
热门标签
热门文章
- 1使用opencv 进行图像美化_opencv窗口美化
- 2Vue3 的响应式和以前有什么区别,Proxy 无敌_reactive proxy array 区别 用处
- 3使用python 多进程进行基于websocket 的实时视频流处理
- 4zdhadljaljdjadajdjald
- 5Android studio虚拟机报错:emulator:PANIC:cannot find AVD system path.please define ANDROID_SDK_ROOT_emulator: error: no avd specified.
- 6分布式&数据结构与算法面试题_分布式更多的一个概念,是为了解决单个物理服务器容量和性能瓶颈问题而采用的优化
- 7.netcore3.1 设置可跨域_.net core 3.1 允许跨域
- 8假设检验_到底该怎么理解假设检验?
- 9MQ-2烟雾传感器模块功能实现(STM32)_mq2
- 10逻辑回归(logistic regression)与正规化方程_回归 正规化
当前位置: article > 正文
使用迁移学习的方法来训练自己的数据集_迁移训练怎么做
作者:我家小花儿 | 2024-03-22 11:34:04
赞
踩
迁移训练怎么做
使用 ImageFolder 类加载图像数据集,其中指定了对应的变换操作,最后通过 DataLoader 类来创建数据加载器,以便于在训练过程中以批次方式获取数据。用到的预训练的模型:efficientnet_b4(模型可以根据自己的需要进行更改)
数据集:只要是分类问题的数据集都可以!
可以在kaggle上或者在本地上运行,建议使用kaggle(比较方便而且还有免费的数据集)
第一步:
导入依赖的库文件
- import warnings
- warnings.filterwarnings('ignore')
- !pip install efficientnet_pytorch
- import pandas as pd
- import matplotlib.pyplot as plt
- import seaborn as sns
- import random
- import torch
- import torch.nn as nn
- import torch.optim as optim
- !pip install vision-transformer-pytorch
- from torchvision import transforms, models
- from sklearn.metrics import classification_report
- from sklearn.utils import shuffle
- from sklearn.metrics import confusion_matrix
- import seaborn as sns
- from torch.utils.tensorboard import SummaryWriter
- from torch.optim.lr_scheduler import ReduceLROnPlateau
- import numpy as np
- from tabulate import tabulate
- import os
- import glob
- import json
- import shutil
- from PIL import Image, ImageDraw
- import torchvision.transforms as transforms
- from torchvision.datasets import ImageFolder
- from torch.utils.data import DataLoader
- from efficientnet_pytorch import EfficientNet

第二步:
定义配置文件,训练模型时使用到的超参数
- #定义配置文件
- class Config:
- def __init__(self):
- #设置输入图像的大小
- self.image_width = 64
- self.image_height = 64
- self.epoch = 3 #训练的次数,可以根据实际情况进行调整
- self.seed = 42
- self.batch_size = 32 #batchsize的大小会影响最后的输出的长度,如batch_size=32,最后输出为#32*1,32个样本作为1组进行输出,最后应该是一维的向量,长度是batch_size的大小
- self.dataset_path = '这里是数据集的路径,如path/to/mydatasets/'
- # self.checkpoint_filepath = 'model_checkpoint.h5'
- # self.logs_path = '/kaggle/working/logs'
-
- #实例化配置函数
- config = Config()
-
- print("Checking Epoch Configuration:", config.epoch)
第三步:数据集的准备及预处理
- #遍历dataset_path路径目录下的图像文件,提取这些图像的路径、状态和位置信息
- #然后将这些信息存储在一个 Pandas DataFrame 中,以方便后续对数据的处理和分析。
-
- #其中包含3个键值对,分别存储图像的路径,图像的状态,图像所在的位置信息
- dataset = {"image_path":[],"img_status":[],"where":[]}#创建字典
-
- for where in os.listdir(config.dataset_path):
- for status in os.listdir(config.dataset_path+"/"+where):
- #使用 glob.glob 函数获取符合特定条件(以.jpg为扩展名)的图像文件的路径。
- for image in glob.glob(os.path.join(config.dataset_path, where, status, "*.jpg")):
- #将每个图像的路径、状态和位置信息分别添加到 dataset 字典对应的列表中。
- dataset["image_path"].append(image)
- dataset["img_status"].append(status)
- dataset["where"].append(where)
