
- 1二次开发的扩展代码
- 2mysql双机热备份
- 3Ubuntu 中文 Wiki_ubuntu xwiki
- 4[equalization] EQ from PCISIG_tx equalization
- 5【Pytorch】神经网络搭建_神经网络搭建思路
- 6最近找到了一个免费的python教程,两周学会了python开发【内附学习视频】_1对1教python
- 7OpenAI开发者大会掀起风暴:GPT模型价格狂降50%,应用商店即将亮相,AI技术将引爆全球!_openai首次开发者大会,gpt-4 turbo首秀,价格直降 亿欧网 2023-11-08 03
- 8爬取京东评论并生成词云_爬取京东商品评论并写入text
- 9AI绘画Stable Diffusion【图生图教程】:图片高清修复的三种方案详解,你一定能用上!(附资料)_图生图 加细节
- 10用Tor实现有效且安全的互联网访问_tor.eff.org
LLM - BGE M3-Embedding 一种高效可靠的向量模型_bge embedding
赞
踩

目录
3.3 Self-Knowledge Distillation
4.3 Multilingual Long-Doc Retrieval
6.2 Experimental Hyperparameters
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
[BGE M3-Embedding:通过自我知识蒸馏的多语言、多功能、多粒度文本嵌入]
Abstract
在本文中,我们提出了一种新的嵌入模型,称为 M3-Embedding,因其在多语言、多功能和多粒度方面的多功能性而著称。它可以支持超过 100 种工作语言,从而在多语言和跨语言检索任务上实现最先进的性能。它可以同时执行嵌入模型的三种常见检索功能:密集检索、多向量检索和稀疏检索,为现实世界的 IR 应用程序提供了统一的模型基础。它能够处理不同粒度的输入,从短句到最多 8192 个标记的长文档。M3-Embedding 的有效训练涉及以下技术贡献:
- 新颖的自我知识蒸馏方法
其中来自不同检索功能的相关性分数可以集成为教师信号以提高训练质量。
- 优化了批处理策略
实现了大批量和高训练吞吐量,以确保嵌入的判别性。
Tips:
模型与代码: https://github.com/FlagOpen/FlagEmbedding
1 Introduction
嵌入模型是自然语言处理中 DNN 应用的一种关键形式。他们在潜在空间中对文本数据进行编码,其中数据的底层语义可以通过输出嵌入来表示(Reimers 和 Gurevych,2019;Ni 等人,2021)。随着预训练语言模型的出现,文本嵌入的质量得到了显着提高,这使得它们成为信息的必要组件检索(IR)。基于嵌入的 IR 是一种常见形式的密集检索,其中可以根据嵌入相似性检索查询的相关答案(Karpukhin 等人,2020;Xiong 等人,2020;Neelakantan 等人,2022;Wang 等人,2022;Xiao 等人,2023)。此外,嵌入模型也可以应用于其他 IR 任务,例如多向量检索,其中查询和文档之间的细粒度相关性是基于多个嵌入的交互分数计算的(Khattab 和 Zaharia,2020),以及稀疏或词汇检索,其中每个术语的重要性由其输出嵌入估计(Gao et al., 2021a; Lin and Ma, 2021; Dai and Clan, 2020)。
尽管文本嵌入很受欢迎,但现有方法在多功能性方面仍然有限。首先,大多数嵌入模型仅针对英语量身定制,为其他语言留下了很少可行的选择。其次,现有的嵌入模型通常针对单个检索功能进行训练。然而,典型的 IR 系统需要多种检索方法的复合工作流程。第三,由于训练成本过高,训练具有竞争力的长文档检索器具有挑战性,其中大多数嵌入模型只能支持短输入。
