- 1ViLBERT:视觉语言多模态预训练模型_视觉-语言多模态训练模型
- 2深度之眼Paper带读笔记NLP.11:FASTTEXT.Baseline.06_in this work, we explore ways to scale thesebaseli
- 3matlab accumarray_32个实用matlab编程技巧
- 4【科研新手指南2】「NLP+网安」相关顶级会议&期刊 投稿注意事项+会议等级+DDL+提交格式_ccs投稿须知文件
- 5spring-boog-测试打桩-Mockito_org.mockito.exceptions.base.mockitoexception: chec
- 6Git将当前分支暂存切换到其他分支_如何暂存修改切换分支git
- 7solidity实现智能合约教程(3)-空投合约
- 8上位机图像处理和嵌入式模块部署(qmacvisual寻找圆和寻找直线)
- 930天拿下Rust之错误处理
- 10基于springboot的在线招聘平台设计与实现 毕业设计开题报告_招聘app的设计与实现的选题背景怎么写
详解 Pytorch 实现 MNIST_pytorch mnist
赞
踩
MNIST虽然很简单,但是值得我们学习的东西还是有很多的。
项目虽然简单,但是个人建议还是将各个模块分开创建,特别是对于新人而言,模块化的创建会让读者更加清晰、易懂。
- CNN模块:卷积神经网络的组成;
- train模块:利用CNN模型 对 MNIST数据集 进行训练并保存模型
- test模块:加载训练好的模型对测试集数据进行测试
- cnn.pt : train 的CNN模型
注意!
有GPU的小伙伴尽量使用GPU训练,GPU的训练速度比CPU的训练速度高许多倍,可以节约大量训练时间

1、CNN 模块
MNIST的识别算法有很多,在此提供的是 卷积神经网络CNN ,其他算法也同样可以取得很好的识别效果,有兴趣的小伙伴可以自己尝试下。
在此就不得不提 Pytorch的优势了,都知道 Pytorch 是动态计算模型。但是何为动态计算模型呢?
- 在此对比 Tensorflow。在流行的神经网络架构中, Tensorflow 就是最典型的静态计算架构。使用 Tensorflow 就必须先搭建好这样一个计算系统, 一旦搭建好了, 就不能改动了 (也有例外), 所有的计算都会在这种图中流动, 当然很多情况下这样就够了, 我们不需要改动什么结构。
- 不动结构当然可以提高效率. 但是一旦计算流程不是静态的, 计算图要变动. 最典型的例子就是 RNN, 有时候 RNN 的 time step 不会一样, 或者在 training 和 testing 的时候, batch_size 和 time_step 也不一样, 这时, Tensorflow 就头疼了。
- 如果用一个动态计算图的 Pytorch, 我们就好理解多了, 写起来也简单多了. PyTorch 支持在运行过程中根据运行参数动态改变应用模型。可以简单理解为:一种是先定义后使用,另一种是边使用边定义。动态计算图模式是 PyTorch 的天然优势之一,Google 2019年 3 月份发布的 TensorFlow 2.0 Alpha 版本中的 Eager Execution,被认为是在动态计算图模式上追赶 PyTorch 的举措。
如果暂时看不懂的小伙伴,可以先不管,先往后学习,等将来需要的时候再回头思考这段话。
CNN 模块分析
CNN 模块主要分为两个部分,一个是定义CNN模块,另一个是将各个模块组成前向传播通道
-
super() 函数: 是用于调用父类(超类)的一个方法。
用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
super(SimpleCNN, self) 首先找到 SimpleCNN 的父类(就是类 nn.Module ),然后把类 SimpleCNN 的对象转换为类 nn.Module 的对象 -
