
(二)hadoop搭建
赞
踩
1. 下载
访问https://hadoop.apache.org/releases.html查看hadoop最新下载地址
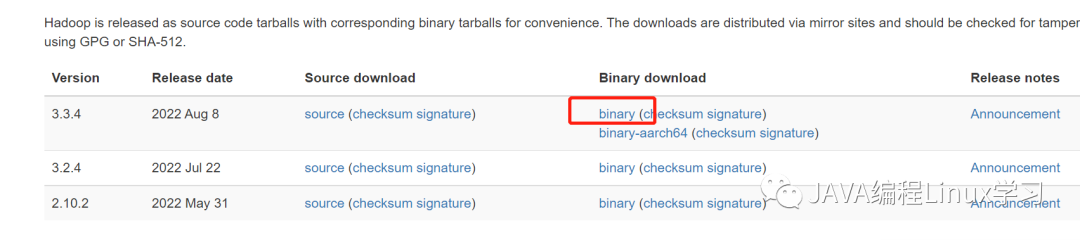
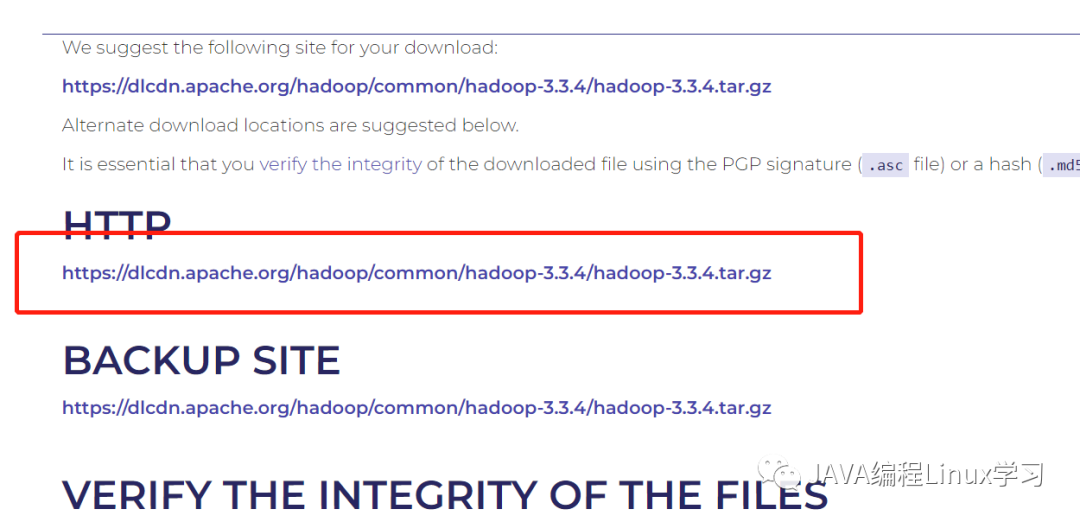
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
2.解压
tar zxvf hadoop-3.3.4.tar.gz
mv hadoop-3.3.4 /usr/local
3.配置环境变量(新建.sh文件,\etc\profile会遍历\etc\profile.d文件夹下的所有.sh文件)
查看jdk安装路径
依次查看link连接命令,
执行
which java
ls -l /usr/bin/java
ls -l /etc/alternatives/java
sudo vim /etc/profile.d/hadoop_profile.sh
内容如下:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
刷新使配置生效
source /etc/profile
4.查看验证
hadoop version
5.配置集群
集群规划
cd /usr/local/hadoop-3.3.4/etc/hadoop
5.1配置hdfs
vi hdfs-site.xml
在<configuration></configuration>标签中新增如下内容
<!-- namenode web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-master:9870</value>
</property>
<!-- secondnamenode web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-slave1:9868</value>
</property>
5.2 配置core-site
vi core-site.xml
在<configuration></configuration>标签中新增如下内容
<!-- 配置NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:8020</value>
</property>
<!-- 配置hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.4/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
5.3 配置yarn
vi yarn-site.xml
在<configuration></configuration>标签中新增如下内容
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-slave2</value>
</property>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop-master:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
5.4配置mapred-site
vi mapred-site.xml
在<configuration></configuration>标签中新增如下内容
<!-- 配置MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-master:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-master:19888</value>
</property>
6.把上述配置复制到hadoop-slave1、hadoop-slave2
sudo scp -r /usr/local/hadoop-3.3.4 hadoop@hadoop-slave1:/home/hadoop/
sudo scp -r /usr/local/hadoop-3.3.4 hadoop@hadoop-slave2:/home/hadoop/
分别在hadoop-slave1和hadoop-slave2的/home/hadoop下执行
sudo mv hadoop-3.3.4/ /usr/local/
7.把配置文件hadoop_profile.sh复制到hadoop-slave1和hadoop-slave2
scp /etc/profile.d/hadoop_profile.sh hadoop@hadoop-slave1:/home/hadoop
scp /etc/profile.d/hadoop_profile.sh hadoop@hadoop-slave2:/home/hadoop
分别在slave1和slave2的/home/hadoop下执行
sudo mv hadoop_profile.sh /etc/profile.d/
source /etc/profile
8.配置worker
vi /usr/local/hadoop-3.3.4/etc/hadoop/workers
添加如下内容
hadoop-master
hadoop-slave1
hadoop-slave2
把配置文件workers复制到hadoop-slave1和hadoop-slave2
scp /usr/local/hadoop-3.3.4/etc/hadoop/workers hadoop@hadoop-slave1:/home/hadoop
scp /usr/local/hadoop-3.3.4/etc/hadoop/workers hadoop@hadoop-slave2:/home/hadoop
分别在slave1和slave2执行
sudo mv /home/hadoop/workers /usr/local/hadoop-3.3.4/etc/hadoop/
9.格式化NameNode
集群第一次启动需要先在master节点格式化NameNode
hdfs namenode -format
注意:
格式化NameNode后,集群会产生新的id,导致NameNode和原来DataNode对应的集群id不一致,这样集群就找不到原来的数据。如集群在运行过程中遇到问题,需要重新格式化NameNode的时,需要先停止namenode和datanode进程,并删除所有机器的data和logs目录,然后再格式化。
10. 启动HDFS (在hadoop-master节点执行)
start-dfs.sh
注意:
如果报错ERROR: JAVA_HOME is not set and could not be found.
解决办法:
vi /usr/local/hadoop-3.3.4/etc/hadoop/hadoop-env.sh
修改 JAVA_HOME为实际的jdk的JAVA_HOME路径
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
11. 启动该YARN(在hadoop-slave2节点执行)
start-yarn.sh
12. 启动历史服务器(在hadoop-master节点执行)
mapred --daemon start historyserver
13验证
13.1在hadoop-master节点执行jps
13.2在hadoop-slave1节点执行jps
13.3在hadoop-slave2节点执行jps
13.4访问HDFS 、YARN 、HistoryJob的web端
HDFS
访问:http://hadoop-master:9870
YARN
访问 http://hadoop-slave2:8088
HistoryJob
访问:http://hadoop-master:19888/jobhistory