为了解决上述挑战,我们引入了 M3-Embedding,这对于它在工作语言中的多功能性的突破很明显。特别是,M3-Embedding 精通多语言,能够支持超过 100 种世界语言。通过学习不同语言的公共语义空间,使每种语言的多语言检索和不同语言之间的跨语言检索成为可能。此外,它能够生成通用嵌入来支持不同的检索功能,而不仅仅是密集检索,也包含稀疏检索和多向量检索。最后,M3-Embedding 学习处理不同的输入粒度,从句子和段落等短输入到多达 8,192 个输入标记的长文档。
M3 这种多功能嵌入模型的有效训练存在重大挑战。在我们的工作中,做出了以下技术贡献来优化训练质量。首先,我们提出了一种新的自知识蒸馏框架,该框架可以联合学习和相互加强多个检索功能。在 M3-Embedding 中,[CLS] 嵌入用于密集检索,而其他标记的嵌入用于稀疏检索和多向量检索。基于集成学习原理(B̈uhlmann,2012),这种异构预测器可以组合成一个更强的预测器。因此,我们将来自不同检索函数的相关性分数作为教师信号,用于通过知识蒸馏来增强学习过程。其次,我们优化了批处理策略,以实现大批量和高训练吞吐量,这极大地促进了嵌入的判别性。最后但并非最不重要的一点是,我们执行全面和高质量的数据管理。
我们的数据集由三个来源组成:
1)从大量多语言语料库中提取无监督数据
2)密切相关的监督数据的集成
3)稀缺训练数据的合成。
三个数据源相互补充并应用于训练过程的不同阶段,为通用文本嵌入奠定了基础。
M3-Embedding 在实验中表现出显着的多功能性。它为多种语言实现了卓越的检索质量,从而在流行的多语言和跨语言基准上取得了最先进的性能,如 MIACL (Zhang et al., 2023c) 和 MKQA (Longpre et al., 2021)。它有效地学习了三种检索功能,它不仅可以单独工作,还可以协同工作以获得更强大的检索质量。它还很好地保留了它在 8192 个标记内不同输入粒度上的卓越性能,大大优于现有方法。
我们的工作做出了以下贡献。
1)提出了 M3-Embedding,这是第一个支持多语言、多功能性和多粒度的模型。
2)提出了一种新的自知识蒸馏训练框架和有效的批处理策略,对训练数据进行了高质量的管理。
3) 模型、代码和数据都将公开,这为文本嵌入的直接使用和未来开发提供了关键资源。
2 Related Work
相关工作从三个方面进行回顾:一般文本嵌入、神经检索嵌入模型、多语言嵌入。
文本嵌入 - 生成 Embedding
在过去的几年里,文本嵌入领域取得了实质性进展。一个主要的驱动力是预训练语言模型的流行,其中数据的底层语义可以通过这种强大的文本编码器有效地编码(Reimers 和 Gurevych,2019;Karpukhin 等人,2020;Ni 等人,2021)。此外,对比学习的进展是另一个关键因素,特别是负采样的改进 (Xiong等人,2020;Qu等人,2020) 和知识蒸馏的利用 (Hofsẗatter等人,2021;Ren等人,2021年;Zhang等人,2021a)。在这些成熟的技术之上,学习多功能嵌入模型变得越来越流行,这些模型能够统一支持各种应用场景。到目前为止,在方向上有许多有影响力的方法,如 Contriever (Izacard et al., 2022)、LLM-Embedder (Zhang et al., 2023a)、E5 (Wang et al., 2022)、BGE (Xiao et al., 2023)、SGPT (Muennighoff, 2022) 和 Open Text Embedding (Neelakantan et al., 2022),这显着促进了文本嵌入对一般任务的使用。
神经检索 - 基于 Embedding 检索
嵌入模型的一个主要应用是神经检索(Lin et al., 2022)。通过测量与文本嵌入的语义关系,可以根据嵌入相似度检索输入查询的相关答案。基于嵌入的检索方法最常见的形式是密集检索(Karpukhin等人,2020),其中文本编码器的输出被聚合 (例如,通过[CLS]或均值池) 来计算嵌入相似度。另一种常见的替代方法被称为多 vector 检索(Khattab和Zaharia,2020;Humeau等人,2020),它对文本编码器的输出应用细粒度交互来计算嵌入相似度。最后,文本嵌入也可以转换为术语权重,这有助于稀疏或词汇检索(Luan 等人,2021;Dai 和 Clan,2020;Lin 和 Ma,2021)。通常,上述检索方法是通过不同的嵌入模型实现的。据我们所知,没有现有方法能够统一所有这些功能。
