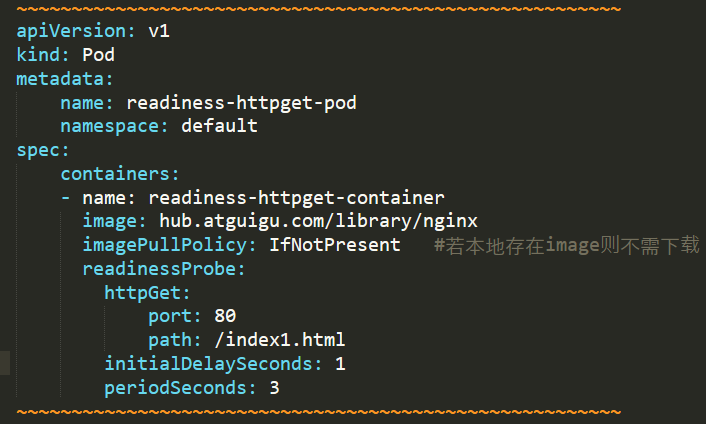
问题9:POD的ready状态未进入?
readiness-httpget-pod 0/1 Running 0 116s
原因分析:POD的执行命令失败,无法获取资源。
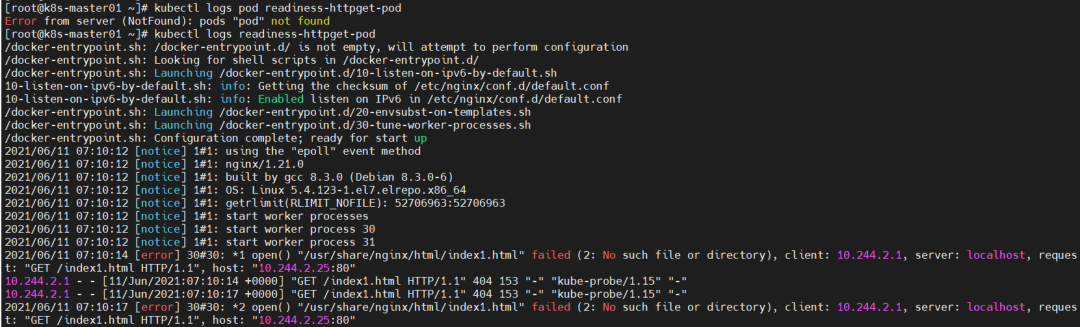
解决方法:进入容器内部,创建yaml定义的资源

