
linux 应用编程(持续更新)_linux应用编程
赞
踩
在嵌入式 Linux 系统中,我们编写的应用程序通常需要与硬件设备进行交互
Tips:本篇将以正点原子 ALPHA/Mini I.MX6U 开发板开发板出厂系统进行测试
进程间通信
- 管道
- FIFO
- 信号
- 消息队列
- 信号量
- 共享内存
- 套接字
开发板 电脑 虚拟机互传数据
互连我看的是正点原子的视频。讲的挺好的网络环境搭建
互传我看的是正点的 “【正点原子】I.MX6U网络环境TFTP&NFS搭建手册V1.3.1”
我一般是用nfs共享文件夹的方法,好用,不需要记指令
应用编程
应用层操控硬件的两种方式
设备文件便是各种硬件设备向应用层提供的一个接口,包括字符设备文件和块设备文件
设备文件通常在/dev/目录下,我们也把/dev 目录下的文件称为设备节点。
设备节点并不是操控硬件设备的唯一途径,除此之外,我们还可以通过== sysfs 文件系统==对硬件设备进行操控
sysfs 文件系统
sysfs 是一个基于内存的文件系统,同 devfs、proc 文件系统一样,称为虚拟文件系统
将内核信息以文件的方式提供给应用层使用
它可以产生一个包含所有系统硬件层次的视图。对系统设备进行管理
sysfs 文件系统把连接在系统上的设备和总线组织成为一个分级的文件、展示设备驱动模型中各组件的层次关系。
sysfs 提供了一种机制,可以显式的描述内核对象、对象属性及对象间关系,用来导出内核对象 (kernel object,譬如一个硬件设备)的数据、属性到用户空间,以文件目录结构的形式为用户空间提供对这些数据、属性的访问支持。
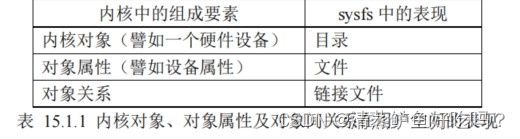
sysfs 文件系统挂载在/sys 目录下
是 sysfs 文件系统中的目录,包括 block、bus、class、dev、devices、firmware、fs、kernel、modules、power 等,每个目录下又有许多文件或子目录
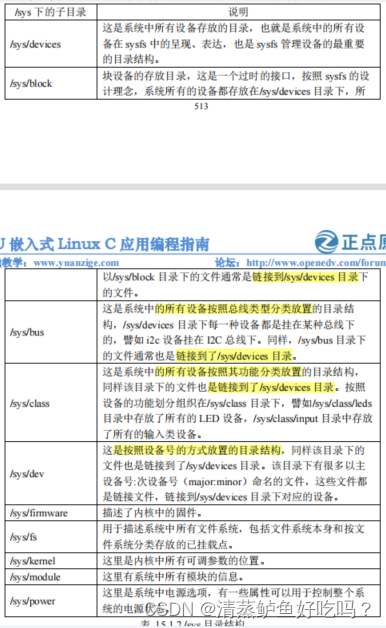
系统中所有的设备(对象)都会在/sys/devices 体现出来,是 sysfs 文件系统中最重要的目录结构
/sys/bus、/sys/class、/sys/dev 分别将设备按照挂载的总线类型、功能分类以及设备号的形式将设备组织存放在这些目录中,这些目录下的文件都是链接到了/sys/devices 中。
设备的数据、属性会导出到用户空间,以文件形式为用户空间提供对这些数据、属性的访问支持,可以把这些文件称为属性文件
应用层想要对底层硬件进行操控,通常可以通过两种方式:
⚫ /dev/目录下的设备文件(设备节点);
⚫ /sys/目录下设备的属性文件。
有些设备只能通过设备节点进行操控,而有些设备只能通过 sysfs 方式进行操控;当然跟设备驱动具体的实现方式有关
简单的设备会用sysfs,例如LED、GPIO
但对于一些较复杂的设备通常会使用设备节点的方式,譬如 LCD 等、触摸屏、摄像头等。
标准接口与非标准接口
Linux 内核中为了尽量降低驱动开发者难度以及接口标准化,就出现了设备驱动框架的概念
对各种常见的设备进行分类,譬如 LED 类设备、输入类设备、FrameBuffer 类设备、video 类设备、PWM 设备等等,并为每一种类型的设备设计了一套成熟的、标准的、典型的驱动实现的框架,这个就叫做设备驱动框架
设备驱动框架为驱动开发和应用层提供了一套统一的接口规范
驱动工程师编写 LED 驱动时,使用 LED 驱动框架来开发自己的 LED 驱动程序,这样做的好处就在于,能够对上层应用层提供统一、标准化的接口、同时又降低了驱动开发工程师的难度。
因为一个计算机系统所能够连接、使用的外设实在太多了,不可能每一种外设都能够精准地分类到某一个设备类型中,通常把这些无法进行分类的外设就称为杂项设备。它是一种非标准接口
LED应用编程
其实现使用 sysfs 方式控制
进入到/sys/class/leds 目录下。/sys/class/leds 目录下便存放了所有的 LED 类设备
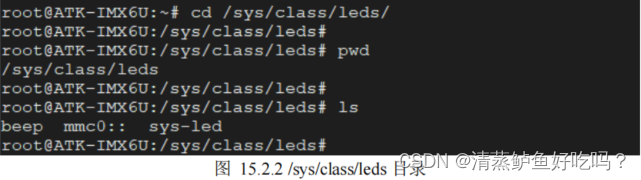
sys-led 文件夹,这个便是底板上的用户 LED 设备文件夹

这里我们主要关注便是 brightness、max_brightness 以及 trigger 三个文件,这三个文件都是 LED 设备的属性文件:
⚫ brightness:亮度。对于 PWM 控制的 LED 来说,存在亮度等级的问题,不同的亮度等级对应不同的占空比,自然 LED 的亮度也是不同
但对于 GPIO控制(控制 GPIO 输出高低电平)的 LED 来说,通常不存在亮度等级这样的说法。譬如 brightness 等于 0 表示 LED 灭
⚫ max_brightness:该属性文件只能被读取,不能写,用于获取 LED 设备的最大亮度等级。
⚫ trigger:触发模式。常用的触发模式包括none(无触发)、mmc0(当对 mmc0 设备发起读写操作的时候 LED 会闪烁)、timer(LED 会有规律的一 亮一灭,被定时器控制住)、heartbeat(心跳呼吸模式,LED 模仿人的心跳呼吸那样亮灭变化)。
大家可以自己动手使用 echo 或 cat 命令进行测试、控制 LED 状态
echo timer > trigger //将 LED 触发模式设置为 timer
echo none > trigger //将 LED 触发模式设置为 none
echo 1 > brightness //点亮 LED echo 0 > brightness//熄灭 LED
- 1
- 2
- 3
写完代码后
在使用之前先对交叉编译工具的环境进行设置,使用 source 执行安装目录下的environment-setup-cortexa7hf-neon-poky-linux-gnueabi 脚本文件即可
source /opt/fsl-imx-x11/4.1.15-2.1.0/environment-setup-cortexa7hf-neon-poky-linux-gnueabi
- 1
然后编译就行了
${CC} -o LED led.c
- 1
这个LED就是交叉编译后arm平台能够运行的程序。
GPIO应用编程
与 LED 设备一样,GPIO 同样也是通过 sysfs 方式进行操控,进入到/sys/class/gpio 目录下
⚫ gpiochipX:当前 SoC 所包含的 GPIO 控制器。板子上分别为 GPIO1、GPIO2、GPIO3、GPIO4、GPIO5,在这里分别对应 gpiochip0、gpiochip32、gpiochip64、gpiochip96、gpiochip128 这 5 个文件夹
进去之后可以看到
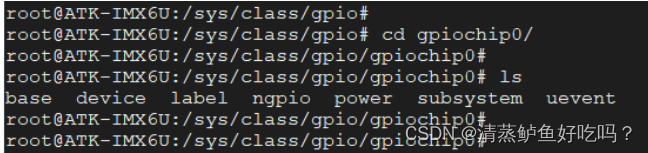
在这个目录我们主要关注的是 base、label、ngpio 这三个属性文件,这三个属性文件均是只读、不可写。
base:与 gpiochipX 中的 X 相同,表示该控制器所管理的这组 GPIO 引脚中最小的编号
label:该组 GPIO 对应的标签,也就是名字。

