
- 1时间仓促的mybatis plus到mybatis的源码走读_mybatis plus 读源码
- 2C语言第三十一弹---自定义类型:结构体(下)
- 3分布式数据库的应用场景_分布式数据库应用实例
- 4Elasticsearch:使用 Streamlit、语义搜索和命名实体提取开发 Elastic Search 应用程序
- 5Android属性(property)机制_android property有两个值
- 6Linux网络协议原理_linux、tcp/ip、http、dns等常用协议的传输原理
- 7Wechaty 社区开源协作最佳实践指南
- 8AIDL使用教程一(传递默认类型数据)_aidl传递数组
- 9Mysql 索引_mysql索引
- 10堡垒机登录服务器_通过 堡垒机 访问内网web
Text-to-3D Generation_zero-shot text-guided object generation with dream
赞
踩
1 NeRF-based
1)《Zero-shot text-guided object generation with dream fields》【CVPR 2023】
Project:https://ajayj.com/dreamfields
Device:未公布
前置知识:伪影(Artifacts)是指本不存在却出现在的影像片子上的一种成像。在图像生成领域中,可以理解是合成图片中,不自然的、反常的、能让人看出是人为处理过的痕迹、区域、瑕疵等。
摘要:我们将神经渲染与多模态图像-文本对相结合,仅从自然语言描述中合成不同的三维对象。Dream fields,可以在没有三维监督下生成广泛的几何和颜色的对象。以前的方法由于缺少多种标题的3D数据,只从少数类别中生成对象,如ShapeNet。相反,我们使用预训练的CLIP,从许多相机姿态下优化神经辐射场。为了提高保真度和视觉质量,我们引入了简单的几何先验,包括稀疏诱导的透明度正则化、场景边界和新MLP架构。
贡献:
不需要3D数据监督,或者多视角图像,只使用图像文本对模型(CLIP)来优化NeRF
引入了几种几何先验: sparsity-inducing transmittance regularization, scene bounds, and new MLP architectures
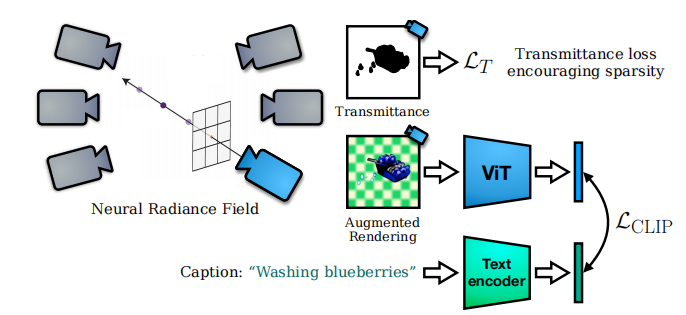
方法总体框架如上。对于给定一个文本caption,使用pre-trained CLIP text encoder编码可以得到一个 text embedding, 随意采样一个pose,经过NeRF可以渲染出一个image,这个image经过ViT后得到了一个image embedding,因为一个目标而言的语义是view-independent (“a bulldozer is a bulldozer from any perspective”),所以可以直接用Lclip监督这两个embedding。也就是类似[1],在feature space上计算rendered image和real image的相似度。这里的损失如下:
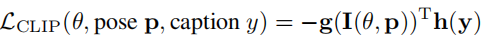
g(·)和h(·)分别是CLIP的两个encoder,I(θ,p)是给定一个pose后NeRF渲染出的图像,y是文本caption。
在输入多个图像训练时,原始的NeRF的重构损失可以学习去除伪密度这种伪影。但是只用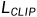 在一个pose下训练时,NeRF的场景表征就太不受约束了,它会生成严重的伪影,这种伪影可以满足,但在人类的视觉系统下是有问题的。见下图,(b)为不加几何先验时的效果,(c)为加入几何先验时的效果。NeRF学习高频和近场伪影,如部分透明的“浮动”密度区域。它还会填充整个图像而不是生成单个目标。总之就是生成的几何是不真实的,尽管其中的纹理信息能能够反映出caption。
在一个pose下训练时,NeRF的场景表征就太不受约束了,它会生成严重的伪影,这种伪影可以满足,但在人类的视觉系统下是有问题的。见下图,(b)为不加几何先验时的效果,(c)为加入几何先验时的效果。NeRF学习高频和近场伪影,如部分透明的“浮动”密度区域。它还会填充整个图像而不是生成单个目标。总之就是生成的几何是不真实的,尽管其中的纹理信息能能够反映出caption。

因此,为了去除近场伪影和伪密度,作者对渲染的不透明度进行正则化。目标是最大限度地使通过物体的光线的平均透射率达到一个目标常数τ。因此总的损失函数如下:
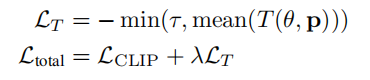
几个tricks:
当渲染在训练过程中使用白色或黑色背景进行alpha合成时,场景会发生扩散现象,作者提出用随机的背景增强会得到相一致的物体。
NeRF的损失训练出的场景,目标是在场景中心的。但是Dream Field训练出的场景,目标会在远离场景中心的地方,因为CLIP的训练数据中的自然图像并不总是集中在中心。因此,为了防止物体漂移太远,通过对密度
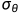 进行掩膜将场景绑定在一个立方体内。
进行掩膜将场景绑定在一个立方体内。
对原始NeRF的MLP结构的优化:使用残差MLP。在残差块中,作者发现在开始时引入layer normalization并增加bottleneck的特征维数是有益的。layer normalization优化了过于透明的区域梯度消失的问题。
[1] Ajay Jain, Matthew Tancik, and Pieter Abbeel. Putting nerf on a diet: Semantically consistent few-shot view synthesis. ICCV, 2021.
