
- 1消防荷载楼板按弹性还是塑性计算_高吨位消防车荷载怎么取?
- 2使用bert进行文本二分类_bert文本二分类
- 3springboot中数据层标准开发(增删改查等数据操作)_spring数据层编写
- 4Vmware重新安装后网络适配器不显示网卡的问题_网络适配器中没有vmware的网卡
- 5零钱兑换Python解法_给你一个整数数组coins,表示不同面额的硬币,以及一个整数amount,表示总金额。
- 6kali联网(桥接,nat和仅主机模式都有)
- 7Centos7.6系统升级openssh_centos7.6升级openssh
- 8Stable Diffusion学习笔记_comfyui一键更换背景
- 9MIPS单周期CPU的设计——I型指令的设计
- 10@ControllerAdvice 配合 @ExceptionHandler 实现自定义全局异常处理_视图跟controller 放在一起 如何自定义异常
分布式爬虫Scrapy-Redis之四种组件及原理
赞
踩
分布式爬虫
分布式爬虫是由一组通过网络进行通信、为了完成共同的爬虫任务而协调工作的计算机节点组成的系统 。分布式爬虫是将多台电脑组合起来,共同完成一个爬虫任务,大大提高爬取效率。
原来scrapy的Scheduler维护的是本机的任务队列(存放Request对象及其回调函数等信息)+本机的去重队列(存放访问过的url地址):
- 所以实现分布式爬取的关键就是,找一台专门的主机上运行一个共享的队列比如Redis,
- 然后重写Scrapy的Scheduler,让新的Scheduler到共享队列存取Request,并且去除重复的Request请求,所以总结下来,实现分布式的关键就是三点:
- 共享队列
- 重写Scheduler,让其无论是去重还是任务都去访问共享队列
- 为Scheduler定制去重规则(利用redis的集合类型)
Scrapy-Redis
Scrapy 是一个通用的爬虫框架,但是不支持分布式, Scrapy-redis是为了更方便地实现 Scrapy 分布式爬取,而提供了一些 以redis为基础 的组件。
安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy-redis
scrapy-redis提供四种组件
scrapy-redis是一个基于redis数据库的scrapy组件,它提供了四种组件,通过它,可以快速实现简单分布式爬虫程序。
Scheduler(调度器)
Scrapy 改造了 Python 本来的 collection.deque(双向队列) 形成了自己的 Scrapy queue ,但是 Scrapy 多个 spider 不能共享待爬取队列Scrapy queue ,即 Scrapy 本身不支持爬虫分布式 ,。
scrapy-redis 的解决是把这个 Scrapy queue 换成 redis 数据库(也是指 redis队列) ,从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取 ,这样实现共享爬取队列。
- Scheduler负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。
Redis支持多种数据结构,这些数据结构可以很方便的实现这样的需求:
- 列表有lpush(),lpop(),rpush(), rpop(),这些方法可以实现先进先出,或者先进后出式的爬取队列。
- 集合元素是无序且不重复的,可以很方便的实现随机排序且不重复的爬取队列。
- Scrapy的Request带有优先级控制,Redis中的集合也是带有分数表示的,可以用这个功能实现带有优先级调度的爬取队列。
Duplication Filter (去重)
Scrapy 自带去重模块,该模块使用的是 Python 中的集合类型。也就是说Scrapy中用集合实现这个request去重功能。
- Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。
该集合会记录每个请求的指纹,指纹也就是 Request的散列值 。
- 指纹的计算采用的是hashlib 的 sha1() 方法。计算的字段包含了,请求的Method , URL , Body , Header 这几个内容,这些字符串里面只要里面有一点不同,那么计算出来的指纹就是不一样的。
- 也就是说,计算的结果是加密后的字符串,这就是请求指纹。通过加密后的字符串,使得每个请求都是唯一的,也就是指纹是惟一的。
- 并且指纹是一个字符串,在判断字符串的时候,要比判断整个请求对象容易。所以采用了指纹作为判断去重的依据 。
ltem Pipeline(管道)
引擎将(Spider返回的)爬取到的ltem给ltem Pipeline , scrapy-redis 的ltem Pipeline将爬取到的Item存入redis的items queue。
- 修改过
ltem Pipeline可以很方便的根据key从items queue提取 item,从而 实现items processes集群
Base Spider(爬虫类)
不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
Scrapy-Redis 工作原理
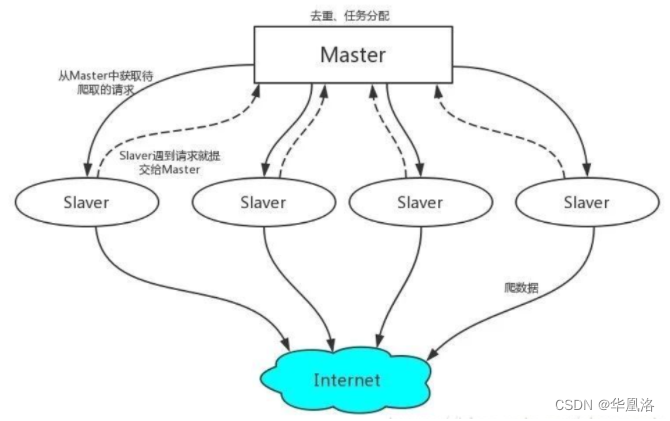
- 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
- Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。


