- 1人脸识别技术趋势与发展_人脸识别的发展趋势
- 2供应链大屏设计实践
- 3读《硅谷钢铁侠——埃隆马斯克自传》有感
- 4Altera FPGA 配置flash读写_asmi flash 控制器
- 5启动和关闭hadoop集群是找不到命令解决方法_hadoop-daemon.sh start 找不到命令
- 6读了《淘宝技术这十年》有感_从淘宝技术这十年的发展有何感想
- 7idea报错:Failed to execute goal org.apache.maven.plugins_maven-deploy-plugin...with status code 400_[error] failed to execute goal org.apache.maven.pl
- 8大模型「训练」与「微调」概念详解【6000字长文】_大模型预训练与微调
- 9【NLP傻瓜式教程】手把手带你CNN文本分类(附代码)
- 10JavaScript语言是什么?有什么优点和缺点!_javascript交互性强吗
8人小团队挑战OpenAI,他们凭什么?
赞
踩

7月3日晚,法国一个仅有8人的非营利性AI研究机构 —— Kyutai,发布震惊世界的模型Moshi,具备听、说、看的多模态功能。
该模型具备的功能可与OpenAI GPT-4o和Google Astra相媲美,但模型要小得多,基础文本语言模型是Kyutai内部开发的7B参数模型Helium。Moshi在说话时思考,具有彻底改变人机通信的潜力。据悉,该团队开发这个模型仅用了6个月。

能听会说的Moshi
在发布会现场,Moshi可以非常流利地回答人们提出的问题,甚至可以猜出提问者的意图,还会开些小玩笑。
例如,演示者和Moshi聊爬珠穆朗玛峰的话题,说到「下个月打算去攀登珠穆朗玛峰,我在想......」,提问者话说到一半,Moshi 就说道:「太了不起了,你需要带些什么装备呢」,并给出了一些攀登设备的专业建议和注意事项。Moshi还会开些小玩笑:「你并不想穿着凉鞋去爬山」。


研究团队还用各种说话风格展示了Moshi表达和理解情绪的能力。例如,让Moshi用法国口音诵读诗句,并中途打断了Moshi的朗诵,Moshi也能立即停下来。

Moshi还可以进行角色扮演和剧本演示。例如:讲述星际迷航,指挥官和舰长的探索故事。
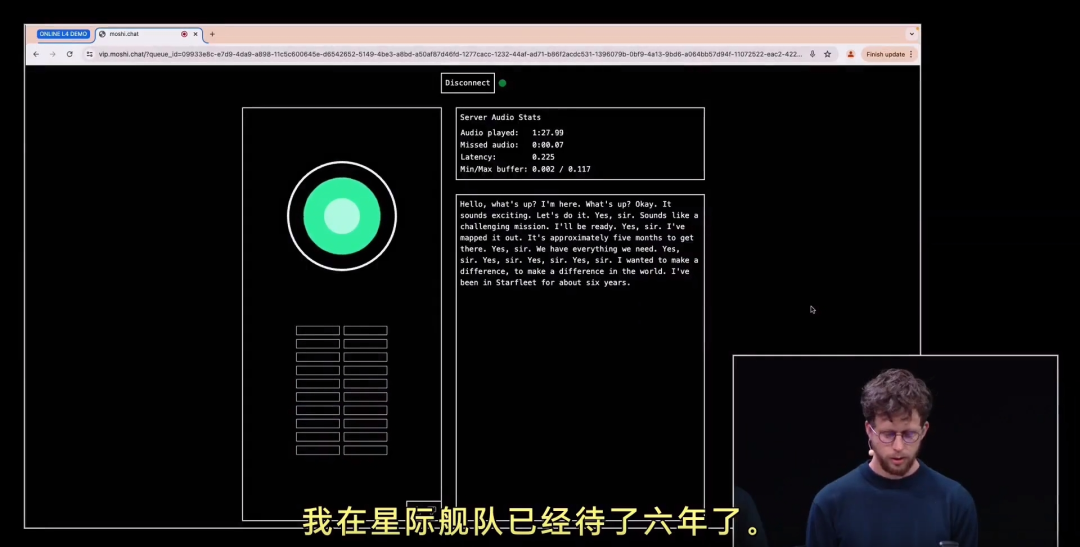
从效果演示来看,Moshi可以随时聆听和实时交谈,表达自然、流畅,甚至还能模仿快乐、悲伤等70种不同情绪和说话风格,以及进行角色扮演。
目前,Moshi还不支持中文普通话,主流语言为英语和法语;视觉处理也暂时并未体现。