2) 《DreamBooth3D: Subject-Driven Text-to-3D Generation》【CVPR 2023】
Author:谷歌
Device:3 hours per prompt on 4 core TPUv4 (4 core $12.88/hour)≈训练一次要花270RMB
Code:未开源
本文的任务是 personalize text-to-3D,就是将DreamBooth[1]和Dreamfusion进行结合,为了实现这样的结合,作者提出了如下的三阶段的优化策略。
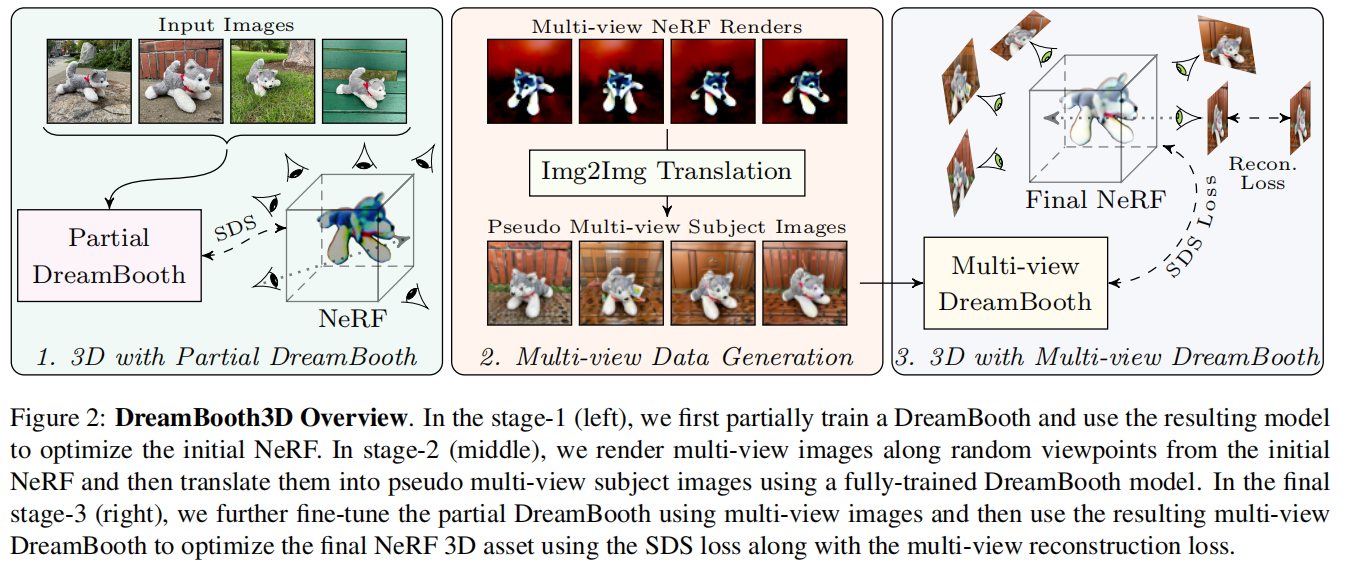
第一步是利用输入的图像和DreamBooth优化一个NeRF,第二步是利用这个NeRF生成多个视角的图像,最后一步利用这个NeRF和这些数据来优化DreamBooth3D。整体来看,有点A+B的感觉,创新性不高。
[1] Ruiz N, Li Y, Jampani V, et al. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation[J]. arXiv preprint arXiv:2208.12242, 2022.
2 Diffusion-based
2.1 Diffusion-based 3D Generation
1)《Dreamfusion: Text-to-3d using 2d diffusion》【ICLR 2023】
Author:Google
Method:NeRF+Pretrained Diffusion。
Code:未开源,因为Imagen未开源。有个用stable-diffusion复现的项目:stable-dreamfusion
Device:1.5 hours per view on one core TPU v4 (4 core $12.88/hour)≈一张视图33块
以文本为条件的生成性图像模型现在支持高保真、多样化和可控的图像合成,高质量来源于大量对齐的图像-文本数据集和可扩展的生成模型架构,如扩散模型。但目前的模型,如DALL-E 2, Imagen等仍然停留在二维创作(即图片),无法生成360度无死角的3D模型。
很多三维生成方法都是基于NeRF模型,比如2022年提出的Dream Fields使用预训练的CLIP模型和基于优化的方法来训练NeRF,直接从文本中生成3D模型,但这种方式生成的三维物体往往缺乏真实性和准确性。
因此,这篇文章中,Dreamfusion与DreamField类似,使用预训练的模型,无需3D数据supervise,从文本生成3D。只不过Dreamfusion使用的是diffusion预训练模型,并且损失函数也与DreamField不一样。本文的损失是基于概率密度蒸馏的,基于扩散的正向过程和由预训练的扩散模型学习到的分数函数,最小化具有共享均值的高斯分布族之间的KL散度。作者称这种方式为Score Distillation Sampling (SDS),可以通过可微图像参数化的优化来实现采样。

上图中y表示text prompt。这里有几个需要注意的点:
对于NeRF渲染出的图像,将其输入至Imagen内重建之前加入了随机噪声ε,这里加入噪声的目的是:正则化优化过程,防止过度拟合;
为什么计算损失时与初始噪声ε相减?因为扩散模型最后计算出的是输出图像与输入图像之间差的噪声。对于NeRF渲染出的一张图像,我们希望以预训练模型最后输出的图像作为它的真实图像
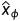 ,所以需要计算出真实图像与NeRF渲染出之间差的噪声:-rendering。扩散模型计算出来的
,所以需要计算出真实图像与NeRF渲染出之间差的噪声:-rendering。扩散模型计算出来的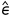 并不是两者的差值,而是真实图像与z_t之间的差值:=-z_t,而z_t=ε+rendering,所以-rendering=+ε? 这一步的目的是不惩罚加入初始噪声矢量本身的偏差,但是这样推导出来的为何变成了相加而不是详见。。
并不是两者的差值,而是真实图像与z_t之间的差值:=-z_t,而z_t=ε+rendering,所以-rendering=+ε? 这一步的目的是不惩罚加入初始噪声矢量本身的偏差,但是这样推导出来的为何变成了相加而不是详见。。
扩散模型使用的是Imagen[1]。Imagen没有公开,但因为作者是谷歌的,所以可以用Imagen模型,也因此这篇文章并没有公开代码,作者在可复现声明中说可以用其他的conditional diffusion models来实现。
使用的NeRF是Mip-NeRF 360[2]。
具体的做法有以下几步:
1)随机采样一个相机和灯光。在每次迭代中,相机位置在球面坐标中被随机采样,仰角范围从-10°到90°,方位角从0°到360°,与原点的距离为1到1.5。同时还在原点周围取样一个看(look-at)的点和一个向上(up)的矢量,并将这些与摄像机的位置结合起来,创建一个摄像机的姿势矩阵。同时对焦距乘数服从U(0.7, 1.35)进行采样,点光位置是从以相机位置为中心的分布中采样的。使用广泛的相机位置对合成连贯的三维场景至关重要,宽泛的相机距离也有助于提高学习场景的分辨率。
2)从该相机和灯光下渲染NeRF的图像。考虑到相机的姿势和光线的位置,以64×64的分辨率渲染阴影NeRF模型。在照明的彩色渲染、无纹理渲染和没有任何阴影的反照率渲染之间随机选择。
3)计算SDS损失相对于NeRF参数的梯度。通常情况下,文本prompt描述的都是一个物体的典型视图,在对不同的视图进行采样时,这些视图并不是最优描述。根据随机采样的相机的位置,在提供的输入文本中附加与视图有关的文本是有益的。对于大于60°的高仰角,在文本中添加俯视(overhead view),对于不大于60°的仰角,使用文本embedding的加权组合来添加前视图、侧视图 或 后视图,具体取决于方位角的值。
对于几何的正则,作者采用了Dream Field中的密度正则和Ref-NeRF 中的方向损失。
总结:对将diffusion用于Text-to-3D任务做出了有意义的尝试,但未开源,中间一些小的细节可以借鉴。
[1] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. arXiv:2205.11487, 2022.