多语言嵌入 - 扩充语种支持
尽管技术进步很大,但大多数现有的文本嵌入仅针对英语开发,其他语言落后。为了缓解这个问题,从多个方向提出了持续的努力。一是开发预训练的多语言文本编码器,如 mBERT (Pires et al., 2019)、mT5 (Xue et al., 2020)、XLM-R (Conneau et al., 2020)。另一个是管理多语言文本嵌入的训练和评估数据,例如 MIACL (Zhang et al., 2023c)、mMARCO (Bonifacio et al., 2021)、Mr.TyDi (Zhang et al., 2021b)、MKQA (Longpre et al., 2021)。同时,多语言文本嵌入是从社区不断开发的,例如 mDPR (Zhang et al., 2023b)、mContriever (Izacard et al., 2022)、mE5 (Wang et al., 2022) 等。然而,鉴于与英语模型的显着差距和不同语言之间的巨大不平衡,当前的进展仍然远远不够。
3 M3-Embedding
M3-Embedding 实现了三方面的多功能性。它支持多种语言并处理不同粒度的输入数据。此外,它统一了文本嵌入的常见检索功能。形式上,给定任意语言 x 中的查询 q,它能够从语料库中检索语言 y 的文档:
![]()
在这种情况下,fn∗(·) 属于任何函数:密集、稀疏 / 词汇或多向量检索; y 可以是另一种语言或与 x 相同的语言。即可以通过相似函数匹配相同或不同语言之间的相似文档。
3.1 Data Curation
M3-Embedding 的训练需要一个大规模多样的多语言数据集。我们从三个来源执行全面的数据收集:来自未标记语料库的无监督数据、来自标记语料库的微调数据和通过协同的微调数据:
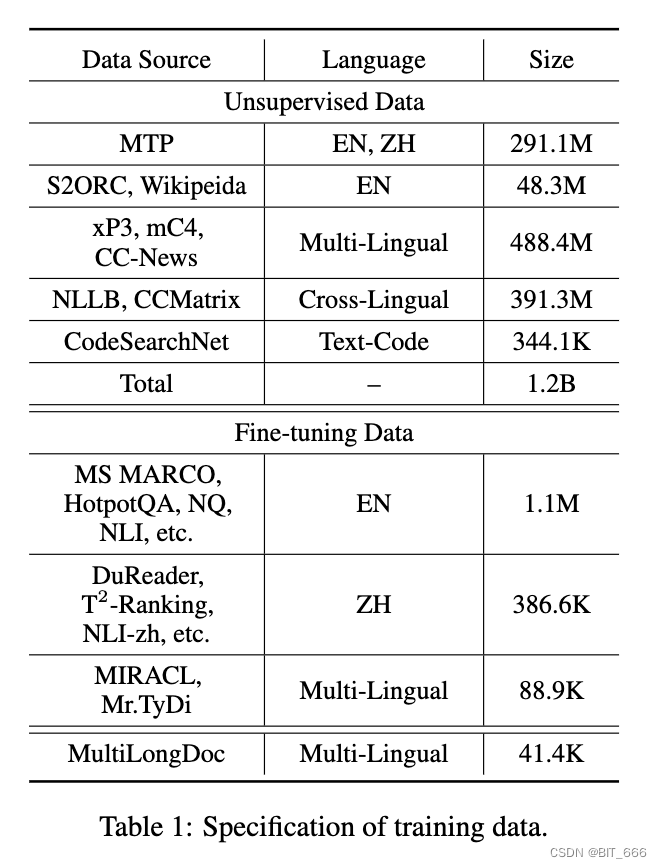
这三个数据源相互补充,应用于训练过程的不同阶段。特别是,在包括维基百科、S2ORC (Lo et al., 2020)、xP3 (Muennighoff et al., 2022)、mC4 (Raffel et al., 2019) 和 CC-News (Hamborg et al., 2017) 等多种多语言语料库中,通过提取丰富的语义结构(例如标题体、标题抽象、指令输出等)来管理无监督数据。此外,直接合并了来自 MTP (Xiao et al., 2023) 的精心策划的数据。为了学习跨语言语义匹配的统一嵌入空间,并行句子从两个翻译数据集 NLLB (NLLB Team et al., 2022) 和 CCMatrix (Schwenk et al., 2021) 中引入。过滤原始数据以去除潜在的不良内容和低相关性样本。总的来说,它带来了 194 种语言的 120 亿个文本对和 2655 个跨语言对应。
此外,我们从标记语料库中收集了相对较小但多样且高质量的微调数据。对于英语,我们结合了八个数据集,包括 HotpotQA (Yang et al., 2018)、TriviaQA (Joshi et al., 2017)、NQ (Kwiatkowski et al., 2019)、MS MARCO (Nguyen et al., 2016),COIEE (Kim et al., 2022)、PubMedQA (Jin et al., 2019)、SQuAD (Rajpurkar et al., 2016) 和 SimCSE (Gao et al., 2021b) 收集的 NLI 数据。对于中文,我们结合了七个数据集,包括 DuReader (He et al., 2017)、mMARCO-ZH (Bonifacio et al., 2021)、T2-Ranking (Xie et al., 2023)、LawGPT1、CMedQAv2 (Zhang et al., 2018)、NLIzh2 和 LeCaRDv2 (Li et al., 2023)。对于其他语言,我们利用 Mr 的训练数据。Tydi (Zhang et al., 2021b) 和 MIRACL (Zhang et al., 2023c)。
