
- 1Unity禁止移动端多点触控_unity如何限制拖拽的时候多点触控
- 2vue项目部署到服务器二级目录_vue部署二级目录
- 3HarmonyOS的生命周期有哪些?HarmonyOS的生命周期
- 4AI与医学辅助诊断_医学智能辅助诊断
- 5语言能力测试C1,本科生实验实践能力测试计算机实验实践能力(C1-1级)达.PDF...
- 6深度学习图片数据集分析手段--个人经验小结
- 7Android Studio中的keystore_android studio default.storage 默认口令是什么
- 8C#版支持高并发的HTTP服务器的示例源代码
- 9大模型笔记之-低成本部署CharGLM3|chatglm.cpp基于ggml 的纯 C++ 实现_chatglm3 低成本部署
- 10CSS3动画学习笔记_transform: rotate(-20deg);
【机器学习-04】最小二乘法的推导过程及使用方法(python代码实现)
赞
踩
最小二乘法是一种常用的数据拟合方法,它可以通过最小化残差平方和来找到数据的最佳拟合线。有了上述内容铺垫之后,本文将介绍最小二乘法的推导过程,并提供使用Python实现最小二乘法的代码示例。
1.模型及方程组的矩阵形式改写
首先,我们对 f ( x ) = w 1 x 1 + w 2 x 2 + . . . + w d x d + b f(x) = w_1x_1+w_2x_2+...+w_dx_d+b f(x)=w1x1+w2x2+...+wdxd+b模型进行矩阵形式改写。
- 模型改写称矩阵表达式
首先,假设多元线性方程有如下形式
f
(
x
)
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
d
x
d
+
b
f(x) = w_1x_1+w_2x_2+...+w_dx_d+b
f(x)=w1x1+w2x2+...+wdxd+b
令
w
=
[
w
1
,
w
2
,
.
.
.
w
d
]
T
w = [w_1,w_2,...w_d]^T
w=[w1,w2,...wd]T,
x
=
[
x
1
,
x
2
,
.
.
.
x
d
]
T
x = [x_1,x_2,...x_d]^T
x=[x1,x2,...xd]T,则上式可写为
f ( x ) = w T x + b f(x) = w^Tx+b f(x)=wTx+b
在机器学习领域,我们使用线性回归模型来建模自变量和因变量之间的关系。在这个模型中,我们引入自变量的系数,通常被称为权重(weight)。这些权重反映了自变量对因变量的影响程度。因此,我们将线性回归模型中的自变量系数命名为w,这是“weight”的简写。通过调整这些权重,我们可以控制自变量对因变量的贡献程度,从而更好地拟合数据并进行预测。
- 将带入数据后的方程组改写为矩阵方程
并且,假设现在总共有m条观测值,
x
(
i
)
=
[
x
1
(
i
)
,
x
2
(
i
)
,
.
.
.
,
x
d
(
i
)
]
x^{(i)} = [x_1^{(i)}, x_2^{(i)},...,x_d^{(i)}]
x(i)=[x1(i),x2(i),...,xd(i)],则带入模型可构成m个方程:

然后考虑如何将上述方程组进行改写,首先,我们可令
w
^
=
[
w
1
,
w
2
,
.
.
.
,
w
d
,
b
]
T
\hat w = [w_1,w_2,...,w_d,b]^T
w^=[w1,w2,...,wd,b]T
x
^
=
[
x
1
,
x
2
,
.
.
.