ngpio:该控制器所管理的 GPIO 引脚的数量(所以引脚编号范围是:base ~ base+ngpio-1)。
对于给定的一个 GPIO 引脚,如何计算它在 sysfs 中对应的编号呢?其实非常简单,譬如给定一个 GPIO引脚为 GPIO4_IO16,那它对应的编号是多少呢?首先我们要确定 GPIO4 对应于 gpiochip96,该组 GPIO 引脚的最小编号是 96(对应于 GPIO4_IO0),所以 GPIO4_IO16 对应的编号自然是 96 + 16 = 112
回到刚才的在/sys/class/gpio文件夹
⚫ export:用于将指定编号的 GPIO 引脚导出。在使用 GPIO 引脚之前,需要将其导出,导出成功之后才能使用它。
echo 0 > export # 导出编号为 0 的 GPIO 引脚(对于 I.MX6UL/I.MX6ULL 来说,也就是GPIO1_IO0)
- 1
导出成功之后会发现在/sys/class/gpio 目录下生成了一个名为 gpio0 的文件夹(gpioX,X 表示对应的编号)
⚫ unexport:将导出的 GPIO 引脚删除。当使用完 GPIO 引脚之后,我们需要将导出的引脚删除
echo 0 > unexport # 删除导出的编号为 0 的 GPIO 引脚
- 1
删除成功之后,之前生成的 gpio0 文件夹就会消失!
以上就给大家介绍了/sys/class/gpio 目录下的所有文件和文件夹
控制 GPIO 引脚主要是通过 export 导出之后所生成的 gpioX(X 表示对应的编号)文件夹,在该文件夹目录下存在一些属性文件可用于控制 GPIO引脚的输入、输出以及输出的电平状态等。
Tips:需要注意的是,并不是所有 GPIO 引脚都可以成功导出,如果对应的 GPIO 已经在内核中被使用了,那便无法成功导出
进入到 gpio0 目录,
我们主要关心的文件是 active_low、direction、edge 以及 value 这四个属性文件
⚫ direction:配置 GPIO 引脚为输入或输出模式。该文件可读、可写
读取或写入操作可取的值为"out"(输出模式)和"in"(输入模式)
⚫ value:在 GPIO 配置为输出模式下,向 value 文件写入"0"控制 GPIO 引脚输出低电平
⚫ active_low:这个属性文件用于控制极性,可读可写,默认情况下为 0,为高电平1。否则反向
⚫ edge:控制中断的触发模式,需将其设置为输入模式:
非中断引脚:echo “none” > edge
上升沿触发:echo “rising” > edge
下降沿触发:echo “falling” > edge
边沿触发:echo “both” > edge
当引脚被配置为中断后可以使用 poll()函数监听引脚的电平状态变化
输入设备应用编程
常见的输入设备有鼠标、键盘、触摸屏、遥控器、电脑画图板等,用户通过输入设备与系统进行交互。
input 子系统
驱动开发人员基于 input 子系统开发输入设备的驱动程序,input 子系统可以屏蔽硬件的差异,向应用层提供一套统一的接口。
基于 input 子系统注册成功的输入设备,都会在==/dev/input 目录下生成对应的设备节点(设备文件)==
节点名称通常为 eventX(X 表示一个数字编号 0、1、2、3 等)
读取数据的流程
①、应用程序打开/dev/input/event0 设备文件;
②、应用程序发起读操作(譬如调用 read),如果没有数据可读则会进入休眠(阻塞 I/O 情况下);
③、当有数据可读时,应用程序会被唤醒,读操作获取到数据返回;
④、应用程序对读取到的数据进行解析。
其实每一次 read 操作获取的都是一个 struct input_event 结构体类型数据,该结构体定义在<linux/input.h>头文件中
struct input_event {
struct timeval time;
__u16 type;
__u16 code;
__s32 value;
};
- 1
- 2
- 3
- 4
- 5
- 6
⚫ type:type 用于描述发生了哪一种类型的事件(对事件的分类)
/* * Event types */ #define EV_SYN 0x00 //同步类事件,用于同步事件 #define EV_KEY 0x01 //按键类事件 #define EV_REL 0x02 //相对位移类事件(譬如鼠标) #define EV_ABS 0x03 //绝对位移类事件(譬如触摸屏) #define EV_MSC 0x04 //其它杂类事件 #define EV_SW 0x05 #define EV_LED 0x11 #define EV_SND 0x12 #define EV_REP 0x14 #define EV_FF 0x15 #define EV_PWR 0x16 #define EV_FF_STATUS 0x17 #define EV_MAX 0x1f #define EV_CNT (EV_MAX+1)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数据同步
提到了同步事件类型 EV_SYN,同步事件用于实现同步操作、告知接收者本轮上报的数据已经完整。
内核将本轮需要上报、发送给接收者的数据全部上报完毕后,接着会上报一个同步事件,以告知应用程序本轮数据已经完整、可以进行同步了。
/*
* Synchronization events.
*/
#define SYN_REPORT 0
#define SYN_CONFIG 1
#define SYN_MT_REPORT 2
#define SYN_DROPPED 3
#define SYN_MAX 0xf
#define SYN_CNT (SYN_MAX+1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
所以的输入设备都需要上报同步事件,上报的同步事件通常是 SYN_REPORT,而 value 值通常为 0。
⚫ code:code 表示该类事件中的哪一个具体事件,譬如一个键盘上通常有很多按键,譬如字母 A、B、C、D 或者数字 1、2、3、4 等,而 code变量则告知应用程序是哪一个按键发生了输入事件
⚫ value:内核每次上报事件都会向应用层发送一个数据 value,对 value 值的解释随着 code 的变化而变化。如果 value 等于 1,则表示 KEY_1 键按下;value 等于 0 表示 KEY_1 键松开。
触摸屏看文档吧,懒得写~
网络基础知识
网络通信概述、OSI 七层模型、IP 地址、TCP/IP 协议族、TCP 和 UDP 协议等等
网络通信概述
网络通信本质上是一种进程间通信,是位于网络中不同主机上的进程之间的通信,属于 IPC 的一种, 通常称为 socket IPC
 网络数据的传输媒介有很多种,大体上分为有线传输(譬如双绞线网线、光纤等)和无线传输(譬如 WIFI、蓝牙、ZigBee、4G/5G/GPRS 等)
网络数据的传输媒介有很多种,大体上分为有线传输(譬如双绞线网线、光纤等)和无线传输(譬如 WIFI、蓝牙、ZigBee、4G/5G/GPRS 等)
在内核层,提供了网卡驱动程序,可以驱动底层网卡硬件设备,同时向应用层提供 socket 接口。
在应用层,应用程序基于内核提供的 socket 接口进行应用编程,实现自己的网络应用程序。
除了 socket 接口之外,在应用层通常还会使用一些更为高级的编程接口,譬如 http、网络控件等,那么这些接口实际上是对 socket 接口的一种更高级别的封装。
网络互连模型:OSI 七层模型
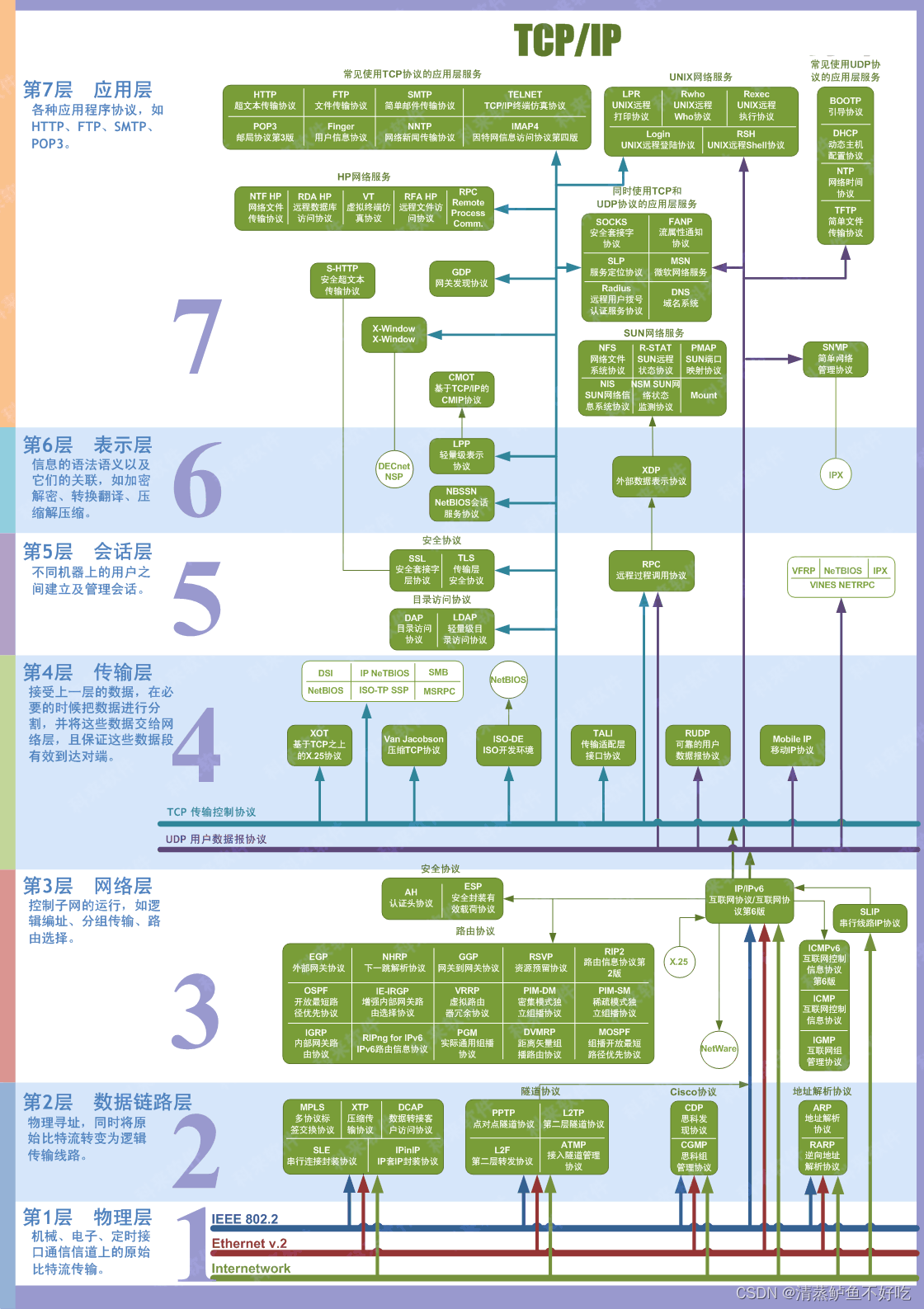 物理层
物理层
物理层的作用是实现相邻计算机节点之间比特流的透明传送,==尽可能屏蔽掉具体传输介质和物理设备的差异。==使数据链路层不必考虑网络的具体传输介质是什么。
数据链路层
数据链路层的具体工作是接收来自物理层的位流形式的数据,并封装成帧,传送到上一层;同样,也将来自上层的数据帧,拆装为位流形式的数据转发到物理层;并且,还负责处理接收端发回的确认帧的信息,以便提供可靠的数据传输。
数据链路层又分为 2 个子层:逻辑链路控制子层(LLC)和媒体访问控制子层(MAC)。MAC 子层的主要任务是解决共享型网络中多用户对信道竞争的问题,完成网络介质的访问控制;LLC 子层的主要任务是建立和维护网络连接,执行差错校验、流量控制和链路控制。
网络层(IP层)
本层通过 IP 寻址来建立两个节点之间的连接,为源端发送的数据包选择合适的路由和交换节点,正确无误地按照地址传送给目的端的运输层。
该层包含的协议有:IP(Ipv4、Ipv6)、ICMP、IGMP 等。
传输层
传输层(Transport Layer)定义传输数据的协议端口号,以及端到端的流控和差错校验。传输层的作用是为上层协议提供端到端的可靠和透明的数据传输服务,包括差错校验处理和流控等问题。
TCP、UDP 协议就工作在这一层,端口号既是这里的“端”。
会话层
会话层就是负责建立、管理和终止表示层实体之间的通信会话。
==不同实体之间表示层的连接称为会话。==因此会话层的任务就是组织和协调两个会话进程之间的通信
表示层
表示层(Presentation Layer)提供各种用于应用层数据的编码和转换功能,确保一个系统的应用层发送的数据能被另一个系统的应用层识别。
数据压缩/解压缩和加密/解密(提供网络的安全性)也是表示层可提供的功能之一。
应用层
我们常见应用层的网络服务协议有:HTTP、FTP、TFTP、SMTP、SNMP、DNS、TELNET、HTTPS、POP3、DHCP。
TCP/IP 四层/五层模型
事实上,TCP/IP 模型是 OSI 模型的简化版本


