
- 1AI助力智慧农业,基于YOLOv5全系列模型【n/s/m/l/x】开发构建不同参数量级农田场景下庄稼作物、杂草智能检测识别系统_基于深度学习的耕地变化检测技术
- 2嵌入式培训机构四个月实训课程笔记(完整版)-Linux ARM驱动编程第四天-ARM Linux编程之IIC与uart (物联技术666)
- 3使用YOLOv5实现单摄像头实时目标检测_yolov5摄像头实时检测
- 4linux系统编程之进程概念(操作系统---管理,进程创建,进程状态,进程优先级, 环境变量,程序地址空间,进程O(1)调度方法)_是linux用户层的工作单元,也是linux进行系统调度的单元。
- 5python实现数据归一化处理的方式:(0,1)标准化_python归一化处理计算公式
- 6Mac系统 Java环境搭建完整教程_macjava开发环境搭建
- 7centos7 环境下使用centos docker中运行flask应用及后台运行实战_怎么让flask程序在centos后台一直运行
- 8张量学习(6):张量代数_双点积
- 9fastadmin微信支付宝支付设置_fastadmin如何写一个支付接口
- 10jupyter notebook无conda内核解决方案_jupyter无法连接内核
VS Stuidio 2019实用调试技巧_vs2019如何知道程序内存地址空间
赞
踩
VS Studio 2019实用调试技巧
1.debug和release的区别
VS集成开发环境上方有一个选项为Debug,表示这是代码的Debug版本,可以将其改为Release,表示这是代码的Release版本,那么Debug版本和Release版本有什么区别吗?


Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。
Release 称为发布版本,编译器对我们写的代码进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用,Release版本不能调试。
例:请看下面代码:
#include <stdio.h>
int main()
{
int i = 0;
int arr[10] = {0};
for(i=0; i<=12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Debug版本下运行,该程序会出现死循环,即无限输出hehe,这是为什么呢?
i和arr都是局部变量,局部变量是存放在栈区上了,栈区内存的使用是先使用高地址处的空间,再使用低地址处的空间,数组随着下标的增长,地址由低到高变化,那么局部变量i和arr在栈区上的内存分配大致如下:
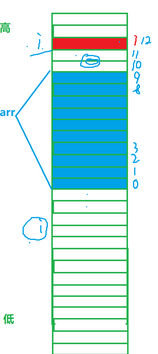
在vs2019环境下,变量i和arr相差两个整型,不同环境可能不一样,现在知道了局部变量i和arr的内存分配情况,我们先回归到代码。
由代码可知,从arr[10]开始越界访问,虽然对于程序而言arr[10]不存在,属于越界访问,但是对于实际内存而言,arr[10]就是arr[9]后面的一个位置,是真实存在的,因此可以将arr[10]赋值为0,同时也可以将arr[11]赋值为0,但是当访问到arr[12]的时候,由上面的内存分配图我们可以知道arr[12]实际上就是i,将arr[12]赋值为0,实际上就是将i赋值为0,因此i满足for循环条件,又会进入到下一轮循环,当i==12,再次访问到arr[12],将arr[12]赋值为0时,实际上又是将i赋值为0,又会进入下一轮的循环,因此这样下去就是无限死循环输出hehe。
那么在Release版本下,代码是怎么运行的呢?