[2] Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-NeRF 360: Unbounded anti-aliased neural radiance fifields. CVPR, 2022.
[3] Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T. Barron, and Pratul P. Srinivasan. Ref-NeRF: Structured view-dependent appearance for neural radiance fifields. CVPR, 2022.
2)《Magic3D: High-Resolution Text-to-3D Content Creation》【CVPR 2023】
Author:Nvidia,为了对标DreamFusion。
Method:NeRF+Pretrained Diffusion。
Code:未开源
Device:40 minutes on 8 NVIDIA A100 GPUs.
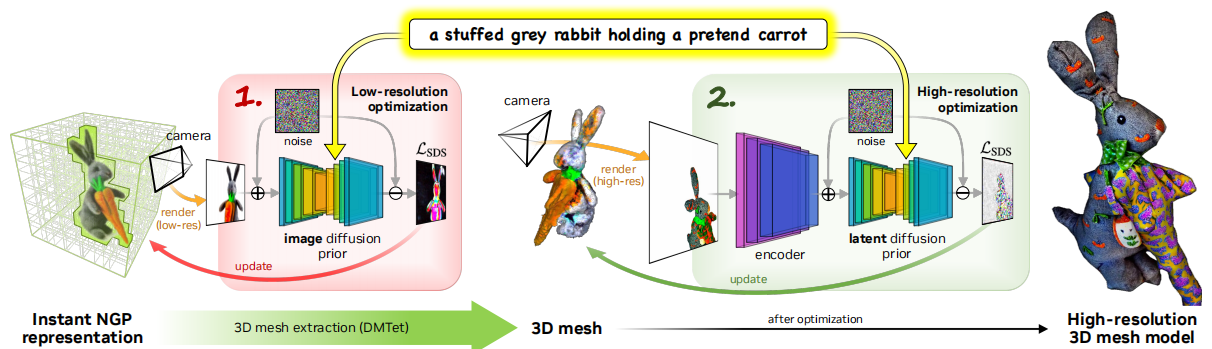
动机:Dreamfusion有两个固有缺陷:1)extremely slow optimization of NeRF;2)
low-resolution image space supervision on NeRF, leading to low-quality 3D models with a long processing time.
方法:为了解决这些问题,这篇文章采用了一个coarse-to-fine双阶段优化框架。如下图,第一个阶段使用low-resolution的diffusion prior来优化NeRF,这一阶段与Dreamfusion相似。第二阶段,再使用一个高分辨率的diffusion model再微调这个coarse的模型。思路很straight。整个过程使用的还是Dreamfusion中的SDS损失。
结果:速度比Dreamfusion快两倍,同时分辨率也更好。
3)《Score jacobian chaining: Lift ing pretrained 2d diffusion models for 3d generation》
Author:TTI-Chicago + Purdue University
Code:https://github.com/pals-ttic/sjc
Devices: 25 minutes on an A6000 GPU
根据[1],score被定义为对数密度函数的梯度: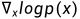 。其中,密度函数指的是状态为x时的概率:
。其中,密度函数指的是状态为x时的概率: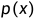 。在此基础上,扩散模型及其变体可以被建模为在σ噪声级别下的去噪分数[2]:
。在此基础上,扩散模型及其变体可以被建模为在σ噪声级别下的去噪分数[2]: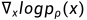 。这篇文章的主要动机是,作者将扩散模型看作是一个梯度场预测器,或者也可以说是一个关于数据对数似然的score function。一个自然的问题就是:链式法则能否被用于学习梯度?
。这篇文章的主要动机是,作者将扩散模型看作是一个梯度场预测器,或者也可以说是一个关于数据对数似然的score function。一个自然的问题就是:链式法则能否被用于学习梯度?
一个图像x可以被参数化为一个参数为θ的函数f: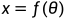 。通过雅可比矩阵
。通过雅可比矩阵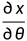 应用链规则,则可以将图像x上的梯度转换为参数θ上的梯度。将预先训练好的扩散模型与不同的f选择配对可以有许多潜在的用例。对于3D模型的参数θ,将在相机角度π下渲染出的图像
应用链规则,则可以将图像x上的梯度转换为参数θ上的梯度。将预先训练好的扩散模型与不同的f选择配对可以有许多潜在的用例。对于3D模型的参数θ,将在相机角度π下渲染出的图像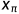 的雅克布矩阵J定义为
的雅克布矩阵J定义为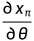 ,这样就可以将2D图像上的梯度传递到3D模型的参数θ。也就是,将2D图像上的梯度通过雅克布矩阵整合到3D上,从而生成一个3D asset(参数为θ)。在本文中,作者将3D assert θ参数化为存储在voxels上的NeRf,然后将f看作是一个可微分的的渲染器。
,这样就可以将2D图像上的梯度传递到3D模型的参数θ。也就是,将2D图像上的梯度通过雅克布矩阵整合到3D上,从而生成一个3D asset(参数为θ)。在本文中,作者将3D assert θ参数化为存储在voxels上的NeRf,然后将f看作是一个可微分的的渲染器。
一个技术挑战是在渲染图像上直接评价diffusion model来计算2D score,会引起out-of-distribution (OOD)问题。具体来讲,扩散模型被训练为去噪器,在训练过程中只看到noisy inputs,但我们的方法需要在non-noisy 渲染图像上评价去噪器,所以这就导致了OOD问题。为了解决这个问题,作者提出了一种为non-noisy images估计score的方法:Perturb-and-Average Scoring(PAAS)。
一个扩散模型可以被解释为一个VAE,或一个去噪的score-matcher。本文使用了一个基于DvGO [3]和TensoRF [4]的超参数自定义的体素辐射场[5]。
这篇工作与DreamFusion是concurrent work:一个用Imagen,一个用Stable-diffusion;一个用数学方法寻找图像参数化来最小化训练损失,一个应用链式法则到2D score上。
在FFHQ人脸数据集上训练的denoiser的OOD问题的示例:

PAAS算法:
因为DreamFusion没有开源,所以作者找了一个第三方实现的版本Stabel-Dreamfusion来进行对比。

[1] Aapo Hyvärinen and Peter Dayan. Estimation of non-normalized statistical models by score matching. J. Mach. Learn. Res, 2005. 1, 3
[2] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In Int. Conf. Learn. Represent., 2021.
[3] Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fifields reconstruction. In IEEE Conf. Comput. Vis. Pattern Recog., 2022.
[4] Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fifields. arXiv preprint arXiv:2203.09517, 2022. 2, 5
[5] Alex Yu, Sara Fridovich-Keil, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fifields without neural networks. arXiv preprint arXiv:2112.05131, 2021.
