
- 1Visual Studio 2013 无法启动 IIS Express 的解决办法,新建web项目时出错,系统找不到指定文件_-visual studio-iis express 2013 工具 web 项目
- 2Android相机调用-CameraX【外接摄像头】【USB摄像头】_安卓调取摄像头设备的方式
- 3关于文本分类的调查:从浅层到深层学习_文本情感分类流程图
- 4linux C/C++多进程教程(多进程原理以及多进程的应用【以多连接socket服务端为例(fork子进程处理socket_fd),同时介绍了僵尸进程产生原因与解决方法】)(getpid、fork)_c++多进程编程
- 5LeafletJS-Markers_前端 leaflet marker选中后高亮
- 6华三链路聚合原理及实验_bridge-aggregation
- 7iOS 国际化
- 8【HarmonyOS】装饰器下的状态管理与页面路由跳转实现_harmonyos应用启动后自动跳转主页面
- 9安卓开发检测不到手机_安卓开发显示不出来手机
- 10阿里云Maven和Gradle仓库最新配置_gradle 阿里云
一文读懂:为什么GPU比CPU更快?_cpu和gpu核心数比较
赞
踩
大家好,我是老猫,猫头鹰的猫。
在过去几十年里,GPU变得越来越流行,尤其是最近ChatGPT大火,背后训练大模型的硬件设备GPU达到了一片难求的地步。
你有没有好奇:为什么必须要用GPU?CPU被淘汰了吗?

今天我们就来一起聊一下,为什么GPU比CPU更快!
▉ GPU比CPU快,并不准确?
单纯的来说是GPU快还是CPU快,其实并不公平。二者的设计理念并不一样。

CPU被称为计算机的"大脑",主要来承担计算的处理功能,操作系统和应用程序运行等操作都必须依赖它来进行,CPU 还决定着计算机的整体速度。
GPU的作用则更具有专业性,其最初的设计是用于辅助3D渲染,能同时并行更多指令,其非常适合现在比较热门的动漫渲染、图像处理、人工智能等工作负载。
简单来说,CPU是为延迟优化的,而GPU则是带宽优化的。CPU更善于一次处理一项任务,而且GPU则可以同时处理多项任务。就好比有些人善于按顺序一项项执行任务,有些人可同时进行多项任务。
为演示 CPU 与 GPU 的不同,英伟达曾经邀请亚当·萨维奇 (Adam Savage) 和杰米·海尼曼 (Jamie Hyneman) 利用机器人技术和彩弹再现了一幅广为人知的艺术作品--蒙娜丽莎的微笑。这个视频充分展示了CPU和GPU工作的过程。如下面的视频:
了不起的云计算
,赞2
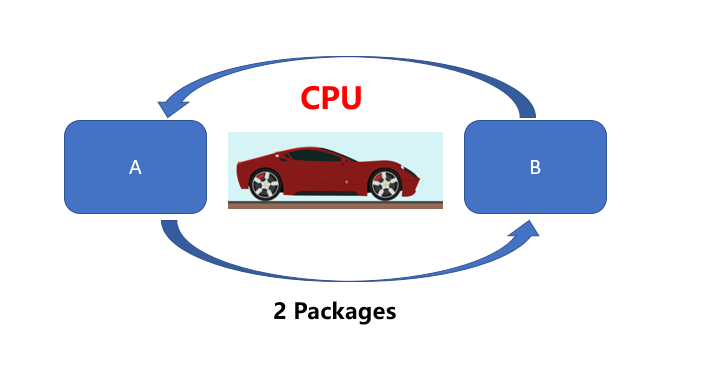
我们通过打比方来通俗的解释二者的区别。CPU就好比一辆法拉利,而GPU则相当于一辆货运卡车,二者的任务都是从A位置将100 Packages运送到B位置,CPU(法拉利)可以在RAM中快速获取一些内存数据(货物),而GPU(货运卡车)执行速度较慢(延迟更高)。但是CPU(法拉利)每次只能运送2 Packages,需要50次才能运送完成。
然而GPU(货运卡车)则可以一次获取更多内存数据进行运输。
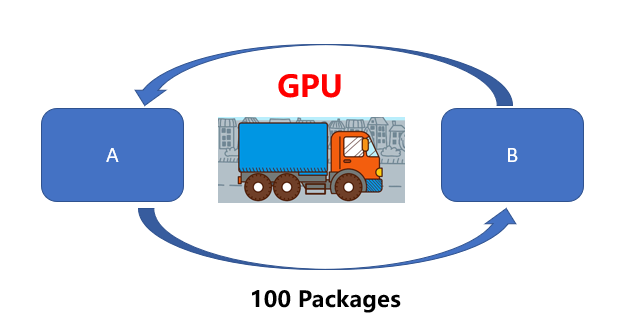
换句话说,CPU更倾向于快速处理少量数据(例如算术运算:5*6*7),GPU更擅长处理大量重复数据(例如矩阵运算:(A*B)*C)。因此,虽然CPU单次运送的时间更快,但是在处理图像处理、动漫渲染、深度学习这些需要大量重复工作负载时,GPU优势就越显著。
但是,GPU最大的问题在于延迟对性能的影响,但对于深度学习的典型任务场景,数据一般占用大块连续的内存空间,GPU可以提供最佳的内存带宽,并且线程并行带来的延迟几乎不会造成影响。
那么是什么导致CPU和GPU工作的方式不同呢?那还要从二者设计结构来说。
▉ 为什么GPU和CPU工作方式不同?
1、架构核心不同
通过下面两张图可以有助于我们理解CPU和GPU工作方式的不同。上文中我们提到,CPU是为顺序的串行处理而设计的,GPU则是为数据的并行而设计的,GPU有成百上千个更小、更简单的内容,而CPU则是有几个大而复杂的内核。