数据的封装与拆封

IP 地址
Internet 依靠 TCP/IP 协议,在全球范围内实现不同硬件结构、不同操作系统、不同网络系统的主机之间的互联
只有合法的 IP 地址才能接入互联网中并且与其他主机进行网络通信,IP 地址是软件地址,不是硬件地址,硬件 MAC 地址是存储在网卡中的,应用于局域网中寻找目标主机。
IP 地址的分类
根据 IP 地址中网络地址和主机地址两部分分别占多少位的不同,将 IP 地址划分为 5 类
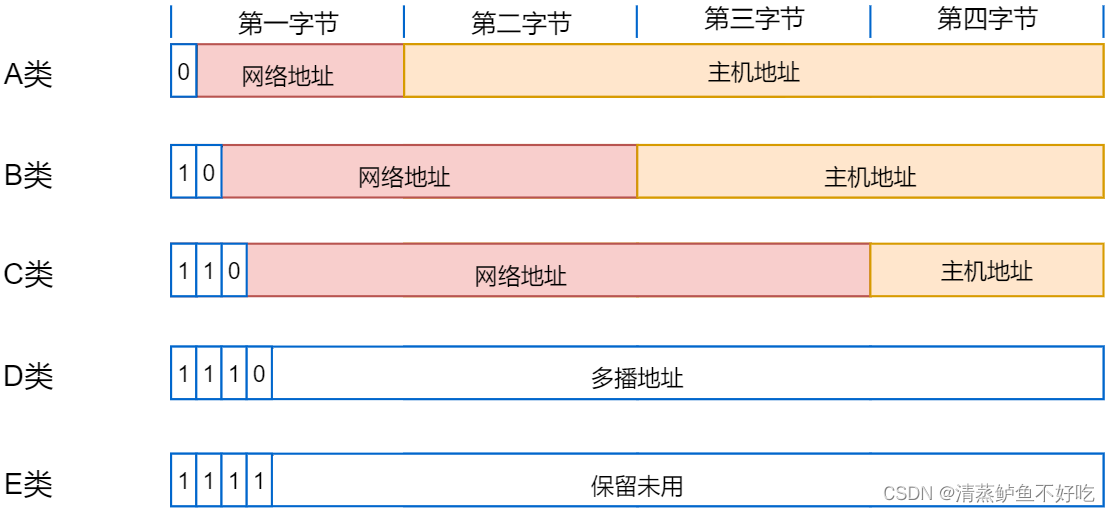 以上就给大家介绍了这 5 类 IP 地址,其中在 A、B、C 三类地址中,各保留了一个区域作为私有地址:
以上就给大家介绍了这 5 类 IP 地址,其中在 A、B、C 三类地址中,各保留了一个区域作为私有地址:
A 类地址:10.0.0.0~10.255.255.255。默认网络掩码为:255.0.0.0
A 类地址分配给规模特别大的网络使用。A 类地址用第一组数字表示网络地址,后面三组数字作为连接于网络上的主机对应的地址。分配给具有大量主机而局域网络个数较少的大型网络,譬如 IBM 公司的网络。
B 类地址:172.16.0.0~172.31.255.255。默认网络掩码为:255.255.0.0
B 类地址分配给一般的中型网络。B 类地址用第一、二组数字表示网络地址,后面两组数字代表网络上的主机地址。
C 类地址:192.168.0.0~192.168.255.255。默认网络掩码为:255.255.255.0
C 类地址分配给小型网络,如一般的局域网和校园网
A 类地址的第一组数字为 1~126。
B 类地址的第一组数字为 128~191。
C 类地址的第一组数字为 192~223。
特殊的 IP 地址
1.直接广播(Direct Broadcast Address):向某个网络上所有的主机发送报文。
A、B、C 三类地址的广播地址结构如下:
⚫ A 类地址的广播地址为: XXX.255.255.255 (XXX 为 A 类地址中网络地址对应的取值范围,譬如:120.255.255.255)。
⚫ B 类地址的广播地址为:XXX.XXX.255.255(XXX 为 B 类地址中网络地址的取值范围,譬如139.22.255.255)。
⚫ C 类地址的广播地址为:XXX.XXX.XXX.255(XXX 为 C 类地址中网络地址的取值范围,譬如203.120.16.255)。
2.受限广播地址
受限广播地址是在本网络内部进行广播的一种广播地址,TCP/IP 规定,32 比特全为“1”的 IP 地址用于本网络内的广播,也就是 255.255.255.255。
3.多播地址
多播地址用在一对多的通信中,即一个发送者,多个接收者,不论接受者数量的多少,发送者只发送一次数据包。
4.环回地址
环回地址(Loopback Address)是用于网络软件测试以及本机进程之间通信的特殊地址。把 A 类地址中的 127.XXX.XXX.XXX 的所有地址都称为环回地址
主要用来测试网络协议是否工作正常的作用。比如在电脑中使用 ping 命令去 ping 127.1.1.1 就可以测试本地 TCP/IP 协议是否正常。
5)0.0.0.0 地址
IP 地址 32bit 全为 0 的地址(也就是 0.0.0.0)表示本网络上的本主机,只能用作源地址。
监听 0.0.0.0 的端口,就是监听本机中所有 IP 的端口。
如何判断 2 个 IP 地址是否在同一个网段内
网络标识 = IP 地址 & 子网掩码
2 个 IP 地址的网络标识相同,那么它们就处于同一网络。譬如 192.168.1.50 和 192.168.1.100,这 2 个都是 C 类地址,对应的子网掩码为 255.255.255.0,很明显,这两个 IP 地址与子网掩码进行按位与操作时得到的结果(网络标识)是一样的,所以它们处于同一网络。
TCP/IP 协议
TCP/IP 协议它其实是一个协议族,包含了众多的协议,譬如应用层协议 HTTP、FTP、MQTT…以及传输层协议 TCP、UDP 等这些都属于 TCP/IP 协议
所以,我们一般说 TCP/IP 协议,它不是指某一个具体的网络协议,而是一个协议族
HTTP 协议
HTTP 超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP 是万维网数据通信的基础。HTTP 的应用最为广泛,譬如大家经常会打开网页浏览器查询资料,通过浏览器便可开启 HTTP 通信。
HTTP 协议工作于客户端(用户)、服务器端(网站)模式下,浏览器作为 HTTP 客户端通过 URL 向HTTP 服务端即 WEB 服务器发送请求。Web 服务器根据接收到的请求后,向客户端发送响应信息。借助这种浏览器和服务器之间的 HTTP 通信,我们能够足不出户地获取网络中的各种信息。
FTP 协议
FTP 协议的英文全称为 File Transfer Protocol,简称为 FTP,它是一种文件传输协议,从一个主机向一个主机传输文件的协议
FTP 协议同样也是基于客户端-服务器模式,在客户端和服务器之间进行文件传输
TCP 协议
关于 TCP 协议我们需要理解的重点如下:
①、TCP 协议工作在传输层,对上服务 socket 接口,对下调用 IP 层;
②、 TCP 是一种面向连接的传输协议,通信之前必须通过三次握手与客户端建立连接关系后才可通信;
③、TCP 协议提供可靠传输,不怕丢包、乱序。
TCP 协议如何保证可靠传输?
①、TCP 协议采用发送应答机制,即发送端发送的每个 TCP 报文段都必须得到接收方的应答,才能认为这个 TCP 报文段传输成功。
②、TCP 协议采用超时重传机制,发送端在发送出一个 TCP 报文段之后启动定时器,如果在定时时间内未收到应答,它将重新发送该报文段。
③、由于 TCP 报文段最终是以 IP 数据报发送的,而 IP 数据报到达接收端可能乱序、重复、所以 TCP协议还会将接收到的 TCP 报文段重排、整理、再交付给应用层。
TCP 协议的特性
⚫面向连接的
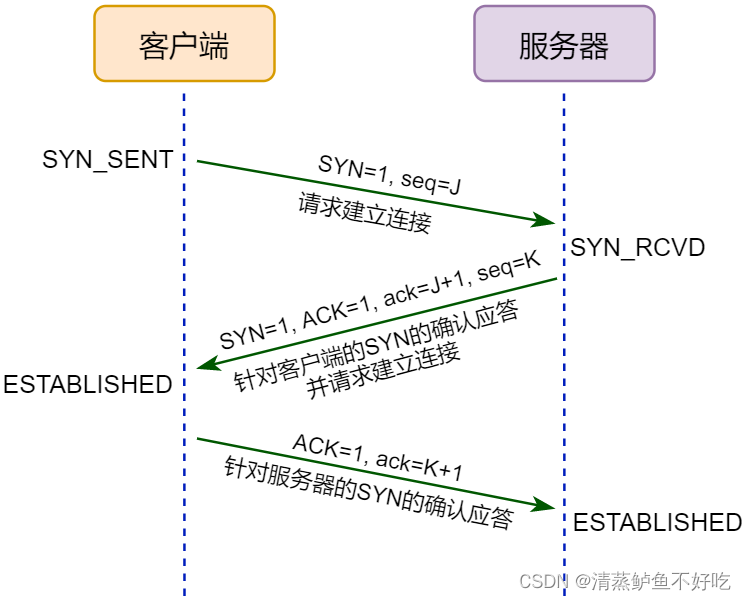
TCP 是一个面向连接的协议,无论哪一方向另一方发送数据之前,都必须先在双方之间建立一个 TCP连接,否则将无法发送数据,通过三次握手建立连接
⚫确认与重传
当数据从主机 A 发送到主机 B 时,主机 B 会返回给主机 A 一个确认应答
在一定的时间内如果没有收到确认应答,发送端就可以认为数据已经丢失,并进行重发。由此,即使产生了丢失,仍然可以保证数据能够到达对端,实现可靠传输。
⚫全双工通信
TCP 连接一旦建立,就可以在连接上进行双向的通信。
⚫基于字节流而非报文
将数据按字节大小进行编号,接收端通过 ACK 来确认收到的数据编号
⚫流量控制(滑动窗口协议)
TCP 流量控制主要是针对接收端的处理速度不如发送端发送速度快的问题,消除发送方使接收方缓存溢出的可能性。
滑动窗口是接受数据端使用的窗口大小,用来告诉发送端接收端的缓存大小,以此可以控制发送端发送数据的大小,从而达到流量控制的目的。
对所有数据帧按顺序赋予编号,发送方在发送过程中始终保持着一个发送窗口,只有落在发送窗口内的帧才允许被发送;同时接收方也维持着一个接收窗口,只有落在接收窗口内的帧才允许接收。
⚫差错控制
TCP 协议除了确认应答与重传机制外,TCP 协议也会采用校验和的方式来检验数据的有效性,主机在接收数据的时候,会将重复的报文丢弃,将乱序的报文重组,发现某段报文丢失了会请求发送方进行重发,因此在 TCP 往上层协议递交的数据是顺序的、无差错的完整数据。
⚫拥塞控制
如果网络上的负载(发送到网络上的分组数)大于网络上的容量(网络同时能处理的分组数),就可能引起拥塞
判断网络拥塞的两个因素:延时和吞吐量。
拥塞控制机制是:开环(预防)和闭环(消除)。
TCP 拥塞控制的几种方法:慢启动,拥塞避免,快重传和快恢复。
TCP 报文格式
当数据由上层发送到传输层时,数据会被封装为 TCP 数据段,我们将其称为 TCP 报文(或 TCP 报文段),TCP 报文由 TCP 首部+数据区域组成,一般 TCP 首部通常为 20 个字节大小