,
x
d
,
1
]
T
\hat x = [x_1,x_2,...,x_d,1]^T
x^=[x1,x2,...,xd,1]T
X ^ = [ x 1 ( 1 ) x 2 ( 1 ) . . . x d ( 1 ) 1 x 1 ( 2 ) x 2 ( 2 ) . . . x d ( 2 ) 1 . . . . . . . . . . . . 1 x 1 ( m ) x 2 ( m ) . . . x d ( m ) 1 ] \hat X = \left [x(1)1x(1)2...x(1)d1x(2)1x(2)2...x(2)d1............1x(m)1x(m)2...x(m)d1\right] X^= x1(1)x1(2)...x1(m)x2(1)x2(2)...x2(m)............xd(1)xd(2)...xd(m)1111
y = [ y 1 y 2 . . . y m ] y = \left [y1y2...ym\right] y= y1y2...ym
y ^ = [ y ^ 1 y ^ 2 . . . y ^ m ] \hat y = \left [ˆy1ˆy2...ˆym\right] y^= y^1y^2...y^m
其中
- w ^ \hat w w^:方程系数所组成的向量,并且我们将自变量系数和截距放到了一个向量;
- x ^ \hat x x^:方程自变量和1共同组成的向量;
- X ^ \hat X X^:样本数据特征构成的矩阵,并在最后一列添加一个全为1的列;
- y y y:样本数据标签所构成的列向量;
- y ^ \hat y y^:预测值的列向量。
因此,上述方程组可表示为
X
^
⋅
w
^
=
y
^
\hat X \cdot \hat w = \hat y
X^⋅w^=y^
- 模型进一步改写
在改写了 x ^ \hat x x^和 w ^ \hat w w^之后,线性模型也可以按照如下形式进行改写:
f ( x ^ ) = w ^ T ⋅ x ^ f(\hat x) = \hat w^T \cdot \hat x f(x^)=w^T⋅x^
2.构造损失函数
在方程组的矩阵表示基础上,我们可以以SSE作为损失函数基本计算流程构建关于
w
^
\hat w
w^的损失函数:
S
S
E
L
o
s
s
(
w
^
)
=
∣
∣
y
−
X
w
^
∣
∣
2
2
=
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
SSELoss(\hat w) = ||y - X\hat w||_2^2 = (y - X\hat w)^T(y - X\hat w)
SSELoss(w^)=∣∣y−Xw^∣∣22=(y−Xw^)T(y−Xw^)
需要补充两点基础知识:
- 向量的2-范数计算公式
上式中, ∣ ∣ y − X w ^ T ∣ ∣ 2 ||y - X\hat w^T||_2 ∣∣y−Xw^T∣∣2为向量的2-范数的计算表达式。向量的2-范数计算过程为各分量求平方和再进行开平方。例如 a = [ 1 , − 1 , ] a=[1, -1,] a=[1,−1,],则 ∣ ∣ a ∣ ∣ 2 = 1 2 + ( − 1 ) 2 = 2 ||a||_2= \sqrt{1^2+(-1)^2}=\sqrt{2} ∣∣a∣∣2=12+(−1)2 =2 。
向量的1-范数为各分量绝对值之和。值得注意的是,矩阵也有范数的概念,不过矩阵的范数计算要比向量复杂得多。
- 2-范数计算转化为内积运算
向量的2-范数计算结果其实就是向量(将其是做矩阵)的交叉乘积计算结果后开平方。例如, a = [ 1 , − 1 ] a=[1, -1] a=[1,−1],则 a a a的交叉乘积为 a ⋅ a T = [ 1 , − 1 ] ⋅ [ 1 − 1 ] = 2 a \cdot a^T = [1, -1] \cdot \left [1−1\right]=2 a⋅aT=[1,−1]⋅[1−1]=2,开平方后等于其2-范数计算结果。
3.最小二乘法求解损失函数的一般过程
在确定损失函数的矩阵表示形式之后,接下来即可利用最小二乘法进行求解。其基本求解思路仍然和Lesson 0中介绍的一样,先求导函数、再令导函数取值为零,进而解出参数取值。只不过此时求解的是矩阵方程。