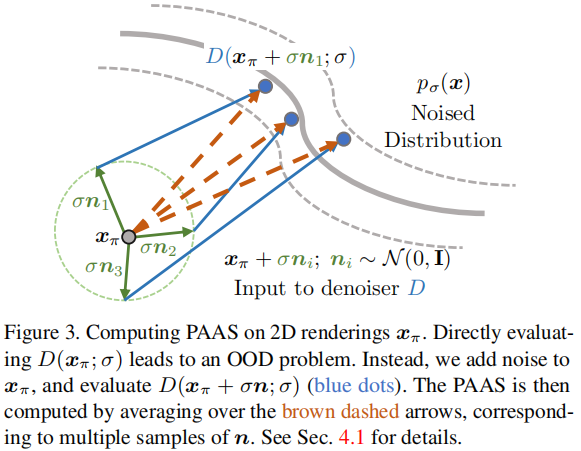
4)《3DDesigner: Towards Photorealistic 3D Object Generation and Editing with Text-guided Diffusion Models》【arXiv 2212】
Author:JD Explore Academy
Method:NeRF+Pretrained Diffusion。
Code:未开源
Device:14 days on 8 NVIDIA A100 GPUs
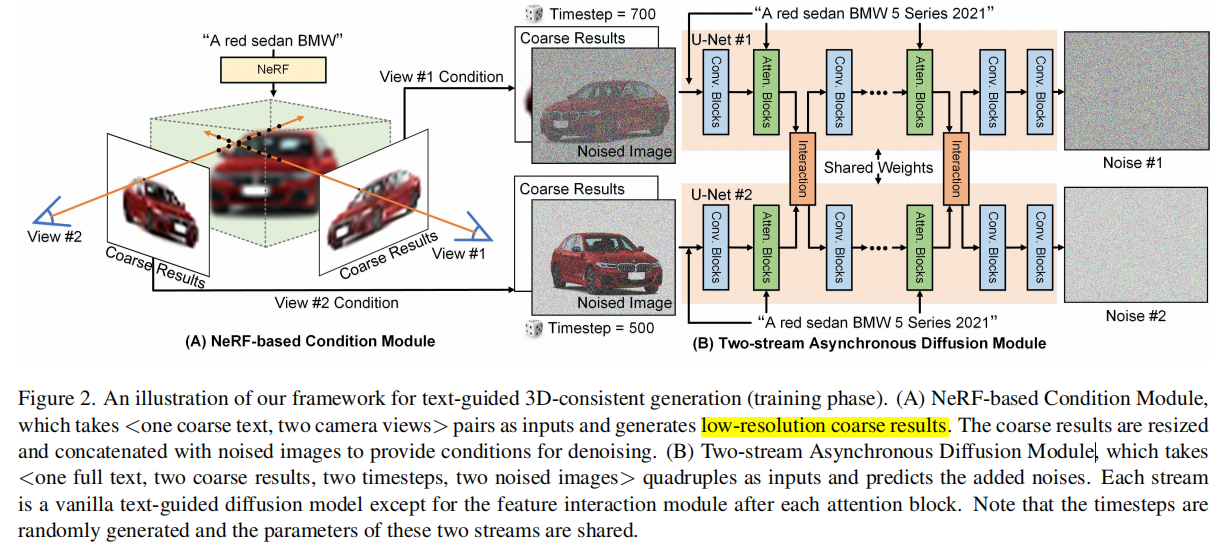
3D local editing 启发于Blended diffusion,相对于Blended diffusion在noisy image上编辑具体的区域,本文提出了将操作空间从图像空间转换为噪声空间,因此可以进一步将blended noise反转到text embedding上。
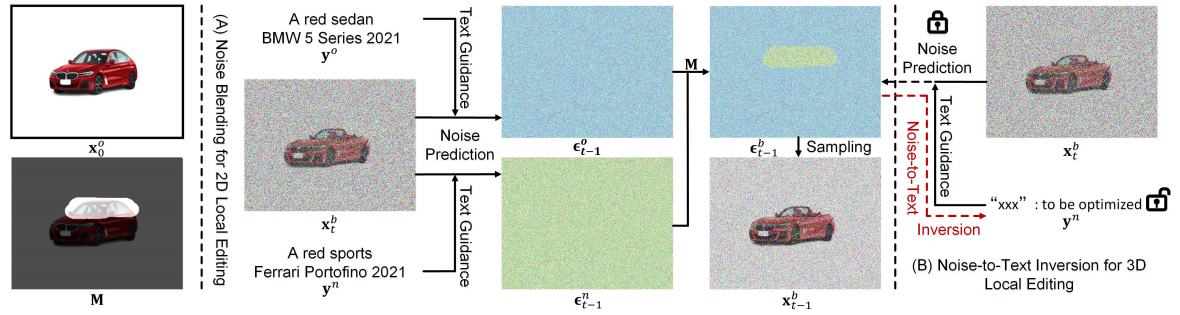
Inversion的思想与Textual inversion[1]的思路有些像。
[1] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022.
5)《Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation》【arXiv 2303】
Author:Korea University+NAVER AI Lab
Code:https://ku-cvlab.github.io/3DFuse/
6)《Compositional 3D Scene Generation using Locally Conditioned Diffusion》【CVPR 2023】
Author:斯坦福
Device:10000 denoising iterations with a learning rate of 0.05 on a single NVIDIA RTX A6000
动机:设计复杂的3D场景一直是一个繁琐的手工过程,需要领域的专业知识。最近的text-to-3d的生成模型在这个问题上显示出了巨大的潜力,但现有的方法仅限于对象级的生成。因此这篇文章提出了一种 locally conditioned diffusion 来进行组合式的场景生成。具体的形式是,给定组合好的 user-input bounding boxes三维模型 和对应的 text prompts,生成一个多目标组合的场景,如下所示。

方法:其实本篇文章就相当于3D版本的Blended diffusion,bounding box相当于3Dmask,属于mask-based。为了将Blended diffusion应用于3D,作者采用了Dreamfusion的方式来实现,因此≈“Blended diffusion”+“Dreamfusion”。
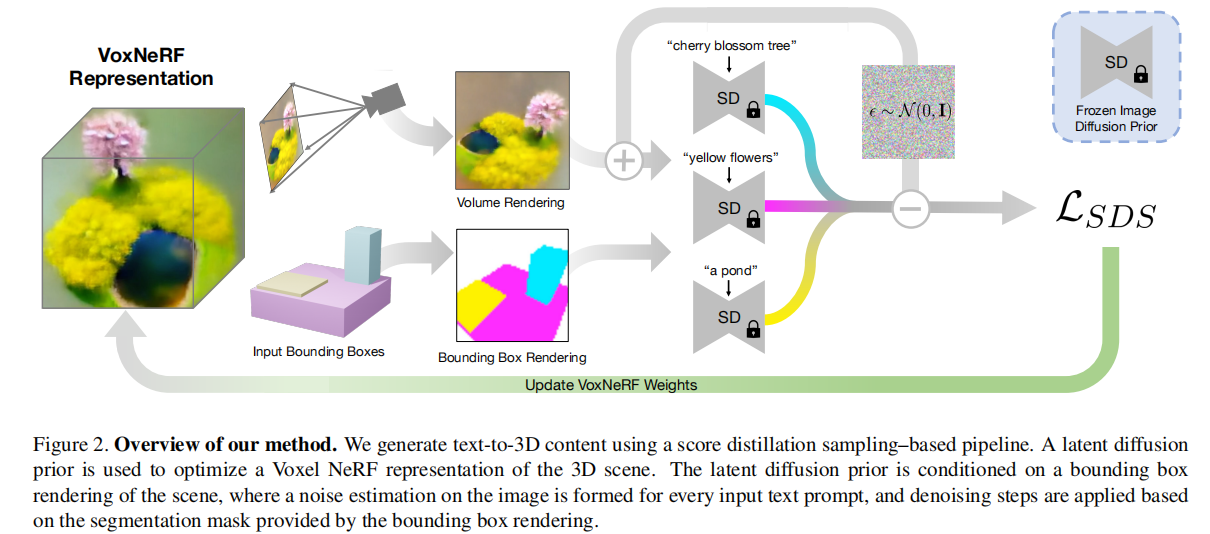
作者是基于text-to-3d方法SJC做的,因为目前只有他们开源了。diffusion用的是stable diffusion。
对于任意一个相机视角,从initial NeRF中渲染一个image,并从3D bounding box中渲染一个图像并进行分割,作为mask(假如有3个prompt,实际上则会有3个mask),在预测噪声的过程中,每一步都分别对每个mask预测噪声,因此最后能在每个mask区域生成prompt对应的图像。最后使用SDS损失去训练NeRF。

7)《ProlificDreamer: High-Fidelity and Diverse Text-to-3D
Generation with Variational Score Distillation》
Author:TSAIL(清华)
Device:xxx
动机:text-to-3d工作现在普遍采用Score distillation sampling (SDS,Dreamfusion) ,它蒸馏大规模预训练文本-图像扩散模型的知识。但是这种方法面临严重的过饱和、过平滑、缺少细节等问题。高质量 3D 内容生成目前仍然是非常困难的前沿问题之一。ProlificDreamer 论文提出了 Variational Score Distillation(VSD)算法,从贝叶斯建模和变分推断(variational inference)的角度重新形式化了 text-to-3D 问题。具体而言,VSD 把 3D 参数建模为一个概率分布,并优化其渲染的二维图片的分布和预训练 2D 扩散模型的分布间的距离。可以证明,VSD 算法中的 3D 参数近似了从 3D 分布中采样的过程,解决了 DreamFusion 所提 SDS 算法的过饱和、过平滑、缺少多样性等问题。此外,SDS 往往需要很大的监督权重(CFG=100),而 VSD 是首个可以用正常 CFG(=7.5)的算法。
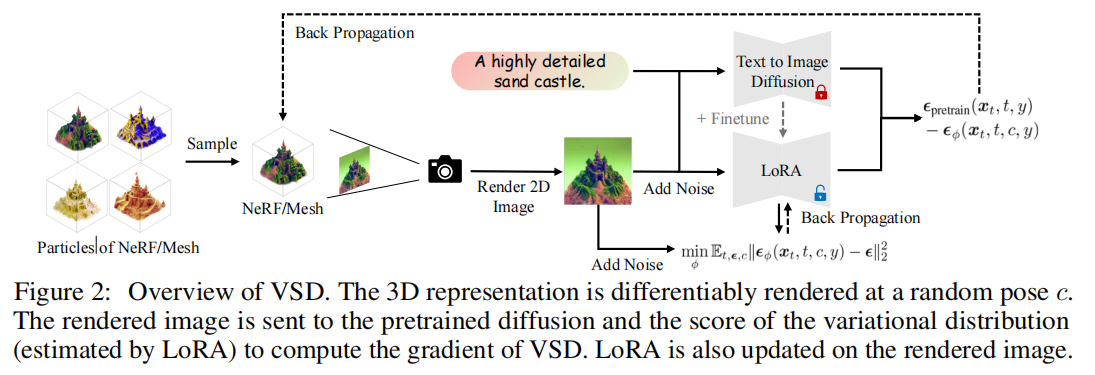
