
- 1集群环境下Kafka启动后自动关闭的解决方案_在一个broker上启动kafka会停止其他broker上的kafka
- 2Redis(01)string字符串_redis 字符串
- 3基于滑膜控制扰动观测器的永磁同步电机PMSM模型_滑模扰动观测器
- 4RabbitMQ--集成Springboot--02--RabbitListener注解_rabbitlistener注解配置
- 5全网最全Stable Diffusion教程及实践_stable-diffusion
- 6华为OD机试C卷-- 符号运算(Java & JS & Python & C)
- 7阿里云产品经理吴华剑:SLS 的产品功能与发展历程_阿里云数据管道
- 8超详细~Windows下PyCharm配置Anaconda环境教程_anaconda pycharm_pycharm2023配置anaconda解释器
- 9游戏场景设计文档案例_游戏基础知识——“游乐场”场景的设计技巧
- 10SuperMap 地图配置,美化,优化_超图设计边界线
轨迹数据
赞
踩
如何通过轨迹相似性度量方法,发现新冠易感人群
轨迹作为一种时空数据,指的是某物体在空间中的移动路径,通常表示为GPS点的序列,例如tr=<p1→p2→…pn>,其中点pi=(lat,lng,t),表示该物体在t时刻位于地理坐标位置(lat,lng)上,lat和lng分别表示纬度和经度。
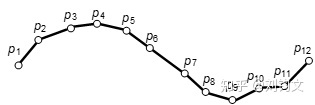
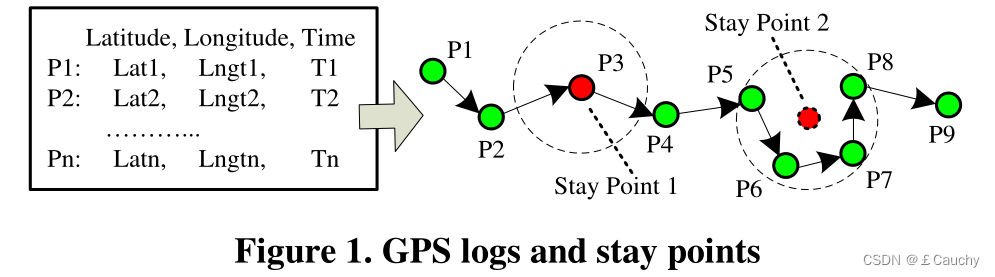
带有停留行为的轨迹:包含平均坐标、到达时间(S.arvT)和离开时间(S.levT)的信息。
轨迹数据集
【1】Dataset: GestureMidAirD1。26个界面命令手势
【2】Singapore’s police now have access to contact tracing data
【3】corona virus.jhu.map
【4】 Location-based online social networks: Gowalla / Brightkite 数据集。
该数据集由微软研究院发布。其收集了 182 个用户从 2007 年 4月到 2012 年 8 月的轨迹数据,数据按照严格的时间序列,生成了 17 621 条轨迹,共有 48 000 多小时的记录。记录了用户的工作地点和户外活动等。该数据集是用来进行用户相似度估算、隐私保护、户外推荐和数据挖掘的切合数据.
【5】[Beijing Taxi Data Set] This is a sample of T-Drive trajectory dataset that contains a one-week trajectories of 10,357 taxis. The total number of points in this dataset is about 15 million and the total distance of the trajectories reaches 9 million kilometers.
【6】微软亚洲研究院Geolife项目,GPS轨迹数据(py绘图),github,Python GPS 轨迹聚类(附代码)
【7】 Brinkhoff轨迹生成器,利用德国奥尔登堡市交通网络图作为输入,生成n条移动轨迹。
【8】 HKUST 智慧城市研究小组
【9】 出租车gps轨迹
【10】 滴滴快的智能出行平台数据2016年8月-成都
【*1】GPS轨迹数据集整理
【*2】
【*3】基于地理位置的用户兴趣推荐有哪些常用数据集?