Moshi背后的技术
Moshi的核心是一个处理语音输入和输出的70亿参数多模态语言模型。该模型采用了I/O双通道系统,同时生成文本token和音频编解码器。具体来说,语言模型Helium-7B从头先开始训练,然后再与文本、语音编码器联合训练。该语音编解码器基于Kyutai的内部Mimi模型,压缩系数高达300倍,可捕捉语义和声音信息。

Moshi的微调过程涉及使用文本到语音(TTS)技术转换的100,000个「口语风格」的合成对话。模型的语音在一个单独的TTS模型生成的合成数据上进行训练,实现了令人印象深刻的200毫秒端到端延迟。值得注意的是,Kyutai还开发了一个可以在MacBook或消费级GPU上运行的Moshi小型版本,使其可以被更广泛的群体使用。
值得一提的是,Kyutai的所有模型都是开源的。之后,该团队计划发布完整模型,包括推理代码库、7B模型、音频编解码器和完整的优化堆栈。

Moshi的创始团队
Kyutai是欧洲首个致力于人工智能开放研究的私人倡议实验室,是一个非营利组织,其使命是解决现代人工智能的基本挑战。
Kyutai组建了一支由具有杰出学术和商业背景的优秀研究人员组成的团队,团队由图灵奖得主Yann LeCun坐镇,三十年AI老兵Patrick Pérez带队。


Moshi体验流程
免费体验地址:
https://moshi.chat/?queue_id=talktomoshi
Moshi的使用流程非常简单:
(1)登录免费体验地址。
(2)填写一个邮箱地址,然后点击Join queue。
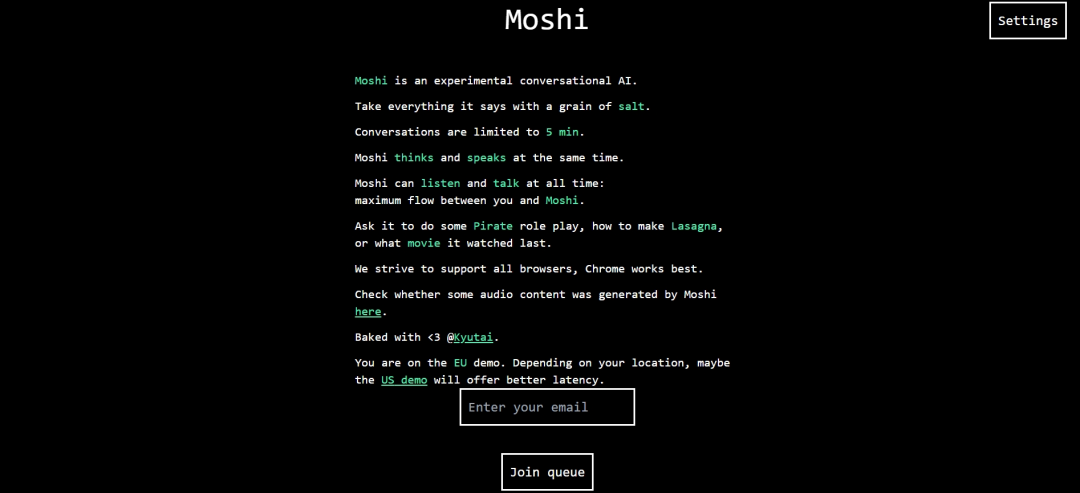
(3)开始语音输入,说出你想提问的内容就行了。