
- 1iOS开发工具,ios开发类库_vjdevicespecificmedia
- 2测试开发-后端开发controller层与service层交互(六)_controller service
- 3拓展:赖世雄英语初级美语(上)
- 4nginx代理MySQL方法_nginx配置 mysql 代理访问 2002 - can't connect to server
- 5MySQL查看数据库表中的重复记录并删除_sql剔除重复手机号
- 6国产操作系统应用开发的现状和趋势分析_国产化开发程度怎么写
- 7DevEco Studio安装_deveco studio 4.0 release
- 8Linux操作系统选择(免费)_linux 系统选择
- 9ChatGPT底层架构Transformer技术及源码实现(三)
- 10Android.mk各种文件编译汇总_local_module_suffix
图像识别的可视化解释史
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达【导读】使用机器学习(ML)算法(尤其是现代深度学习)进行图像识别的最大挑战之一,是难以理解为什么一个特定的输入图像会产生它所预测的结果。我们为过去十年中最先进的图像解释技术整合了视觉界面,并对每种技术进行了简要描述。
过去11年中用于解释神经网络的最新方法是如何发展的呢?
本文在 Inception 网络图像分类器上尝试使用引导反向传播进行解释演示。 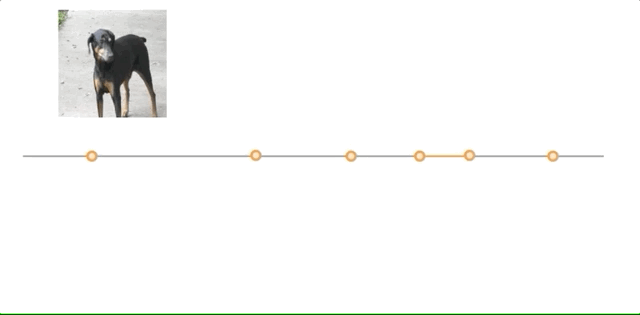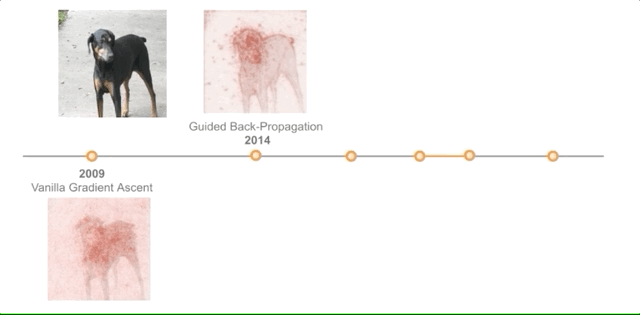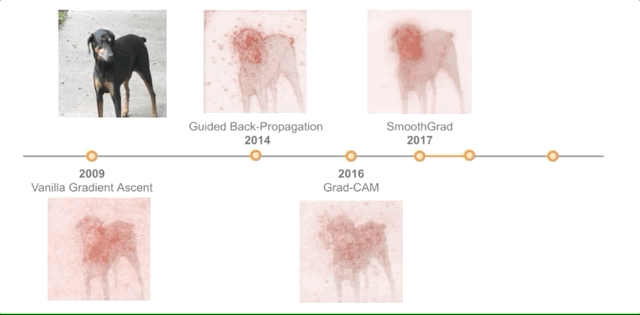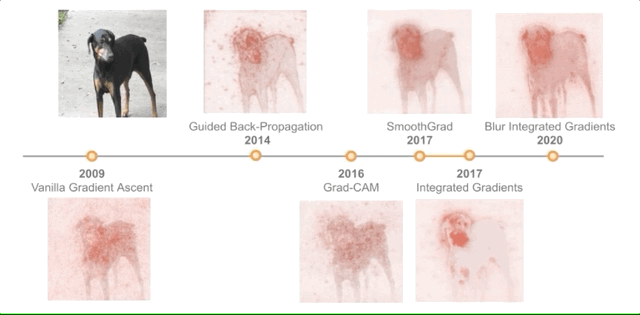
为什么「解释」很重要?
使用机器学习(ML)算法(尤其是现代深度学习)进行图像识别的最大挑战之一,是难以理解为什么一个特定的输入图像会产生它所预测的结果。
ML模型的用户通常想了解图像的哪些部分是预测中的重要因素。这些说明或“解释”之所以有价值,有很多原因:
机器学习开发人员可以分析调试模型的解释,识别偏差,并预测模型是否可能推广到新的图像
如果提供了为何做出特定预测的解释,则机器学习模型的用户可能会更信任模型
像 GDPR 这样围绕机器学习的规则要求一些算法决策能够用人类的术语来解释
因此,至少从2009年开始,研究人员就开发了许多不同的方法来打开深度学习的“黑匣子”,从而使基础模型更容易解释。
下面,我们为过去十年中最先进的图像解释技术整合了视觉界面,并对每种技术进行了简要描述。
我们使用了许多很棒的库,但是特别依赖 Gradio 来创建你在下面的 gif 文件和 PAIR-code 的 TensorFlow 实现中看到的接口。
用于所有接口的模型是Inception Net图像分类器,可以在此jupyter笔记本和Colab上找到复制此博客文章的完整代码。
在我们深入研究论文之前,让我们先从一个非常基本的算法开始。
七种不同的解释方法
Leave-one-out (LOO) 
Leave-one-out (LOO) 是最容易理解的方法之一。如果你想了解图像的哪个部分负责预测,这可能会是你想到的第一个算法。
其思想是首先将输入图像分割成一组较小的区域,然后,运行多个预测,每次都屏蔽一个区域。根据每个区域的「被屏蔽」对输出的影响程度,为每个区域分配一个重要性分数。这些分数是对哪个区域最负责预测的量化。
这种方法很慢,因为它依赖于运行模型的许多迭代,但是它可以生成非常准确和有用的结果。上面是杜宾狗的图片示例。
LOO是Gradio库中的默认解释技术,完全不需要访问模型的内部——这是一个很大的优点。
Vanilla Gradient Ascent [2009 and 2013] 
Paper: Visualizing Higher-Layer Features of a Deep Network [2009]
Paper: Visualizing Image Classification Models and Saliency Maps [2013]
这两篇论文的相似之处在于,它们都通过使用梯度上升来探索神经网络的内部。换句话说,它们认为对输入或激活的微小更改将增加预测类别的可能性。
第一篇论文将其应用于激活,作者报告说,「有可能找到对高级特征的良好定性解释, 我们证明,也许是违反直觉的,但这种解释在单位水平上是可能的,它很容易实现,并且各种技术的结果是一致的。」
第二种方法也采用梯度上升,但是直接对输入图像的像素点进行探测,而不是激活。
作者的方法「计算特定于给定图像和类的类显着性图,这样的地图可以使用分类ConvNets用于弱监督的对象分割。」
Guided Back-Propogation [2014]
Paper: Striving for Simplicity: The All Convolutional Net [2014]
本文提出了一种新的完全由卷积层构成的神经网络。由于以前的解释方法不适用于他们的网络,因此他们引入了引导式反向传播。
该反向传播可在进行标准梯度上升时过滤掉传播时产生的负激活。作者称,他们的方法「可以应用于更广泛的网络结构。」
Grad-CAM [2016]