nn.Sequential(): 是一个有顺序的容器,将神经网络模块 按照传入构造器的顺序依次被添加到计算图中执行。由于每一个神经网络模块都继承于nn.Module,通过索引的方式利用add_module函数将 nn.Sequential()模块 添加到现有模块中。
-
forward(): 是前向传播函数,将之前定义好的每层神经网络模块串联起来,同时也定义了模型的输入参数
-
x.view() & x.reshape(): 其实两者的作用并没有太大区别,作用都是调整张量的类型大小,view() 出现的更早些,而 reshape() 则是为了与 Numpy对齐,在 Pytorch 0.3版本之后添加的,两者作用没有太大区别;
# !/usr/bin/env python # -*- coding:utf-8 -*- # @Time : 2020. # @Author : 绿色羽毛 # @Email : lvseyumao@foxmail.com # @Blog : https://blog.csdn.net/ViatorSun # @Note : from torch import nn class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1,16,kernel_size=3) , nn.BatchNorm2d(16) , nn.ReLU(inplace=True)) self.layer2 = nn.Sequential( nn.Conv2d(16,32,kernel_size=3) , nn.BatchNorm2d(32) , nn.ReLU(inplace=True) , nn.MaxPool2d(kernel_size=2 , stride=2)) self.layer3 = nn.Sequential( nn.Conv2d(32,64,kernel_size=3) , nn.BatchNorm2d(64) , nn.ReLU(inplace=True)) self.layer4 = nn.Sequential( nn.Conv2d(64,128,kernel_size=3) , nn.BatchNorm2d(128) , nn.ReLU(inplace=True) , nn.MaxPool2d(kernel_size=2 , stride=2)) self.fc = nn.Sequential(nn.Linear(128*4*4,1024) , nn.ReLU(inplace=True) , nn.Linear(1024,128) , nn.ReLU(inplace=True) , nn.Linear(128,10) ) def forward( self , x): x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) # x = x.view(x.size(0) , -1) x = x.reshape(x.size(0) , -1) fc_out = self.fc(x) return fc_out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
2、train 模块
# !/usr/bin/env python # -*- coding:utf-8 -*- # @Time : 2020. # @Author : 绿色羽毛 # @Email : lvseyumao@foxmail.com # @Blog : https://blog.csdn.net/ViatorSun # @Note : import torch import CNN from torch import nn , optim from torchvision import datasets from torchvision import transforms from torch.autograd import Variable from