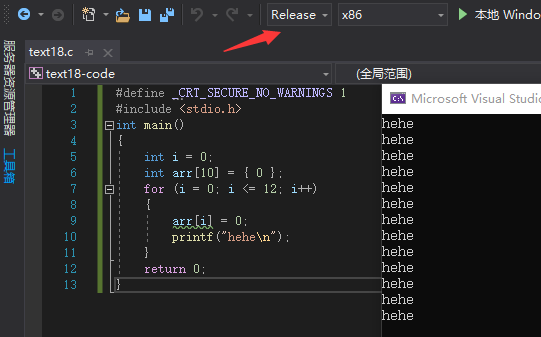
如图所示在Release版本下,只输出了13次hehe,程序没有出现死循环,这是因为编译器对程序进行了优化:
由于Release版本无法进行调试,因此这里我们手动输出局部变量i和arr的地址:
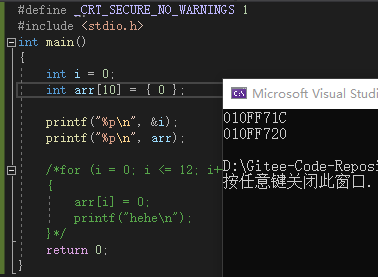
前面说过局部变量存放在栈区,栈区的内存是从高地址向低地址使用的,因此变量i的地址应该大于arr的地址,可是由上图可知,变量i的地址小于arr的地址,这就是Release版本的优化,我们可以大致画出优化后的栈区内存分配图:

画出内存分配图后,我们可以更加清晰地了解到Releas版本对代码的优化,Release版本中,变量内存开辟的顺序发生了变化,先在高地址处开辟数组的空间,然后在低地址处开辟变量i的内存空间,这样即便数组越界访问,也不会影响到变量i的值,也就不会出现Debug版本死循环的情况。
由此可见Release版本的确会对代码进行优化,不过这种优化是底层的优化,比如这里对内存空间的开辟顺序进行了优化,而且这种优化并不会改变你的代码。
2.调试
首先要注意的是,调试只有在Debug版本下才能进行:

(1)调试最常使用的几个快捷键
F5:
F5向后执行代码,跳到下一个逻辑上的断点。
F9:
创建断点和取消断点。
断点的重要作用:可以在程序的任意位置设置断点。这样就可以使得程序运行到断点的位置停止执行,继而开始调试,一步步执行下去。