建立 TCP 连接:三次握手
 关闭 TCP 连接:四次挥手
关闭 TCP 连接:四次挥手
四次挥手即终止 TCP 连接,就是指断开一个 TCP 连接时,需要客户端和服务端总共发送 4 个包以确认连接的断开。在 socket 编程中,这一过程由客户端或服务端任一方执行 close 来触发。
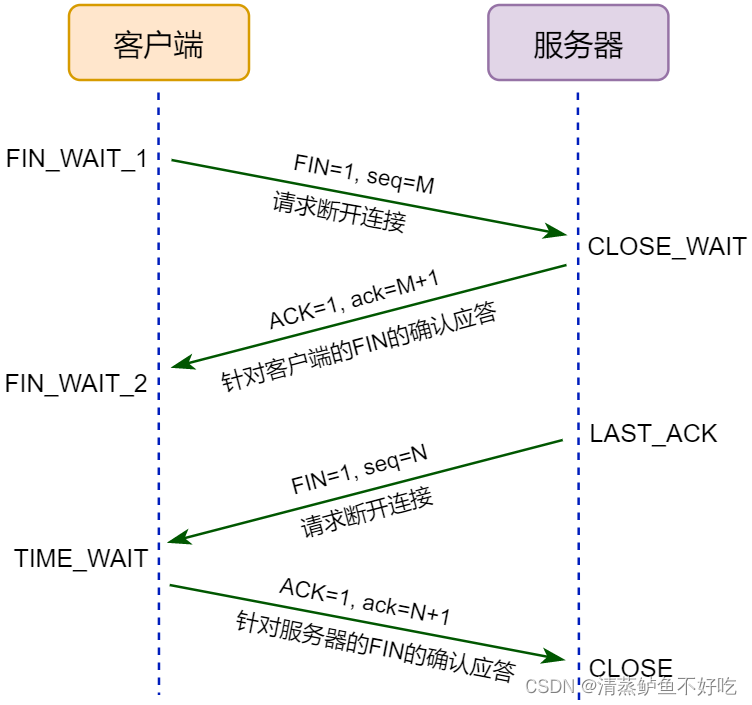 由于 TCP 连接是全双工的,因此,每个方向都必须要单独进行关闭
由于 TCP 连接是全双工的,因此,每个方向都必须要单独进行关闭
当一方完成数据发送任务后,发送一个 FIN 来终止这一方向的连接,收到一个 FIN 只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个 TCP 连接上仍然能够发送数据,直到这一方向也发送了 FIN。
所以 TCP 协议传输数据的整个过程就如同下图所示:
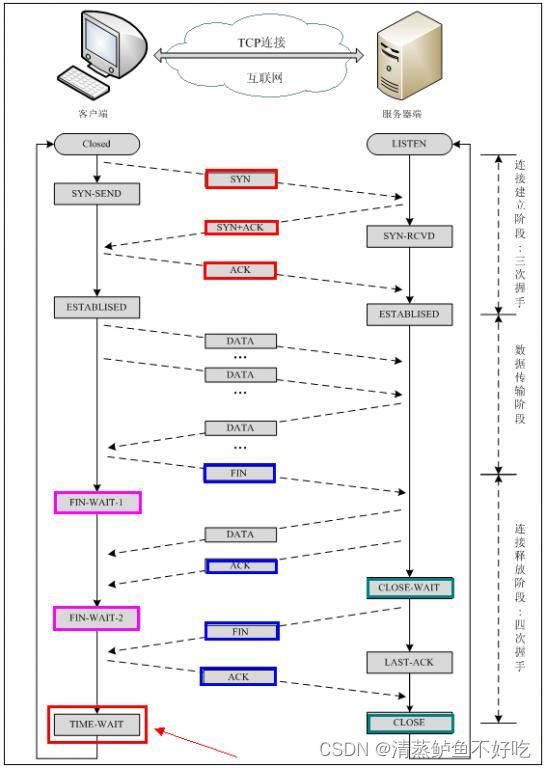
UDP 协议
UDP 是 User Datagram Protocol 的简称,中文名是用户数据报协议,是一种无连接、不可靠的协议,同样它也是工作在传输层。
它只是简单地实现从一端主机到另一端主机的数据传输功能,这些数据通过 IP 层发送,在网络中传输,到达目标主机的顺序是无法预知的
UDP 协议的特点:
①、无连接、不可靠;
②、尽可能提供交付数据服务,出现差错直接丢弃,无反馈;
③、面向报文,发送方的 UDP 拿到上层数据直接添加个 UDP 首部,然后进行校验后就递交给 IP 层,而接收的一方在接收到 UDP 报文后简单进行校验,然后直接去除数据递交给上层应用;
④、速度快,因为 UDP 协议没有 TCP 协议的握手、确认、窗口、重传、拥塞控制等机制,UDP 是一个无状态的传输协议,所以它在传递数据时非常快,即使在网络拥塞的时候 UDP 也不会降低发送的数据。
它的实时性是非常好,常用于实时视频的传输,比如直播、网络电话等,因为即使是出现了数据丢失的情况,导致视频卡帧,这也不是什么大不了的事情
端口号的概念
一台主机通常只有一个 IP 地址,但主机上运行的网络进程却通常不止一个,譬如 Windows 电脑上运行着 QQ、微信、钉钉、网页浏览器等,这些进程都需要进行网络连接,它们都可通过网络发送/接收数据。通常端口号来确定
端口号用来在一台主机中唯一标识一个能上网(能够进行网络通信)的进程,端口号的取值范围为 0~65535。

socket 编程基础
socket是内核向应用层提供的一套网络编程接口,用户基于 socket 接口可开发自己的网络相关应用程序。
进程间通信机制(socket IPC)。socket IPC 通常使用客户端<—>服务器这种模式完成通信,多个客户端可以同时连接到服务器中,与服务器之间完成数据交互。
socket 编程接口介绍
包含两个头文件:
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
socket()函数
int socket(int domain, int type, int protocol);
socket()函数类似于 open()函数,它用于创建一个网络通信端点(打开一个网络通信),如果成功则返回一个网络文件描述符,通常把这个文件描述符称为 socket 描述符(socket descriptor)
该函数包括 3 个参数,如下所示:


bind()函数
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
bind()函数用于将一个 IP 地址或端口号与一个套接字进行绑定(将套接字与地址进行关联)。
调用 bind()函数将参数 sockfd 指定的套接字与一个地址 addr 进行绑定,成功返回 0,失败情况下返回-1
struct sockaddr {
sa_family_t sa_family;
char sa_data[14];
}
struct sockaddr_in {
sa_family_t sin_family; /* 协议族 */
in_port_t sin_port; /* 端口号 */
struct in_addr sin_addr; /* IP 地址 */
unsigned char sin_zero[8];
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
一般我们在使用的时候都会使用 struct sockaddr_in 结构体。指向 sockaddr_in 的结构体的指针也可以指向 sockadd 的结构体,并代替它
使用示例
struct sockaddr_in socket_addr; memset(&socket_addr, 0x0, sizeof(socket_addr)); //清零 int socket_fd = socket(AF_INET, SOCK_STREAM, 0);//打开套接字 if (0 > socket_fd) { perror("socket error"); exit(-1); } //填充变量 socket_addr.sin_family = AF_INET; socket_addr.sin_addr.s_addr = htonl(INADDR_ANY); socket_addr.sin_port = htons(5555); //将地址与套接字进行关联、绑定 bind(socket_fd, (struct sockaddr *)&socket_addr, sizeof(socket_addr)); close(socket_fd); //关闭套接字
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
listen()函数
listen()函数只能在服务器进程中使用,让服务器进程进入监听状态,等待客户端的连接请求
一般在 bind()函数之后调用,在 accept()函数之前调用
int listen(int sockfd, int backlog);
无法在一个已经连接的套接字执行 listen()。
参数 backlog 用来描述 sockfd 的等待连接队列能够达到的最大值。内核会在自己的进程空间里维护一个队列,这些连接请求就会被放入一个队列中,服务器进程会按照先来后到的顺序去处理这些连接请求
当一个客户端的连接请求到达并且该队列为满时,客户端可能会收到一个表示连接失败的错误,本次请求会被丢弃不作处理。
accept()函数
服务器调用 listen()函数之后,就会进入到监听状态,等待客户端的连接请求,使用 accept()函数获取客户端的连接请求并建立连接。
如果调用 accept()函数时,并没有客户端请求连接(等待连接队列中也没有等待连接的请求),此时 accept()会进入阻塞状态,直到有客户端连接请求到达为止。
当有客户端连接请求到达时,accept()函数与远程客户端之间建立连接,accept()函数返回一个新的套接字。这个套接字代表了服务器与客户端的一个连接。
==参数 addr 是一个传出参数,参数 addr 用来返回已连接的客户端的 IP 地址与端口号等这些信息。==可以把 arrd 和 addrlen 均置为空指针 NULL。
为了能够正常让客户端能正常连接到服务器,服务器必须遵循以下处理流程:
①、调用 socket()函数打开套接字;
②、调用 bind()函数将套接字与一个端口号以及 IP 地址进行绑定;
③、调用 listen()函数让服务器进程进入监听状态,监听客户端的连接请求;
④、调用 accept()函数处理到来的连接请求。
下面这个是客户端的函数
connect()函数
客户端调用 connect()函数将套接字 sockfd 与远程服务器进行连接,参数 addr 指定了待连接的服务器的 IP 地址以及端口号等信息
客户端通过 connect()函数请求与服务器建立连接,对于 TCP 连接来说,调用该函数将发生 TCP 连接的握手过程,并最终建立一个 TCP 连接,
而对于 UDP 协议来说,调用这个函数只是在 sockfd 中记录服务器IP 地址与端口号,而不发送任何数据。
发送和接收函数
一旦客户端与服务器建立好连接之后,我们就可以通过套接字描述符来收发数据了
可以调用 read()或 recv()函数读取网络数据,调用 write()或 send()函数发送