本文的核心是所提出的Variational Score Distillation (VSD),下面主要对其进行讲解。给一个text prompt,VSD将相应的3D scene看作是一个随机变量,而不是SDS中的一个点。VSD要做的是优化3D scenes的分布,目的是将从所有视角渲染图像中推导出的分布与2D扩散模型定义的分布尽可能接近,比如使用KL散度等。在这种变分定义下,VSD自然地描述了多个3D场景可能与一个prompt对齐的现象。
为了实现这种想法,VSD采取了particle-based 变分推理,并保持了一组三维参数作为particles(粒子)来表示三维分布。(TODO:particle-based 变分推理?)作者们通过Wasserstein gradient flow推导了一种新的基于梯度的粒子更新规则,并保证当优化收敛时,粒子将是期望分布的样本(见定理2)。这样的更新需要估计扩散渲染图像上分布的分数函数,这可以通过预先训练的扩散模型的低秩自适应(LoRA)[18,39]有效地实现。最终的算法也会交替地更新粒子和评分函数。
作者指出,SDS是VSD的一种特殊情况,它使用单个点的Dirac distribution作为变分分布。这个观点就解释了SDS生成的3D场景的多样性和保真度为什么会受到了限制。此外,即使是单个粒子,VSD也可以学习参数分数模型,可能提供比SDS更好的泛化。
这篇文章还提出了scene initialization,这个对复杂场景的合成很有用。
Background
1)CFD
扩散模型最成功的应用之一是文本到图像的生成,其中噪声预测模型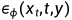 以文本提示符y为condition。在实践中,classifier free guidance (CFG)是平衡样本质量和多样性的关键技巧,将更改为如下形式:
以文本提示符y为condition。在实践中,classifier free guidance (CFG)是平衡样本质量和多样性的关键技巧,将更改为如下形式:
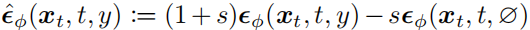
其中,∅是一个特殊的“empty” text prompt,表示无条件的情况,s>0是 guidance scale。s越大,文本图像对齐的质量越好,也就是生成的质量越好,但是多样性会降低。
2)SDS的理解以及与“知识蒸馏”的区别
SDS的概念
Score Distillation Sampling (SDS)是一种通过蒸馏预训练扩散模型的优化方法,有时也被称为 Score Jacobian Chaining (SJC)。SDS已经成了 text-to-3D 路线中唯一的一个方法,目前所有的text-to-3D都是基于SDS来做。2D预训练扩散模型近些年已经展现出了强大的能力,比如stable-diffusion等,他们拥有着强大的text-to-semantic的知识,SDS的思想就是借助这些2D预训练扩散模型的知识,来完成text-to-3D的任务。
也就是说,SDS 通过从另一个比当前模型性能更好的生成模型(stable-diffusion)中学习,并且将学习到的知识迁移到当前模型中,以提高生成样本的质量。具体来说,这种方法通过利用生成模型的另一个教师模型的分数(例如概率密度函数值)信息来指导训练,并让生成模型更好地逼近教师模型的分数分布。这样可以更好地模拟真实世界中的样本分布,从而提高生成样本的质量。
Score distillation sampling中的“score”和“sampling”
在 Score distillation sampling 中,对于输入的 text prompt y,预训练模型会预测出一个目标分布I,而“score”指的是就是这个目标分布I给每个样本(采样得到)打的分数,其反应的是样本的质量和目标分布的相似程度。这个分数通常表示的是目标分布生成该样本的概率密度,可以理解为该样本在目标分布中的“重要程度”。
对于 "sampling",它在 Score distillation sampling 中的含义是从目标分布I(预训练模型的输出)中生成(采样)一系列的样本,作为更新学生模型的训练数据。采样的方式一般选择蒙特卡罗采样(随机采样并求期望值)或重要性采样(加权采样)。对于每个采样的样本,教师模型都会生成一个分数(score),通常也称为“评分”,这个分数其实就是该样本在目标分布I中对应的概率密度,可以用于确定训练中每个样本的权重,并用于计算损失函数和影响参数更新的方向。
SDS 就是根据目标分布(预训练模型的输出)和当前模型的生成结果引导模型的训练,利用采样的方式不断对当前模型的参数进行更新,直到最终生成的样本质量足够好,能够和目标分布相接近。
score distillation sampling与“知识蒸馏”的区别
Score distillation sampling 和知识蒸馏在一定程度上是相似的,它们都涉及将一个教师模型的知识传递给一个学生模型。但是,它们的目标和方法略有不同。
知识蒸馏主要是一个模型压缩技术,它旨在将一个较大的、精度较高的模型的知识“蒸馏”到一个较小的、可部署的模型中,以提高在计算资源有限的情况下的性能。知识蒸馏通常通过对教师模型的预测及其与训练数据标注的关系的分析来提取知识,并将这些知识编码后传递给学生模型。这些知识可以包括模型参数、特征表示、损失函数等。