GPU内核经过优化,可以同时对多个数据元素进行类似的简单处理操作。而且CPU则针对顺序指令处理进行了优化,这也导致二者的核心处理能力的不同。
网上有一个比喻用来比较 GPU 和 CPU 核心的区别,我觉得非常贴切,CPU的核心像学识渊博的教授,GPU的核心更像一堆小学生,只会简单的算数运算,可即使教授再神通广大,也不能一秒钟内计算出500次加减法,因此对简单重复的计算来说单单一个教授敌不过数量众多的小学生,在进行简单的算数运算这件事上,500个小学生(并发)可以轻而易举打败教授。
2、内存架构不同
除了计算差异之外,GPU还利用专门的高带宽内存架构将数据送到所有核心,目前GPU通常用的是GDDR或HBM内存,它们提供的带宽比CPU中的标准DDR 内存带宽的带宽更高。

GPU处理的数据被传输到这个专门的内存中,以最大限度地减少并行计算期间的访问延迟。GPU的内存是分段的,因此可以执行来自不同内核的并发访问以获得最大吞吐量。
相比之下,CPU内存系统对缓存数据的低延迟访问进行了高度优化。对总带宽的重视程度较低,这会降低数据并行工作负载的效率。
3、并行性
专用内核和内存的结合使GPU能够比CPU更大程度地利用数据并行性。对于像图形、渲染这样的任务,相同的着色器程序可以在许多顶点或像素上并行运行。

现代GPU包含数千个核心,而高端CPU最多只有不到100个核心。通过更多的核,GPU可以以更高的算术强度在更宽的并行范围内处理数据。对于并行工作负载,GPU核心可以实现比CPU高100倍或更高的吞吐量。
相比之下,阿姆达尔定律意味着CPU对一个算法所能获得的并行加速是有限的。即使有100个内部核心,由于串行部分和通信,实际速度也限制在10倍或更低。由于其大规模并行架构,GPU可以实现几乎完美的并行加速。
4、即时(JIT)编译
GPU的另一个优点是即时(JIT)编译,它减少了调度并行工作负载的开销。GPU驱动程序和运行时具有JIT编译功能,可以在执行之前将高级着色器代码转换为优化的设备指令。
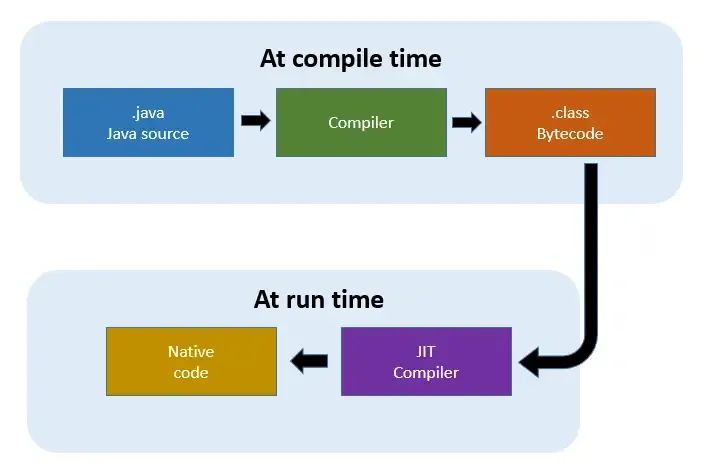
这为程序员提供了灵活性,同时避免了CPU所需的传统离线编译步骤。JIT还支持基于运行时信息的优化,综合效果将GPU开销降低到几乎为零。
相比之下,CPU必须坚持预编译的机器码,不能根据运行时行为自适应地重新编译,因此CPU的调度开销更高,灵活性也更差。
5、编程模型
与CPU相比,GPU还提供了一个更加出色的并行编程模型CUDA,开发人员可以更快速编写并行代码,而不必担心低级别的线程、同步和通信等问题。

