
- 1Visual Effect Graph官方案例打开错误解决 ------ Could not find file Unity.Analytics.StandardEvents.EditorTests._could not find graph window
- 2力扣——174.地下城游戏(困难难度)——万能的递归与动态分析
- 3在IDEA中配置eslint和prettier_idea eslint配置
- 4循环神经网络模型_文件rates.csv是从oanda
- 5在 CentOS 7/RHEL 7 上安装 Java 17 (OpenJDK 17) |_yum 安装jdk17
- 6vue使用elementUI校验获取校验获取校验报错信息_elementui表单验证获取错误信息
- 7RCNN_人脸检测_rcnn人脸识别
- 8Axure中继器的使用二(删除数据操作、弹出框显示更新数据、中继器更新数据操作)_axuew解除数据
- 9No known conditions for “./lib/locale/lang/zh-cn“ specifier in “element-plus“ package_no known conditions for "./lib/locale/lang/zh-cn"
- 10一些看起来不错的Unity资源包_unity环境资源包
帅呆了!Kafka移除了Zookeeper!_kafka最新版是否需要zk
赞
踩
普天同庆!最新版的Kafka 2.8.0,移除了对Zookeeper的依赖,通过KRaft进行自己的集群管理。很好很好,终于有点质的改变了。
一听到KRaft,我们就想到了Raft协议。Raft协议是当今最流行的分布式协调算法,Etcd、Consul等系统的基础,就来自于此。现在Kafka也有了。
由于这个功能太新了,所以2.8.0版本默认还是要用ZooKeeper的,但并不妨碍我们尝尝鲜。另外,不要太激动了,据官方声称有些功能还不是太完善,所以不要把它用在线上。
1. 如何开始KRaft?
Kafka使用内嵌的KRaft替代了ZooKeeper,是一个非常大的进步,因为像ES之类的分布式系统,这种集群meta信息的同步,都是自循环的。
但如何使用KRaft启动呢?很多同学直接晕菜了,这方面的资料也比较少,但使用起来非常简单。
我们注意到,在config目录下,多了一个叫做kraft的目录,里面包含着一套新的配置文件,可以直接摒弃对ZK的依赖。
通过下面三行命令,即可开启一个单机的broker,从始至终没有ZK的参与。
复制
- # ./bin/kafka-storage.sh random-uuid
- # ./bin/kafka-storage.sh format -t TBYU7WMiREexuZqrjKG60g -c ./config/kraft/server.properties
- # ./bin/kafka-server-start.sh ./config/kraft/server.properties
- 1.
- 2.
- 3.
经过一阵噼里啪啦的运行,No ZK的Kafka已经启动起来了。
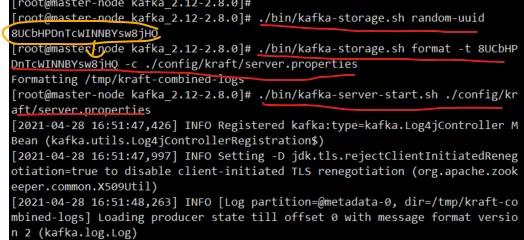
就是这么简单。
2. 如何配置的?
kafka又加了一个内部主题,叫做@metadata,用来存这些元信息。
接下来我们就要看一些关键的配置信息。你可以使用vimdiff config/server.properties config/kraft/server.properties看一下这些主要的区别。
首先,kraft多了一个叫做process.roles的配置。在我们的配置文件里它是这样的。
复制
process.roles=broker,controller
- 1.
它其实有三个取值。
- broker: 这台机器将仅仅当作一个broker
- controller: 作为 Raft quorum的控制器之一进行启动
- broker,controller: 包含两者的功能
熟悉ES的同学可以看出,这些划分就像是es的master和node,所以分布式的概念其实在一定程度上是相通的。
接下来是监听地址的变化,因为我们的server有了两个功能,所以也就需要开启两个端口。
复制
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
- 1.