IP 地址格式转换函数
对于人来说,我们更容易阅读的是点分十进制的 IP 地址,譬如 192.168.1.110、192.168.1.50,这其实是一种字符串的形式,
但是计算机所需要理解的是二进制形式的 IP 地址,所以我们就需要在点分十进制字符串和二进制地址之间进行转换。
点分十进制字符串和二进制地址之间的转换函数主要有:inet_aton、inet_addr、inet_ntoa、inet_ntop、inet_pton 这 五 个 , 在 我 们 的 应 用 程 序 中 使 用 它 们 需 要 包 含 头 文 件 <sys/socket.h> 、 <arpa/inet.h> 以 及<netinet/in.h>。


#include <stdio.h> #include <stdlib.h> #include <arpa/inet.h> #define IPV4_ADDR "192.168.1.222" int main(void) { struct in_addr addr; inet_pton(AF_INET, IPV4_ADDR, &addr); printf("ip addr: 0x%x\n", addr.s_addr); exit(0); } int main(void) { struct in_addr addr; char buf[20] = {0}; addr.s_addr = 0xde01a8c0; inet_ntop(AF_INET, &addr, buf, sizeof(buf)); printf("ip addr: %s\n", buf); exit(0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
socket 编程实战
编写服务器应用程序的流程如下:
①、调用 socket()函数打开套接字,得到套接字描述符;
②、调用 bind()函数将套接字与 IP 地址、端口号进行绑定;
③、调用 listen()函数让服务器进程进入监听状态;
④、调用 accept()函数获取客户端的连接请求并建立连接;
⑤、调用 read/recv、write/send 与客户端进行通信;
⑥、调用 close()关闭套接字。
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <sys/socket.h> #include <arpa/inet.h> #include <netinet/in.h> #define SERVER_PORT 8888 //端口号不能发生冲突,不常用的端口号通常大于 5000 int main(void) { struct sockaddr_in server_addr = {0}; struct sockaddr_in client_addr = {0}; char ip_str[20] = {0}; int sockfd, connfd; int addrlen = sizeof(client_addr); char recvbuf[512]; int ret; /* 打开套接字,得到套接字描述符 */ sockfd = socket(AF_INET, SOCK_STREAM, 0); if (0 > sockfd) { perror("socket error"); exit(EXIT_FAILURE); } /* 将套接字与指定端口号进行绑定 */ server_addr.sin_family = AF_INET; server_addr.sin_addr.s_addr = htonl(INADDR_ANY); server_addr.sin_port = htons(SERVER_PORT); ret = bind(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr)); if (0 > ret) { perror("bind error"); close(sockfd); exit(EXIT_FAILURE); } /* 使服务器进入监听状态 */ ret = listen(sockfd, 50); if (0 > ret) { perror("listen error"); close(sockfd); exit(EXIT_FAILURE); } /* 阻塞等待客户端连接 */ connfd = accept(sockfd, (struct sockaddr *)&client_addr, &addrlen); if (0 > connfd) { perror("accept error"); close(sockfd); exit(EXIT_FAILURE); printf("有客户端接入...\n"); inet_ntop(AF_INET, &client_addr.sin_addr.s_addr, ip_str, sizeof(ip_str)); printf("客户端主机的 IP 地址: %s\n", ip_str); printf("客户端进程的端口号: %d\n", client_addr.sin_port); /* 接收客户端发送过来的数据 */ for ( ; ; ) { // 接收缓冲区清零 memset(recvbuf, 0x0, sizeof(recvbuf)); // 读数据 ret = recv(connfd, recvbuf, sizeof(recvbuf), 0); if(0 >= ret) { perror("recv error"); close(connfd); break; } // 将读取到的数据以字符串形式打印出来 printf("from client: %s\n", recvbuf); // 如果读取到"exit"则关闭套接字退出程序 if (0 == strncmp("exit", recvbuf, 4)) { printf("server exit...\n"); close(connfd); break; } } /* 关闭套接字 */ close(sockfd); exit(EXIT_SUCCESS); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
编写客户端程序
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <sys/types.h> #include <sys/socket.h> #include <arpa/inet.h> #include <netinet/in.h> #define SERVER_PORT 8888 #define SERVER_IP "192.168.1.150" //服务器的端口号 //服务器的 IP 地址 int main(void) { struct sockaddr_in server_addr = {0}; char buf[512]; int sockfd; int ret; /* 打开套接字,得到套接字描述符 */ sockfd = socket(AF_INET, SOCK_STREAM, 0); if (0 > sockfd) { perror("socket error"); exit(EXIT_FAILURE); } /* 调用 connect 连接远端服务器 */ server_addr.sin_family = AF_INET; server_addr.sin_port = htons(SERVER_PORT); //端口号 inet_pton(AF_INET, SERVER_IP, &server_addr.sin_addr);//IP 地址 ret = connect(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr)); if (0 > ret) { perror("connect error"); close(sockfd); exit(EXIT_FAILURE); } printf("服务器连接成功...\n\n"); /* 向服务器发送数据 */ for ( ; ; ) { // 清理缓冲区 memset(buf, 0x0, sizeof(buf)); // 接收用户输入的字符串数据 printf("Please enter a string: "); fgets(buf, sizeof(buf), stdin); // 将用户输入的数据发送给服务器 ret = send(sockfd, buf, strlen(buf), 0); if(0 > ret){ perror("send error"); break; } //输入了"exit",退出循环 if(0 == strncmp(buf, "exit", 4)) break; } close(sockfd); exit(EXIT_SUCCESS); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
CMake 入门与进阶
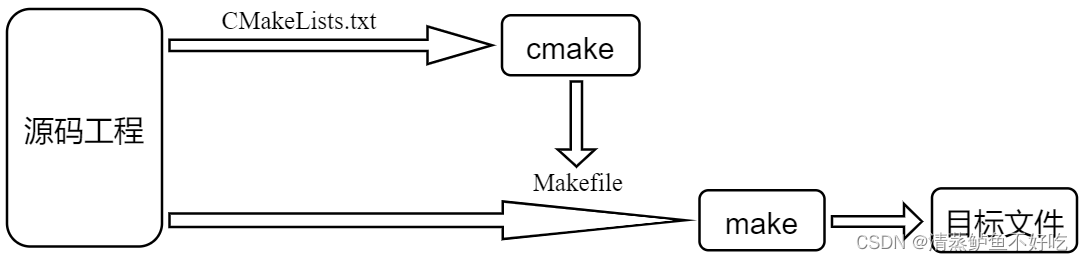
一个工程中可能包含几十、成百甚至上千个源文件,这些源文件按照其类型、功能、模块分别放置在不同的目录中;面对这样的一个工程,通常会使用 make 工具进行管理、编译,make 工具依赖于 Makefile 文件,通过 Makefile 文件来定义整个工程的编译规则
大都数的 IDE 都有这个工具,譬如 Visual C++的 nmake、linux 下的 GNU make、Qt 的 qmake 等等,这些 make 工具遵循着不同的规范和标准,对应的 Makefile 文件其语法、格式也不相同
而 cmake 就是针对这个问题所诞生,允许开发者编写一种与平台无关的 CMakeLists.txt 文件来制定整个工程的编译流程,再根据具体的编译平台,生成本地化的 Makefile 和工程文件,最后执行 make 编译。
因此,对于大多数项目,我们应当考虑使用更自动化一些的 cmake 或者 autotools 来生成 Makefile
cmake 简介
cmake 是一个跨平台的自动构建工具。cmake 的诞生主要是为了解决直接使用 make+Makefile 这种方式无法实现跨平台的问题
cmake 还包含以下优点:
⚫ 开放源代码。我们可以直接从 cmake 官网 https://cmake.org/下载到它的源代码;
⚫ 跨平台。cmake 仅仅只是根据不同平台生成对应的 Makefile,最终还是通过 make工具来编译工程源码,但是 cmake 却是跨平台的。
⚫ 语法规则简单
 除了 cmake 之外,还有一些其它的自动构建工具,常用的譬如 automake、autoconf 等
除了 cmake 之外,还有一些其它的自动构建工具,常用的譬如 automake、autoconf 等
cmake 的使用方法
cmake 就是一个工具命令,在 Ubuntu 系统下通过 apt-get 命令可以在线安装,如下所示:
sudo apt-get install cmake
安装完成之后可以通过 cmake --version 命令查看 cmake的版本号
1)现在我们需要新建一个 CMakeLists.txt 文件, CMakeLists.txt 文件会被 cmake 工具解析,就好比是 Makefile文件会被 make 工具解析一样;CMakeLists.txt 创建完成之后,在文件中写入如下内容:
project(HELLO)
add_executable(hello ./main.c)
2)接着我们在工程目录下直接执行
cmake 命令,如下所示:cmake ./
3)执行完 cmake 之后,除了源文件 main.c 和 CMakeLists.txt 之外,可以看到当前目录下生成了很多其它的文件或文件夹,包括:CMakeCache.txt、CmakeFiles、cmake_install.cmake、Makefile,重点是生成了这个Makefile 文件,有了 Makefile 之后,接着我们使用 make 工具编译我们的工程
通过 file 命令可以查看到 hello 是一个 x86-64 架构下的可执行文件,所以只能在我们的 UbuntuPC 上运行
CMakeLists.txt 文件
⚫ 第一行 project(HELLO)
project 命令用于设置工程的名称,括号中的参数 HELLO 便是我们要设置的工程名称;设置工程名称并不是强制性的,但是最好加上。
⚫ 第二行 add_executable(hello ./main.c)
add_executable 同样也是一个命令,用于生成一个可执行文件。
第一个参数表示生成的可执行文件对应的文件名,第二个参数表示对应的源文件
使用 out-of-source 方式构建
在上面的例子中,工程看起来非常乱。我们需要将构建过程生成的文件与源文件分离开来,不让它们混杂在一起,也就是使用 out-of-source 方式构建。
示例一:单个源文件
1)在工程目录下创建一个 build 目录
2)然后进入到 build 目录下执行 cmake:
cd build/
cmake …/
make
示例二:多个源文件
1)准备好 CMakeLists.txt 文件
project(HELLO)
set(SRC_LIST main.c hello.c) //set 命令用于设置变量,如果变量不存在则创建该变量并设置它;在本例中,我们定义了一个 SRC_LIST 变量,SRC_LIST 变量是一个源文件列表,记录生成可执行文件 hello 所需的源文件 main.c 和 hello.c
add_executable(hello ${SRC_LIST})
- 1
- 2
- 3
2)进入到 build 目录下,执行 cmake、再执行 make 编译工程
当然我们也可以不去定义 SRC_LIST 变量,直接将源文件列表写在 add_executable 命令中,如下:
add_executable(hello main.c hello.c)
示例三:生成库文件
在示例二的基础上对 CMakeLists.txt 文件进行修改,如下所示:
project(HELLO)
add_library(libhello hello.c)
add_executable(hello main.c)
target_link_libraries(hello libhello) //target_link_libraries 命令为目标指定依赖库,在本例中,hello.c 被编译为库文件,并将其链接进 hello 程序。
- 1
- 2
- 3
- 4
本例中,add_library 命令生成了一个静态库文件 liblibhello.a,如果要生成动态库文件,可以这样做:
add_library(libhello SHARED hello.c) #生成动态库文件
add_library(libhello STATIC hello.c) #生成静态库文件
修改生成的库文件名字
本例中有一点非常不爽,生成的库为 liblibhello.a,名字非常不好看
实际上我们只需要在 CMakeLists.txt文件中添加下面这条命令即可:
set_target_properties(libhello PROPERTIES OUTPUT_NAME “hello”)
set_target_properties 用于设置目标 的属性,这里通 过 set_target_properties 命令 对libhello 目标 的OUTPUT_NAME 属性进行了设置,将其设置为 hello。
入到 build 目录下,使用 cmake+make 编译整个工程,编译完成之后会发现,生成的库文件为 libhello.a,而不是 liblibhello.a
示例四:将源文件组织到不同的目录