Score distillation sampling 与知识蒸馏的主要区别在于它专注于提高生成模型的生成能力,而知识蒸馏则专注于提高分类模型的泛化性能。在 Score distillation sampling 中,预训练生成模型通常拥有更好的性能和更高的生成能力,因此它可以作为目标分布来指导当前模型的训练,从而提高当前模型的生成能力。因此,Score distillation sampling 应用可以被看作是对预训练生成模型知识的复用和迁移,这种方法通常可以提高生成模型的性能和效率,同时也可以减少训练成本和时间。而知识蒸馏则更多地关注于将教师模型的知识注入学生模型中,以提高模型的泛化性能。因此,Score distillation sampling 与知识蒸馏虽然有些联系,但是它们的应用场景和方法并不完全相同。
在SDS这一系列的文章中,“蒸馏”指的是这样的一个过程:给定2D预训练扩散模型一个prompt text y生成一个场景的分布 s,然后给定一个新的生成模型同样的prompt text y学习一个场景分布s'来对齐s。SDS的“蒸馏”流程可以看作是以s来监督s'的生成,就是将2D预训练扩散模型的知识“蒸馏”到3D场景的分布中。
3)3D 表征
3D表征用NeRF也行,用mesh也行。当用NeRF时,g(θ,c)表示给NeRF一个pose,渲染出一个图像的过程。当用 textured mesh时,g(θ,c)就是代表一个从3D textured mesh在某个pose下拍照的过程。
4) particle-based variational inference
Particle-based 变分推理 (particle-based variational inference) 是一种基于粒子的概率推断方法,常用于对高维概率分布进行变分推断。该方法的主要思想是,基于加权分布,从粒子样本中随机抽取一组样本,用于推断后验分布。
在本文中,每个particle表示一组可能产生场景的3D 参数,就是对于一个分布,我们通过采样出的几个particles(可以看作是分布的样本)来表示。
5) Wasserstein gradient flow
Wasserstein gradient flow是一种基于梯度的优化方法,用于解决Wasserstein距离推断中的优化问题。Wasserstein距离(也称为Earth Mover's Distance)是一种衡量两个概率分布之间相似度的距离度量,并在生成对抗网络(GANs)等深度学习模型中得到广泛应用。
Wasserstein梯度流:基于Wasserstein距离的梯度信息,定义了一个概率分布随时间演化的微分方程。在Wasserstein梯度流中,考虑一个初始概率分布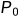 和目标概率分布
和目标概率分布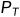 ,目标是找到一个时间依赖的概率分布
,目标是找到一个时间依赖的概率分布 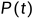 ,其中 t 在 [0, T] 范围内变化,使得 在每个时间点 t 与目标分布 的 Wasserstein 距离最小化。
,其中 t 在 [0, T] 范围内变化,使得 在每个时间点 t 与目标分布 的 Wasserstein 距离最小化。
在Wasserstein距离推断中,优化问题通常形如minibatch stochastic gradient descent的形式。Wasserstein gradient flow是一种替代的优化方法,它通过在流形上迭代地计算梯度和运动方程,直接寻找最小化Wasserstein距离的解。
Wasserstein gradient flow的基本思想是将距离度量看作流形上的某种能量函数,然后使用能梯度下降(energy gradient descent)来找到这个能量函数的最小值。在实践中,这通常通过将能量函数离散化为点集的形式,并使用梯度下降法来近似求解。Wasserstein gradient flow在实践中的结果往往比传统的优化方法更加稳定和准确,并且能够应用于更广泛的概率分布和推断模型。
能量函数的理解可以参考之前的文章:扩散模型的数学理解,任何概率分布都可以写作能量函数的形式,但是对能量函数的定义不同的方法可以有所不同。如果能量函数被表示为似然函数,那么求最大似然就相当于求最小能量。
Method
这篇文章提出的VSD,主要是用来学习从3D场景的分布中采样。
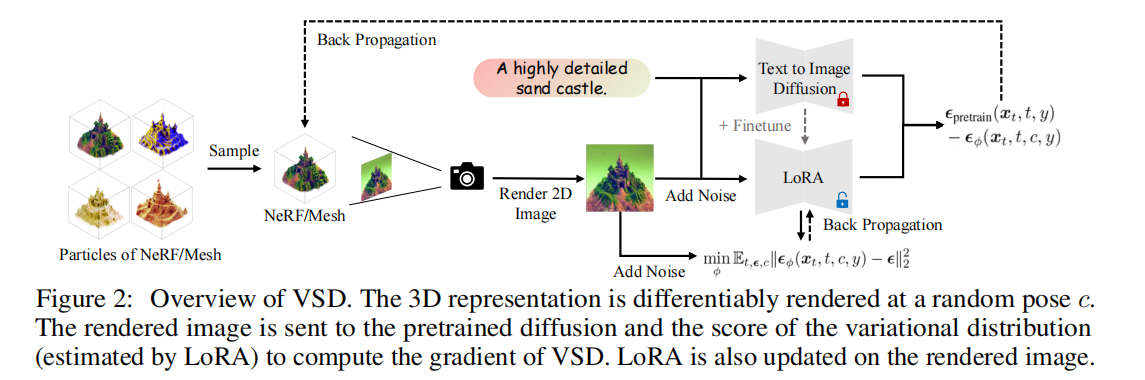
给定一个text prompt y,它对应的场景可以由N种3D representations(e.g., NeRF, mesh)来表示,在每种表征的形式下,都会有一个分布来表示这个场景。比如在参数化为θ的3D 表征下,这样的一个分布可以建模为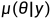 。给定一个camera c和渲染函数g(·,c),渲染图像x0:=g(θ,c)的分布被记为
