
- 1LightPicture精致图床PHP系统源码+功能强大_图床源码
- 2NLP入门-Task3 特征选择_nlp task3
- 3多家中国车企宣布将搭载英伟达最新车载芯片;Altman 曝全新 GPT-5 细节丨 RTE 开发者日报 Vol.168
- 4YOLOv6 Pro | YOLOv6网络魔改 (1) ——RepGFPN融合高效聚合网络(ELAN)和重参数化的目标检测Neck(来自DAMO-YOLO)
- 5游戏中的数学与物理学 第二版_数天才——游戏中体会数学的乐趣
- 6《云原生安全攻防》-- 云原生应用风险分析
- 7威胁建模与网络安全测试方法
- 8AI辅写疑似度检测软件推荐,让论文真实性和原创性更有保障!_askpaper写论文可以通过aigc检测吗 知乎
- 9Windows Edge 兼容性问题修复
- 10容器化技术与微服务结合---SpringCloud框架与阿里云serverless k8s的结合(六)_serverless框架和spring cloud
拼写纠错原理以及模型(Spelling Correction model)_英文纠错 文本模型
赞
踩
拼写纠错(Spelling Correction)
1 任务定义
拼写纠错(Spelling Correction),又称拼写检查(Spelling Checker),往往被用于字处理软件、输入法和搜索引擎中,如下所示:



2 类型
拼写纠错一般可以拆分成两个子任务:
Spelling Error Detection:按照错误类型不同,分为Non-word Errors和Real-word Errors。前者指那些拼写错误后的词本身就不合法,如错误的将“giraffe”写成“graffe”;后者指那些拼写错误后的词仍然是合法的情况,如将“there”错误拼写为“three”(形近),将“peace”错误拼写为“piece”(同音),将“two”错误拼写为“too”(同音)。
Spelling Error Correction:自动纠错,如把“hte”自动校正为“the”,或者给出一个最可能的拼写建议,甚至一个拼写建议列表。
2)Non-word拼写错误
Spelling error detection:任何不被词典所包含的word均被当作spelling error,识别准确率依赖词典的规模和质量。
Spelling error correction:查找词典中与error最近似的word,常见的方法有Shortest weighted edit distance和Highest noisy channel probability。
3)Real-word拼写错误
Spelling error detection:每个word都作为spelling error candidate。
Spelling error correction:从发音和拼写等角度,查找与word最近似的words集合作为拼写建议,常见的方法有Highest noisy channel probability和Classifier。
4)基于Noisy Channel Model的拼写纠错
Noisy Channel Model即噪声信道模型,或称信源信道模型,这是一个普适性的模型,被用于语音识别、拼写纠错、机器翻译、中文分词、词性标注、音字转换等众多应用领域。其形式很简单,如下图所示:

噪声信道试图通过带噪声的输出信号恢复输入信号,形式化定义为:
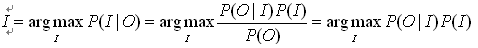
应用于拼写纠错任务的流程如下:

noisy word(即splling error)被看作original word通过noisy channel转换得到,现在已知noisy word(用x表示)如何求得最大可能的original word(用w表示),公式如下:

P(w)为先验概率,P(x|w)为转移概率,二者可以基于训练语料库建立语言模型和转移矩阵(又称error model,channel model)得到。
下面通过一个Non-word spelling error correction的例子加以解释:
给定拼写错误“acress”,首先通过词典匹配容易确定为“Non-word spelling error”;然后通过计算最小编辑距离获取最相似的candidate correction,需要特别说明的是,这里的最小编辑距离涉及四种操作:


据统计,80%的拼写错误编辑距离为1,几乎所有的拼写错误编辑距离小于等于2,基于此,可以减少大量不必要的计算。
通过计算最小编辑距离获取拼写建议候选集(candidate w),此时,我们希望选择概率最大的w作为最终的拼写建议,基于噪声信道模型思想,需要进一步计算P(w)和P(x|w)。
通过对语料库计数、平滑等处理可以很容易建立语言模型,即可得到P(w),如下表所示,计算Unigram Prior Probability(word总数:404,253,213)

接下来,可以基于大量<misspelled word x=x1 x2 x3 … xm, correct word w=w1 w2 w3 … wn>pair计算del、ins、sub和trans四种转移矩阵,然后求得转移概率P(x|w):

计算P(“acress”|w)如下:

计算P(w)P(“acress”|w)如下:

“across”相比其他candidate可能性更大。
上面建立语言模型时采用了unigram,也可以推广到bigram,甚至更高阶,以较好的融入上下文信息。
如句子“a stellar and versatile acress whose combination of sass and glamour…”,计算bigram为:
P(actress|versatile)=.000021 P(whose|actress) = .0010
P(across|versatile) =.000021 P(whose|across) = .000006
则联合概率为:
P(“versatile actress whose”) = .000021*.0010 = 210 x10-10
P(“versatile across whose”) = .000021*.000006 = 1 x10-10
“actress”相比“across”可能性更大。
5)Real-word拼写纠错
Kukich(1992)指出有25%~40%的拼写错误都属于Real-word类型,与Non-word类型相比,纠错难度更大,因为句子中的每个word都被当作待纠错对象。通常,解决方法分两步:

例如,给定句子S=w1,w2,w3,…,wn,为每个wi生成candidate set,如下:
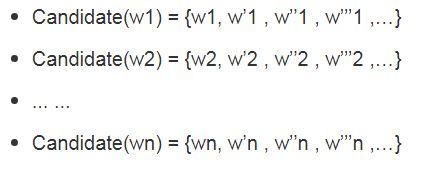
最后,选择概率最大的序列W为自动纠错后的句子,与中文分词、音字转换等应用相同,可以表示成词网格形式,转化为HMM的解码过程:

为了简化起见,一般规定一个句子中最多有一个word存在splling error(事实上,所出现的情况也的确如此)。
6)应用
实际的拼写纠错系统一般会遵守如下HCI(Human Computer Interface)准则:

根据应用场景不同(Domain Sensitivity),需要对语言模型进行特别的处理,如:

除了字面上的拼写错误,还有可能同音导致,所以,有些系统将“error model”转化为“Phonetic error model”解决拼写纠错问题。
另外,键盘上临近的按键更容易引入spelling error pair,据此可以对转移矩阵进行加权。

我们还可以将拼写纠错问题转化为分类问题,通过构建训练语料库,抽取features,训练分类模型,预测新实例等一系列过程解决,如下:

中文与英文区别
抛砖引玉。英文和中文的区别在于,英文没有输入法,最小处理单元是一个词(相对于中文的字),而中文处理的最小单元其实是词。英文拼写纠错主要针对的是一 个word中有部分字母拼写错误,而中文的纠错主要是针对词,多数由于输入法联想得到的词和我们希望的词不同导致,或因前后鼻音等南方人拼音问题导致,所以中文的纠错主要是针对词,相当于英语的phrase。面对word的纠错无法直接应用于中文。中文的纠错会根据词到拼音的转换,得到具有同样拼音的其 他的词或具有前后鼻音的会混淆的拼音对应的其他的词。这里切得的词可以基于分词算法也可以基于n-gram来得到词,并需要分析词之间的关联或单个词的出 现概率等,一般需要挑选和其他词关联明显小,或给定词本身出现概率相比同拼音其他词出现概率小的进行所谓的纠正。为了做到这点,需要有对应的转换词库以及对应的同音 词的出现频率以及和其他词的co-occurrence等计算所得的概率。这里也可以应用同样适用于英文纠错的near duplicated的query log进行推荐。
query correction应该是query suggestion的子类。前者主要在于纠正拼写或输入错误,而后者还可以关联搜索的推荐,类似related search,以及根据结果的反馈的查询扩展等。前者关注查询本身,主要利用大corpus得到的简单的统计出现和共现模型以及词典,而后者还会依赖 query log和搜索结果对输入的修正
王利锋Fandy:回复@昊奋:补充一个,中文中还会混杂拼音
恩,对于混淆拼音或英文等字符的话,即可按照之前对英文的来处理。之前主要写出和基于unigram的基于编辑距离等的引文纠错的区别,在不考虑分词和纠错的联合模型的情况下,可直接转换为图网,找出和其他相连节点关联度弱且出现概率低的词并纠正。
我刚刚的评论仅仅写了如果是我,打算怎么做。原则是:利用词和拼音转换得到候选词,充分利用大corpus的威力(类似google和Microsoft提供的n-gram library)估计词出现频率和贡献概率,建模(词网或图)获得top-k可被替换的词组合。
进一步补充一下:上面提到了一个通用的框架,并没有涉及到学习算法。大部分是通过简单的概率计算和建模,借助基于图的语言模型做的非监督的方法。当然在选择top-k(往往一个词进行纠错,这和英文中一个句子中只有一个word有speling error是类似的),可以将问题也看作是一个序列标注问题,对于输入的查询,其输出是区分无需纠正(标为0)和需要纠正的那些词(标为1)的序列。也可以应用结构化学习方法,输出排序列表,这样可以进行top-k的控制。