torch.utils.data import DataLoader # 定义超参数 learning_rate = 1e-2 # 学习率 batch_size = 128 # 批的大小 epoches_num = 20 # 遍历训练集的次数 # 下载训练集 MNIST 手写数字训练集 train_dataset = datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True ) train_loader = DataLoader( train_dataset, batch_size=batch_size, shuffle=True ) # 定义model 、loss 、optimizer model = CNN.SimpleCNN() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD( model.parameters(), lr=learning_rate ) if torch.cuda.is_available(): print("CUDA is enable!") model = model.cuda() model.train() # 开始训练 for epoch in range(epoches_num): print('*' * 40) train_loss = 0.0 train_acc = 0.0 # 训练 for i, data in enumerate(train_loader, 1 ): img, label = data # 拥有GPU的小伙伴还是推荐使用GPU训练 if torch.cuda.is_available(): img = Variable(img).cuda() label = Variable(label).cuda() else: img = Variable(img) label = Variable(label) # 前向传播 optimizer.zero_grad() out = model(img) loss = criterion(out, label) # 反向传播 loss.backward() optimizer.step() # 损失/准确率计算 train_loss += loss.item() * label.size(0) _ , pred = out.max(1) num_correct = pred.eq(label).sum() accuracy = pred.eq(label).float().mean() train_acc += num_correct.item() print('Finish {} Loss: {:.6f}, Acc: {:.6f}'.format( epoch+1 , train_loss / len(train_dataset), train_acc / len(train_dataset ))) # 保存模型 torch.save(model, 'cnn.pt')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
3、test 模块
在模型的使用过程中,有些子模块(如:丢弃层、批次归一化层等)有两种状态,即训练状态和预测状态,在不同时候 Pytorch模型 需要在两种状态中相互转换。
- model.tran() 方法会将模型(包含所有子模块)中的参数转换成训练状态
- model.eval() 方法会将模型(包含所有子模块)中的参数转换成预测状态
Pytorch 的模型在不同状态下的预测准确性会有差异,在训练模型的时候需要转换为训练状态,在预测的时候需要转化为预测状态,否则最后模型预测准确性可能会降低,甚至会得到错误的结果。