另外,还有一个叫做node.id的东西。不同于原来的broker.id,这个nodeid是用来投票用的。
复制
node.id=1
- 1.
因为raft协议的特性,我们的投票配置就要使用上面的node.id。写起来比较怪异是不是?但总比Zk的好看多了。所以这些配置在后面的版本是有可能改动的。
复制
controller.quorum.voters=1@localhost:9093
- 1.
这就是配置文件的主要区别。我们来看看它的集合。
复制
- process.roles=broker,controller
- listeners=PLAINTEXT://:9092,CONTROLLER://:9093
- node.id=1
- controller.quorum.voters=1@localhost:9093
- 1.
- 2.
- 3.
- 4.
3. 为什么要干掉ZK?
Kafka作为一个消息队列,竟然要依赖一个重量级的协调系统ZooKeeper,不得不说是一个笑话。同样作为消息队列,人家RabbitMQ早早的就实现了自我管理。
Zookeeper非常笨重,还要求奇数个节点的集群配置,扩容和缩容也不方便。Zk的配置方式,也和kafka的完全不一样,要按照调优Kafka,竟然还要兼顾另外一个系统,这真是日了狗了。
Kafka要想往轻量级,开箱即用的方向发展,就不得不干掉Zk。
另外,由于Zk和Kafka毕竟不是在一个存储体系里面,当Topic和Partition的数量上了规模,数据同步问题就变的显著起来。Zk是可靠,但是它慢啊,完全不如放在Kafka的日志存储体系里面,这对标榜速度的Kafka来说,是不得不绕过的一环。
使用过Kafka-admin的同学,应该都对缓慢的监控数据同步历历在目。它需要先从zk上转一圈,获取一些元数据信息,然后再从Kafka的JMX接口中拉取数据。这么一转悠,就几乎让大型集群死翘翘。
4. 会有哪些改变?
部署更简单。
首先,部署变的更加简单。对于一些不太追求高可用的系统,甚至一个进程就能把可爱的kafka跑起来。我们也不需要再申请对zookeeper友好的SSD磁盘,也不用再关注zk的容量是不是够用了。
监控更便捷。
其次,由于信息的集中,从Kafka获取监控信息,就变得轻而易举,不用再到zk里转一圈了。与grafana/kibana/promethus等系统的集成,指日可待。
速度更快捷。
最重要的当然是速度了。Raft比ZK的ZAB协议更加易懂,也更加高效,partition的主选举将变得更快捷,controller的调度速度将上一个档次。
以后,再也不会有这样的连接方式。
复制
zookeeper.connect=zookeeper:2181
- 1.
取而代之的,只会剩下bootstrap的连接方式。Kafka的节点,越来越像对等节点。
复制
bootstrap.servers=broker:9092
- 1.
kafka还提供了一个叫做kafka-metadata-shell.sh的工具,能够看到topic和partion的分布,这些信息原来是可以通过zk获取的,现在可以使用这个命令行获取。
复制
- $ ./bin/kafka-metadata-shell.sh --snapshot /tmp/kraft-combined-logs/\@metadata-0/00000000000000000000.log
- >> ls /
- brokers local metadataQuorum topicIds topics
- >> ls /topics
- foo
- >> cat /topics/foo/0/data
- {
- "partitionId" : 0,
- "topicId" : "5zoAlv-xEh9xRANKXt1Lbg",
- "replicas" : [ 1 ],
- "isr" : [ 1 ],
- "removingReplicas" : null,
- "addingReplicas" : null,
- "leader" : 1,
- "leaderEpoch" : 0,
- "partitionEpoch" : 0
- }
- >> exit

- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
最后,还是要提醒一下,目前不要在线上环境开启这个功能,还是老老实实用ZK吧。功能就是原因,因为这些功能的配套设施还没有到位,代码也没有达到让人放心的程度。你要是用了,很可能会因为工具不全或者难缠的bug痛不欲生。
不过,这勇敢的第一步已经卖出,方向也已经指明,我们剩下的就是等待了。无论如何,干掉Zk,是件大好事。