在此之前,需要补充两点矩阵转置的运算规则:
(
A
−
B
)
T
=
A
T
−
B
T
(A-B)^T=A^T-B^T
(A−B)T=AT−BT
(
A
B
)
T
=
B
T
A
T
(AB)^T=B^TA^T
(AB)T=BTAT
接下来,对
S
S
E
L
o
s
s
(
w
)
SSELoss(w)
SSELoss(w)求导并令其等于0:
S
S
E
L
o
s
s
(
w
^
)
∂
w
^
=
∂
∣
∣
y
−
X
w
^
∣
∣
2
2
∂
w
^
=
∂
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
∂
w
^
=
∂
(
y
T
−
w
^
T
X
T
)
(
y
−
X
w
^
)
∂
w
^
=
∂
(
y
T
y
−
w
^
T
X
T
y
−
y
T
X
w
^
+
w
^
T
X
T
X
w
^
)
∂
w
^
=
0
−
X
T
y
−
X
T
y
+
X
T
X
w
^
+
(
X
T
X
)
T
w
^
=
0
−
X
T
y
−
X
T
y
+
2
X
T
X
w
^
=
2
(
X
T
X
w
^
−
X
T
y
)
=
0
SSELoss(ˆw)∂ˆw=∂||y−Xˆw||22∂ˆw=∂(y−Xˆw)T(y−Xˆw)∂ˆw=∂(yT−ˆwTXT)(y−Xˆw)∂ˆw=∂(yTy−ˆwTXTy−yTXˆw+ˆwTXTXˆw)∂ˆw=0−XTy−XTy+XTXˆw+(XTX)Tˆw=0−XTy−XTy+2XTXˆw=2(XTXˆw−XTy)=0
∂w^SSELoss(w^)=∂w^∂∣∣y−Xw^∣∣22=∂w^∂(y−Xw^)T(y−Xw^)=∂w^∂(yT−w^TXT)(y−Xw^)=∂w^∂(yTy−w^TXTy−yTXw^+w^TXTXw^)=0−XTy−XTy+XTXw^+(XTX)Tw^=0−XTy−XTy+2XTXw^=2(XTXw^−XTy)=0
即
X
T
X
w
^
=
X
T
y
X^TX\hat w = X^Ty
XTXw^=XTy
要使得此式有解,等价于
X
T
X
X^TX
XTX(也被称为矩阵的交叉乘积crossprod存在逆矩阵,若存在,则可解出
w
^
=
(
X
T
X
)
−
1
X
T
y
\hat w = (X^TX)^{-1}X^Ty
w^=(XTX)−1XTy
4.最小二乘法的简单实现(python实现)
使用方法: 现在我们将使用Python来实现最小二乘法,并拟合一组数据点。 首先,导入必要的库: import numpy as np 接下来,定义数据点: x = np.array([1, 2, 3, 4, 5]) y = np.array([2, 3, 5, 6, 8]) 然后,计算最小二乘法的参数: n = len(x) m = (n * np.sum(x * y) - np.sum(x) * np.sum(y)) / (n * np.sum(x**2) - np.sum(x)**2) b = (np.sum(y) - m * np.sum(x)) / n 最后,打印拟合的直线方程: print(f"拟合直线方程:y = {m}x + {b}") 运行代码,将得到拟合的直线方程。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
【补充阅读】简单线性回归方程的参数计算
如果是简单线性回归,方程组形式也可快速推导自变量系数与截距。在简单线性回归中,w只包含一个分量,x也只包含一个分量,我们令此时的 x i x_i xi就是对应的自变量的取值,此时求解过程如下
损失函数为:
S
S
E
L
o
s
s
=
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
SSELoss = \sum^m_{i=1}(f(x_i)-y_i)^2
SSELoss=i=1∑m(f(xi)−yi)2
通过偏导为零求得最终结果的最小二乘法求解过程为:
∂
S
S
E
(
w
,
b
)
∂
(
w
)
=
2
(
w
∑
i
=
1
m
x
i
2
−
∑
i
=
1
m
(
y
i
−
b
)
x
i
)
=
0
∂SSE(w,b)∂(w)=2(wm∑i=1x2i−m∑i=1(yi−b)xi)=0