最后,我们生成合成数据来减轻长文档检索任务的不足,并引入额外的多语言微调数据(表示为 MultiLongDoc)。具体来说,我们从 Wiki 和 MC4 数据集中抽取冗长的文章,并从中随机选择段落。然后我们使用 GPT-3.5 基于这些段落生成问题。生成的问题和采样文章构成了微调数据的新文本对。下面是一些生成细节:
GPT3.5 的 Prompt 是:
"You are a curious AI assistant, please generate one specific and valuable question based on the following text. The generated question should revolve around the core content of this text, and avoid using pronouns (e.g., "this"). Note that you should generate only one question, without including additional content:"
"你是一个好奇的 AI 助手,请根据以下文本生成一个特定且有价值的问题。生成的问题应该围绕该文本的核心内容展开,并避免使用代词(例如,“this”)。请注意,您应该只生成一个问题,不包括额外的内容:”。生成的数据集的详细信息如下:

3.2 Hybrid Retrieval
M3-Embedding 统一了嵌入模型的所有三个常见检索功能,即密集检索、词汇(稀疏)检索和多向量检索。公式如下:
- Dense retrieval
输入查询 q 被转换为基于文本编码器的隐藏状态 Hq。我们使用特殊标记 "[CLS]" 的归一化隐藏状态来表示查询:
![]()
类似地,我们可以得到段落 p 的嵌入为:
![]()
因此,查询和段落之间的相关性分数由两个嵌入 eq 和 ep 之间的内积来衡量:
![]()
- Lexical Retrieval
输出 Embedding 也被用来估计每个术语的重要性,以促进词汇检索。对于查询中的每个术语 (术语对应于我们工作中的 token),术语权重计算为:
![]()
这里 W 是是将隐藏状态映射到浮点数的矩阵:
![]()
如果术语 t 在查询 query 中出现多次,我们只保留其最大权重。我们使用同样的方法来计算段落中每个术语的权重。基于估计项权重,查询和段落之间的相关性分数由查询和段落中共存项(表示为 q ∩ p)的联合重要性计算:
![]()
这里有点绕,大概理解了下,给定 qeury 和 paragraph,二者基于 token 做交集得到 q ∩ p,随后计算 ∑ w-token-q * w-token-p 的总和衡量重要性,有点像 FM 二阶交叉项 v_ij 的计算~
- Multi-Vector Retrieval
作为密集检索的扩展,多向量方法利用整个输出嵌入来表示查询和段落。
Eq 表示为:
![]()
Ep 表示为:
![]()
W 是是可学习的投影矩阵:
![]()
继 ColBert(Khattab and Zaharia, 2020) 之后,我们使用后期交互来计算细粒度的相关性分数:
![]()
N 和 M 是查询和段落的长度。
由于嵌入模型的多功能性,检索过程可以在混合过程中进行。首先,可以通过每种方法单独检索候选结果(多向量方法由于其沉重的成本而免除这一步)。然后,根据综合相关性分数对最终的检索结果进行重新排序:
![]()
3.3 Self-Knowledge Distillation
训练嵌入模型将正样本与负样本区分开来。对于每个检索方法,与负样本相比,期望为查询的正样本分配更高的分数。因此,进行训练过程以最小化 InfoNCE 损失,其一般形式由以下损失函数表示:
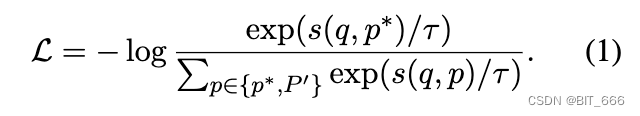
这里,p∗ 和 P' 代表查询 q 的正样本和负样本,s(·) 是内部的任何函数:
![]()