- #将字典转换为 Pandas DataFrame,其中每个键对应 DataFrame 的一列。
- #最终,每行包含一个图像的路径、状态和位置信息。
- dataset = pd.DataFrame(dataset)
-
-
- # 将数据集进行打乱
- dataset = shuffle(dataset)
-
- # 重新设置索引,并将原来的索引丢弃,使索引重新按照顺序排列
- dataset = dataset.reset_index(drop=True)
- # 对训练集-数据集进行数据增强
- train_transform = transforms.Compose([
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
- ])
- # 12/05 定义一些增强操作
- train_transform = transforms.Compose([
- transforms.RandomHorizontalFlip(), # 随机水平翻转
- transforms.RandomRotation(degrees=15), # 随机旋转
- transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 颜色扭曲
- #transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)), # 随机裁剪和缩放
- transforms.ToTensor(), # 转换为张量
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
- ])
- # Data Transformation for Validation and Testing
- val_test_transform = transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
- ])
-
- # Data Loaders使用 ImageFolder 类加载图像数据集,其中指定了对应的变换操作
- #最后通过 DataLoader 类来创建数据加载器,以便于在训练过程中以批次方式获取数据
- train_dataset = ImageFolder(os.path.join(config.dataset_path, 'train'), transform=train_transform)
- train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)
-
- valid_dataset = ImageFolder(os.path.join(config.dataset_path, 'valid'), transform=val_test_transform)
- valid_loader = DataLoader(valid_dataset, batch_size=config.batch_size, shuffle=False)
-
- test_dataset = ImageFolder(os.path.join(config.dataset_path, 'test'), transform=val_test_transform)
- test_loader = DataLoader(test_dataset, batch_size=5, shuffle=False)
- #train
- print("Train Dataset: ", train_dataset)
- print("Train Loader: ", train_loader)
-
- #valid
- print("Valid Dataset: ", valid_dataset)
- print("Valid Loader: ", valid_loader)
-
- #test
- print("Test Dataset: ", test_dataset)
- print("Test Loader: ", test_loader)
第四步:
定义训练模型,MyModel类通过扩展nn来定义神经网络模型。模块利用预先训练的模型架构,替换其完全连接的层,提供可视化,并总结其架构和参数。
- class MyModel(nn.Module):
- def __init__(self, model_name, num_classes):
- super(MyModel, self).__init__()
- self.model = models.__dict__[model_name](pretrained=True)
- #vgg模型
- if 'vgg' in model_name:
- num_features = self.model.classifier[6].in_features
- self.model.classifier[6] = nn.Sequential(
- nn.Linear(num_features, 512),
- nn.ReLU(),
- nn.BatchNorm1d(512),
- nn.Linear(512, num_classes)
- )
- #mobilenet模型
- elif 'mobilenet' in model_name:
- num_features = self.model.classifier[1].in_features
- self.model.classifier = nn.Sequential(
- nn.Linear(num_features, 512),
- nn.ReLU(),
- nn.BatchNorm1d(512),
- nn.Linear(512, num_classes)
- )
- #efficientnet模型
- elif 'efficientnet_b4' in model_name:
- # 加载预训练的 EfficientNet 模型
- self.model = EfficientNet.from_pretrained('efficientnet-b4')
- feature = self.model._fc.in_features
- self.model._fc = nn.Linear(in_features=feature, out_features=num_classes, bias=True)
-
- #print(model)
- #vision transformer 模型,目前没有调试正确,上面的3个模型都可以试一下,均可以运行
- elif 'vit' in model_name:
- # Use the correct name for the Vision Transformer model
- # Define the pre-trained ViT model string
- model_str = 'google/vit-base-patch16-224-in21k'
-
- # Create a processor for ViT model input from the pre-trained model
- processor = ViTImageProcessor.from_pretrained(model_str)
- self.vit_model = vision_transformer.vit_base_patch16_224(pretrained=True)
- in_features = self.vit_model.head.in_features
- self.vit_model.head = nn.Linear(in_features, num_classes)
-
- else:
- num_features = self.model.fc.in_features
- self.model.fc = nn.Sequential(
- nn.Linear(num_features, 512),
- nn.ReLU(),
- nn.BatchNorm1d(512),
- nn.Linear(512, num_classes)
- )
-
- self.val_loss = []
- self.val_accuracy = []
- self.test_loss = []
- self.test_accuracy = []
- self.train_loss = []
- self.train_accuracy = []
-
- def forward(self, x):
- return self.model(x)
-
- def print_model_summary(self):
- print(self.model)
- print("Model Summary:")
- total_params = sum(p.numel() for p in self.parameters())
- print(f"Total Parameters: {total_params}")
- trainable_params = sum(p.numel() for p in self.parameters() if p.requires_grad)
- print(f"Trainable Parameters: {trainable_params}")
-
- def plot_metrics_graph(self):
- epochs = range(1, len(self.train_loss) + 1)
-
- plt.figure(figsize=(12, 8))
-
- plt.subplot(2, 1, 1)
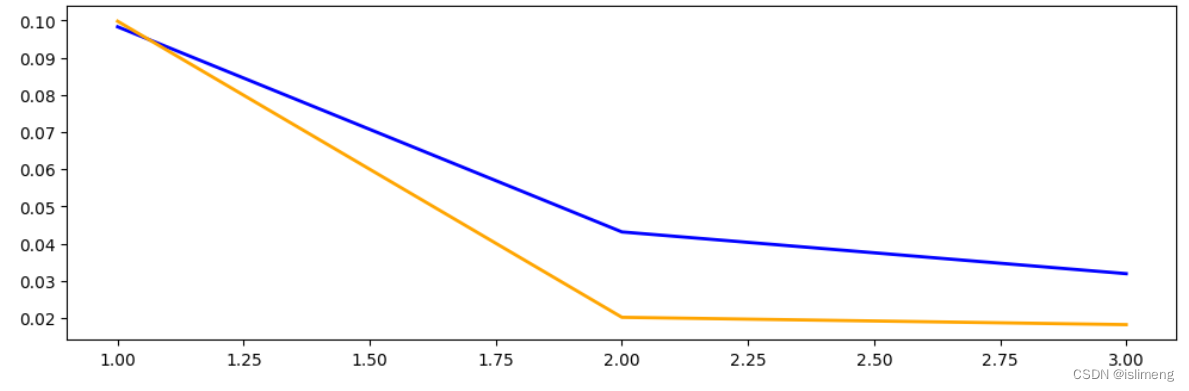
- plt.plot(epochs, self.train_loss, label='Train Loss', linewidth=2, color='blue')
- plt.plot(epochs, self.val_loss, label='Validation Loss', linewidth=2, color='orange')
- plt.plot(epochs, self.test_loss, label='Test Loss', linewidth=2, color='green')
- plt.xlabel('Epochs')
- plt.ylabel('Loss')
- plt.title('Training ,Test and Validation Loss')
- plt.legend()
-
- plt.subplot(2, 1, 2)
- plt.plot(epochs, self.train_accuracy, label='Train Accuracy', linewidth=2, color='green')
- plt.plot(epochs, self.val_accuracy, label='Validation Accuracy', linewidth=2, color='red')
- plt.xlabel('Epochs')
- plt.ylabel('Accuracy')
- plt.title('Training and Validation Accuracy')
- plt.legend()
-
- plt.tight_layout()
- plt.show()
-
- def plot_confusion_matrix(self, y_true, y_pred):
- cm = confusion_matrix(y_true, y_pred)
-
- plt.figure(figsize=(8, 6))
- sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", cbar=False)
- plt.xlabel("Predicted Labels")
- plt.ylabel("True Labels")
- plt.title("Confusion Matrix")
- plt.show()
-
- def train_model(self, train_loader, valid_loader, num_epochs, device):
- criterion = nn.BCEWithLogitsLoss() # Binary Cross-Entropy loss
- optimizer = optim.Adam(self.parameters(), lr=0.001)
-
- scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.2, patience=3, verbose=True, min_lr=1e-6)
-
- for epoch in range(num_epochs):
- self.train() # Set the model to training mode
- total_loss = 0.0
- correct_train = 0
- total_train = 0
-
- print(f"Epoch [{epoch+1}/{num_epochs}] - Training...")