。给定一个camera c和渲染函数g(·,c),渲染图像x0:=g(θ,c)的分布被记为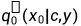 。如果相机的分布是p(c),那么渲染图像的边际分布为:
。如果相机的分布是p(c),那么渲染图像的边际分布为: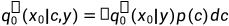 。上面这个分布是从3D表征中渲染出来的图像,那么给预训练扩散模型一个text prompt y后生成的图像的边缘分布,可以写作
。上面这个分布是从3D表征中渲染出来的图像,那么给预训练扩散模型一个text prompt y后生成的图像的边缘分布,可以写作 。前者的边缘分布意义可以理解为没有相机渲染视角指导下的图片分布,其应该对应上 2D Diffusion 从 web scale 图片下获取的分布。
。前者的边缘分布意义可以理解为没有相机渲染视角指导下的图片分布,其应该对应上 2D Diffusion 从 web scale 图片下获取的分布。
为了获取高质量的3D representation,这篇文章希望通过优化μ(θ|y),使其渲染出来的样本与预先训练好的扩散模型对齐,解决这样的问题形式化如下:
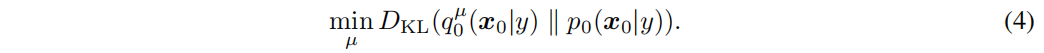
这是一个典型的变分推断问题,通过变分分布 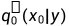 来近似(蒸馏)目标分布。但直接解这个问题是困难的,因为p0是相当复杂的,且p0的高密度区域在高纬度中可能会非常稀疏。
来近似(蒸馏)目标分布。但直接解这个问题是困难的,因为p0是相当复杂的,且p0的高密度区域在高纬度中可能会非常稀疏。
直接解比较难,怎么办?那就分开解。这也就是扩散模型的思想,把一个难的问题分解成T个相对简单的优化问题来解决。当t增加到T时,优化问题变得更容易,因为扩散分布更接近标准高斯分布。将这样的问题使用扩散模型来求解,就是将看作是扩散模型中的 ,将看作是扩散模型中的
,将看作是扩散模型中的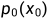 。所以优化目标转换为了如下形式:
。所以优化目标转换为了如下形式:
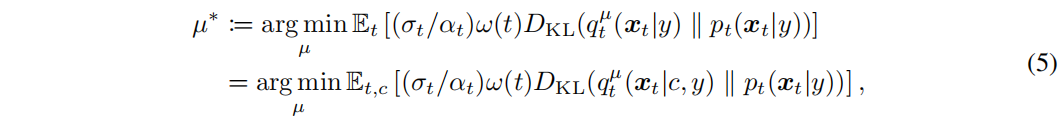
其中,α_t和σ_t为超参,满足α_0 ≈ 1,σ_0 ≈ 0,α_1 ≈ 0,σ_1 ≈ 1。 此外,每一个时刻渲染图象的
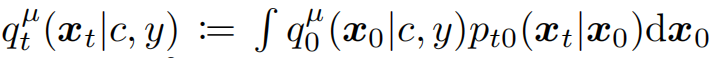

并且,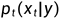 是t时刻对应的噪声分布,
是t时刻对应的噪声分布,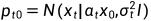 是高斯转移矩阵。ω(t)是一个与时间相关的加权函数。
是高斯转移矩阵。ω(t)是一个与时间相关的加权函数。

与SDS相比,SDS只优化分布中的某一个点,而VSD优化整个分布。
VSD的更新方法
为了解决(5),直观的方法是训练另一个以μ为参数的生成模型,但是这样计算消耗非常庞大。因此作者采用了particle-based 的变分推断方法,即用n=4个( 4 为了平衡效果和计算消耗)3D 参数 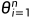 作为 particles 并且遵循一个更新法则。直观地,就是用这n个particles代表当前的分布μ,并且会从优化后的分布
作为 particles 并且遵循一个更新法则。直观地,就是用这n个particles代表当前的分布μ,并且会从优化后的分布 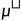 中进行采样(如果收敛的话)。
中进行采样(如果收敛的话)。
这样的优化过程可以被写成模拟一个关于 θ 的 ODE(常微分方程) 的过程,下面进行描述:
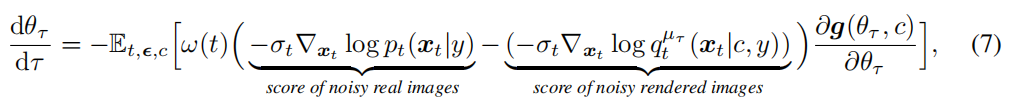
τ指的是每次更新模型参数的迭代。t指的是每次迭代中扩散模型的阶段。
在每次迭代中(每个τ),三维场景的分布是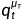 ,需要确保ϵϕ匹配当前的这个分布。
,需要确保ϵϕ匹配当前的这个分布。
VSD的方法如下图,伪代码如下。总的来讲,要更新两个网络,一个3D scene(NeRF),一个diffusion model。

先更新3D表达的参数。最后再更新LoRA 中蕴含的潜在 3D 分布,使更加贴近原本 的分布,如此往复直至收敛。
VSD vs SDS
VSD之于SDS,可以类比VAE之于AE。VSD要做的事就是把要优化的确定性的3D场景改成一个3D场景分布。所谓变分variational的意思就是,将原来(SDS)的3D场景 θ,改成了一个场景的分布 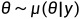 。
。
SDS的优化目标是让单个场景 θ 的渲染图片分布靠近预训练扩散模型的图片分布;而VSD建模了场景的分布 ,优化目标让场景的分布的渲染图片分布靠近预训练扩散模型的图片分布。