不同检索方法的训练目标可以相互冲突。因此,原生多目标训练不利于嵌入的质量。为了便于优化多个检索函数,我们建议在自知识蒸馏的基础上统一训练过程。特别是,基于集成学习原理(B̈uhlmann,2012),不同检索方法的预测可以集成为更准确的相关性分数,因为它们的异质性。在最简单的形式中,集成只能是不同预测分数的总和:
![]()
在之前的研究中,嵌入模型的训练质量可以从知识蒸馏中受益,它利用了另一个 rank 模型的细粒度软标签(Hofst ̈atter 等人,2021 年)。在这种情况下,我们简单地使用集成分数 sinter 作为 teacher,其中每个检索方法的损失函数修改为:
![]()
这里,p(·) 是 softmax 激活; s∗ 是 sdense、slex 和 smul 中的任何成员。我们进一步整合和规范化修改后的损失函数:
![]()
整个训练过程是一个多阶段的工作流程,我们使用预先训练的 XLMRoBERTa (Conneau et al., 2020) 模型,通过 RetroMAE (Xiao et al., 2022) 方法作为基础文本编码器。首先,使用海量无监督数据对文本编码器进行预训练,其中只有密集检索以对比学习的基本形式进行训练。将自知识蒸馏应用于第二阶段,对嵌入模型进行微调以建立三个检索功能。在这个阶段都使用了标记数据和未标记数据,其中按照 ANCE 方法为每个查询引入硬负样本(Xiong et al., 2020)。
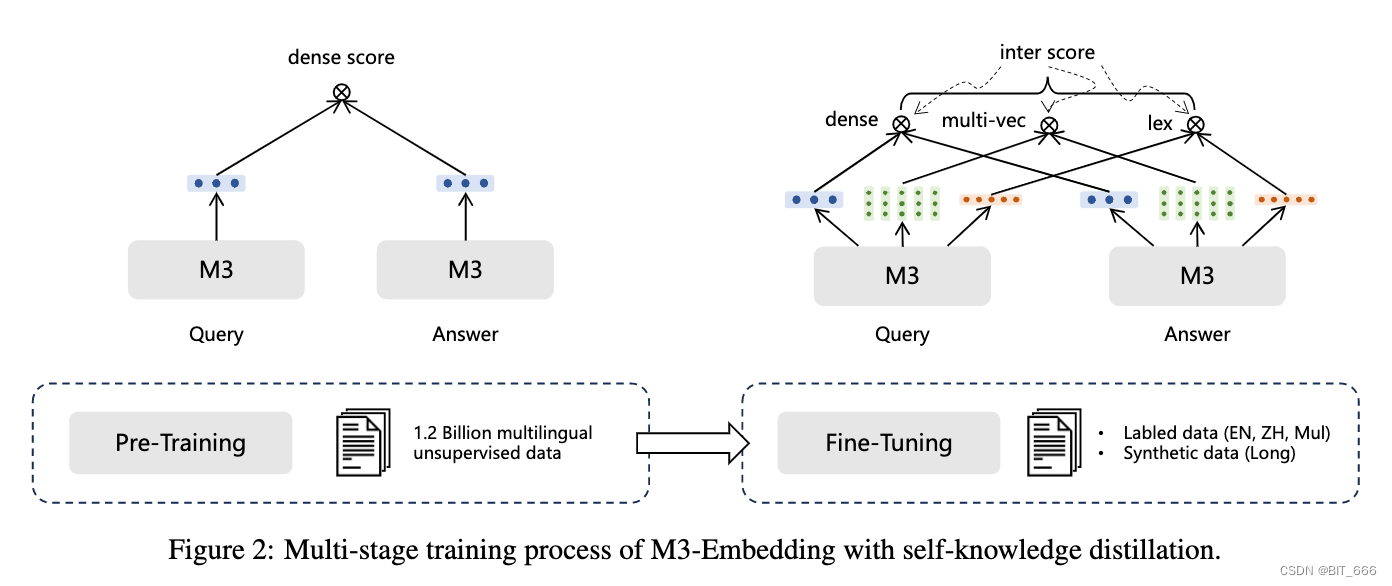
第一步类似一个 DSSM 的双塔结构,Query 塔和 Answer 塔计算 Dense Score 得到基本的参数,这样可以通过 Query 和 Answer 塔生成基础信息向量,随后通过类多目标学习进行模型有监督微调,使模型学习微调数据的特性。
3.4 Efficient Batching
嵌入模型需要从多样化和海量的多语言数据中学习,以完全捕捉不同语言的一般语义。它还需要尽可能保持批量大小,以确保文本嵌入的判别性。鉴于 GPU 内存和计算能力的限制,人们通常将输入数据截断为短序列,以实现高吞吐量的训练和大批量。然而,常见的做法不是 M3-Embedding 的可行选择,因为它需要从短序列和长序列数据中学习来有效地处理不同粒度的输入。在我们的工作中,我们通过优化批处理策略来提高训练效率,该策略可以实现高训练吞吐量和大批量。
特别是,训练数据通过按序列长度分组进行预处理。在生成小批量时,训练实例从同一组中采样。由于序列长度相似,它显着减少了序列填充(用红色标记),并有助于更有效地利用 GPU。此外,在采样时不同 GPU 的训练数据,随机种子总是固定的,这确保了负载平衡并最小化每个训练步骤中的等待时间。此外,在处理长序列训练数据时,小批量进一步划分为子批次,占用内存占用较少。我们使用梯度检查点 (Chen et al., 2016) 迭代地对每个子批次进行编码,并收集所有生成的嵌入。这种方法可以显着提高批量大小。例如,在处理长度为 8192 的文本时,批量大小可以增加 20 倍以上。最后,广播来自不同 gpu 的嵌入,允许每个设备在分布式环境中获得所有嵌入,这显著扩大了负样本的规模。
- Split-batch Method

Algorithm 1 提供了拆分批次策略的伪代码。对于当前批次,我们将其划分为多个较小的子批次。对于每个子批次,我们利用模型生成嵌入,在前向传递期间通过梯度检查点丢弃所有中间激活。最后,我们从所有子批次中收集编码结果,并获得当前批次的嵌入。启用梯度检查点是至关重要的策略;否则,每个子批次的中间激活将不断累积,最终占用与传统方法相同数量的 GPU 内存。
在 Table 10 中,我们研究了拆分批次对批量大小的影响。可以观察到,随着启用拆分批次,批量大小显着增加。同时,随着文本长度较长,增加变得更加明显,并且在长度为 8192 的情况下,使拆分批次导致批量大小的增长超过 20 倍。

然而,用户可能缺乏足够的计算资源或数据来训练长文本模型。因此,我们还提出了一种 MCLS 策略来增强模型的长文本能力,而无需训练。该策略利用多个 CLS 标记来捕获在推理过程中应用的文本语义。
- MCLS Method