顶 层 CMakeLists.txt 中 使 用 了 add_subdirectory 命 令 , 该 命 令 告 诉 cmake 去 子 目 录 中 寻 找 新 的CMakeLists.txt 文件并解析它;
而在 src 的 CMakeList.txt 文件中,新增加了 include_directories 命令用来指明头文件所在的路径,并且使用到了 PROJECT_SOURCE_DIR 变量,该变量指向了一个路径,从命名上可知,该变量表示工程源码的目录。
示例五:将生成的可执行文件和库文件放置到单独的目录下
 其实实现这个需求非常简单,通过对 LIBRARY_OUTPUT_PATH 和 EXECUTABLE_OUTPUT_PATH变 量 进 行 设 置 即 可 完 成
其实实现这个需求非常简单,通过对 LIBRARY_OUTPUT_PATH 和 EXECUTABLE_OUTPUT_PATH变 量 进 行 设 置 即 可 完 成
CMakeLists.txt 语法规则
⚫注释
在 CMakeLists.txt 文件中,使用“#”号进行单行注释
⚫命令(command)
多个参数使用空格分隔而不是逗号“,”
在 CMakeLists.txt 中,命令名不区分大小写,可以使用大写字母或小写字母书写命令名,譬如:
project(HELLO) #小写
PROJECT(HELLO) #大写
⚫变量(variable)
在 CMakeLists.txt 文件中可以使用变量,使用 set 命令可以对变量进行设置,譬如:
#设置变量 MY_VAL
set(MY_VAL "Hello World!")
#引用变量 MY_VAL
message(${MY_VAL})
- 1
- 2
- 3
- 4
其他命令
 target_include_directories 和 target_link_libraries
target_include_directories 和 target_link_libraries
⚫ 当使用 PRIVATE 关键字修饰时,意味着包含目录列表仅用于当前目标;
⚫ 当使用 INTERFACE 关键字修饰时,意味着包含目录列表不用于当前目标、只能用于依赖该目标的其它目标,也就是说 cmake 会将包含目录列表传递给当前目标的依赖目标;
⚫ 当使用 PUBLIC 关键字修饰时,这就是以上两个的集合,包含目录列表既用于当前目标、也会传递给当前目标的依赖目标。
部分常用变量

改变行为的变量

控制编译的变量

双引号的作用
命令中多个参数之间使用空格进行分隔,而 cmake 会将双引号引起来的内容作为一个整体,当它当成一个参数,假如你的参数中有空格(空格是参数的一部分),那么就可以使用双引号,如下所示:
message(Hello World)
message(“Hello World”)
输出
HelloWorld
而第二个 message 命令只有一个参数,所以打印信息如下:
Hello World
引用变量
MY_LIST 是一个列表,
M
Y
L
I
S
T
是一个列表,我们用
"
{MY_LIST}是一个列表,我们用"
MYLIST是一个列表,我们用"{MY_LIST}"这种形式的时候,表示要让 CMake 把这个数组的所有元素当成一个整体,而不是分散的个体。于是,为了保持数组的含义,又提供一个整体的表达方式,CMake 就会用分号“;”把这数组的多个元素连接起来。
条件判断
在 cmake 中可以使用条件判断,条件判断形式如下:
if(expression) # then section. command1(args ...) command2(args ...) ... elseif(expression2) # elseif section. command1(args ...) command2(args ...) ... else(expression) # else section. command1(args ...) command2(args ...) ... endif(expression)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
循环语句
包括 foreach()循环、while()循环。
①、foreach 基本用法
# foreach 循环测试
set(my_list hello world china)
foreach(loop_var ${my_list})
message("${loop_var}")
endforeach() //也可以endforeach(loop_var)
- 1
- 2
- 3
- 4
- 5
②、foreach 循环之 RANGE 关键字
用法如下所示:
foreach(loop_var RANGE stop)
foreach(loop_var RANGE start stop [step])
对于第一种方式,循环会从 0 到指定的数字 stop
而对于第二种,循环从指定的数字 start 开始到 stop 结束
③、foreach 循环之 IN 关键字
用法如下:
foreach(loop_var IN [LISTS [list1 […]]]
[ITEMS [item1 […]]])
循环列表中的每一个元素,或者直接指定元素。
二、while 循环
while 循环用法如下:
while(condition)
command1(args ...)
command1(args ...)
...
endwhile(condition)
- 1
- 2
- 3
- 4
- 5
endwhile 括号中的 condition 可写可不写,如果写了,就必须和 while 中的 condition 一致。
三、break、continue
cmake 中,也可以在循环体中使用类似于 C 语言中的 break 和 continue 语句。
数学运算 math

