- 1JavaTCP和UDP套接字编程_在了解网络编程之前,我们先了解一下什么叫套接字
- 2Baidu Comate中文名——文心快码——送礼物来了(活动最后3天)_文心快码怎么用
- 3计算机学院北航算法作业,北航《算法与数据结构》在线作业一(BUAA algorithms and data structures online homework).doc...
- 4【AI 大模型】大模型应用架构 ( 业务架构 - AI Embedded、AI Copilot、AI Agent | 技术架构 - 提示词、代理 + 函数调用、RAG、Fine-tuning )_大模型应用模式 embedded
- 5SCI投稿经验(三) 回复审稿人_sci感谢审稿人的语句
- 6Oracle数据库表空间使用情况查询_oracle查看表空间使用情况
- 7【多机器人】基于A星实现多机器人避障路径规划附Matlab代码_多机器人避障研究
- 8ES入门系列 — 4 索引及分析器_es索引analyzer 分析器
- 9详解Hook框架frida,让你在逆向工作中效率成倍提升!_nexus 6p frida
- 10英特尔CPU研发团队繁忙的一天
Langchain Ollama安装与使用_ollama如何安装在d盘
赞
踩
Ollama
简述:
Ollama是一个旨在简化大型语言模型(Large Language Models, LLMs)本地部署和运行过程的工具。它提供了一个轻量级、易于扩展的框架,允许开发者在本地机器上轻松构建和管理LLMs。通过Ollama,用户可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,而无需关注复杂的底层实现细节。Ollama支持多种操作系统,包括macOS、Windows、Linux,以及Docker环境,确保了广泛的可用性和灵活性。
本地调用查看
Cmd
执行 :ollama --version
返回:ollama version is 0.1.28
需要文档版本高于0.1.27
查看安装大预言包情况
执行: ollama list
返回
NAME ID SIZE MODIFIED
gemma:2b b50d6c999e59 1.7 GB 36 minutes ago
查看可部署模型类别
https://ollama.com/library
支持模型:
gemma
llama2
mistral
codellama
…
部署模型
ollama pull gemma:2b
执行结果 出现success,表示成功。(中途验证过程中 没有翻墙也可以完成会花费一些时间)

运行对话
ollama run gemma:2b
开启对话
系统操作
/? 查看具体的详情
返回以下内容
/set Set session variables #详细设置 可设置很多
/show Show model information #查看模型详情
/load Load a session or model #加载其他模型如果有
/save Save your current session #保存当前对话
/bye Exit #退出
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts#快捷键
模型位置调整
建议先下载一个小的模型做本地的验证
1、系统新建环境变量
变量名称:OLLAMA_MODELS
变量值:本地位置
2、复制已下载的模型
xcopy /e “C盘路径.ollama\models” “本地磁盘:\模型目录” 注意要和上面的变量值一致
如果是gemma:2b 会复制6个文件
3、删除原模型文件
rmdir /s “C盘路径.ollama\models”
是否确认(Y/N)? y
4、创建关联链接
mklink /j “C盘路径.ollama\models” “本地磁盘:\模型目录”
5、测试是否建立成功
ollama list 可显示已经下载的模型
python 调用
Pip install langchain
- 1
测试代码:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.llms import Ollama
prompt_template = "请问题下 {product} 住哪里"
ollama_llm = Ollama(model="qwen:7b")
llm_chain = LLMChain(
llm = ollama_llm,
prompt = PromptTemplate.from_template(prompt_template)
)
print(llm_chain("周杰伦"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
{‘product’: ‘周杰伦’, ‘text’:
‘周杰伦的私人住所信息是受隐私保护的,公开的信息往往是他在台湾的一些工作地点或者公共场所。若想了解更具体的个人住所位置,可能需要尊重他的私生活,并不建议进行无礼的询问。\n’}
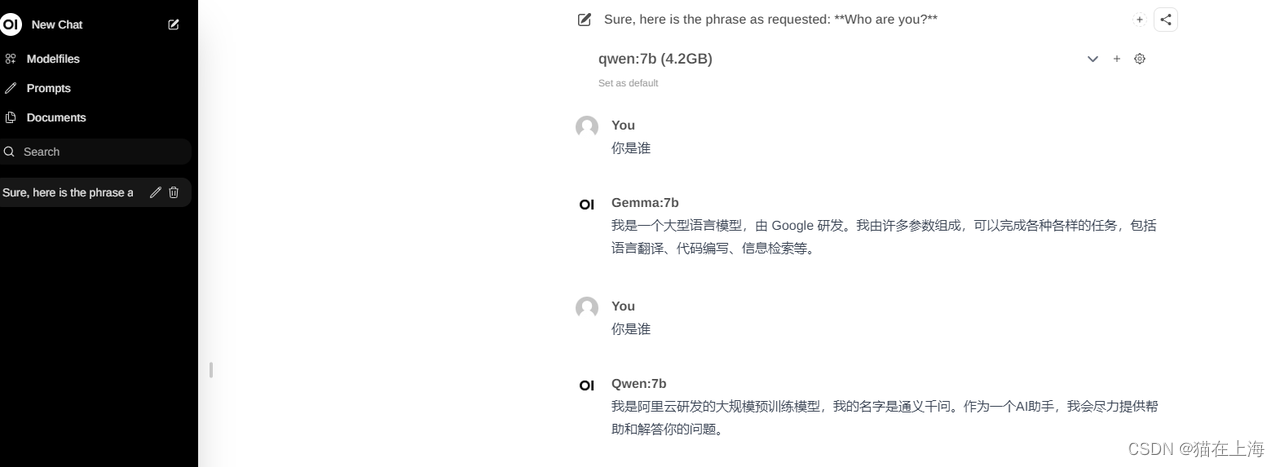
Docker 调用
Docker 打开
Cmd 中运行
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
下载完成后
http://localhost:3000/ 登录 需要注册下在本地
模型的下载和上述一致 加载会需要一些时间可以耐心等待