由于缺乏长文本数据或计算资源,使用长文本进行微调可能会受到限制。在这种情况下,我们提出了一种简单但有效的方法:MCLS(Multiple CLS) 来增强模型在没有对长文本进行微调的情况下的能力。MCLS 方法旨在利用多个 CLS 标记来共同捕获长文本的语义。具体来说,我们为每个固定数量的标记插入 CLS 标记(在我们的实验中,我们为每个 256 个标记插入“[CLS]”),每个 CLS 标记可以从其相邻标记中捕获语义信息。最终,最终的文本嵌入是通过对所有 CLS 标记的最后一个隐藏状态进行平均来获得的,这里有点像 Bert-Whitening 里选取 Bert 的 Last-Hidden-States。
4 Expirement
在接下来的部分中,我们在三个任务上评估我们的模型:多语言检索、跨语言检索和长文档检索。
4.1 Multi-Lingual Retrieval
我们使用 MIACL (Zhang et al., 2023c) 评估多语言检索性能,该数据集由 18 种语言的临时检索任务组成。每个任务由同一语言中呈现的查询和段落组成。在官方基准之后,我们使用 Pyserini (Lin et al., 2021) 评估我们的方法,并使用 nDCG@10 作为主要评估指标(Recall@100 也在附录 C.1 中测量和报告)。我们在实验中使用了以下基线:词汇检索方法:BM25 (Robertson and Zaragoza, 2009);密集检索方法:mDPR3 (Zhang et al., 2023b)、mContriever4 (Izacard et al., 2022)、mE5large (Wang et al., 2022) 和 E5misral-7b (Wang et al., 2023)。为了使 BM25 和 M3 更具可比性,在实验中,我们对 BM25 使用与 M3(即 XLM-Roberta 的标记器)相同的标记器。使用来自 XLM-Roberta 的相同词汇表也可以确保这两种方法都具有相同的检索延迟。我们还与 OpenAI-5 最近发布的 Text-Embedding-3-Large (简称 OpenAI3) 进行了比较。
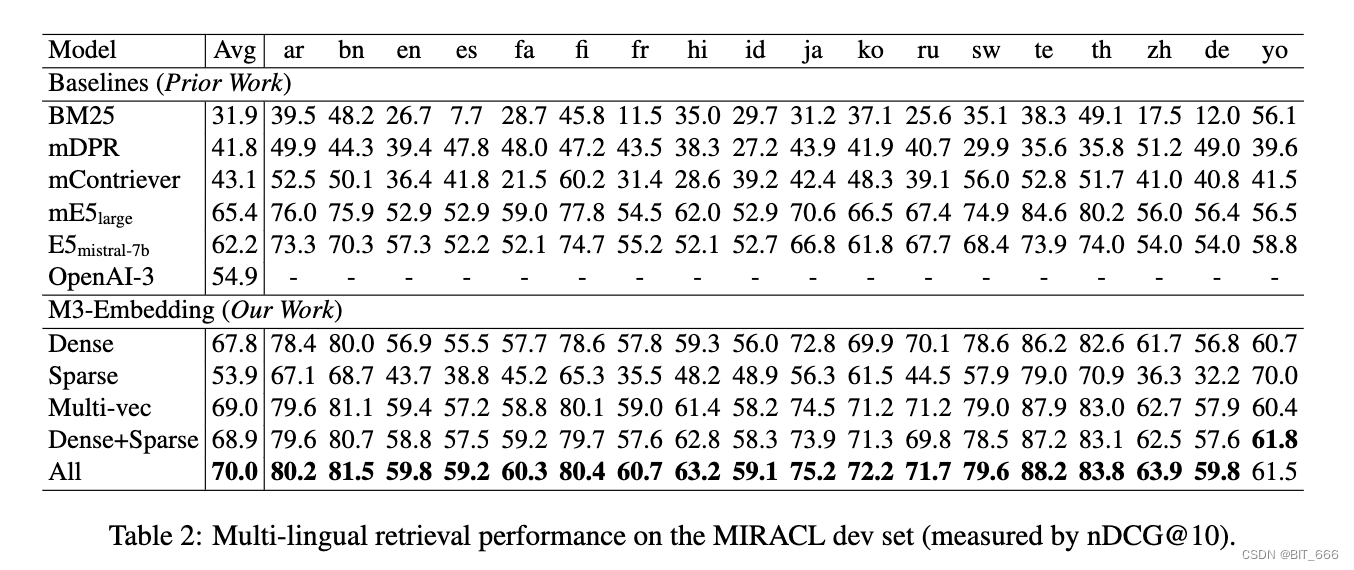
我们可以根据表 2 中的实验结果进行以下观察。首先,M3-Embedding 已经仅使用其密集检索功能(表示为 Dense)实现了卓越的检索性能。它不仅在平均性能方面优于其他基线方法,而且在大多数单独的语言中也保持了一致的经验优势。即使与利用更大的 Mistral-7B 模型作为文本编码器并使用英语数据进行训练的 E5 mistral-7b 相比,我们的方法能够在英语中产生类似的结果,在其他语言中产生明显更高的结果。此外,稀疏检索功能(表示为 Sparse)也由 M3-Embedding 有效训练,它在所有语言中都优于典型的 BM25 方法。我们还可以观察到多向量检索 6(表示为 Mult-vec)的额外改进,它依赖于查询和段落嵌入之间的细粒度交互来计算相关性分数。最后,密集稀疏方法(例如 Dense+Sparse7)的协作导致每个单独方法的进一步改进;这三种方法的协作 8(表示为 All)带来了最佳性能。
4.2 Cross-Lingual Retrieval
我们使用 MKQA 基准 (Longpre et al., 2021) 评估跨语言检索性能,其中包括 25 种非英语语言中的查询。对于每个查询,它需要从英语维基百科语料库中检索真实段落。在我们的实验中,我们利用了 BEIR9 提供的处理良好的语料库(Thakur 等人,2021 年)。根据之前的研究(Karpukhin et al., 2020),我们报告 Recall@100 作为主要指标(Recall@20 在附录中报告为辅助指标)。