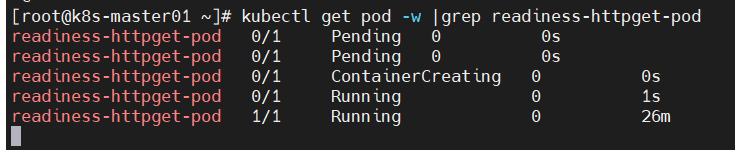
问题10:pod创建失败?
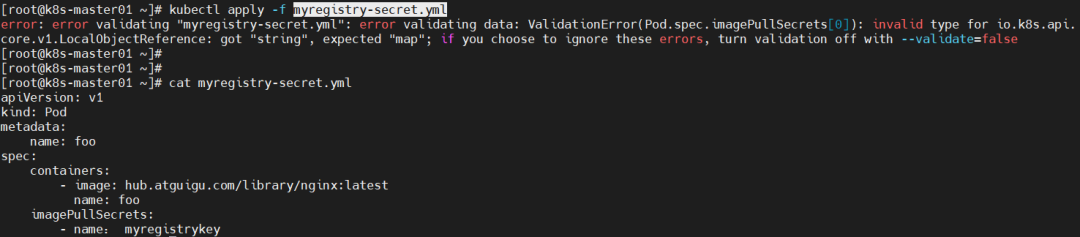
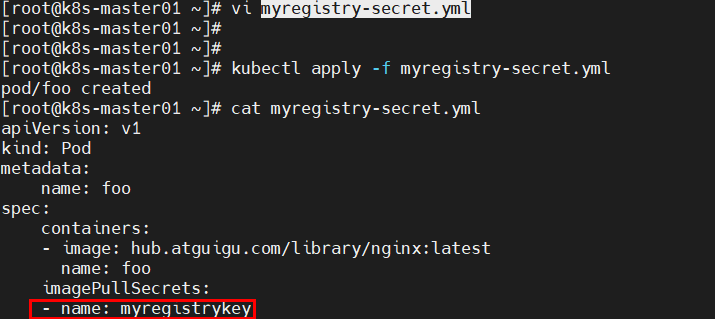
原因分析:yml文件内容出错—-使用中文字符;
解决方法:修改myregistrykey内容即可。
问题11、kube-flannel-ds-amd64-ndsf7插件pod的status为Init:0/1?
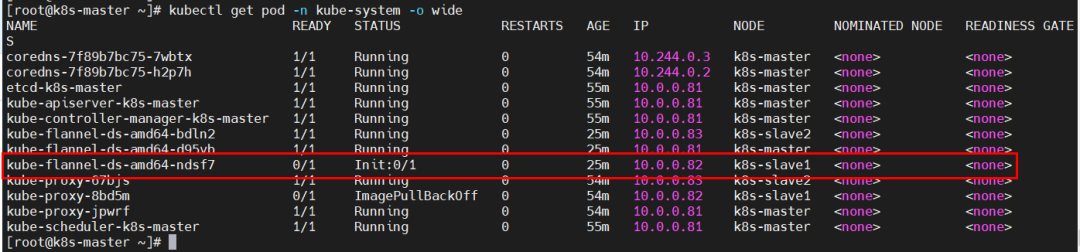
排查思路:kubectl -n kube-system describe pod kube-flannel-ds-amd64-ndsf7 #查询pod描述信息;

原因分析:k8s-slave1节点拉取镜像失败。
解决方法:登录k8s-slave1,重启docker服务,手动拉取镜像。
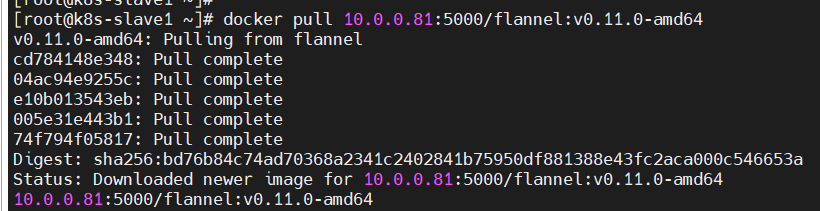
k8s-master节点,重新安装插件即可。
kubectl create -f kube-flannel.yml;kubectl get nodes

问题12、K8S创建服务status为ErrImagePull?

排查思路:
kubectl describe pod test-nginx
原因分析:拉取镜像名称问题。
解决方法:删除错误pod;重新拉取镜像;
kubectl delete pod test-nginx;kubectl run test-nginx --image=10.0.0.81:5000/nginx:alpine
问题13、不能进入指定容器内部?
![]()
原因分析:yml文件comtainers字段重复,导致该pod没有该容器。
解决方法:去掉yml文件中多余的containers字段,重新生成pod。