# !/usr/bin/env python # -*- coding:utf-8 -*- # @Time : 2020. # @Author : 绿色羽毛 # @Email : lvseyumao@foxmail.com # @Blog : https://blog.csdn.net/ViatorSun # @Note : import torch from torch import nn from torchvision import datasets from torchvision import transforms from torch.autograd import Variable from torch.utils.data import DataLoader # 定义超参数 batch_size = 128 # 批的大小 # 下载训练集 MNIST 手写数字测试集 test_dataset = datasets.MNIST( root='./data', train=False, transform=transforms.ToTensor()) test_loader = DataLoader(test_dataset , batch_size=batch_size, shuffle=False) # 加载 Train 模型 model = torch.load('cnn.pt') criterion = nn.CrossEntropyLoss() model.eval() eval_acc = 0 eval_loss = 0 # 测试 for data in test_loader: img, label = data if torch.cuda.is_available(): img = Variable(img ).cuda() label = Variable(label).cuda() else: img = Variable(img ) label = Variable(label) out = model(img) loss = criterion(out, label) eval_loss += loss.item() * label.size(0) _ , pred = torch.max(out,1) num_correct = (pred==label).sum() eval_acc += num_correct.item() print('Test Loss: {:.6f} , Acc: {:.6f}'.format( eval_loss/(len(test_dataset)), eval_acc/(len(test_dataset)) ))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
4、MNIST 数据集
如果还没有MNIST数据集,可以通过以下方式从 torchvision 下载,下载路径为项目路径下的 ‘./data’ 文件夹下,可以看到 MNIST 的数据是 ubyte
from torchvision import datasets
train_dataset = datasets.MNIST( root='./data', train=True, transform=transforms.ToTensor(), download=True )
- 1
- 2
- 3
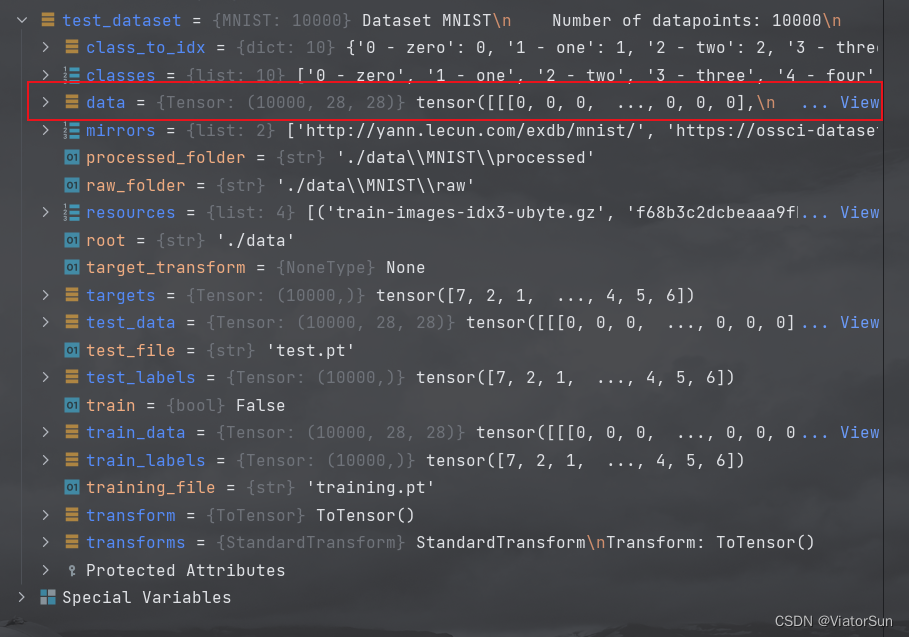
通过上述 datasets.MNIST 命令将 MNIST 数据读取到内存中,并转换为 Tensor 格式保存在 train_dataset 变量中,通过Debug 我们可以看到 MNIST 的数据 是 【10000,28,28】的数据,每个 【28,28】的数据对应的标签是 targets
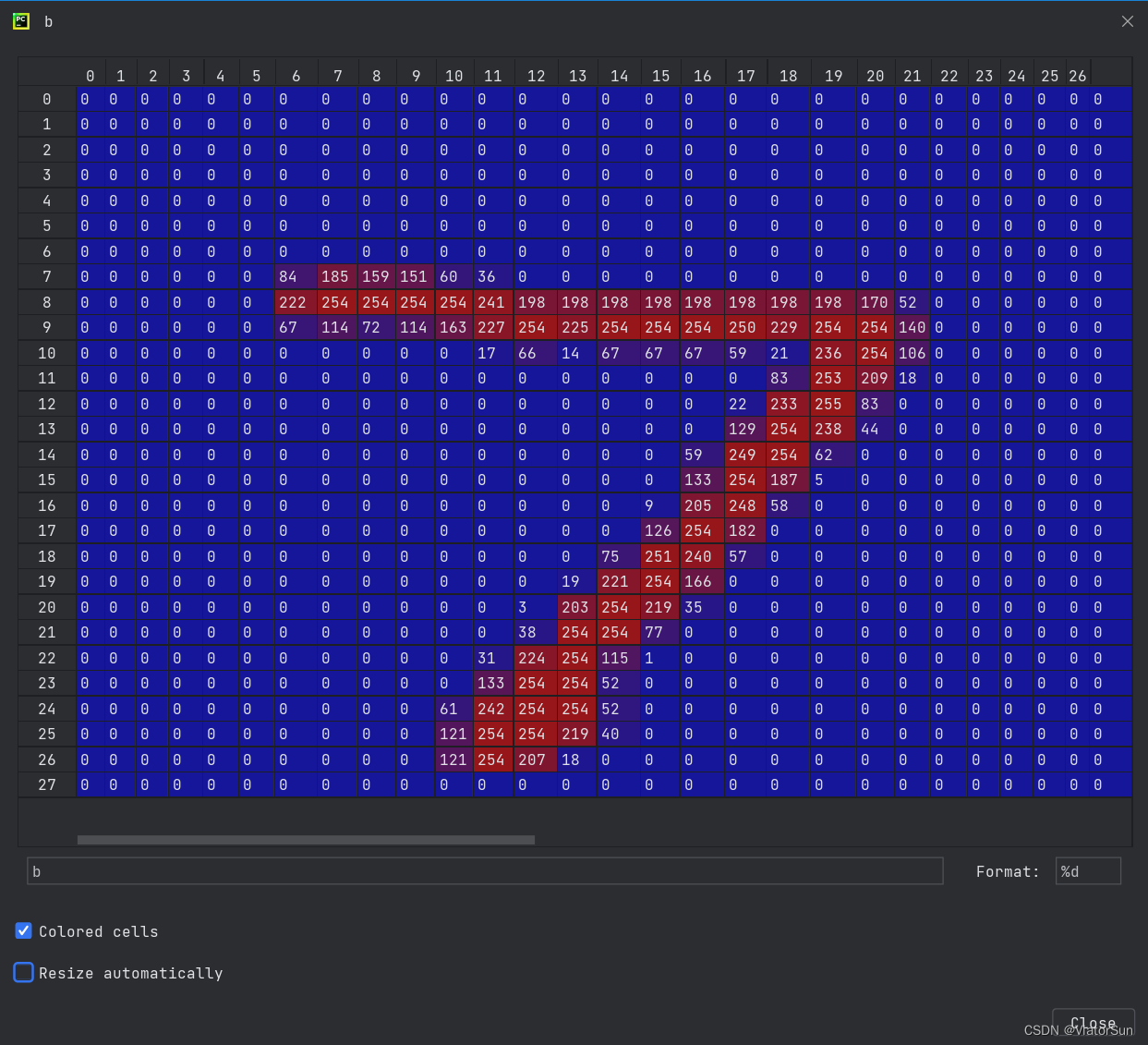
然后我们可视化其中一个 【28,28】数据可以看出,其就是一个 28x28 的单通道灰度图,每个值表示一个像素点,其值范围为 【0-255】,像素值并不能直接传入模型,需要通过 transforms.ToTensor() 将其转化为 Tensor格式。