
- 1人工智能-机器学习&人工神经网络_人工神经网络和机器学习
- 2【智能语音机器人】0_Ubuntu20.04下Rasa环境部署_ubuntu安装rasa
- 3搭建机器人产业发展重要展示平台“2024南京国际机器人展览会”
- 4python路径规划仿真实验_[python] A*算法基于栅格地图的全局路径规划
- 5手写字识别代码_手写体识别代码
- 6微信H5页面实现微信小程序支付_微信浏览器调起小程序支付
- 7华为HECS配置python开发环境_华为平板 python开发环境
- 8【操作系统详解】功能|分类|进程|线程|死锁_pcd是进程的组成吗
- 9JavaScript全栈开发指南:从ECMAScript基础到实战应用_lighthouse supertest
- 10PaddleNLP+Paddlehub打造你的发泄机器人_paddlehub 部署paddlenlp
神经网络的隐藏层
赞
踩
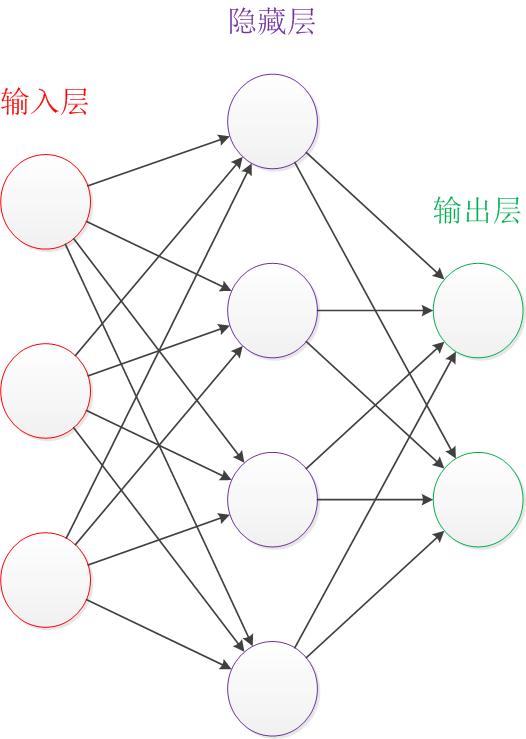
通常,卷积神经网络除了输入和输出层之外还有四个基本的神经元层,在三层神经网络中,这基层被称为隐藏层
卷积层(Convolution)
激活层(Activation)
池化层(Pooling)
完全连接层(Fully connected)
卷积层
在最初的卷积层中,成千上万的神经元充当第一组过滤器,搜寻图像中的每个部分和像素,找出模式(pattern)。随着越来越多的图像被处理,每个神经元逐渐学习过滤特定的特征,这提高了准确性。
比如图像是苹果,一个过滤器可能专注于发现“红色”这一颜色,而另一个过滤器可能会寻找圆形边缘,另一个过滤器则会识别细细的茎。如果你要清理混乱的地下室,准备在车库搞个大销售,你就能理解把一切按不同的主题分类是什么意思了(玩具、电子产品、艺术品、衣服等等)。 卷积层就是通过将图像分解成不同的特征来做这件事的。
特别强大的是,神经网络赖以成名的绝招与早期的 AI 方法(比如 Deep Blue 中用到的)不同,这些过滤器不是人工设计的。他们纯粹是通过查看数据来学习和自我完善。
卷积层创建了不同的、细分的图像版本,每个专用于不同的过滤特征——显示其神经元在哪里看到了红色、茎、曲线和各种其他元素的实例(但都是部分的) 。但因为卷积层在识别特征方面相当自由,所以需要额外的一双眼睛,以确保当图片信息在网络中传递时,没有任何有价值的部分被遗漏。
神经网络的一个优点是它们能够以非线性的方式学习。如果不用数学术语解释,它们的意思是能够发现不太明显的图像中的特征——树上的苹果,阳光下的,阴影下的,或厨房柜台的碗里的。这一切都要归功于于激活层,它或多或少地突出了有价值的东西——一些既明了又难以发现的属性。
在我们的车库大甩卖中,想像一下,从每一类东西里我们都挑选了几件珍贵的宝物:书籍,大学时代的经典 T 恤。要命的是,我们可能还不想扔它们。我们把这些“可能”会留下的物品放在它们各自的类别之上,以备再考虑。
池化层