cmake 进阶
定义函数
在 cmake 中我们也可以定义函数, cmake 提供了 function()命令用于定义一个函数,使用方法如下所示:
function(<name> [arg1 [arg2 [arg3 ...]]])
command1(args ...)
command2(args ...)
...
endfunction(<name>)
- 1
- 2
- 3
- 4
- 5
①、基本使用方法
第一个参数 name 表示函数的名字,arg1、arg2…表示传递给函数的参数
 ⑤、函数的作用域
⑤、函数的作用域
通过 function()定义的函数它的使用范围是全局的,并不局限于当前源码、可以在其子源码或者父源码中被使用。
文件操作
cmake 提供了 file()命令可对文件进行一系列操作,譬如读写文件、删除文件、文件重命名、拷贝文件、创建目录等等
# file()写文件测试 file(WRITE wtest.txt "Hello World!")#给定内容生成 wtest.txt 文件 file(APPEND wtest.txt " China")#给定内容追加到 wtest.txt 文件末尾 # 由前面生成的 wtest.txt 中的内容去生成 out1.txt 文件 file(GENERATE OUTPUT out1.txt INPUT "${PROJECT_SOURCE_DIR}/wtest.txt") # 由指定的内容生成 out2.txt file(GENERATE OUTPUT out2.txt CONTENT "This is the out2.txt file") # 由指定的内容生成 out3.txt,加上条件控制,用户可根据实际情况 # 用表达式判断是否需要生成文件,这里只是演示,直接是 1 file(GENERATE OUTPUT out3.txt CONTENT "This is the out3.txt file" CONDITION 1) # file()读文件测试 file(READ "${PROJECT_SOURCE_DIR}/wtest.txt" out_var) #读取前面生成的 wtest.txt的内容到out_var message(${out_var}) # 打印输出 # 读取 wtest.txt 文件:限定起始字节和大小 file(READ "${PROJECT_SOURCE_DIR}/wtest.txt" out_var OFFSET 0 LIMIT 10) message(${out_var}) # 读取 wtest.txt 文件:以二进制形式读取,限定起始字节和大小, file(READ "${PROJECT_SOURCE_DIR}/wtest.txt" out_var OFFSET 0 LIMIT 5 HEX) message(${out_var})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
④、以字符串形式读取
file(STRINGS […])
从文件中解析 ASCII 字符串列表并将其存储在中。这个命令专用于读取字符串,会将文件中的二进制数据将被忽略,回车符(\r, CR)字符被忽略。
options:可选的参数,可选择 0 个、1 个或多个选项,这些选项包括:
➢ LENGTH_MAXIMUM :读取的字符串的最大长度;
➢ LENGTH_MINIMUM :读取的字符串的最小长度;
➢ LIMIT_COUNT :读取的行数;
➢ LIMIT_INPUT :读取的字节数;
➢ LIMIT_OUTPUT :存储到变量的限制字节数;
➢ NEWLINE_CONSUME:把换行符也考虑进去;
➢ NO_HEX_CONVERSION:除非提供此选项,否则 Intel Hex 和 Motorola S-record 文件在读取时会自动转换为二进制文件。
➢ REGEX :只读取符合正则表达式的行;
➢ ENCODING :指定输入文件的编码格式,目前支持的编码有: UTF-8、 UTF-16LE、UTF-16BE、UTF-32LE、UTF-32BE。如果未提供 ENCODING 选项并且文件具有字节顺序标记,则 ENCODING 选项将默认为尊重字节顺序标记。
⑤、计算文件的 hash 值
file()命令可以计算指定文件内容的加密散列(hash 值)并将其存储在变量中。命令格式如下所示:
file(<MD5|SHA1|SHA224|SHA256|SHA384|SHA512> )
MD5|SHA1|SHA224|SHA256|SHA384|SHA512 表示不同的计算 hash 的算法,必须要指定其中之一,
⑥、文件重命名
使用 file()命令可以对文件进行重命名操作,命令格式如下:
file(RENAME )
⑦、删除文件
使用 file()命令可以删除文件,命令格式如下:
file(REMOVE […])
file(REMOVE_RECURSE […])
REMOVE 选项将删除给定的文件,但不可以删除目录;
而 REMOVE_RECURSE 选项将删除给定的文件或目录、以及非空目录。
设置交叉编译
如果不设置交叉编译,默认情况下,cmake 会使用主机系统(运行 cmake 命令的操作系统)的编译器来编译我们的工程,那么得到的可执行文件或库文件
只能在 Ubuntu 系统运行,如果我们需要使得编译得到的可执行文件或库文件能够在我们的开发板(ARM 平台)上运行,则需要配置交叉编译
我们使用的交叉编译器如下:
arm-poky-linux-gnueabi-gcc #C 编译器
arm-poky-linux-gnueabi-g++ #C++编译器
其实配置交叉编译非常简单,只需要设置几个变量即可,如下所示:
# 配置 ARM 交叉编译 set(CMAKE_SYSTEM_NAME Linux)#设置目标系统名字 set(CMAKE_SYSTEM_PROCESSOR arm) #设置目标处理器架构 # 指定编译器的 sysroot 路径 set(TOOLCHAIN_DIR /opt/fsl-imx-x11/4.1.15-2.1.0/sysroots) set(CMAKE_SYSROOT ${TOOLCHAIN_DIR}/cortexa7hf-neon-poky-linux-gnueabi) # 指定交叉编译器 arm-gcc 和 arm-g++ set(CMAKE_C_COMPILER ${TOOLCHAIN_DIR}/x86_64-pokysdk-linux/usr/bin/arm-poky-linux-gnueabi/arm-poky-linux-gnueabi-gcc) set(CMAKE_CXX_COMPILER ${TOOLCHAIN_DIR}/x86_64-pokysdk-linux/usr/bin/arm-poky-linux-gnueabi/arm-poky-linux-gnueabi-g++) # 为编译器添加编译选项 set(CMAKE_C_FLAGS "-march=armv7ve -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7") set(CMAKE_CXX_FLAGS "-march=armv7ve -mfpu=neon -mfloat-abi=hard -mcpu=cortex-a7") set(CMAKE_FIND_ROOT_PATH_MODE_PROGRAM NEVER) set(CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY) set(CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这里要注意,配置 ARM 交叉编译的这些代码需要放置在 project()命令之前,否则不会生效!
上例中的这种交叉编译配置方式自然是没有问题的,但是不规范,通常的做法是,将这些配置项(也就是变量的设置)单独拿出来写在一个单独的配置文件中,而不直接写入到 CMakeLists.txt 源码中,然后在执行 cmake 命令时,指定配置文件给 cmake,让它去配置交叉编译环境。
如何指定配置文件呢?通过如下方式:
cmake -DCMAKE_TOOLCHAIN_FILE=cfg_file_path …
通过-DCMAKE_TOOLCHAIN_FILE 选项指定配置文件
在工程源码目录下创建一个配置文件 arm-linux-setup.cmake
二、目录作用域(Directory Scope)
目录作用域有两个特点:向下有效(上层作用域中定义的变量在下层作用域中是有效的),值拷贝
三、全局作用域(Persistent Cache 持久缓存、缓存变量)
属性
一、目录属性
目录属性其实就是 CMakeLists.txt 源码的属性
 CACHE_VARIABLES
CACHE_VARIABLES
当前目录中可用的缓存变量列表。
CLEAN_NO_CUSTOM
如果设置为 true 以告诉 Makefile Generators 在 make clean 操作期间不要删除此目录的自定义命令的输出文件。如何获取或设置属性稍后再给大家介绍。
INCLUDE_DIRECTORIES
此 属 性 是 目 录 的 头 文 件 搜 索 路 径 列 表 , 其 实 就 是 include_directories() 命 令 所 添 加 的 目 录
LINK_DIRECTORIES
此属性是目录的库文件搜索路径列表,其实就是 link_directories()命令所添加的目录
二、目标属性
目标属性,顾名思义就是目标对应的属性
BINARY_DIR
只读属性,定义目标的目录中 CMAKE_CURRENT_BINARY_DIR 变量的值。
SOURCE_DIR
只读属性,定义目标的目录中 CMAKE_CURRENT_SOURCE_DIR 变量的值。
INCLUDE_DIRECTORIES
目标的头文件搜索路径列表
NTERFACE_INCLUDE_DIRECTORIES
target_include_directories()命令使用 PUBLIC 和 INTERFACE 关键字的值填充此属性。
INTERFACE_LINK_LIBRARIES
target_link_libraries()命令使用 PUBLIC 和 INTERFACE 关键字的值填充此属性。
LIBRARY_OUTPUT_DIRECTORY
LIBRARY_OUTPUT_NAME
LINK_LIBRARIES
目标的链接依赖库列表。
OUTPUT_NAME
目标文件的输出名称。
TYPE
目 标 的 类 型 , 它 将 是 STATIC_LIBRARY 、 MODULE_LIBRARY 、 SHARED_LIBRARY 、INTERFACE_LIBRARY、EXECUTABLE 之一或内部目标类型之一。
实战小项目之 MQTT 物联网
MQTT(消息队列遥测传输协议)应该是应用最广泛的标准之一。目前,MQTT 已逐渐成为 IoT 领域最热门的协议
MQTT 简介
MQTT 是一种基于客户端服务端架构的发布 / 订阅模式的消息传输协议。它的设计思想是轻巧、开放、简单、规范,易于实现。这些特点使得它对很多场景来说都是很好的选择,特别是对于受限的环境如机器与机器的通信( M2M )以及物联网环境( IoT )。 ----MQTT 协议中文版
- 1
MQTT 最大优点在于,==可以以极少的代码和有限的带宽,为连接远程设备提供实时可靠的消息服务。==作为一种低开销、低带宽占用的即时通讯协议,使其在物联网、小型设备、移动应用等方面有较广泛的应用。
MQTT 的主要特性
①、使用发布/订阅消息模式,提供一对多的消息发布,解除应用程序耦合。
②、基于 TCP/IP 提供网络连接
③、支持 QoS 服务质量等级。
根据消息的重要性不同设置不同的服务质量等级。
④、小型传输,开销很小,协议交换最小化,以降低网络流量。
⑤、使用 will 遗嘱机制来通知客户端异常断线。
⑥、基于主题发布/订阅消息,对负载内容屏蔽的消息传输。
⑦、支持心跳机制。
MQTT 协议
MQTT 通信基本原理
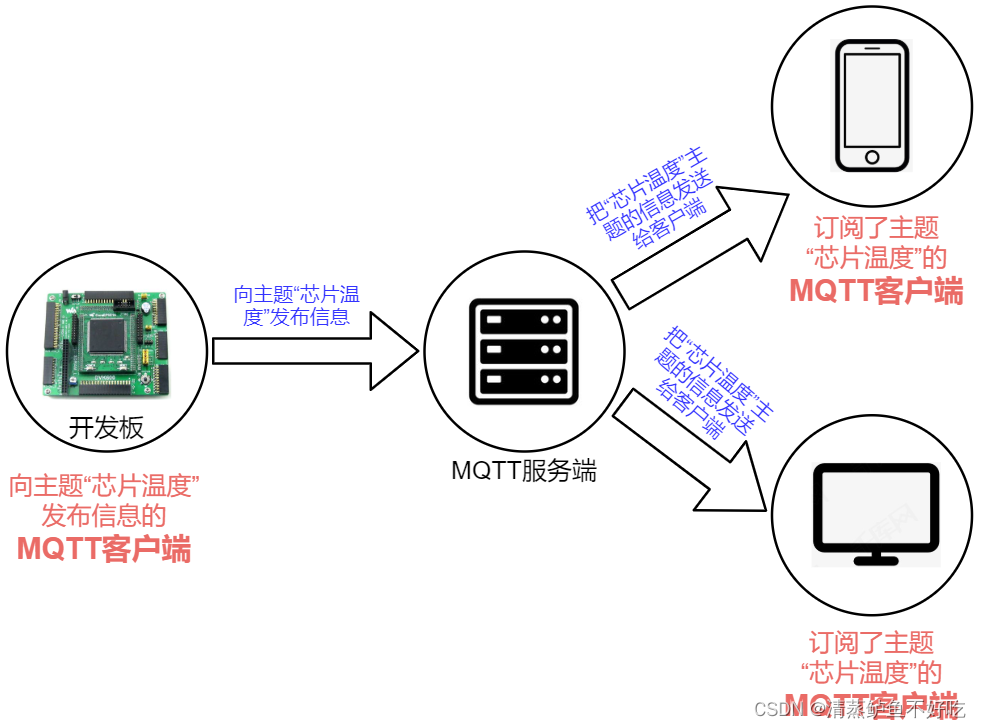
MQTT 是一种基于客户端-服务端架构的消息传输协议
MQTT 服务端通常是一台服务器(broker),它是 MQTT 信息传输的枢纽,负责将 MQTT 客户端发送来的信息传递给 MQTT 客户端;MQTT 服务端还负责管理 MQTT 客户端,以确保客户端之间的通讯顺畅,保证 MQTT 信息得以正确接收和准确投递。
连接 MQTT 服务端
MQTT 客户端连接服务端总共包含了两个步骤:
①、首先客户端需要向服务端发送连接请求,这个连接请求实际上就是向服务端发送一个 CONNECT报文,也就是发送了一个 CONNECT 数据包。
②、MQTT 服务端收到连接请求后,会向客户端发送连接确认。连接确认实际上是向客户端发送一个CONNACK 报文,也就是 CONNACK 数据包。
报文就是一个数据包,MQTT 报文组成分为三个部分:固定头(Fixed header)、可变头(Variableheader)以及有效载荷(Payload,消息体)
⚫ 固定头(Fixed header):存在于所有 MQTT 报文中,固定头中有报文类型标识,可用于识别是哪种 MQTT 报文,譬如该报文是 CONNECT 报文还是 CONNACK 报文,亦或是其它类型报文。
⚫ 可变头(Variable header):存在于部分类型的 MQTT 报文中,报文的类型决定了可变头是否存在及其具体的内容。
⚫ 消息体(Payload):存在于部分类型的 MQTT 报文中,payload 就是消息载体的意思。
CONNECT 报文
 CONNACK 报文
CONNACK 报文