Paper: Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization [2016]
接下来是梯度加权类激活映射(gradient-weighted class activation mapping,Grad-CAM) 。它利用「任何目标概念的梯度,流入最后的卷积层,生成一个粗糙的定位映射,突出图像中的重要区域,以预测概念。」
该方法的主要优点是进一步推广了可以解释的神经网络类(如分类网络、字幕和可视化问答(VQA)模型) ,以及一个很好的后处理步骤,围绕图像中的关键对象对解释进行集中和定位。
SmoothGrad [2017]

Paper: SmoothGrad: removing noise by adding noise [2017]
像前面的论文一样,此方法从计算类评分函数相对于输入图像的梯度开始。
但是,SmoothGrad通过在输入图像中添加噪声,然后针对图像的这些扰动版本中的每一个来计算梯度,从而在视觉上锐化这些基于梯度的灵敏度图。将灵敏度图平均在一起可以得到更清晰的结果。
Integrated Gradients [2017]

Paper: Axiomatic Attribution for Deep Networks [2017]
不同于以往的论文,本文的作者从解释的理论基础入手。它们「确定了归因方法应该满足的两个基本公理——敏感性和实现不变性」。
他们用这些原理来指导设计一种新的归属方法(称为综合梯度),该方法可以产生高质量的解释,同时仍然只需要访问模型的梯度; 但是它添加了一个「基线」超参数,这可能影响结果的质量。
Blur Integrated Gradients [2020]

Paper: Attribution in Scale and Space [2020]
论文研究了一个最新技术---- 这种方法被提出来用于解决具体的问题,包括消除「基线」参数,移除某些在解释中倾向于出现的视觉伪影。
此外,它还「在尺度/频率维度上产生分数」,本质上提供了图像中重要物体的尺度感。
下面这张图比较了所有这些方法: 
好消息!
小白学视觉知识星球
开始面向外开放啦
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