∂(w)∂SSE(w,b)=2(wi=1∑mxi2−i=1∑m(yi−b)xi)=0
∂ S S E ( w , b ) ∂ ( b ) = 2 ( m b − ∑ i = 1 m ( y i − w x i ) ) = 0 ∂SSE(w,b)∂(b)=2(mb−m∑i=1(yi−wxi))=0 ∂(b)∂SSE(w,b)=2(mb−i=1∑m(yi−wxi))=0
进而可得
w
=
∑
i
=
1
m
y
i
(
x
i
−
x
ˉ
)
∑
i
=
1
m
x
i
2
−
1
m
(
∑
i
=
1
m
x
i
)
2
w = \frac{\sum^m_{i=1}y_i(x_i-\bar{x}) }{\sum^m_{i=1}x^2_i-\frac{1}{m}(\sum^m_{i=1}x_i)^2 }
w=∑i=1mxi2−m1(∑i=1mxi)2∑i=1myi(xi−xˉ)
b = 1 m ∑ i = 1 m ( y i − w x i ) b = \frac{1}{m}\sum^m_{i=1}(y_i-wx_i) b=m1i=1∑m(yi−wxi)
其中, x ˉ = 1 m ∑ i = 1 m x i , x i \bar x = \frac{1}{m}\sum^m_{i=1}x_i,x_i xˉ=m1∑i=1mxi,xi为x的均值,并且 ( x i , y i ) (x_i,y_i) (xi,yi)代表二维空间中的点。此外,我们也可以通过前文介绍的 w ^ = ( X T X ) − 1 X T y \hat w = (X^TX)^{-1}X^Ty w^=(XTX)−1XTy结论,通过设置 w w w为两个分量的参数向量反向求解对应方程表达式来进行求解。
【补充阅读】简单线性回归的“线性”与“回归”形象理解
对于简单线性回归来说,由于模型可以简单表示为 y = w x + b y=wx+b y=wx+b形式,因此我们可以用二维平面图像来进行对应方程的函数图像绘制。例如,当模型为 y = x + 1 y=x+1 y=x+1时,函数图像如下所示:
import matplotlib as mpl
import matplotlib.pyplot as plt
x = np.arange(-5,5,0.1)
y = x + 1
plt.plot(x, y, '-', label='y=x+1')
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc = 2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

于此同时,我们的建模数据为:
| Whole weight | Rings |
|---|---|
| 1 | 2 |
| 3 | 4 |
将特征是为x、将标签是为y,则绘制图像可得:
# 绘制对应位置元素点图
A = np.arange(1, 5).reshape(2, 2)
plt.plot(A[:,0], A[:, 1], 'ro')
# 线性回归直线
plt.plot(x, y, '-', label='y=x+1')
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc = 2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

由于模型方程是基于满足数据中x和y基本关系构建的,因此模型这条直线最终将穿过这两个点。而简单线性回归的几何意义,就是希望找到一条直线,尽可能的接近样本点。或者说,我们是通过一条直线去捕捉平面当中的点。当然,大多数情况下我们都无法对平面中的点进行完全的捕捉,而直线和点之间的差值,实际上就是SSE。
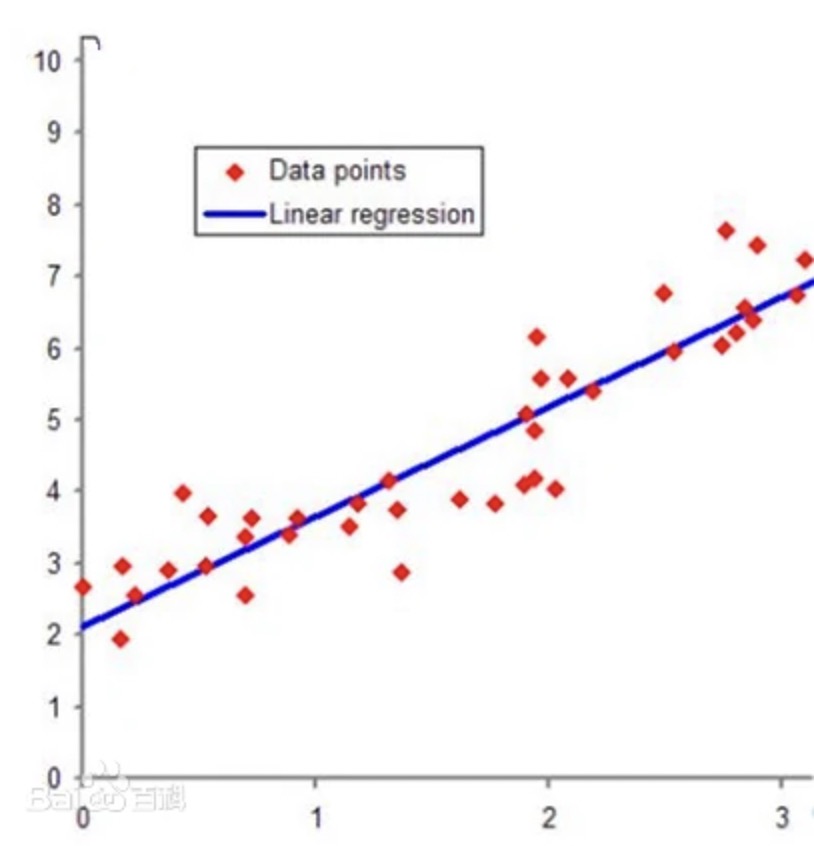
而线性回归中回归的含义,则是:如果模型真实有效,则新数据也会像朝向这条直线“回归”一样,最终分布在这条直线附近。这就是简单线性回归中的“线性”和“回归”的形象理解。
当然,对于线性回归中的参数b,其实是bias(偏差或者截距)的简写,当x去职位0时,y=b,就好像直线在y轴上的截距,或者距离y=0的偏差。
形象理解只是辅助理解,若要从机器学习角度建好一个线性回归模型,需要从特征加权求和汇总角度理解模型本质。