问题14、创建PV失败?
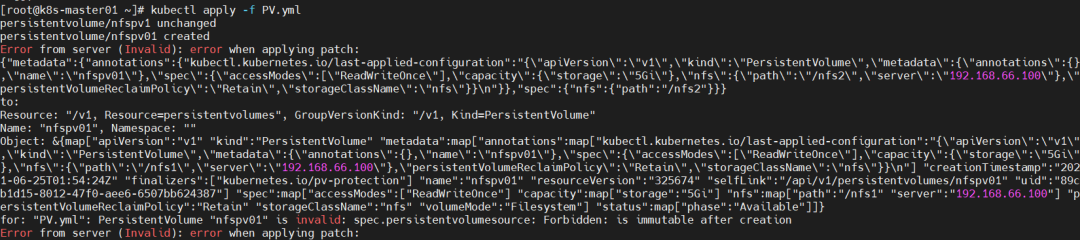
原因分析:pv的name字段重复。
解决方法:修改pv的name字段即可。
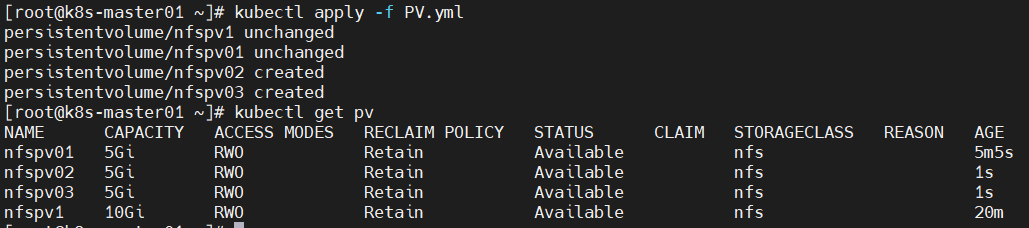
问题15、pod无法挂载PVC?

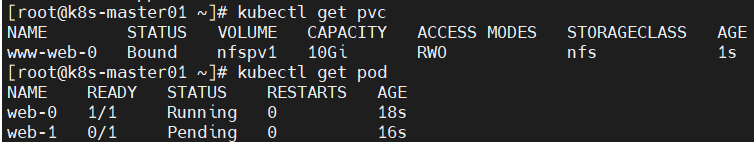
原因分析:pod无法挂载PVC。

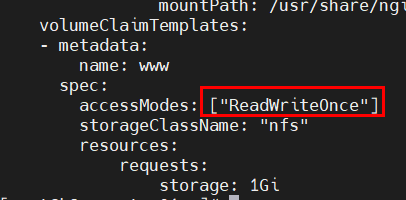
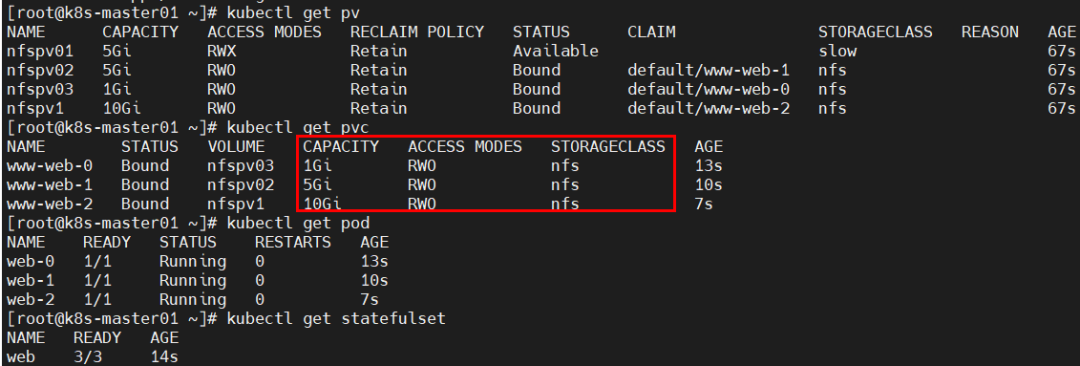
accessModes与可使用的PV不一致,导致无法挂载PVC,由于只能挂载大于1G且accessModes为RWO的PV,故只能成功创建1个pod,第2个pod一致pending,按序创建时则第3个pod一直未被创建;
解决方法:修改yml文件中accessModes或PV的accessModes即可。
问题16、问题:pod使用PV后,无法访问其内容?
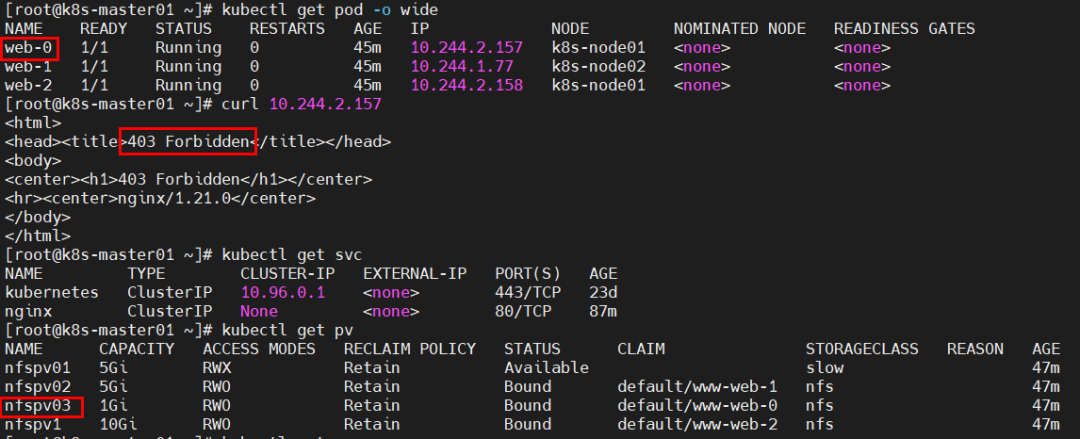
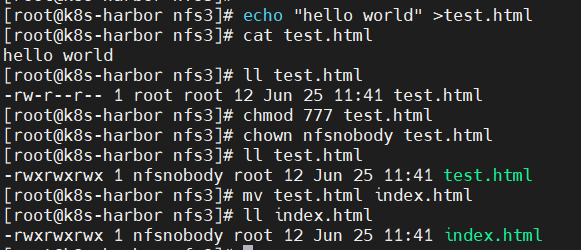
原因分析:nfs卷中没有文件或权限不对。