实验结果如表 3 所示。与我们在多语言检索中观察到的类似,M3-Embedding 继续产生卓越的性能,它明显优于其他基线方法,纯粹具有密集检索功能 (Dense)。不同检索方法的协作带来了进一步的改进,导致跨语言检索的最佳经验性能。此外,我们还可以观察到这个基准独有的以下有趣的结果。首先,性能差距不如 MIRACL 显着,其中 E5misstral-7b 等竞争基线能够在一些测试语言上产生相似甚至更好的结果。然而,基线在许多其他语言中往往表现不佳,尤其是低资源语言,如ar、km、he等。相比之下,M3-Embedding 在所有语言中都保持了相对稳定的性能,这在很大程度上可以归因于它对综合无监督数据的预训练。其次,虽然 M3-Embedding (Sparse) 仍然比 BM25 好,但与其他方法相比表现不佳。这是因为跨语言检索只有非常有限的共存术语,因为查询和段落以不同的语言呈现。
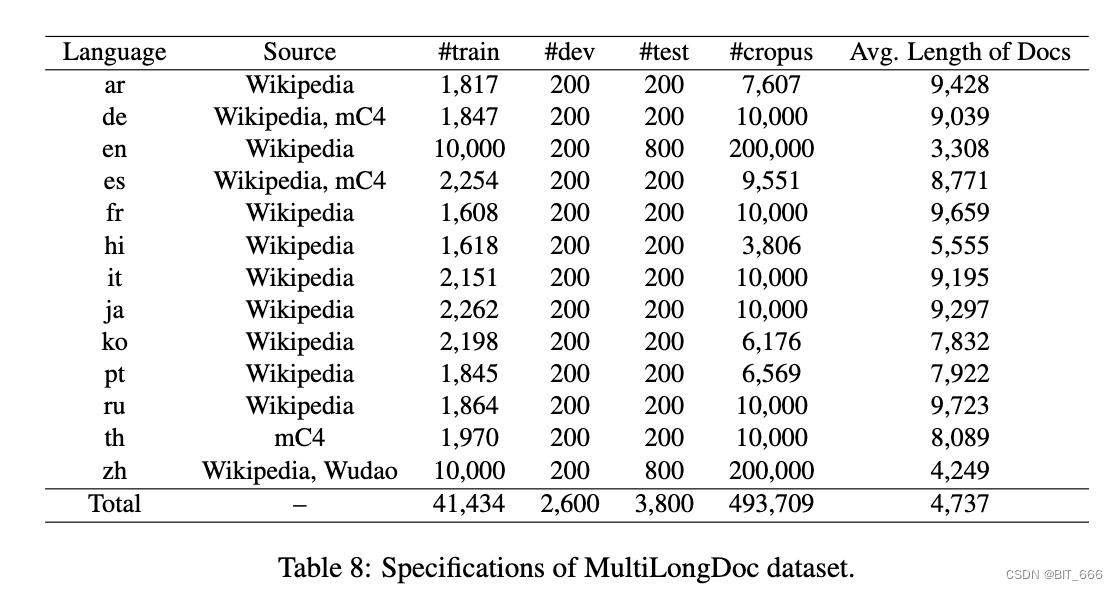
4.3 Multilingual Long-Doc Retrieval
我们使用两个基准评估长序列的检索性能:MLDR(多语言长文档检索),它由来自 Wikipedia、Wudao 和 mC4 的多语言文章管理(见表 8)和 NarrativeQA10(s Koˇ cisk ́y 等人,2018 年;G̈unther 等人 2024),仅适用于英语。除了前面的基线,我们进一步引入了 JinaEmbeddingv211 (G̈unther et al., 2024)、文本嵌入-ada-002 和文本嵌入-3-large,因为它们具有出色的长文档检索能力。
MLDR 的评估结果如表 4 所示。有趣的是,M3(Sparse) 被证明是长文档检索的一种更有效的方法,它比密集方法实现了大约 10 个点的改进。此外,多向量检索也令人印象深刻,比 M3 (Dense) 提高了 5.1+ 分。最后,不同检索方法的组合导致 65.0 的显着平均性能。
为了探索 M3-Embedding 在长文档检索方面竞争力的原因,我们通过从微调阶段删除长文档数据来执行消融研究(表示为 w.o.长)。经过这种修改,密集方法,即 Dense-w.o.long,仍然可以超过大多数基线,这表明其经验优势在训练前阶段得到了很好的建立。我们还提出了一个简单的策略,MCLS,以解决这种情况(没有数据或没有 GPU 资源用于文档检索微调)。实验结果表明,在没有训练的情况下,MCLS 可以显着提高文档检索的性能(41.2 → 45.0)。

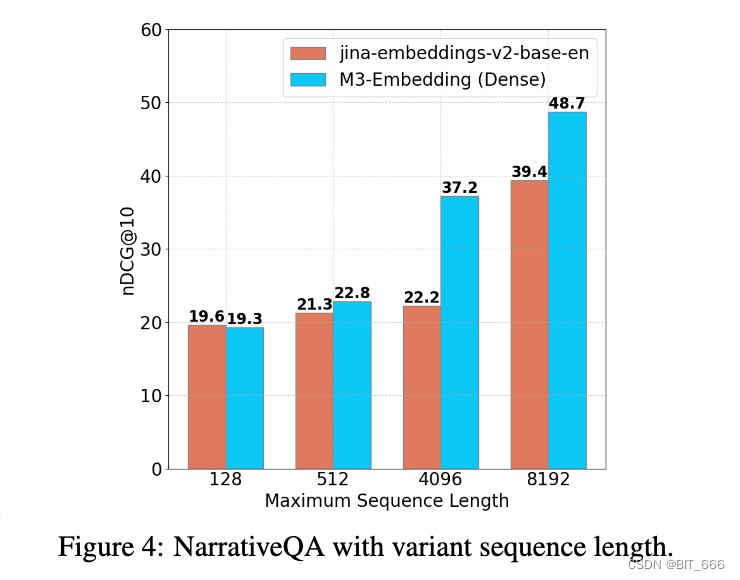
我们对 NarrativeQA(表 5)进行了进一步分析,其中我们观察到与 MLDR 相似。此外,随着序列长度的增长,我们的方法逐渐扩展了它相对于基线的优势(图 4),这反映了它在处理长输入方面的熟练程度。
4.4 Ablation study
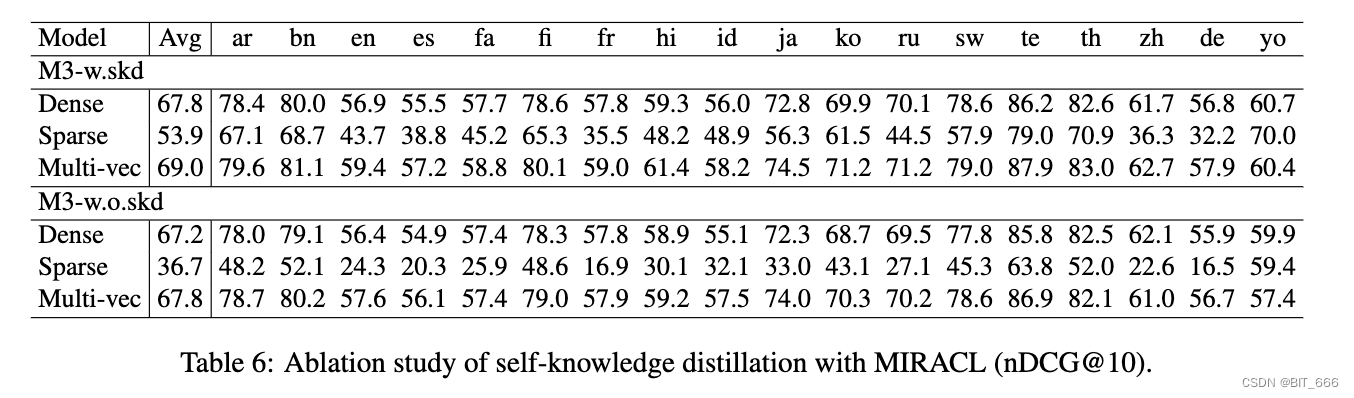
- Self-knowledge distillation
进行消融研究以分析自我知识蒸馏 (skd) 的影响。特别是,我们禁用蒸馏处理并拥有独立训练的每个检索方法(表示为 M3-w.o.skd)。根据我们对 MIACL 的评估(表 6),原始方法,即 M3 w.skd,在所有设置中都比消融方法带来更好的性能,即 Dense、Sparse、Multivec。值得注意的是,稀疏检索的影响更为明显,这表明密集检索方法和稀疏检索方法不兼容。
- Impact of multi-stage training
进行了实验来探索不同阶段的影响。微调表明直接从 xlm-roberta (Conneau et al., 2020) 模型进行微调,RetroMAE+Fine-tuning 是指对使用 RetroMAE 训练的模型进行微调(Xiao et al., 2022)。同时,RetroMAE+Unsup+Finetuning 涉及对使用 RetroMAE 训练的模型进行微调,然后在无监督数据上进行训练。结果如表 7 所示。我们可以看到,RetroMAE 可以显著提高检索性能,对无监督数据的预训练可以进一步提高嵌入模型的检索能力。

5 Conclustion
在本文中,我们提出了 M3-Embedding,它在支持多语言检索、处理不同粒度的输入以及统一不同的检索功能方面取得了显着的多功能性。我们对训练数据进行了全面和高质量的管理,通过自我知识蒸馏优化学习过程,并通过高效的批处理改进训练和批量大小。M3-Embedding 的有效性通过我们的实验研究得到验证,这导致多语言检索、跨语言检索和多语言长文档检索任务的性能优越。