CUDA和OpenCL提供C/ C++编程语言,其中代码专注于跨抽象线程的并行计算,凌乱的协调细节在幕后被无形地处理。
相反,CPU并行性要求使用OpenMP等库直接处理线程。在线程管理、锁和避免竞争条件方面,存在明显的额外复杂性。这使得从高层考虑并行性变得更加困难。
6、响应方式不同
CPU基本上是实时响应,对单任务的速度要求很高,所以就要用很多层缓存的办法来保证单任务的速度。
GPU往往采用的是批处理的机制,即:任务先排好队,挨个处理。

7、应用方向不同
CPU所擅长的像操作系统这一类应用,需要快速响应实时信息,需要针对延迟优化,所以晶体管数量和能耗都需要用在分支预测、乱序执行、低延迟缓存等控制部分。
GPU适合对于具有极高的可预测性和大量相似的运算以及高延迟、高吞吐的架构运算。目前广泛应用于三大应用市场:游戏、虚拟现实和深度学习。

一、游戏市场
游戏是GPU最早应用的领域之一。由于GPU在图像处理和物理效果方面具有天然优势,因此在游戏开发中,GPU被广泛用于游戏引擎和游戏渲染。在游戏中,GPU可以快速运算出大量的几何体、纹理、光影等数据,从而实现更加真实的画面效果。
二、虚拟现实市场
虚拟现实技术是一种将计算机生成的三维图像与真实世界相结合的技术。GPU在虚拟现实应用中,可以实现对虚拟世界的逼真渲染和物体运动控制。随着虚拟现实技术的不断发展,GPU在虚拟现实市场中的应用越来越广泛,尤其是在头戴式设备和沉浸式体验方面。
三、深度学习
深度学习是一种基于人工神经网络的机器学习算法。GPU在深度学习中,可以高效地训练神经网络,并通过大规模并行计算来加速训练过程。目前,随着GPU在深度学习中的应用不断扩展,它已成为训练深度学习模型的主要加速器。
另外,GPU还可以应用于自动驾驶、医疗影像分析、金融风控等领域。不过,由于不同应用场景对GPU性能的要求不同,因此在选择GPU时需要考虑其计算能力、功耗和应用领域等因素。需要根据任务类型选择最合适的GPU,并进行优化以发挥其性能优势。
▉国产GPU发展情况
国产GPU的发展落后于国产CPU,直到2014年4月,景嘉微才成功研发出国内首款国产高性能、低功耗GPU芯片-JM5400。

在国产GPU的开发中,GPU对CPU的依赖性和GPU的高研发难度,阻碍了该产业的快速发展。首先,GPU对CPU有依赖性。GPU结构没有控制器,必须由CPU进行控制调用才能工作,否则GPU无法单独工作。所以国产CPU较国产GPU先行一步是符合芯片产业发展逻辑的。
再者,GPU技术难度很高。Moor Insights & Strategy首席分析师莫海德曾表示:"相比CPU,开发GPU要更加困难,而GPU设计师、工程师和驱动程序的开发者都要更少。"国内人才缺口也是国产GPU发展缓慢的重要原因之一。
目前,中国的GPU芯片虽然在市场份额上仍然占据较小的比例,但国产GPU芯片的入局者也越来越多,越来越多的国内企业向图形处理领域转型,比如芯动科技、景嘉微等,国产GPU芯片也有了更好的发展机遇。
如今,随着一系列美国政策的实施,不少人看到了国产GPU芯片代替进口芯片的未来,并将开始多角度支持国内GPU芯片企业。根据最新统计数据,三家国产GPU企业壁仞科技、摩尔线程、沐曦仅仅获得的投资就已经超过100亿元,这说明着确实正在付出极大的努力投入到技术研发中。
目前看来,随着美国实施更多的出口管制措施,或将为"中国芯"崛起制造机会窗口,这可能导致英伟达在中国市场面临更大的竞争压力。