解决方法:在nfs卷中创建文件并授予权限。

问题17、查看节点状态失败?
Error from server (NotFound): the server could not find the requested resource (get services http:heapster:)
原因分析:没有heapster服务。
解决方法:安装promethus监控组件即可。

问题18、pod一直处于pending’状态?

原因分析:由于已使用同样镜像发布了pod,导致无节点可调度。

解决方法:删除所有pod后部署pod即可。
问题19、helm安装组件失败?
- [root@k8s-master01 hello-world]# helm install
-
- Error: This command needs 1 argument: chart nam
-
- [root@k8s-master01 hello-world]# helm install ./
- Error: no Chart.yaml exists in directory "/root/hello-world"
原因分析:文件名格式不对。
解决方法:mv chart.yaml Chart.yaml
问题20、k8s中的pod不停的重启,定位问题原因与解决方法
我们在做性能测试的时候,往往会发现我们的pod服务,频繁重启,通过kubectl get pods 命令,我们来逐步定位问题
现象:running的pod,短时间内重启次数太多

定位问题方法:查看pod日志
- kubectl get event #查看当前环境一个小时内的日志
- kubectl describe pod pod_name #查看当前pod的日志
-
- kubectl logs -f pod_name --previous #查看重启之前的那一次pod的日志,从那一刻开始计算
-
- ###############
- 一般用以上的三个命令就行
- 本次使用以下命令,解决了问题
-
- kubectl describe pod pod_name
问题原因:OOM,pod被kill掉,重启了(内存不够用)
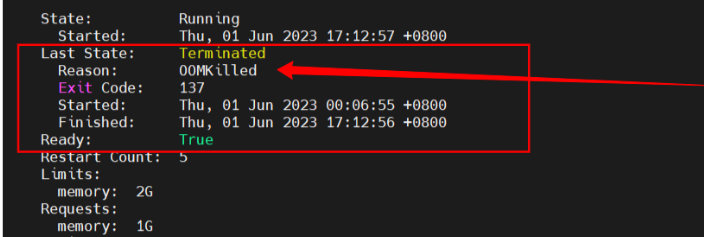
查看该服务的deployment.yaml文件

发现我们deployment.yaml对服务的内存使用,做了限制
解决方法:将limit的memory数值提高,然后delete -f yaml,再apply -f yaml
至此我们成功解决问题,并发现问题发生的根本原因