字符串数据集
【1】 北卡罗来纳州选民登记数据集(NCVR)
轨迹应用
定位介绍:如何知道你想找的人的位置(想找到你想找的人)
- GPS、LBS基站、IP定位
应用场景:
- 地图、网约车、外卖、快递
相关会议
时间序列
相似性度量
【1】 时序数据特征提取
【2】 时间序列的自回归模型—从线性代数的角度来看
【3】【3】停留点:HGSM——基于层级结构图的相似度分析
【4】 轨迹相似度计算方法汇总
加权欧式距离
欧式距离是计算每个时间点上轨迹对应的两个点
的欧式距离, 加权欧式距离是将轨迹点在时间维度上
划分, 每个时间段内的特征点进行特征提取, 并给不同
的时间段赋予不同的权值, 例如, 筛选家庭成员则给予
夜间时间区间以较高的权值, 筛选学习工作同伴则给
予日间时间区间以较高的权值.
(a)Hausdorff 距离
- 【1】 豪斯多夫距离、MindSpore的实现代码
(b)Fréchet distance

- 【1】 弗雷歇距离、python计算
- 【2】 弗雷歇距离,多边形曲线相似性
- 【3】 离散弗雷歇距离、评价曲线相似度
- 【4】 麦吉尔大学 2002 - 计算两条多边形曲线之间的弗雷歇距离
- 【5】 杜兰大学 2015 - Slides:Fréchet Distance

【6】 路网匹配理论
【7】 深度学习的“瓶颈”与“遛狗”定理
隐式马尔科夫模型(HMM)- 地图匹配
时间对齐
python - 如何根据时间对齐数据?:switch开关
聚类
《Time-series clustering – A decade review》
3.1. Finding similar time-series in time
Euclidean distance measure are proper for this objective.
Fourier transforms, wavelets or Piecewise Aggregate Approximation (PAA). Keogh and Kasetty
3.2. Finding similar time-series in shape
elastic methods such as Dynamic time Warping (DTW)
3.3. Finding similar time-series in change (structural similarity)
Hidden Markov Models (HMM) or an ARMA process.
This approach is proper for long time-series, not for modest or short time-series.
【1】【2】github: Timeseries Classification: KNN & DTW
【时序分割】2017KDD论文 Toeplitz Inverse Covariance-Based Clustering of Multivariate Time Series(TICC)
最新文献
【1】 [KDD2022] Spatial-Temporal Trajectory Similarity Learning in Road Networks (轨迹表示学习)
SAX(Symbolic Aggregate Approximation)符号聚合近似
【1】
【2】
【3】附Python代码
【4】Professor Keogh’s homepage
- PAA (Piece-wise Average Approximation) 把不同时长的序列都分成n段,每段取它的均值,这样每个时间序列都变成了n维的特征,然后你就可以用欧式距离或者余弦计算相似度了。问题是:分段大丢失信息多,分段小降维程度低,关键是如何选择合适的线段数和合适的分段点。
有个改进叫APCA, 根据时间序列变化自动确定是否分段,每个子段用该子段上各点的平均值来表示。
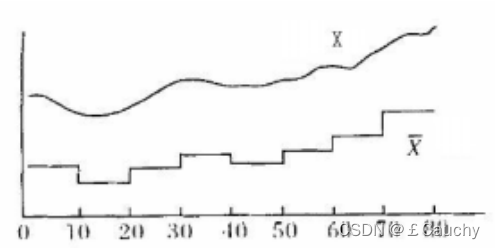
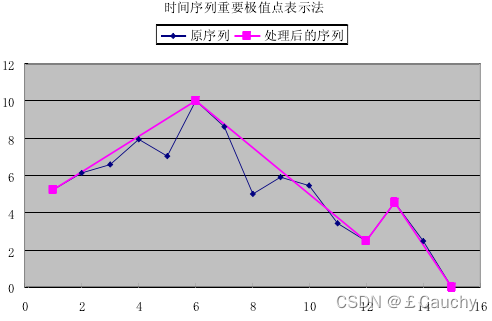
- 界标模型(landmark) 将时间序列中一些转折点定义为界标,如局部极大值、极小值和拐点等。每个序列都要对数值标准化,然后通过限定界标的变化幅度和持续时间找出最重要的n个界标。最后用这n个界标计算相似度。(Peng Changshing, Wang Haixun, Zhang Sylvia R, Parker D Stott. Landmarks: A New Model for Similarity-Based Pattern Querying in Time Series Databases[D]. Feb: Proc 16th IEEE Int’1 Conf on Data Engineering, 2000, 675~693)