F9和F5是配合使用的。
F10:
逐过程,通常用来处理一个过程,一个过程可以是一次函数调用,或者是一条语句,逐过程执行会直接执行完整的过程,不会逐个执行过程中的每条语句。
F11
逐语句,就是每次都执行一条语句,这个快捷键可以使我们的执行逻辑进入函数内部(这是最长用的)。
CTRL + F5
开始执行不调试,如果你想让程序直接运行起来而不调试就可以直接使用。
(2)用监视窗口查看临时变量的值
监视窗口的打开过程如下:
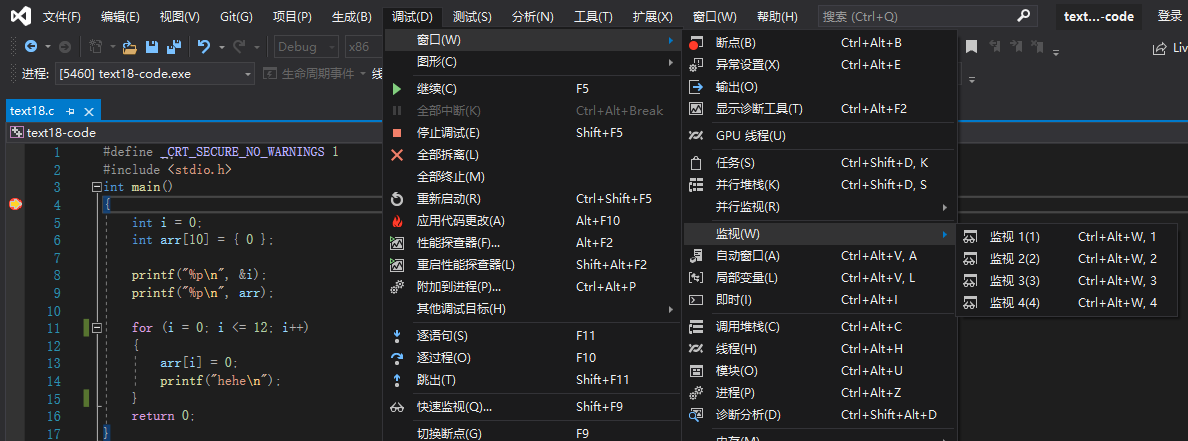
打开监视窗口后,我们可以添加要监视的变量:
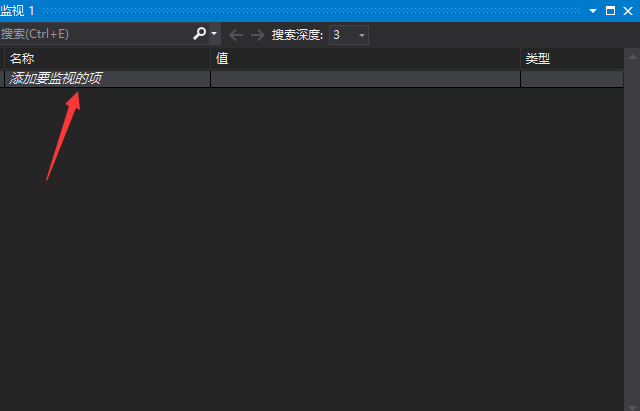
如图所示,我正在监视变量i和数组arr的信息:
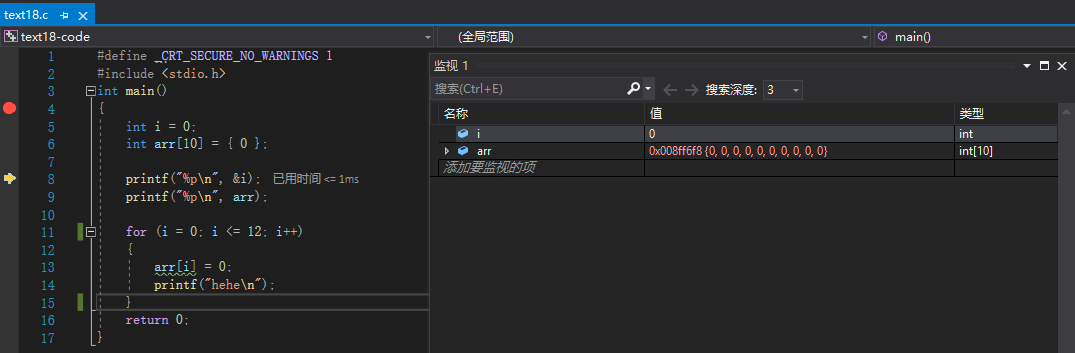
(3)查看内存信息
打开内存窗口的过程如下:
 打开内存窗口后,我们查看数组arr的内存信息:
打开内存窗口后,我们查看数组arr的内存信息:
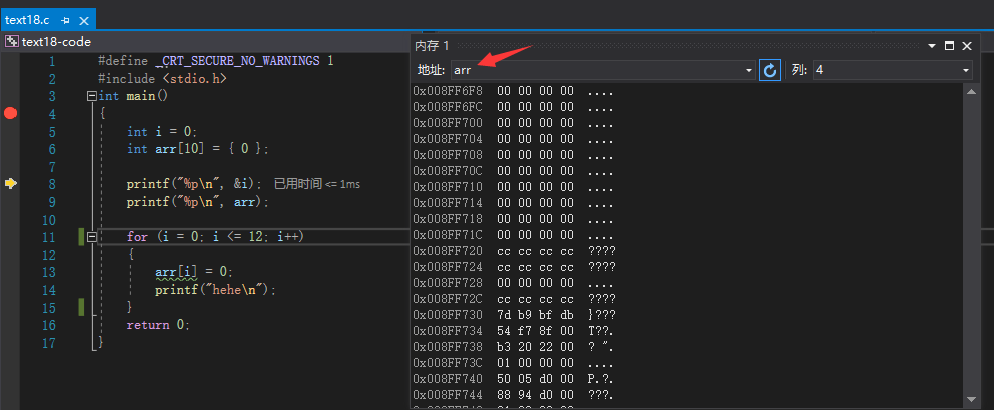
如图所示,输入arr即数组首元素的地址,然后就可以在下面看到数组每个元素的地址以及每个元素在内存中被初始化为0。
(4)查看调用堆栈
打开调用堆栈窗口过程:
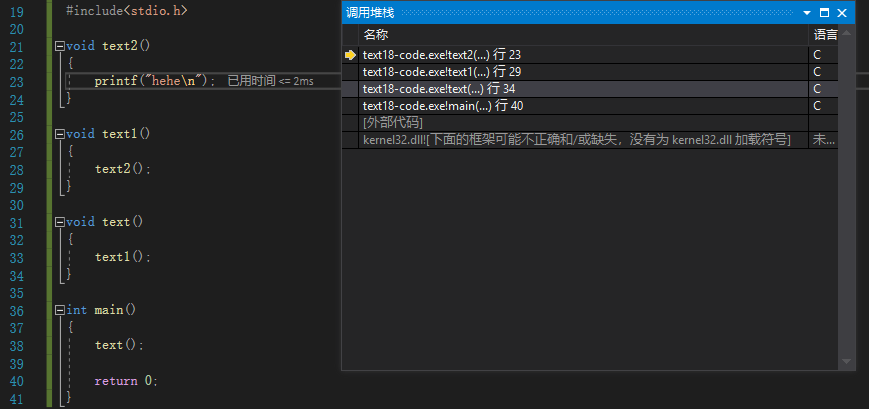 在main函数处设置断点后,然后使用F11逐语句执行,就会进入调用函数内部逐条执行语句,通过调用堆栈,可以清晰地反应函数的调用关系以及当前调用所处的位置。
在main函数处设置断点后,然后使用F11逐语句执行,就会进入调用函数内部逐条执行语句,通过调用堆栈,可以清晰地反应函数的调用关系以及当前调用所处的位置。
(5)查看汇编信息
在调试开始之后,有两种方式转到汇编:
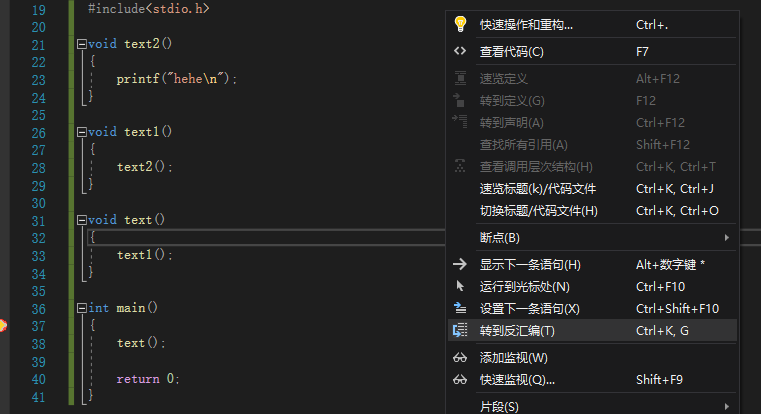
(1)第一种方式:右击鼠标,选择【转到反汇编】:
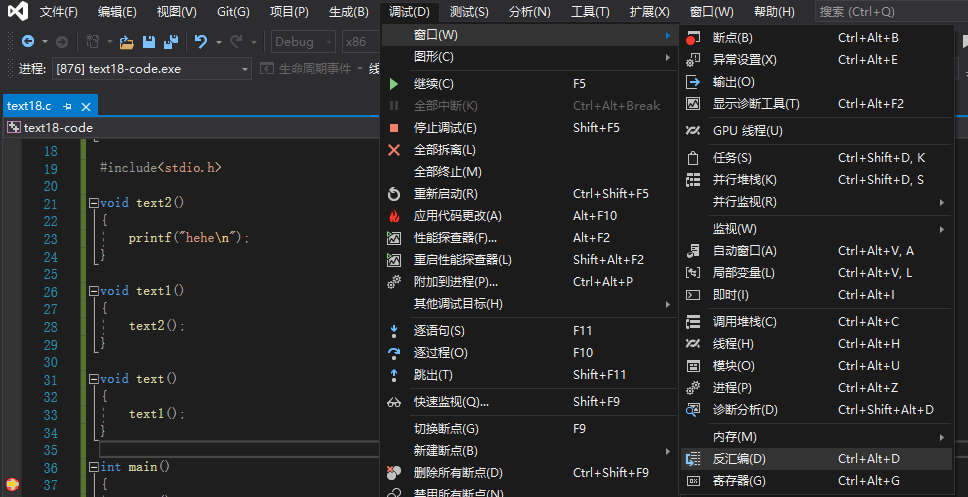
 (2)通过调试窗口选择反汇编:
(2)通过调试窗口选择反汇编:
(6)查看寄存器信息
可以查看当前运行环境的寄存器的使用信息。
3.如何写出易于调试/好的代码
优秀的代码:
- 代码运行正常
- bug很少
- 效率高
- 可读性高
- 可维护性高
- 注释清晰
- 文档齐全
常见的coding技巧:
- 使用assert
- 尽量使用const
- 养成良好的编码风格
- 添加必要的注释
- 避免编码的陷阱。
4.编程中常见错误
- 编译型错误:都是语法错误引起的,直接看错误提示信息(双击),解决问题。或者凭借经验就可以搞定。相对来说简单。
- 链接型错误:看错误提示信息,主要在代码中找到错误信息中的标识符,然后定位问题所在。一般是标识符名不存在或者拼写错误。
- 运行时错误:借助调试,逐步定位问题。最难搞。