整个图像中的这种“卷积”会产生大量的信息,这可能会很快成为一个计算噩梦。进入池化层,可将其全部缩小成更通用和可消化的形式。有很多方法可以解决这个问题,但最受欢迎的是“最大池”(Max Pooling),它将每个特征图编辑成自己的“读者文摘”版本,因此只有红色、茎或曲线的最好样本被表征出来。
在车库春季清理的例子中,如果我们使用著名的日本清理大师 Marie Kondo 的原则,将不得不从每个类别堆中较小的收藏夹里选择“激发喜悦”的东西,然后卖掉或处理掉其他东西。 所以现在我们仍然按照物品类型来分类,但只包括实际想要保留的物品。其他一切都卖了。
这时,神经网络的设计师可以堆叠这一分类的后续分层配置——卷积、激活、池化——并且继续过滤图像以获得更高级别的信息。在识别图片中的苹果时,图像被一遍又一遍地过滤,初始层仅显示边缘的几乎不可辨别的部分,比如红色的一部分或仅仅是茎的尖端,而随后的更多的过滤层将显示整个苹果。无论哪种方式,当开始获取结果时,完全连接层就会起作用。

完全连接层
现在是时候得出结果了。在完全连接层中,每个削减的或“池化的”特征图“完全连接”到表征了神经网络正在学习识别的事物的输出节点(神经元)上。 如果网络的任务是学习如何发现猫、狗、豚鼠和沙鼠,那么它将有四个输出节点。 在我们描述的神经网络中,它将只有两个输出节点:一个用于“苹果”,一个用于“橘子”。
如果通过网络馈送的图像是苹果,并且网络已经进行了一些训练,且随着其预测而变得越来越好,那么很可能一个很好的特征图块就是包含了苹果特征的高质量实例。 这是最终输出节点实现使命的地方,反之亦然。
“苹果”和“橘子”节点的工作(他们在工作中学到的)基本上是为包含其各自水果的特征图“投票”。因此,“苹果”节点认为某图包含“苹果”特征越多,它给该特征图的投票就越多。两个节点都必须对每个特征图进行投票,无论它包含什么。所以在这种情况下,“橘子”节点不会向任何特征图投很多票,因为它们并不真正包含任何“橘子”的特征。最后,投出最多票数的节点(在本例中为“苹果”节点)可以被认为是网络的“答案”,尽管事实上可能不那么简单。
因为同一个网络正在寻找两个不同的东西——苹果和橘子——网络的最终输出以百分比表示。在这种情况下,我们假设网络在训练中表现已经有所下降了,所以这里的预测可能就是75%的“苹果”,25%的“橘子”。或者如果是在训练早期,可能会更加不正确,它可能是20%的“苹果”和80%的“橘子”。这可不妙。

如果一开始没成功,再试,再试…
所以,在早期阶段,神经网络可能会以百分比的形式给出一堆错误的答案。 20%的“苹果”和80%的“橘子”,预测显然是错误的,但由于这是使用标记的训练数据进行监督学习,所以网络能够通过称为“反向传播”的过程来进行系统调整。
避免用数学术语来说,反向传播将反馈发送到上一层的节点,告诉它答案差了多少。然后,该层再将反馈发送到上一层,再传到上一层,直到它回到卷积层,来进行调整,以帮助每个神经元在随后的图像在网络中传递时更好地识别数据。
这个过程一直反复进行,直到神经网络以更准确的方式识别图像中的苹果和橘子,最终以100%的正确率预测结果——尽管许多工程师认为85%是可以接受的。这时,神经网络已经准备好了,可以开始真正识别图片中的苹果了。