Shapelet
【1】Shapelet : 一种象形化的时间序列特征提取方法
【2】
FFT快速傅立叶变换
【抽稀算法】
【1】轨迹数据预处理
垂直欧式距离
1)Douglas-Peuker 算法(DP)
【1】
2)垂距限值法
时间同步欧氏距离(SED)
3)Top-Down Time Ratio (TDTR)
字符串 近似匹配
【1】 Python中的Levenshtein距离和文本相似度
【2】 信息检索导论读书笔记(三):词典及容错式检索(通配符查询、拼写校正)
【3】 最接近字符串匹配算法
- LCSS最长公共子序列
- Dice系数
- k-gram
- Soundex:【1】
- Metaphone
距离度量算法,包括Euclidean算法,用于地址信息项的字段值字符串的相似度计算;
相似性度量算法,包括Cosine算法、Dice算法、Jaccard算法和Overlap算法,用于地址
信息项和分段处理后的数字信息项的字段值字符串的相似度计算;
最长公共子序列算法,包括Needleman-Wunsch算法,用于地址信息项、数字信息项和语
句信息项的字段值字符串的相似度计算;
编辑距离算法,包括Levenshtein Distance算法、Smith-Waterman算法、Jaro算法和
Jaro-Winkler算法,用于地址信息项、数字信息项和语句信息项的字段值字符串的相似度
计算。
基因 序列比对
【1】 生物信息学经典算法之双序列比对
【2】 字符串与模式匹配算法(六):Needleman–Wunsch算法
【3】 详解序列比对算法 01 | 两条序列比对与计分矩阵
【4】 做出漂亮的序列比对alignment图——ENDscript/ESPript
- Needleman-Wunsch 算法
- PAM Matrices
轨迹数据挖掘
社交媒体中的时空轨迹模式挖掘TrajectoryPatternMininginSocialMedia.PDF
论文pdf
停留行为 / 驻留点
【代码GitHub】 Q. Li, Y. Zheng, X. Xie, Y. Chen, W. Liu, and W.-Y. Ma, “Mining user similarity based on location history”
low sampling rate – CATS:Clue-Aware Trajectory Similarity
由于轨迹在采集的时候可能会存在大量采样点缺失的轨迹段,而对象的同一种运动行为形成的轨迹在空 间上和时间上应该都比较接近,因此Hung等人通过识别 时空上相似的轨迹,而推断出轨迹中缺失采样点 [16] 。 如图10所示,前三条轨迹的采样点缺失十分严重,通过 CATS(CATS: Clue-Aware Trajectory Similarity)方法,可以找出同一模式的轨迹,将他们的采样点相互补 充,得到一条采样完整的轨迹。CATS可以支持局部时间扭曲,对轨迹的采样率和长度都没有要求,并且对噪声具有鲁棒性。
【1】
时间序列数据挖掘
【1】 将一维时间序列转化成二维图片
降维
1. 局部敏感哈希:LSH
【1】LSH系列3:p-stable LSH&E2LSH——原理介绍
【2】LSH那些事儿 (IV): p-stable LSH
2. 时空索引
【1】 JUST技术:JUST高效时空索引揭秘及使用指南
Hilbert填充曲线
- 生成方法:
面向字节技术方法、几何方法、L系统方法、IFS迭代函数系统方法等。此外,陈宁涛等提出的方法,采用“矩阵复制、翻转、迭代”的思想,解决大型Hilbert填充曲线生成的效率问题
【1】Hilbert曲线介绍以及代码实现
【2】地理空间索引实现:z 曲线、希尔伯特曲线、四叉树, 最邻近几何特征查询、范围查询
【3】 四叉树上如何求希尔伯特曲线的邻居 ?
【4】 Google S2 中的 CellID 是如何生成的 ?
【5】 画图
其他
经纬度的距离
Computing with Spatial Trajectories 2011 书 Slides
Chapter 2 Trajectory Indexing and Retrival
时空交通数据预测方法及应用
一些对时间序列数据的理解
基于GPS轨迹数据的检索、分析和挖掘
【文献】Trajectory-Paper-Collation
【代码】Trajectory Similarity Search in Apache Spark

