
- 1C语言:找出n个数中最大的数和最小的数,并将它们的值输出出来。_找出n个数中最大的数和最小的数,并将它们的值输出出来
- 2Android应用开发(1)Android Studio开发环境搭建_android studio开发app
- 3ubuntu adb 找不到设备问题的解决方法_ubuntu adb找不到设备
- 4js获取给定日期的后几天或者前几天_js获取当前日期后几天
- 5linux usb免驱麦克风,pyaudio检测不到USB 麦克风
- 6基于Visuanl stdio 2017 检测人脸坐标C++代码_c++如何获取人脸识别的坐标
- 7项目开发中遇到的extjs常见问题 _extjs httpproxy 异常关闭后事件
- 8模糊查询like的用法
- 9【数据结构】单链表的层层实现!! !
- 10批量双重加密压缩小工具7z格式_批量压缩文件为加密压缩
本地运行 AI 语音克隆工具 GPT-SoVITS,超方便,超真实_ai语音克隆gpt-sovits
赞
踩

文本转语音已经很成熟了,例如剪映的朗读功能。
但这些工具提供的语音风格都是固定,你只能从中选择,如果你想要使用某个喜爱人物的声音,怎么办?
这就需要使用语音克隆,模拟你的目标语音风格。
GPT-SoVITS(github.com/RVC-Boss/GPT-SoVITS) 是一个开源的语音克隆项目,克隆效果很好,已经有 18.8k 的 star。
主要特点:
-
极其方便,只需提供5秒的语音样本,就可以模仿这个样本的语音风格朗读指定的文本。
-
可以训练微调,仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
-
操作简单,提供了 Web 界面。
下面以 Windows 系统为例,了解一下安装和使用过程。
安装
GPT-SoVITS 为 Windows 系统提供了安装包,下载地址:
https://huggingface.co/lj1995/GPT-SoVITS-windows-package/resolve/main/GPT-SoVITS-beta.7z?download=true
是 7z 压缩格式,需要你先安装好 7zip。
下载之后解压,里面有一个启动文件 go-webui.bat,双击即可启动 GPT-SoVITS 的 Web 操作界面。
使用