6 appendix
6.1 Collected Data
无监督数据的语言和长度分布(令牌的数量)如图 5 所示。
我们观察到,对于长文本(例如 cc-news 中的新闻),初始句子往往是总结语句,模型只能依赖这些初始句子中呈现的信息来建立相关关系。为了防止模型只关注这些起始句子,我们实现了一种随机洗牌整个文本中片段顺序的策略。具体来说,我们将文本分为三个部分,随机打乱它们的顺序,并重新组合它们。这种方法允许相关的文本段在长序列中的任何位置随机出现。在训练期间,我们将此操作应用于概率为 0.2% 的段落。

6.2 Experimental Hyperparameters
我们采用进一步预训练的 XLM-RoBERTa12 作为基础模型。我们将最大位置扩展到 8192,并通过 RetroMAE (Xiao et al., 2022) 方法更新模型。数据包括 Pile (Gao et al., 2020)、Wudao (Yuan et al., 2021) 和 mC4 (Raffel et al., 2019) 数据集。我们从这些来源中抽取了总共 18400 万个文本样本,涵盖了 105 种语言。最大序列长度为 8192,学习率为 7 × 10e−5。批量大小设置为 32,我们在 16 步上累积梯度。预训练在 32 个 A100(40GB) GPU 上进行 20,000 步。
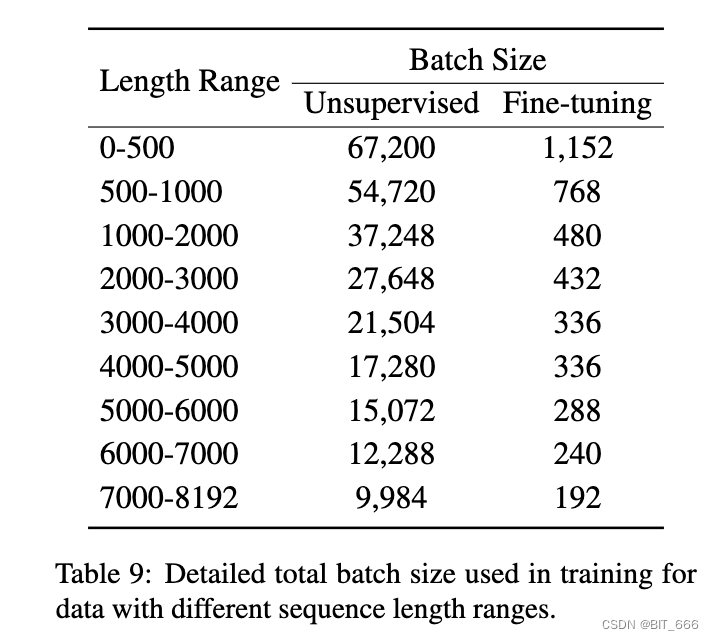
对于具有大量无监督数据的预训练,查询和段落的最大长度分别设置为 512 和 8192。学习率为 5 × 10e−5,预热比为 0.1,重量衰减为 0.01。这个训练过程需要 25,000 步。对于序列长度范围不同的训练数据(例如 0-500、500-1000 等),我们使用不同的批量大小。细节如表 9 所示。第二阶段在 96 A800(80GB) GPU上进行:
在微调阶段,我们为每个查询采样 7 个负样本。有关批量大小,请参见表 9。在初始阶段,我们使用大约 6000 步对密集嵌入、稀疏嵌入和多向量进行预热。随后,我们使用自我知识蒸馏进行了统一训练。这些实验是在 24 个 A800(80GB) GPU 上进行的。
7.Some thoughts
M3-Embedding 作为当前最先进的 Embedding 模型,也是引入了非常多的思路供我们学习,下面整理一下博主阅读完的一些可以应用在自己场景的想法:
7.1 Data
6.1 节 collect_data 中提到了一点,一些 news 新闻的开头总是相似的或者冗长的,这很容易导致 Query 、Paragraph 之间的相似度受到这部分公共内容的影响,所以文中提出的拆分为 3 段,再按照 0.2% 的概率进行随机打乱还是很有启发性的,当我们场景的 Answer 相似句子多时,可以考虑剔除或者采用打乱的方式,增加其随机性。
7.2 Mix Metric
知识蒸馏的环节里采用三个向量相似度计算方法的均分作为 teacher,在我们 LLM 开发的过程中,单一指标往往不具备很强的说服力,可以参考类似结合的方法,将多个相似度指标结合,论文中利用结合后的分数作为 teacher,我们就直接作为 metric 评估即可:
![]()
7.3 MCLS Method
这个方法通过对原始句子构造 [CLS] 掩码的方法,学习其他位置向量的信息,最终取多个 [CLS] 向量的向量均值作为嵌入表征计算相似度,这提供了一种信息抽取方式的相似度计算方法,即对待预测相似度的 Pair 进行 Token 采样,再 Pooling 进行相似度计算,和 bert-Whitening 里增加检索效率有一定的相似,一个减维度一个减数量。
7.4 Token Weight
基于 Token 相似度的评估,M3 提供了权重矩阵 W 可以获取 Token 的权重,同时支持互相计算相似度,这个我们一种基于关键词 Token 向量相似度的评估方法,也是非常的哇塞,后续去 M3-Embedding 官网把模型搞下来好好试验下 M3 的能力,到时候再和大家分享!