-
- for batch_idx, (inputs, labels) in enumerate(train_loader):
- inputs, labels = inputs.to(device), labels.to(device)
-
- optimizer.zero_grad()
- outputs = self(inputs)
- loss = criterion(outputs, labels.float().unsqueeze(1))
- loss.backward()
- optimizer.step()
-
- total_loss += loss.item() * inputs.size(0)
- predicted_labels = (outputs >= 0.0).float()
- correct_train += (predicted_labels == labels.float().unsqueeze(1)).sum().item()
- total_train += labels.size(0)
-
- print(f"Epoch [{epoch+1}/{num_epochs}] - Batch [{batch_idx+1}/{len(train_loader)}] - "
- f"Loss: {loss.item():.4f} - Train Accuracy: {correct_train / total_train:.4f}")
-
- average_loss = total_loss / len(train_loader.dataset)
- train_accuracy = correct_train / total_train
-
- self.train_loss.append(average_loss)
- self.train_accuracy.append(train_accuracy)
-
- self.eval()
- total_val_loss = 0.0
- correct_val = 0
- total_val = 0
-
- y_true = []
- y_pred = []
-
- with torch.no_grad():
- for inputs, labels in valid_loader:
- inputs, labels = inputs.to(device), labels.to(device)
- outputs = self(inputs)
- val_loss = criterion(outputs, labels.float().unsqueeze(1))
- total_val_loss += val_loss.item() * inputs.size(0)
- predicted_labels = (outputs >= 0.0).float()
- correct_val += (predicted_labels == labels.float().unsqueeze(1)).sum().item()
- total_val += labels.size(0)
-
- y_true.extend(labels.float().unsqueeze(1).cpu().numpy())
- y_pred.extend(predicted_labels.cpu().numpy())
-
- average_val_loss = total_val_loss / len(valid_loader.dataset)
- val_accuracy = correct_val / total_val
-
- self.val_loss.append(average_val_loss)
- self.val_accuracy.append(val_accuracy)
-
- print(f"Epoch [{epoch+1}/{num_epochs}] - "
- f"Train Loss: {average_loss:.4f} - Train Accuracy: {train_accuracy:.4f} - "
- f"Val Loss: {average_val_loss:.4f} - Val Accuracy: {val_accuracy:.4f} - "
- f"LR: {scheduler.optimizer.param_groups[0]['lr']:.6f}")
-
- scheduler.step(average_val_loss)
-
- self.plot_metrics_graph()
- self.plot_confusion_matrix(y_true, y_pred)
将模型加载到cpu上
- # Instantiate the mymodel model
-
- #num_classes = 1# Change this to your number of classes,全连接这里应该是1
- #model_name = "resnet18" # Change this to any model available in torchvision
- #model_name = "vgg16"
-
- num_classes = 1
- model_name = "efficientnet_b4"
- model = MyModel(model_name=model_name, num_classes=num_classes)
-
- # Move the model to GPU if available
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- model.to(device)
-
- # Print model summary
- #model.print_model_summary()
训练模型并保存训练好的参数
- # Train the model using the integrated training loop
- num_epochs = config.epoch # Change this in last
- model.train_model(train_loader, valid_loader, num_epochs, device)
-
- torch.save(model.state_dict(), 'model_efficient_b4.pth')
完成!
代码直接一行行拷贝,粘贴,运行就可咯~
对于使用vit进行训练,暂时没有更改正确,先挖坑,后续会了再填坑
2023.12.10
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/287850
推荐阅读
相关标签