总的来讲,现在2D-to-3D的方法都是借助于2D 预训练模型,从中提炼出3D:
DreamCLIP,单个场景,直接梯度下降优化
DreamFusion,单个场景去拟合预训练的分布,方法是score distillation sampling
ProlificDreamer,场景分布(一堆场景)去拟合预训练的分布,方法是variational score distillation

由于SDS缺少多样性,所以需要非常大的CFG系数(CFG=100)才能得到与text prompt对齐的结果,否则会有严重的over-smoothing。而VSD可以在使用正常的CFG(CFG=7.5)大小的情况下依然保证多样性,这个大小和一般的text-to-image diffusion差不多,这也是VSD结果质量更高的直接原因之一。
第一个参考中关于3D一致性先验的讨论很有意思。

参考:ProlificDreamer: Text-to-3D with VSD 论文笔记、ProlificDreamer(VSD)论文阅读笔记。侵删
2.2 Diffusion-based 2D Image editing with masks
1)《Blended diffusion for text-driven editing of natural images》【CVPR 2022】
Mask-based。
Mask-free:《Text-guided mask-free local image retouching》,这个文章一般。
2)《Blended latent diffusion》
3)《High-resolution image editing via multi-stage blended diffusion》
4)《Diffedit: Diffusion-based semantic image editing with mask guidance》
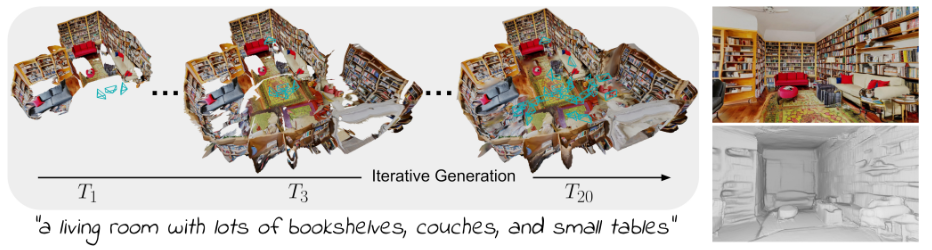
1)《Text2Room-Extracting Textured 3D Meshes from 2D Text-to-Image Models》【arXiv 2303】
Project:https://lukashoel.github.io/text-to-room/
Author:apple
概况:迭代(层次)式场景生成
在第一阶段,创建场景的主要部分,包括总体布局和家具。
第二阶段,细化三维场景细节。
可以说与我们的想法基本一致,而且效果不错。
2)《Gaudi: A neural architect for immersive 3d scene generation》【NeurIPS 2022】
Project:https://github.com/apple/ml-gaudi
Author:apple
概况:
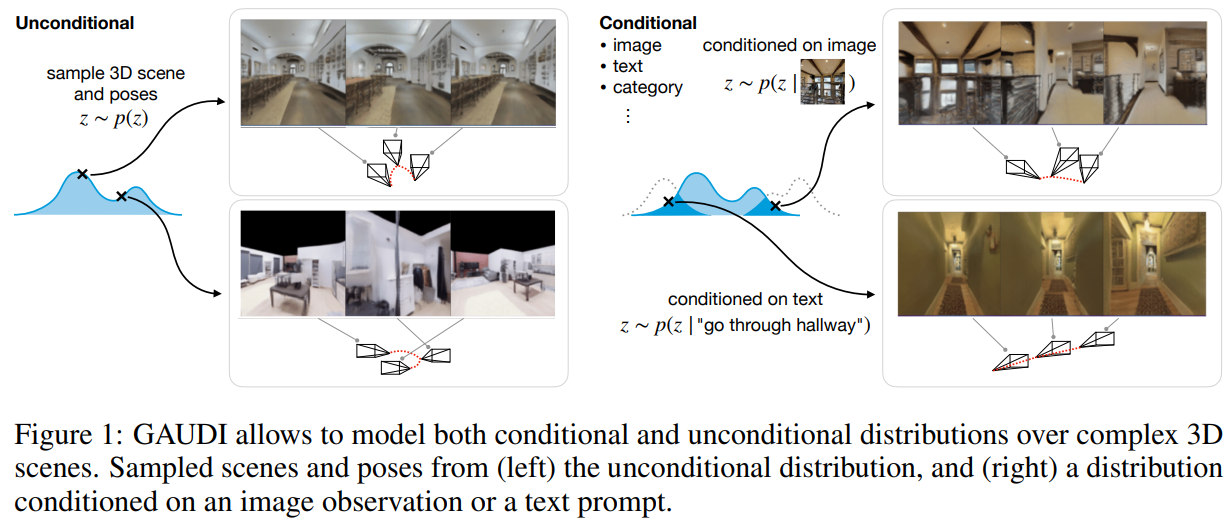
提出了 GAUDI,这是一种生成模型,可捕获参数化为辐射场的 3D 场景的分布。
我们将生成模型分成两步:(i) 优化 3D 辐射场和相应相机姿势的latent representation。(ii) 在潜在空间上学习一个强大的基于分数的生成模型。
GAUDI 在无条件生成的多个数据集上获得了最先进的性能,并能够从文本或 RGB 图像等不同模态有条件地生成 3D 场景。
3)《Text2Scene: Text-driven Indoor Scene Stylization with Part-aware Details》【CVPR'2023】
论文未公布,但在CVPR接收名单中
4)《Set-the-Scene: Global-Local Training for Generating Controllable NeRF Scenes》【arXiv 2303】
Project:https://danacohen95.github.io/Set-the-Scene/
Author:Tel Aviv University
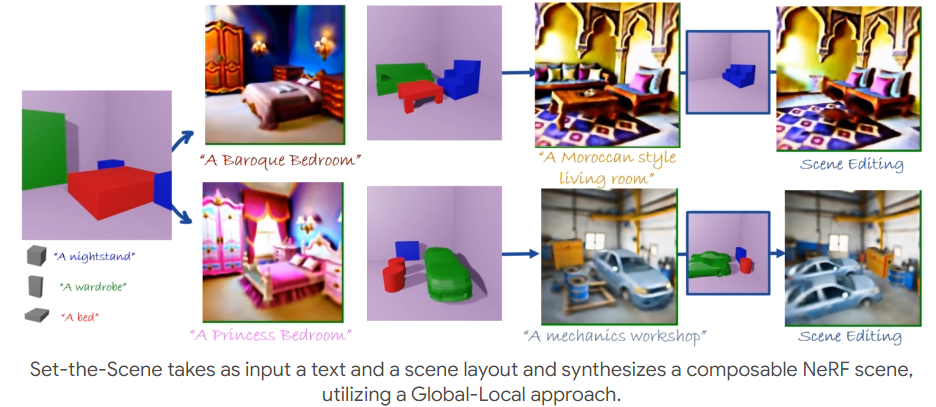
概况:先全局再局部,也就是层次式生成三维场景。
输入文本和场景布局,将每个对象表示为一个独立的 NeRF,独立的优化每个NeRF和场景的表征。与之前的想法一致。
效果:

5)《Text-To-4D Dynamic Scene Generation》【arXiv 2303】
Project:https://make-a-video3d.github.io/
Author:Meta AI
概况:从文本描述生成三维动态场景

6)《SceneScape: Text-Driven Consistent Scene Generation》【arXiv 2302】
Project:https://scenescape.github.io/
Author:Weizmann Institute of Science + NVIDIA
概况:根据文字输入,结合diffusion模型的图片生成能力和单目深度估计算法,给定mesh的连续几何约束和不同时间视频帧的连续性约束,生成连续的三维空间模型。