上图是启动之后的界面效果,点击导航标签中的 “1-GPT-SoVITS-TTS” 进行文本转语音操作。
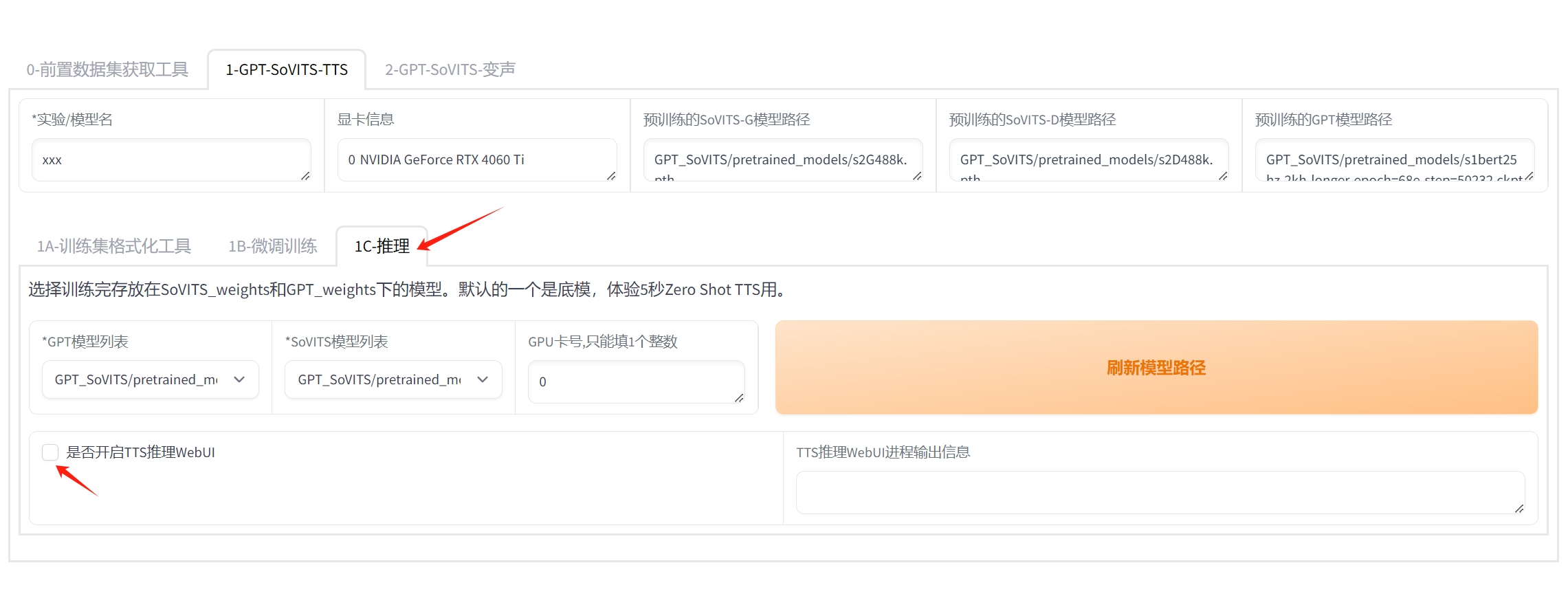
进入后,这个页面有一个二级导航标签,点击其中的 “1C-推理” 标签。
进入后,选中 “是否开启TTS推理WebUI” 这一选项。
选中后,耐心等待几秒钟,会自动打开一个新的页面。
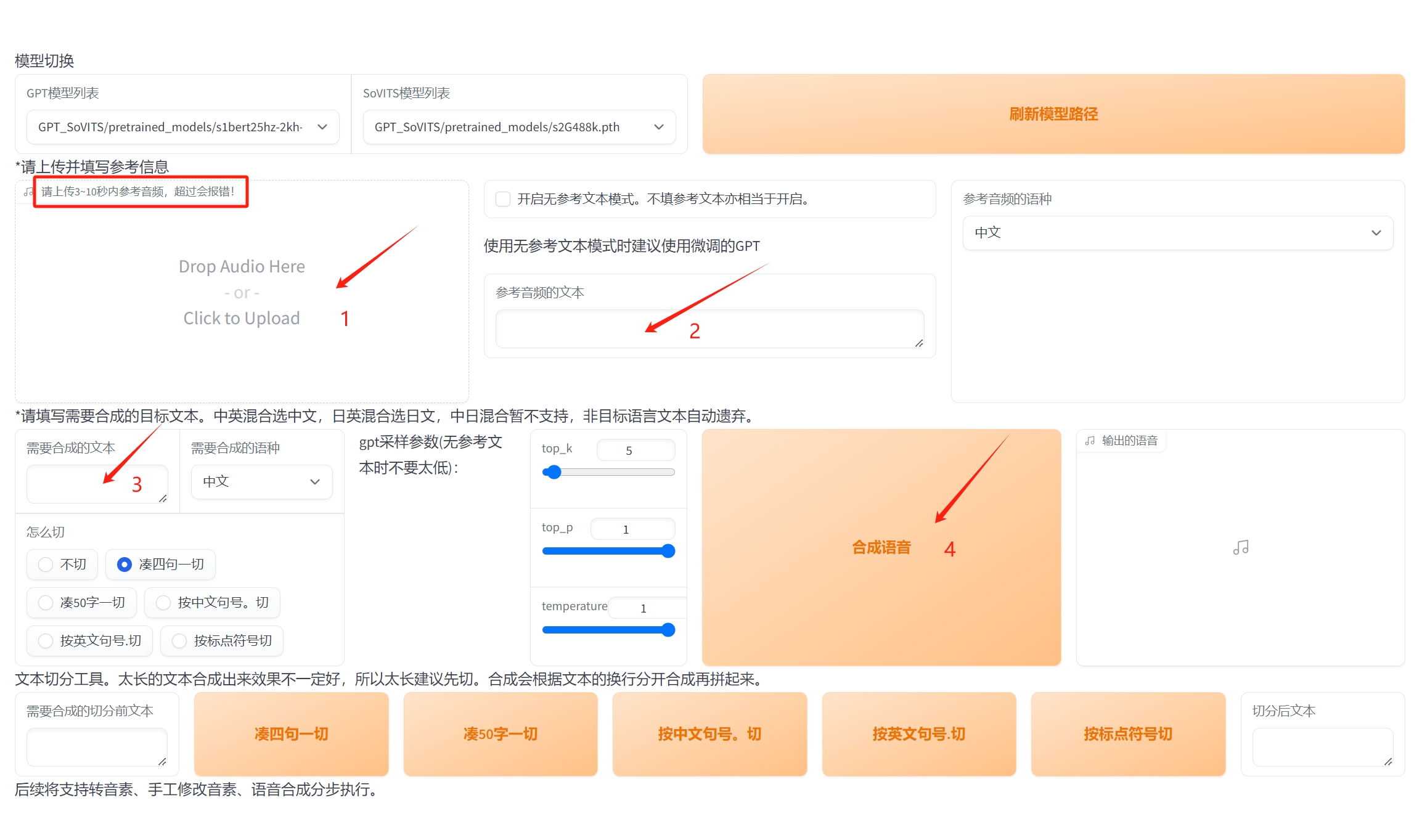
这个页面就是真正进行声音克隆和文本转语音的操作界面。
操作非常简单,一共就4步。
第一步,把你准备好的要克隆的语音样本上传上来。
需要注意的是,语音样本一定要在 3~10 秒,不能超过,否则会报错。还有,样本中的人声一定要清晰,不要模糊嘈杂,否则会大大影响克隆效果
第二步,把你要克隆的语音所对应的文本粘贴过来,这样 GPT-SoVITS 就可以校准语音样本的内容了。
第三步,输入你要朗读的文本。
第四步,开始语音合成。

上图是我上传和填写的示例,超级简单,而且合成的效果很好,我认为输出的声音效果能达到样本的 **80%**。
性能
在我的示例中,输出的结果声音为9秒。
运行时间大概为7秒。

运行过程中我看了性能占用情况。
对 CPU 和内存的占用较小,主要是使用显卡,运行期间会有两三秒的峰值,把显卡占满。
GPT-SoVITS 克隆效果不错,安装操作都很简单,运行速度快。
对语音克隆、文本转语音有兴趣的话,推荐试试。
#语音克隆,#AI 人工智能,#GPT-SoVITS,#TTS,#gpt890
信息来源 gpt890.com/article/32