断开连接
客户端可以主动向服务端发送一个 DISCONNECT 报文来断开与服务端的连接
发布消息、订阅主题与取消订阅主题
当客户端连接到服务端之后,便可以发布消息或订阅主题了
MQTT 客户端向服务端发布消息其实就是向服务端发送一个 PUBLISH 报文

SUBSCRIBE–订阅主题
当客户端向服务端发送 SUBSCRIBE 报文,服务端接收到 SUBSCRIBE 报文之后会向客户端回复一个SUBACK 报文(订阅确认报文)
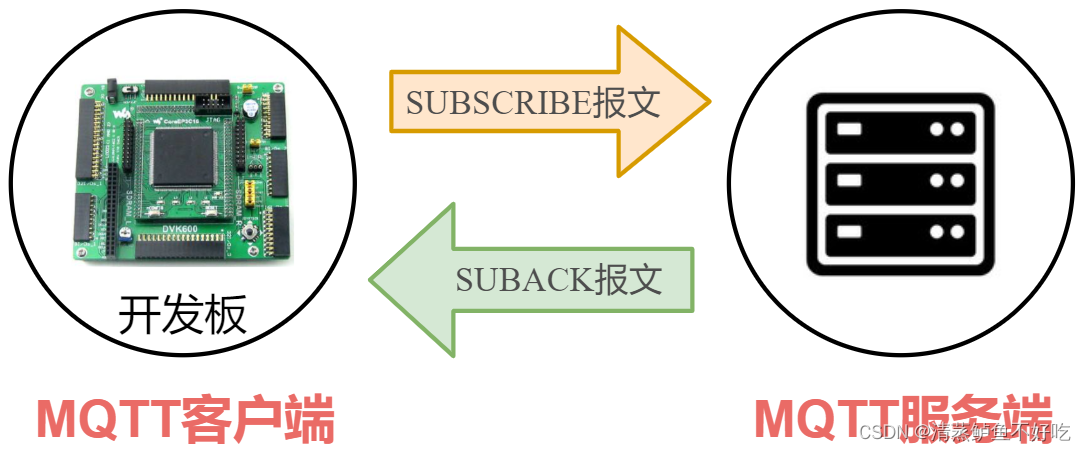
UNSUBSCRIBE–取消订阅主题
当服务端接收到 UNSUBSCRIBE 报文后,会向客户端发送取消订阅确认报文 – UNSUBACK 报文。

主题的进阶知识
1、主题的基本形式
⚫ 主题是区分大小写的。
⚫ 主题可以使用空格。
⚫ 不要使用中文主题。
2、主题分级
支持主题分级,对主题进行分级处理,各个级别之间使用" / "符号进行分隔。如下所示:
“home/sensor/led/brightness”
在以上示例中一共有四级主题,分别是第 1 级 home、第 2 级 sensor、第三级 led、第 4 级 brightness。
需要注意的是,主题名称不要使用" / "开头
3、主题通配符
当客户端订阅主题时,可以使用通配符同时订阅多个主题。通配符只能在订阅主题时使用
单级通配符:+ 可以匹配任意一个主题级别,注意是一个主题级别
“home/sensor/+/status”
多级通配符:# 自然是可以匹配任意数量个主题级别,而不再是单一主题级别,后面的级别也能匹配
4、主题应用注意事项
1)以$号开头的主题是 MQTT 服务端系统保留的特殊主题,客户端不可随意订阅或向其发布信息
2)不要使用“/”作为主题开头
3)主题中不要使用空格
4)主题中尽量使用 ASCII 字符
QoS 是什么?
QoS 是 Quality of Service 的缩写,所以中文名便是服务质量。
MQTT 协议有三种服务质量等级:
⚫ QoS = 0:最多发一次;
⚫ QoS = 1:最少发一次;
⚫ QoS = 2:保证收一次。
服务质量降级
假如客户端 A 发布到主题 1 的消息是采用 QoS=2,然而客户端 B 订阅主题 1 采用 QoS = 1
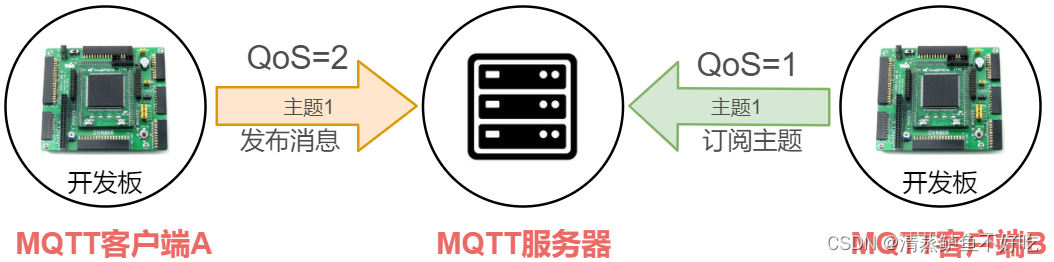
虽然 A 发送到主题 1 的消息采用 QoS 为 2,但是服务端发送主题 1 的消息给 B 时,采用的 QoS 为 1。
保留消息
让服务端对客户端发布的消息进行保留,如果有其它客户端订阅了该消息对应的主题时,服务端会立即将保留消息推送给订阅者,而不必等到发送者向主题发布新消息时订阅者才会收到消息。
但是需要注意的是,每一个主题只能有一个“保留消息”
删除保留消息
如果我们要删除保留消息又该怎么做呢?其实非常简单,只需要向该主题发布一条空的“保留消息”
MQTT 的心跳机制
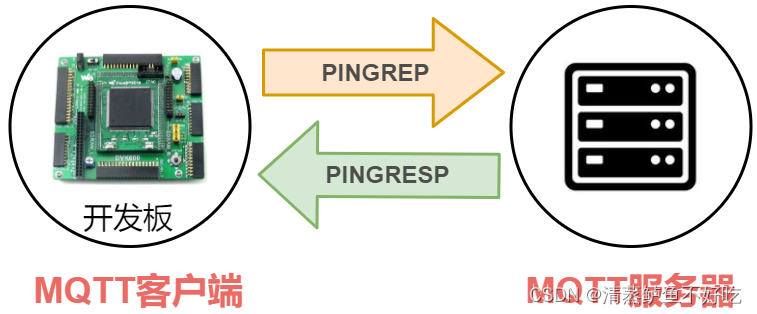 由于心跳请求是定时发送的(通过 keepAlive 设置时间间隔,也是告诉服务端,客户端将会多少多少秒向它发送心跳请求,这样服务端就会知道了);一旦服务器未收到客户端的心跳包,那么服务器就会知道,这台客户端可能已经掉线了。
由于心跳请求是定时发送的(通过 keepAlive 设置时间间隔,也是告诉服务端,客户端将会多少多少秒向它发送心跳请求,这样服务端就会知道了);一旦服务器未收到客户端的心跳包,那么服务器就会知道,这台客户端可能已经掉线了。
MQTT 的遗嘱机制
客户端断开与服务端的连接通常是有两种方式的:
⚫ 客户端主动向服务端发送 DISCONNECT 报文,请求断开连接,自然服务端也就知道了客户端要离线了;
⚫ 客户端意外掉线。被动与服务端断开了连接。
所以针对这种意外掉线的情况,MQTT 协议使用了遗嘱机制来服务客户端、管理客户端。
MQTT 协议允许客户端在“活着”的时候就写好遗嘱,这样一旦客户端意外断线,服务端就可以将客户端的遗嘱公之于众。
客户端如何设置自己的“遗嘱”信息
客户端连接服务端时发送的 CONNECT 报文中有这样几个参数

willTopic – 遗嘱主题
此遗嘱主题为“clientWill”,也就是说,只有订阅了主题“clientWill”的客户端,才会收到这台客户端的遗嘱消息。
客户端 A 上线时可以向自己的遗嘱主题发布一条消息,那么那些订阅了该遗嘱主题的客户端可以收到这条消息,这些订阅者也就知道了客户端 A 已经上线了。
willMessage – 遗嘱消息
willRetain – 遗嘱消息的保留标志
willQoS – 遗嘱消息的 QoS
开发板移植 MQTT 客户端库
看文档把P1071

